תרגול 10 - MLP and Back-propagation
Artificial Neural Networks (ANN)
רשתות ניורונים מלאכותיות הינן שיטה לבניה של פונקציות פרמטריות.
במקור, השיטה הינה (כנראה) בהשראת רשתות נוירונים ביולוגיות.
ברשתות נוירונים מלאכותיות נשלב הרבה פונקציות פרמטריות פשוטות על מנת לקבל מודל אשר יכול לייצג פונקציות מורכבות.
לרוב, הפונקציות הפשוטות יקבלו מספר משתנים ויחזירו סקלר.
לרוב נבחר את הפונקציות הפשוטות להיות מהצורה:
h ( x ; w , b ) = φ ( w ⊤ x + b ) h(\boldsymbol{x};\boldsymbol{w},b)=\varphi(\boldsymbol{w}^{\top}\boldsymbol{x}+b) h ( x ; w , b ) = φ ( w ⊤ x + b )
מושגים:
יחידות נסתרות (hidden units ): הנוירונים אשר אינם מחוברים למוצא הרשת (אינם נמצאים בסוף הרשת).רשת עמוקה (deep network ): רשת אשר מכילה מסלולים מהכניסה למוצא, אשר עוברים דרך יותר מיחידה נסתרת אחת.ארכיטקטורה : הצורה שבה הנוירונים מחוברים בתוך הרשת.
מוטיבציה
רשתות נוירונים הן פונקציות פרמטריות לכל דבר ועניין.
נשתמש בהן בקורס למטרות הבאות:
פתרון בעיות סיווג בגישה הדיסקרימינטיבית הסתברותית.
פתרון בעיות רגרסיה בשיטת ERM.
לרוב, נפתור את בעיות האופטימיזציה של מציאת הפרמטרים בעזרת gradient descent.
ניעזר באלגוריתם שנקרא back-propagation על מנת לחשב את הנגזרות של הרשת על פי הפרמטריים.
הערה: נשתמש בוקטור θ \boldsymbol{\theta} θ
הערה לגבי השם loss
עד כה השתמשנו בשם loss בהקשר של פונקציות risk (הקנס שמקבלים על שגיאת חיזוי בודדת מסויימת).
בהקשר של רשתות נוירונים משתמשים לרוב במושג זה על מנת לתאר את הפונקציית המטרה (ה objective) שאותו רוצים למזער בבעיית האופטימיזציה.
בכדי למנוע בלבול, בקורס זה נשתדל להיצמד להגדרה המקורית של פונקציית ה loss (שמגדירה את פונקציית ה risk) ונמשיך להשתמש בשם פונקציית מטרה או objective בכדי לתאר את הביטוי שאותו אנו רוצים למזער.
Back-Propagation
Back-propagation הוא אלגוריתם המשתמש בכלל השרשת על מנת לחשב את הנגזרות של רשת נוירונים.
המטרה באלגוריתם זה היא לחשב את הנגזרת של המוצא ביחס לכל אחד מהפרמטרים ברשת, כך שלאחר מכן נוכל להפעיל את אלגוריתם gradient descent על מנת לעדכן את הפרמטרים
תזכורת לכלל השרשרת:
d d x f ( z 1 ( x ) , z 2 ( x ) , z 3 ( x ) ) = ( ∂ ∂ z 1 f ( z 1 ( x ) , z 2 ( x ) , z 3 ( x ) ) ) d d x z 1 ( x ) + ( ∂ ∂ z 2 f ( z 1 ( x ) , z 2 ( x ) , z 3 ( x ) ) ) d d x z 2 ( x ) + ( ∂ ∂ z 3 f ( z 1 ( x ) , z 2 ( x ) , z 3 ( x ) ) ) d d x z 3 ( x ) \begin{aligned}
\frac{d}{dx} f(z_1(x),z_2(x),z_3(x))
=& &\left(\frac{\partial}{\partial z_1} f(z_1(x),z_2(x),z_3(x))\right)\frac{d}{dx}z_1(x)\\
&+&\left(\frac{\partial}{\partial z_2} f(z_1(x),z_2(x),z_3(x))\right)\frac{d}{dx}z_2(x)\\
&+&\left(\frac{\partial}{\partial z_3} f(z_1(x),z_2(x),z_3(x))\right)\frac{d}{dx}z_3(x)\\
\end{aligned} d x d f ( z 1 ( x ) , z 2 ( x ) , z 3 ( x ) ) = + + ( ∂ z 1 ∂ f ( z 1 ( x ) , z 2 ( x ) , z 3 ( x ) ) ) d x d z 1 ( x ) ( ∂ z 2 ∂ f ( z 1 ( x ) , z 2 ( x ) , z 3 ( x ) ) ) d x d z 2 ( x ) ( ∂ z 3 ∂ f ( z 1 ( x ) , z 2 ( x ) , z 3 ( x ) ) ) d x d z 3 ( x )
דוגמא (מההרצאה)
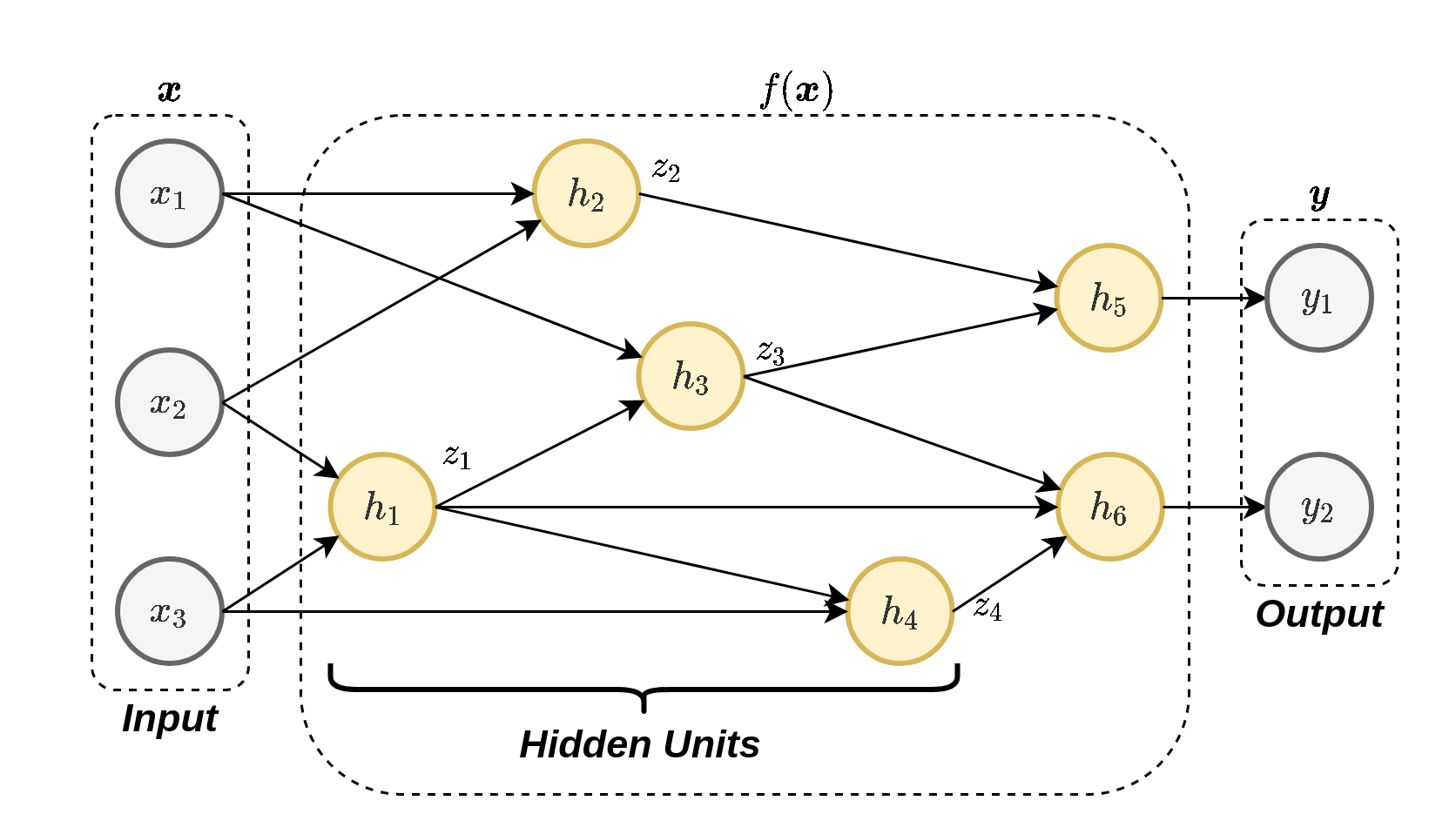
נסתכל על הרשת הבאה:
עבור x \boldsymbol{x} x θ \boldsymbol{\theta} θ
נרצה לחשב את הנזרות של מוצא הרשת y \boldsymbol{y} y θ \boldsymbol{\theta} θ
נסתכל לדוגמא על הנגזרת של y 1 y_1 y 1 θ 3 \theta_3 θ 3 z i z_i z i h i h_i h i
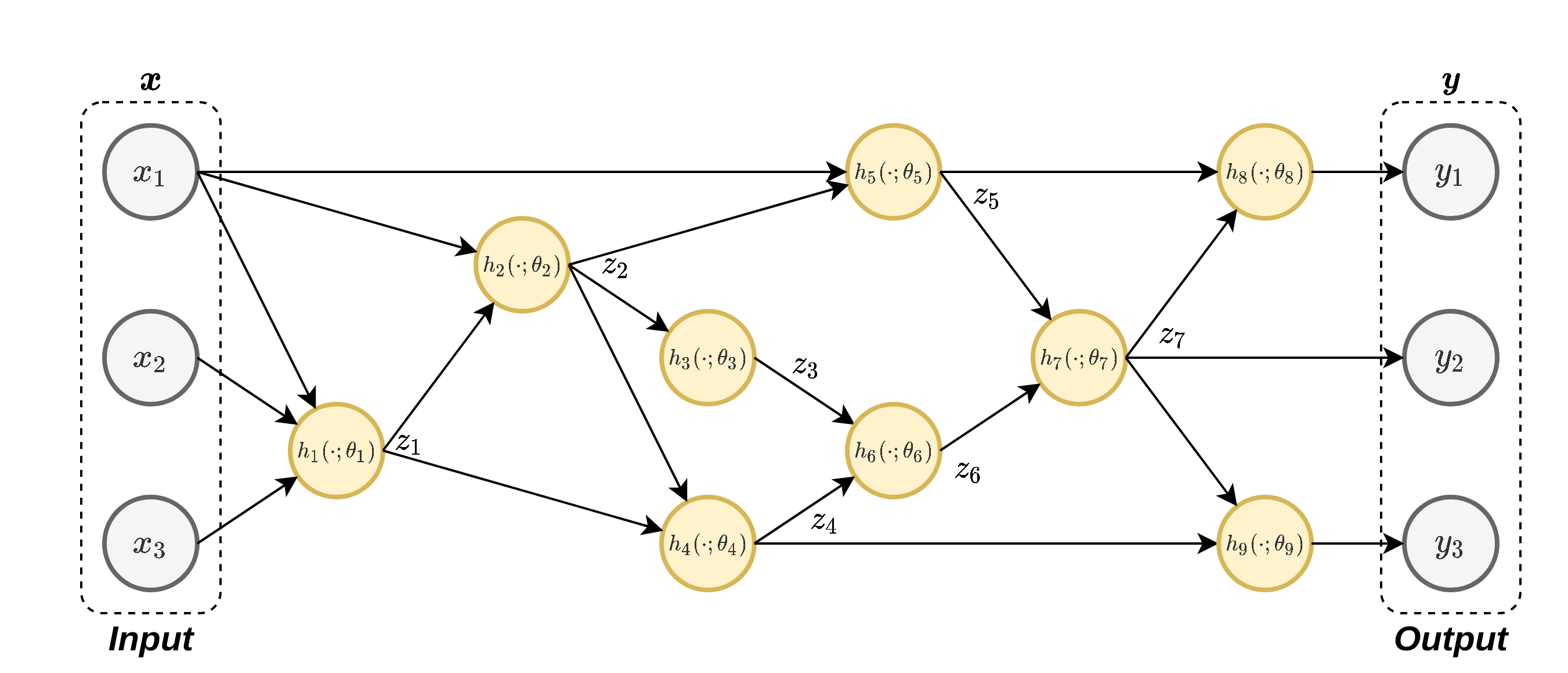
נוכל לפרק את ∂ y ∂ θ 3 \frac{\partial y}{\partial\theta_3} ∂ θ 3 ∂ y
∂ y 1 ∂ θ 3 = ∂ y 1 ∂ z 3 ∂ z 3 ∂ θ 3 = ∂ y 1 ∂ z 3 ∂ h 3 ∂ θ 3 \frac{\partial y_1}{\partial\theta_3}
=\frac{\partial y_1}{\partial z_3}\frac{\partial z_3}{\partial \theta_3}
=\frac{\partial y_1}{\partial z_3}\frac{\partial h_3}{\partial \theta_3} ∂ θ 3 ∂ y 1 = ∂ z 3 ∂ y 1 ∂ θ 3 ∂ z 3 = ∂ z 3 ∂ y 1 ∂ θ 3 ∂ h 3 נוכל לפרק גם את d y 1 d z 3 \frac{dy_1}{dz_3} d z 3 d y 1
∂ y 1 ∂ z 3 = ∂ y 1 ∂ z 6 ∂ z 6 ∂ z 3 = ∂ y 1 ∂ z 6 ∂ h 6 ∂ z 3 \frac{\partial y_1}{\partial z_3}
=\frac{\partial y_1}{\partial z_6}\frac{\partial z_6}{\partial z_3}
=\frac{\partial y_1}{\partial z_6}\frac{\partial h_6}{\partial z_3} ∂ z 3 ∂ y 1 = ∂ z 6 ∂ y 1 ∂ z 3 ∂ z 6 = ∂ z 6 ∂ y 1 ∂ z 3 ∂ h 6 ונוכל להמשיך ולפרק את d y 1 d z 6 \frac{dy_1}{dz_6} d z 6 d y 1
∂ y 1 ∂ z 6 = ∂ y 1 ∂ z 7 ∂ z 7 ∂ z 6 = ∂ h 8 ∂ z 7 ∂ h 7 ∂ z 6 \frac{\partial y_1}{\partial z_6}
=\frac{\partial y_1}{\partial z_7}\frac{\partial z_7}{\partial z_6}
=\frac{\partial h_8}{\partial z_7}\frac{\partial h_7}{\partial z_6} ∂ z 6 ∂ y 1 = ∂ z 7 ∂ y 1 ∂ z 6 ∂ z 7 = ∂ z 7 ∂ h 8 ∂ z 6 ∂ h 7
זאת אומרת שאם נדע לחשב את הנגזרות של d h i d z i \frac{dh_i}{dz_i} d z i d h i d h i d θ i \frac{dh_i}{d\theta_i} d θ i d h i
נסתכל לדוגמא על הנגזרת:
∂ ∂ θ 6 h 6 ( z 3 , z 4 ; θ 6 ) \frac{\partial}{\partial \theta_6}h_6(z_3,z_4;\theta_6) ∂ θ 6 ∂ h 6 ( z 3 , z 4 ; θ 6 )
ראשית, נגזור את הפונקציה h 6 h_6 h 6 z 3 z_3 z 3 z 4 z_4 z 4 θ 6 \theta_6 θ 6
בכדי לחשב את הערכים של z i z_i z i x \boldsymbol{x} x z i z_i z i forward pass .
לאחר שחישבנו את ערכי הביניים z i z_i z i
נחשב את: ∂ y 1 ∂ θ 8 \frac{\partial y_1}{\partial\theta_8} ∂ θ 8 ∂ y 1 ∂ y 1 ∂ z 7 \frac{\partial y_1}{\partial z_7} ∂ z 7 ∂ y 1
נשתמש ב ∂ y 1 ∂ z 7 \frac{\partial y_1}{\partial z_7} ∂ z 7 ∂ y 1 ∂ y 1 ∂ θ 7 \frac{\partial y_1}{\partial\theta_7} ∂ θ 7 ∂ y 1 ∂ y ∂ z 5 \frac{\partial y}{\partial z_5} ∂ z 5 ∂ y ∂ y ∂ z 6 \frac{\partial y}{\partial z_6} ∂ z 6 ∂ y
נשתמש ב ∂ y 1 ∂ z 6 \frac{\partial y_1}{\partial z_6} ∂ z 6 ∂ y 1 ∂ y 1 ∂ θ 6 \frac{\partial y_1}{\partial\theta_6} ∂ θ 6 ∂ y 1 ∂ y ∂ z 3 \frac{\partial y}{\partial z_3} ∂ z 3 ∂ y ∂ y ∂ z 4 \frac{\partial y}{\partial z_4} ∂ z 4 ∂ y
וכן הלאה. מכיוון שבשלב זה אנו מחשבים את הנגזרות מהמוצא לכיוון הכניסה, שלב זה נקרא ה backward pass ומכאן גם מקבלת השיטה את שמה.
MultiLayer Perceptron (MLP)
הניורונים הם מהצורה:
h i , j ( z i − 1 ; w i , j , b i , j ) = φ ( w i , j T z i − 1 + b i , j ) h_{i,j}(\boldsymbol{z}_{i-1};\boldsymbol{w}_{i,j},b_{i,j})=\varphi(\boldsymbol{w}_{i,j}^T\boldsymbol{z}_{i-1}+b_{i,j}) h i , j ( z i − 1 ; w i , j , b i , j ) = φ ( w i , j T z i − 1 + b i , j )
הפרמטרים הנלמדים הינם המשקולות w i , j \boldsymbol{w}_{i,j} w i , j b i , j b_{i,j} b i , j h i , j h_{i,j} h i , j
ה Hyperparameters של MLP הינם:
מספר השכבות
מספר הנוירונים בכל שכבה
פונקציית האקטיבציה (שיכולה להשתנות משכבה לשכבה)
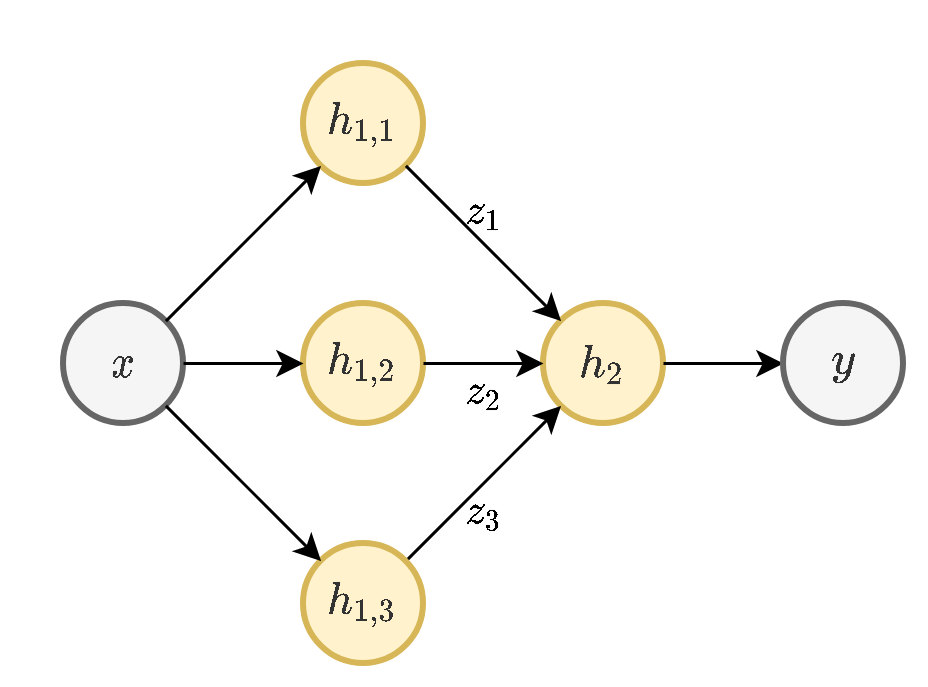
תרגיל 10.1 - Back propagation in MLP
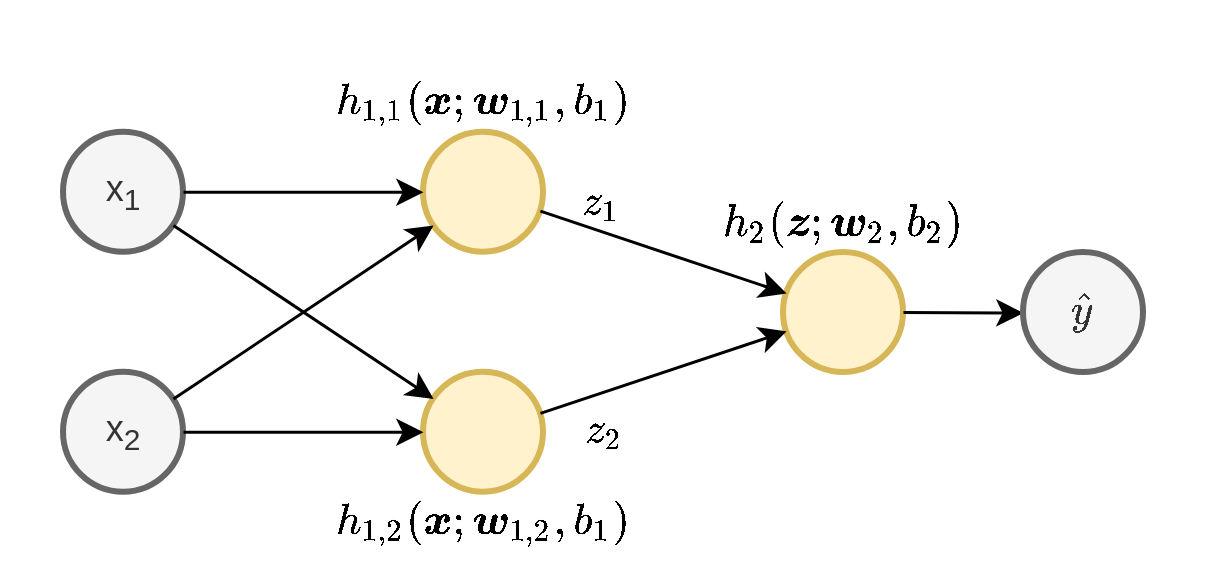
נפתור בעיית רגרסיה בעזרת ERM ורשת ה MLP הבאה:
כניסה באורך 2
שכבה נסתרת אחת ברוחב 2
יציאה באורך 1 (מוצא סקלרי)
ב- h 1 , 1 h_{1,1} h 1 , 1 h 1 , 2 h_{1,2} h 1 , 2
ב- h 2 h_2 h 2
h 1 , 1 ( x ; w 1 , 1 , b 1 ) = max ( x ⊤ w 1 , 1 + b 1 , 0 ) h 1 , 2 ( x ; w 1 , 2 , b 1 ) = max ( x ⊤ w 1 , 2 + b 1 , 0 ) h 2 ( z ; w 2 , b 2 ) = z ⊤ w 2 + b 2 \begin{aligned}
h_{1,1}(\boldsymbol{x};\boldsymbol{w}_{1,1},b_1)&=\max(\boldsymbol{x}^{\top}\boldsymbol{w}_{1,1}+b_1,0)\\
h_{1,2}(\boldsymbol{x};\boldsymbol{w}_{1,2},b_1)&=\max(\boldsymbol{x}^{\top}\boldsymbol{w}_{1,2}+b_1,0)\\
h_2(\boldsymbol{z};\boldsymbol{w}_2,b_2)&=\boldsymbol{z}^{\top}\boldsymbol{w}_2+b_2
\end{aligned} h 1 , 1 ( x ; w 1 , 1 , b 1 ) h 1 , 2 ( x ; w 1 , 2 , b 1 ) h 2 ( z ; w 2 , b 2 ) = max ( x ⊤ w 1 , 1 + b 1 , 0 ) = max ( x ⊤ w 1 , 2 + b 1 , 0 ) = z ⊤ w 2 + b 2 שימו לב: איבר ההיסט בשכבה הראשונה b 1 b_1 b 1
נרכז את כל הפרמטרים של הרשת לוקטור פרמטרים אחד:
θ = [ w 1 , 1 ⊤ , w 1 , 2 ⊤ , b 1 , w 2 ⊤ , b 2 ] ⊤ \boldsymbol{\theta}=[\boldsymbol{w}_{1,1}^{\top},\boldsymbol{w}_{1,2}^{\top},b_1,\boldsymbol{w}_2^{\top},b_2]^{\top} θ = [ w 1 , 1 ⊤ , w 1 , 2 ⊤ , b 1 , w 2 ⊤ , b 2 ] ⊤ ונסמן את הפונקציה שאותה הרשת מממשת ב y ^ = f ( x ; θ ) \hat{\boldsymbol{y}}=f(\boldsymbol{x};\boldsymbol{\theta}) y ^ = f ( x ; θ )
1) בעבור מדגם נתון D = { x ( i ) , y ( i ) } i = 1 N \mathcal{D}=\{\boldsymbol{x}^{(i)},y^{(i)}\}_{i=1}^N D = { x ( i ) , y ( i ) } i = 1 N f f f
פתרון:
פונקציית המחיר (סיכון) של RMSE נתונה על ידי:
E [ ( y ^ − y ) 2 ] = E [ ( f ( x ; θ ) − y ) 2 ] \sqrt{\mathbb{E}\left[(\hat{\text{y}}-\text{y})^2\right]}
=\sqrt{\mathbb{E}\left[(f(\mathbf{x};\boldsymbol{\theta})-\text{y})^2\right]} E [ ( y ^ − y ) 2 ] = E [ ( f ( x ; θ ) − y ) 2 ]
הסיכון האמפירי מתקבל על ידי החלפה של התחולת בממוצע על המדגם:
1 N ∑ i ( f ( x ( i ) ; θ ) − y ( i ) ) 2 \sqrt{\frac{1}{N}\sum_i(f(\boldsymbol{x}^{(i)};\boldsymbol{\theta})-y^{(i)})^2} N 1 i ∑ ( f ( x ( i ) ; θ ) − y ( i ) ) 2
בעיית האופטימיזציה שנרצה לפתור הינה למצוא את הפרמטרים שימזערו את הסיכון האמפירי:
arg min θ 1 N ∑ i ( f ( x ( i ) ; θ ) − y ( i ) ) 2 = arg min θ 1 N ∑ i ( f ( x ( i ) ; θ ) − y ( i ) ) 2 \underset{\boldsymbol{\theta}}{\arg\min}\sqrt{\frac{1}{N}\sum_i(f(\boldsymbol{x}^{(i)};\boldsymbol{\theta})-y^{(i)})^2}
=\underset{\boldsymbol{\theta}}{\arg\min}\frac{1}{N}\sum_i(f(\boldsymbol{x}^{(i)};\boldsymbol{\theta})-y^{(i)})^2 θ arg min N 1 i ∑ ( f ( x ( i ) ; θ ) − y ( i ) ) 2 = θ arg min N 1 i ∑ ( f ( x ( i ) ; θ ) − y ( i ) ) 2
2) נפתור את בעיית האופטימיזציה בעזרת gradient descent עם גודל קצב לימוד η \eta η θ \boldsymbol{\theta} θ ∇ θ f ( x ; θ ) \nabla_{\boldsymbol{\theta}}f(\boldsymbol{x};\boldsymbol{\theta}) ∇ θ f ( x ; θ )
נסמן את ה objective שאותו נרצה למזער ב:
g ( θ ) = 1 N ∑ i ( f ( x ( i ) ; θ ) − y ( i ) ) 2 g(\boldsymbol{\theta})=\frac{1}{N}\sum_i(f(\boldsymbol{x}^{(i)};\boldsymbol{\theta})-y^{(i)})^2 g ( θ ) = N 1 i ∑ ( f ( x ( i ) ; θ ) − y ( i ) ) 2
כלל העדכון של הפרמטרים הינו:
θ ( t + 1 ) = θ ( t ) − η ∇ θ g ( x ; θ ( t ) ) = θ ( t ) − η ∇ θ 1 N ∑ i ( f ( x ( i ) ; θ ( t ) ) − y ( i ) ) 2 = θ ( t ) − 2 η N ∑ i ( f ( x ( i ) ; θ ( t ) ) − y ( i ) ) ∇ θ f ( x ( i ) ; θ ( t ) ) \begin{aligned}
\boldsymbol{\theta}^{(t+1)}
&=\boldsymbol{\theta}^{(t)}-\eta\nabla_{\boldsymbol{\theta}}g(\boldsymbol{x};\boldsymbol{\theta}^{(t)})\\
&=\boldsymbol{\theta}^{(t)}-\eta\nabla_{\boldsymbol{\theta}}\frac{1}{N}\sum_i(f(\boldsymbol{x}^{(i)};\boldsymbol{\theta}^{(t)})-y^{(i)})^2\\
&=\boldsymbol{\theta}^{(t)}-\frac{2\eta}{N}\sum_i(f(\boldsymbol{x}^{(i)};\boldsymbol{\theta}^{(t)})-y^{(i)})\nabla_{\boldsymbol{\theta}}f(\boldsymbol{x}^{(i)};\boldsymbol{\theta}^{(t)})\\
\end{aligned} θ ( t + 1 ) = θ ( t ) − η ∇ θ g ( x ; θ ( t ) ) = θ ( t ) − η ∇ θ N 1 i ∑ ( f ( x ( i ) ; θ ( t ) ) − y ( i ) ) 2 = θ ( t ) − N 2 η i ∑ ( f ( x ( i ) ; θ ( t ) ) − y ( i ) ) ∇ θ f ( x ( i ) ; θ ( t ) )
3) נתון המדגם הבא באורך 2:
x ( 1 ) = [ 1 , 2 ] ⊤ y ( 1 ) = 70 x ( 2 ) = [ 0 , − 1 ] ⊤ y ( 2 ) = 50 \begin{aligned}
\boldsymbol{x}^{(1)}&=[1,2]^{\top}\qquad &y^{(1)}=70\\
\boldsymbol{x}^{(2)}&=[0,-1]^{\top}\qquad &y^{(2)}=50\\
\end{aligned} x ( 1 ) x ( 2 ) = [ 1 , 2 ] ⊤ = [ 0 , − 1 ] ⊤ y ( 1 ) = 7 0 y ( 2 ) = 5 0 כמו כן, נתון כי בצעד מסויים t t t
b 1 ( t ) = 1 w 1 , 1 ( t ) = [ 2 , 3 ] ⊤ w 1 , 2 ( t ) = [ 4 , − 5 ] ⊤ b 2 ( t ) = 6 w 2 ( t ) = [ 7 , 8 ] ⊤ \begin{aligned}
b_1^{(t)}&=1\\
\boldsymbol{w}_{1,1}^{(t)}&=[2,3]^{\top}\\
\boldsymbol{w}_{1,2}^{(t)}&=[4,-5]^{\top}\\
b_2^{(t)}&=6\\
\boldsymbol{w}_{2}^{(t)}&=[7,8]^{\top}\\
\end{aligned} b 1 ( t ) w 1 , 1 ( t ) w 1 , 2 ( t ) b 2 ( t ) w 2 ( t ) = 1 = [ 2 , 3 ] ⊤ = [ 4 , − 5 ] ⊤ = 6 = [ 7 , 8 ] ⊤ חשבו את הערך של b 1 ( t + 1 ) b_1^{(t+1)} b 1 ( t + 1 ) η = 0.01 \eta=0.01 η = 0 . 0 1
נרצה לחשב את:
b 1 ( t + 1 ) = b 1 ( t ) − 2 η N ∑ i ( f ( x ( i ) ; θ ( t ) ) − y ( i ) ) d d b 1 f ( x ( i ) ; θ ( t ) ) \boldsymbol{b}_1^{(t+1)}
=\boldsymbol{b}_1^{(t)}-\frac{2\eta}{N}\sum_i(f(\boldsymbol{x}^{(i)};\boldsymbol{\theta}^{(t)})-y^{(i)})\frac{d}{db_1}f(\boldsymbol{x}^{(i)};\boldsymbol{\theta}^{(t)}) b 1 ( t + 1 ) = b 1 ( t ) − N 2 η i ∑ ( f ( x ( i ) ; θ ( t ) ) − y ( i ) ) d b 1 d f ( x ( i ) ; θ ( t ) )
נחשב את d d b 1 f ( x ( i ) ; θ ( t ) ) \frac{d}{db_1}f(\boldsymbol{x}^{(i)};\boldsymbol{\theta}^{(t)}) d b 1 d f ( x ( i ) ; θ ( t ) )
i = 1 i=1 i = 1 נחשב את ה forward-pass בשביל למצוא את משתני הביניים ואת המוצא:
z 1 = max ( x ( 1 ) ⊤ w 1 , 1 + b 1 , 0 ) = max ( [ 1 , 2 ] [ 2 , 3 ] ⊤ + 1 , 0 ) = max ( 9 , 0 ) = 9 z 2 = max ( x ( 1 ) ⊤ w 1 , 2 + b 1 , 0 ) = max ( [ 1 , 2 ] [ 4 , − 5 ] ⊤ + 1 , 0 ) = max ( − 5 , 0 ) = 0 y = z ⊤ w 2 + b 2 = [ 9 , 0 ] [ 7 , 8 ] ⊤ + 6 = 69 \begin{aligned}
z_1&=\max(\boldsymbol{x}^{(1)\top}\boldsymbol{w}_{1,1}+b_1,0)=\max([1,2][2,3]^{\top}+1,0)=\max(9,0)=9\\
z_2&=\max(\boldsymbol{x}^{(1)\top}\boldsymbol{w}_{1,2}+b_1,0)=\max([1,2][4,-5]^{\top}+1,0)=\max(-5,0)=0\\
y&=\boldsymbol{z}^{\top}\boldsymbol{w}_2+b_2=[9,0][7,8]^{\top}+6=69
\end{aligned} z 1 z 2 y = max ( x ( 1 ) ⊤ w 1 , 1 + b 1 , 0 ) = max ( [ 1 , 2 ] [ 2 , 3 ] ⊤ + 1 , 0 ) = max ( 9 , 0 ) = 9 = max ( x ( 1 ) ⊤ w 1 , 2 + b 1 , 0 ) = max ( [ 1 , 2 ] [ 4 , − 5 ] ⊤ + 1 , 0 ) = max ( − 5 , 0 ) = 0 = z ⊤ w 2 + b 2 = [ 9 , 0 ] [ 7 , 8 ] ⊤ + 6 = 6 9
נחשב את הנגזרות ב backward-pass.
נתחיל בחישוב של d y ^ d z 1 \frac{d\hat{y}}{dz_1} d z 1 d y ^ d y ^ d z 1 \frac{d\hat{y}}{dz_1} d z 1 d y ^
d y ^ d z 1 = d d z 1 ( z ⊤ w 2 + b 2 ) = w 2 , 1 = 7 d y ^ d z 2 = d d z 2 ( z ⊤ w 2 + b 2 ) = w 2 , 2 = 8 \begin{aligned}
\frac{d\hat{y}}{dz_1}&=\frac{d}{dz_1}(\boldsymbol{z}^{\top}\boldsymbol{w}_2+b_2)=w_{2,1}=7\\
\frac{d\hat{y}}{dz_2}&=\frac{d}{dz_2}(\boldsymbol{z}^{\top}\boldsymbol{w}_2+b_2)=w_{2,2}=8\\
\end{aligned} d z 1 d y ^ d z 2 d y ^ = d z 1 d ( z ⊤ w 2 + b 2 ) = w 2 , 1 = 7 = d z 2 d ( z ⊤ w 2 + b 2 ) = w 2 , 2 = 8
נשתמש בחישוב זה בכדי לחשב את d d b 1 f ( x ; θ ) = d y ^ d b 1 \frac{d}{db_1}f(\boldsymbol{x};\boldsymbol{\theta})=\frac{d\hat{y}}{db_1} d b 1 d f ( x ; θ ) = d b 1 d y ^ b 1 b_1 b 1 h 1 , 1 h_{1,1} h 1 , 1 h 1 , 2 h_{1,2} h 1 , 2
(נשתמש בעובדה ש d d x max ( x , 0 ) = I { x > 0 } \frac{d}{dx}\max(x,0)=I\{x>0\} d x d max ( x , 0 ) = I { x > 0 }
d y ^ d b 1 = d y ^ d z 1 d z 1 d b 1 + d y ^ d z 2 d z 2 d b 1 = 7 ⋅ I { x ⊤ w 1 , 1 + b 1 > 0 } + 8 ⋅ I { x ⊤ w 1 , 2 + b 1 > 0 } = 7 \begin{aligned}
\frac{d\hat{y}}{db_1}
&= \frac{d\hat{y}}{dz_1}\frac{dz_1}{db_1}
+\frac{d\hat{y}}{dz_2}\frac{dz_2}{db_1}\\
&= 7\cdot I\{\boldsymbol{x}^{\top}\boldsymbol{w}_{1,1}+b_1>0\}
+8\cdot I\{\boldsymbol{x}^{\top}\boldsymbol{w}_{1,2}+b_1>0\}
=7
\end{aligned} d b 1 d y ^ = d z 1 d y ^ d b 1 d z 1 + d z 2 d y ^ d b 1 d z 2 = 7 ⋅ I { x ⊤ w 1 , 1 + b 1 > 0 } + 8 ⋅ I { x ⊤ w 1 , 2 + b 1 > 0 } = 7
i = 2 i=2 i = 2 נחשב באופן דומה את ה- Forward Pass:
z 1 = max ( x ( 2 ) ⊤ w 1 , 1 + b 1 , 0 ) = max ( [ 0 , − 1 ] [ 2 , 3 ] ⊤ + 1 , 0 ) = max ( − 2 , 0 ) = 0 z 2 = max ( x ( 2 ) ⊤ w 1 , 2 + b 1 , 0 ) = max ( [ 0 , − 1 ] [ 4 , − 5 ] ⊤ + 1 , 0 ) = max ( 6 , 0 ) = 6 y = z ⊤ w 2 + b 2 = [ 0 , 6 ] [ 7 , 8 ] ⊤ + 6 = 54 \begin{aligned}
z_1&=\max(\boldsymbol{x}^{(2)\top}\boldsymbol{w}_{1,1}+b_1,0)=\max([0,-1][2,3]^{\top}+1,0)=\max(-2,0)=0\\
z_2&=\max(\boldsymbol{x}^{(2)\top}\boldsymbol{w}_{1,2}+b_1,0)=\max([0,-1][4,-5]^{\top}+1,0)=\max(6,0)=6\\
y&=\boldsymbol{z}^{\top}\boldsymbol{w}_2+b_2=[0,6][7,8]^{\top}+6=54
\end{aligned} z 1 z 2 y = max ( x ( 2 ) ⊤ w 1 , 1 + b 1 , 0 ) = max ( [ 0 , − 1 ] [ 2 , 3 ] ⊤ + 1 , 0 ) = max ( − 2 , 0 ) = 0 = max ( x ( 2 ) ⊤ w 1 , 2 + b 1 , 0 ) = max ( [ 0 , − 1 ] [ 4 , − 5 ] ⊤ + 1 , 0 ) = max ( 6 , 0 ) = 6 = z ⊤ w 2 + b 2 = [ 0 , 6 ] [ 7 , 8 ] ⊤ + 6 = 5 4
Backward-pass:
d y ^ d z 1 = d d z 1 ( z ⊤ w 2 + b 2 ) = w 2 , 1 = 7 d y ^ d z 2 = d d z 2 ( z ⊤ w 2 + b 2 ) = w 2 , 2 = 8 \begin{aligned}
\frac{d\hat{y}}{dz_1}&=\frac{d}{dz_1}(\boldsymbol{z}^{\top}\boldsymbol{w}_2+b_2)=w_{2,1}=7\\
\frac{d\hat{y}}{dz_2}&=\frac{d}{dz_2}(\boldsymbol{z}^{\top}\boldsymbol{w}_2+b_2)=w_{2,2}=8\\
\end{aligned} d z 1 d y ^ d z 2 d y ^ = d z 1 d ( z ⊤ w 2 + b 2 ) = w 2 , 1 = 7 = d z 2 d ( z ⊤ w 2 + b 2 ) = w 2 , 2 = 8 d y ^ d b 1 = d y ^ d z 1 d z 1 d b 1 + d y ^ d z 2 d z 2 d b 1 = 7 ⋅ I { x ⊤ w 1 , 1 + b 1 > 0 } + 8 ⋅ I { x ⊤ w 1 , 2 + b 1 > 0 } = 8 \begin{aligned}
\frac{d\hat{y}}{db_1}
&= \frac{d\hat{y}}{dz_1}\frac{dz_1}{db_1}
+\frac{d\hat{y}}{dz_2}\frac{dz_2}{db_1}\\
&= 7\cdot I\{\boldsymbol{x}^{\top}\boldsymbol{w}_{1,1}+b_1>0\}
+8\cdot I\{\boldsymbol{x}^{\top}\boldsymbol{w}_{1,2}+b_1>0\}
=8
\end{aligned} d b 1 d y ^ = d z 1 d y ^ d b 1 d z 1 + d z 2 d y ^ d b 1 d z 2 = 7 ⋅ I { x ⊤ w 1 , 1 + b 1 > 0 } + 8 ⋅ I { x ⊤ w 1 , 2 + b 1 > 0 } = 8
חישוב צעד העדכון
נציב את התוצאות שקיבלנו ואת η = 0.01 \eta=0.01 η = 0 . 0 1
b 1 ( t + 1 ) = b 1 ( t ) − 2 η N ∑ i ( f ( x ( i ) ; θ ( t ) ) − y ( i ) ) d d b 1 f ( x ( i ) ; θ ( t ) ) = 1 − 0.01 ( ( f ( x ( 1 ) ; θ ( t ) ) − y ( 1 ) ) d d b 1 f ( x ( 1 ) ; θ ( t ) ) + ( f ( x ( 2 ) ; θ ( t ) ) − y ( 2 ) ) d d b 1 f ( x ( 2 ) ; θ ( t ) ) ) = 1 − 0.01 ( ( 69 − 70 ) ⋅ 7 + ( 54 − 50 ) ⋅ 8 ) = 1 − 0.01 ⋅ 25 = 0.75 \begin{aligned}
\boldsymbol{b}_1^{(t+1)}
&=\boldsymbol{b}_1^{(t)}-\frac{2\eta}{N}\sum_i(f(\boldsymbol{x}^{(i)};\boldsymbol{\theta}^{(t)})-y^{(i)})\frac{d}{db_1}f(\boldsymbol{x}^{(i)};\boldsymbol{\theta}^{(t)})\\
&=1-0.01\left(
(f(\boldsymbol{x}^{(1)};\boldsymbol{\theta}^{(t)})-y^{(1)})\frac{d}{db_1}f(\boldsymbol{x}^{(1)};\boldsymbol{\theta}^{(t)})
+(f(\boldsymbol{x}^{(2)};\boldsymbol{\theta}^{(t)})-y^{(2)})\frac{d}{db_1}f(\boldsymbol{x}^{(2)};\boldsymbol{\theta}^{(t)})
\right)\\
&=1-0.01\left((69-70)\cdot7+(54-50)\cdot8\right)
=1-0.01\cdot25=0.75
\end{aligned} b 1 ( t + 1 ) = b 1 ( t ) − N 2 η i ∑ ( f ( x ( i ) ; θ ( t ) ) − y ( i ) ) d b 1 d f ( x ( i ) ; θ ( t ) ) = 1 − 0 . 0 1 ( ( f ( x ( 1 ) ; θ ( t ) ) − y ( 1 ) ) d b 1 d f ( x ( 1 ) ; θ ( t ) ) + ( f ( x ( 2 ) ; θ ( t ) ) − y ( 2 ) ) d b 1 d f ( x ( 2 ) ; θ ( t ) ) ) = 1 − 0 . 0 1 ( ( 6 9 − 7 0 ) ⋅ 7 + ( 5 4 − 5 0 ) ⋅ 8 ) = 1 − 0 . 0 1 ⋅ 2 5 = 0 . 7 5
תרגיל 10.2
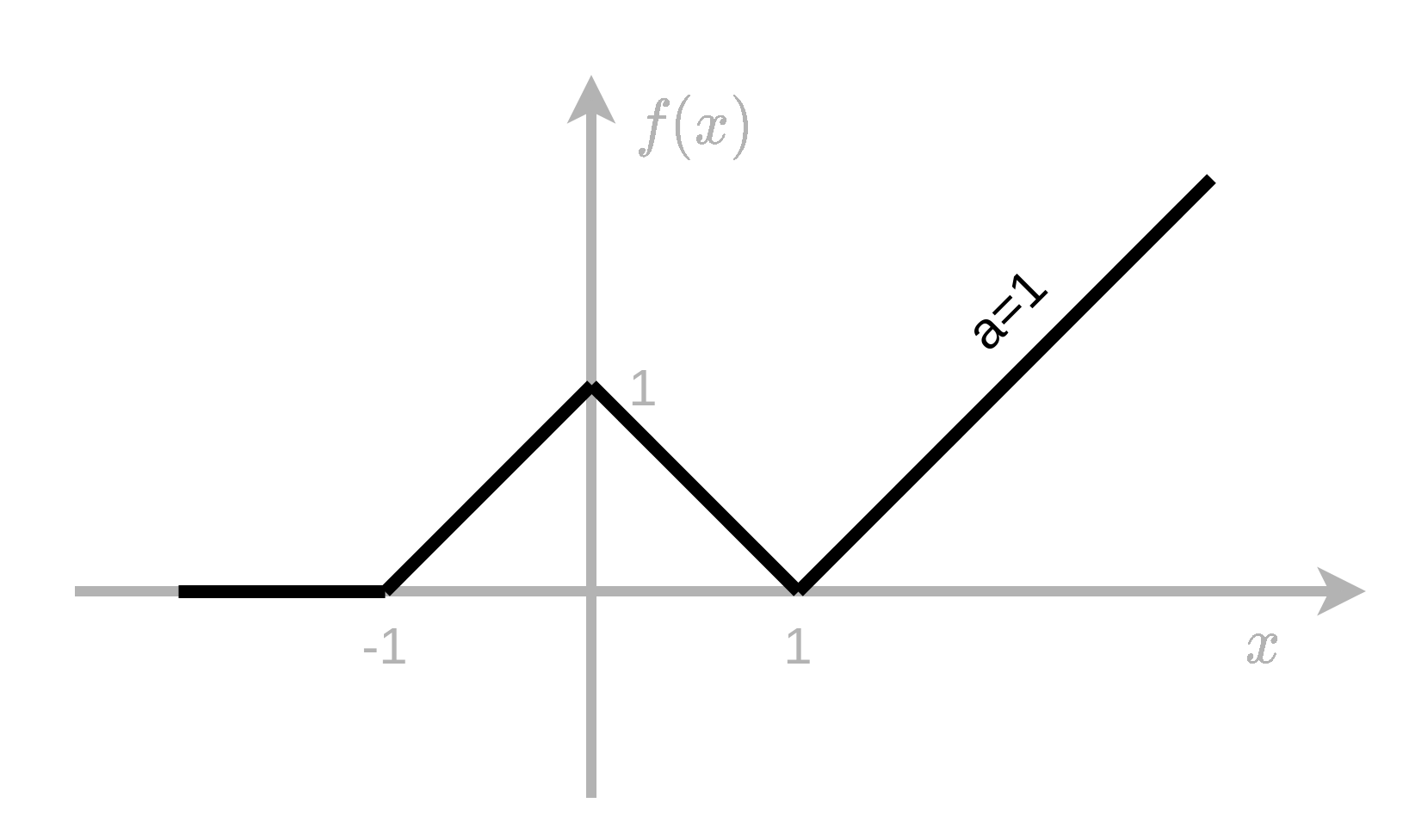
1) הראו כיצד ניתן לייצג את הפונקציה הבאה בעזרת רשת MLP עם פונקציית אקטיבציה מסוג ReLU.
שרטטו את הרשת ורשמו את הערכים של פרמטרי הרשת.
פתרון:
נבנה פונקציות רציפות ולינאריות למקוטעין, בעלות מספר סופי של קטעים, כמו זו בשבשאלה זו.
נשתמש בנויירונים בעלי פונקציית אקטיבציה מסוג ReLU הפועלים על קומבינציה לינארית של הכניסות.
נבנה פונקציה זו בעזרת MLP בעל שיכבה נסתרת אחת אשר דואגת לייצג את המקטעים השונים ושיכבת מוצא אשר דואגת לשיפוע בכל מקטע.
נקבע את קבוע הbias בכל נוירון כך שהשינוי בשיפוע של ה ReLU (ב x = 0 x=0 x = 0
h 1 , 1 ( x ) = max ( x + 1 , 0 ) h 1 , 2 ( x ) = max ( x , 0 ) h 1 , 3 ( x ) = max ( x − 1 , 0 ) \begin{aligned}
h_{1,1}(x)=\max(x+1,0) \\
h_{1,2}(x)=\max(x,0) \\
h_{1,3}(x)=\max(x-1,0) \\
\end{aligned} h 1 , 1 ( x ) = max ( x + 1 , 0 ) h 1 , 2 ( x ) = max ( x , 0 ) h 1 , 3 ( x ) = max ( x − 1 , 0 )
כעת נדאג לשיפועים. נסתכל על מקטעים משמאל לימין.
המקטע השמאלי ביותר הינו בעל שיפוע 0 ולכן הוא כבר מסודר, שכן כל הפונקציות אקטיבציה מתאפסות באיזור זה.
המקטע [ − 1 , 0 ] [-1,0] [ − 1 , 0 ]
המקטע [ 0 , 1 ] [0,1] [ 0 , 1 ] − 2 -2 − 2 − 1 -1 − 1 − 2 -2 − 2
באופן דומה ניתן לנוירון השלישי משקל של 2 2 2
סה"כ קיבלנו כי h 2 ( z 1 , z 2 , z 3 ) = z 1 − 2 z 2 × 2 z 3 h_2(z_1,z_2,z_3)=z_1-2z_2\times2z_3 h 2 ( z 1 , z 2 , z 3 ) = z 1 − 2 z 2 × 2 z 3
2) האם ניתן לייצג במדוייק את הפונקציה f ( x ) = x 2 + ∣ x ∣ f(x)=x^2+\lvert x\rvert f ( x ) = x 2 + ∣ x ∣
מכיוון ש:
נוירון בעל פונקציית הפעלה מסוג ReLU מייצג פונקציה רציפה ולינארית למקוטעין.
כל הרכבה או סכימה של פונקציות רציפות ולינאריות למקוטעין יצרו תמיד פונקציה חדשה שגם היא רציפה ולינארית למקוטעין.
מכאן, שנוכל באמצעת נוירונים מסוג ReLU לייצג רק פונקציות רציפות ולנאריות למקוטעין.
מכיוון שx 2 x^2 x 2
תרגיל מעשי - איבחון סרטן שד עם MLP
נסתכל שוב על הבעיה של איבחון סרטן שד על סמך תצלום מיקרוסקופי של ריקמה.
diagnosis
radius_mean
texture_mean
perimeter_mean
area_mean
smoothness_mean
compactness_mean
concavity_mean
0
M
17.99
10.38
122.8
1001
0.1184
0.2776
0.3001
1
M
20.57
17.77
132.9
1326
0.08474
0.07864
0.0869
2
M
19.69
21.25
130
1203
0.1096
0.1599
0.1974
3
M
11.42
20.38
77.58
386.1
0.1425
0.2839
0.2414
4
M
20.29
14.34
135.1
1297
0.1003
0.1328
0.198
5
M
12.45
15.7
82.57
477.1
0.1278
0.17
0.1578
6
M
18.25
19.98
119.6
1040
0.09463
0.109
0.1127
7
M
13.71
20.83
90.2
577.9
0.1189
0.1645
0.09366
8
M
13
21.82
87.5
519.8
0.1273
0.1932
0.1859
9
M
12.46
24.04
83.97
475.9
0.1186
0.2396
0.2273
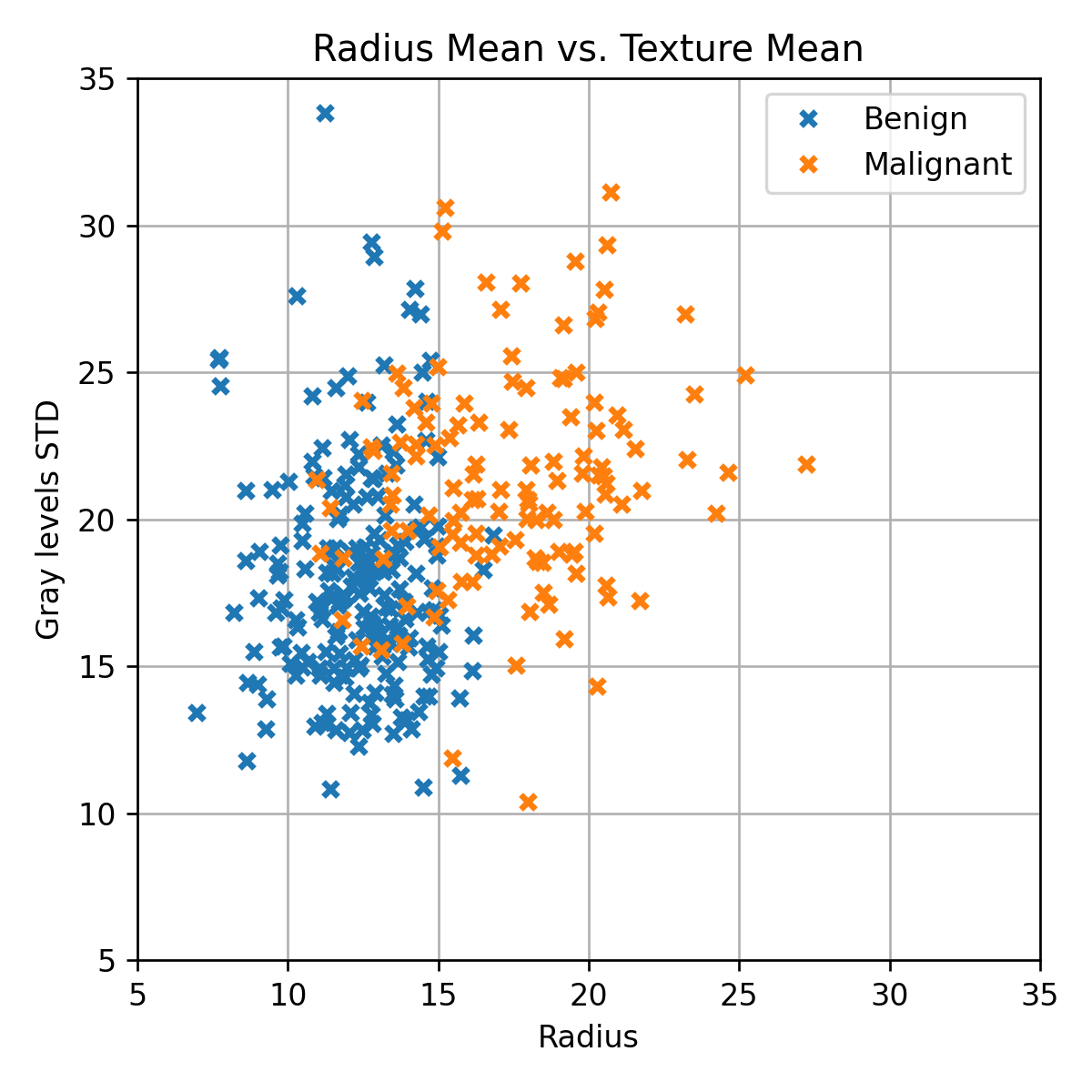
נתחיל שוב בביצוע איבחון על סמך שתי העמודות הראשונות בלבד. אנו עושים זאת כמובן רק בכדי שנוכל להציג את הבעיה בגרף דו מימדי.
נפצל אותו שוב ל 60% train / 20% validation / 20% test.
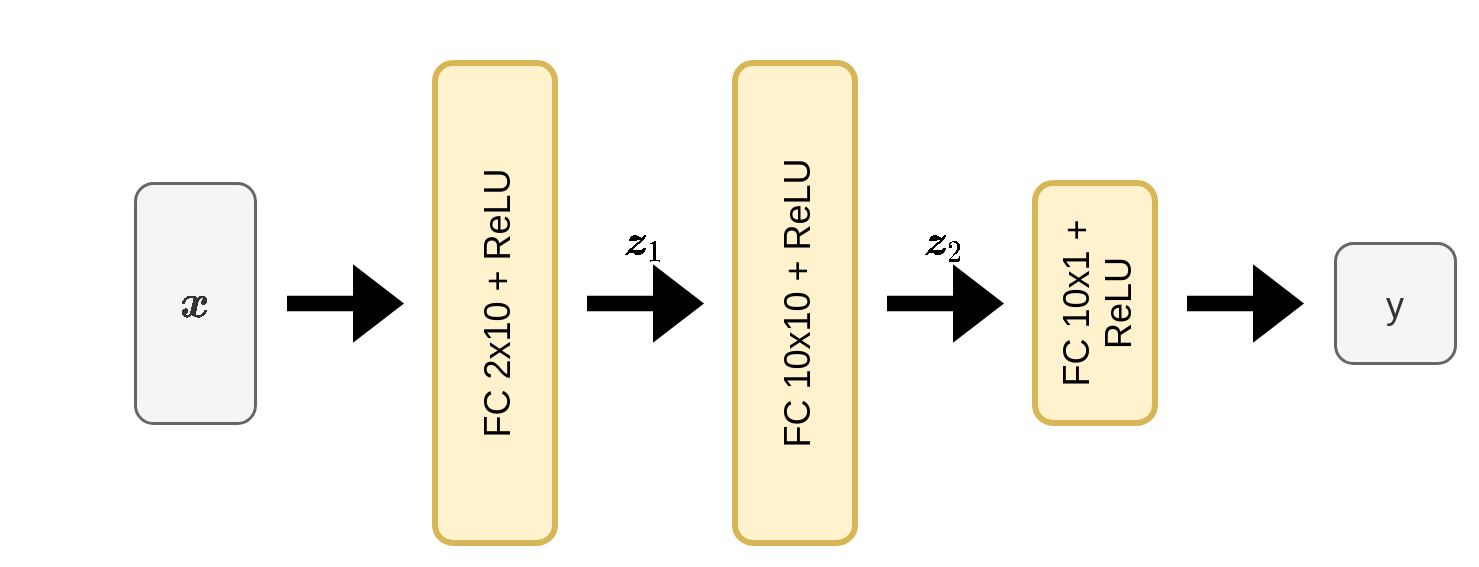
וננסה להתאים לו את המודל הבא:
FC 2x10 מציין שכבה של fully connected שבכניסה אליה יש וקטור באורך 2 וביציאה יש וקטור ברוחב 10
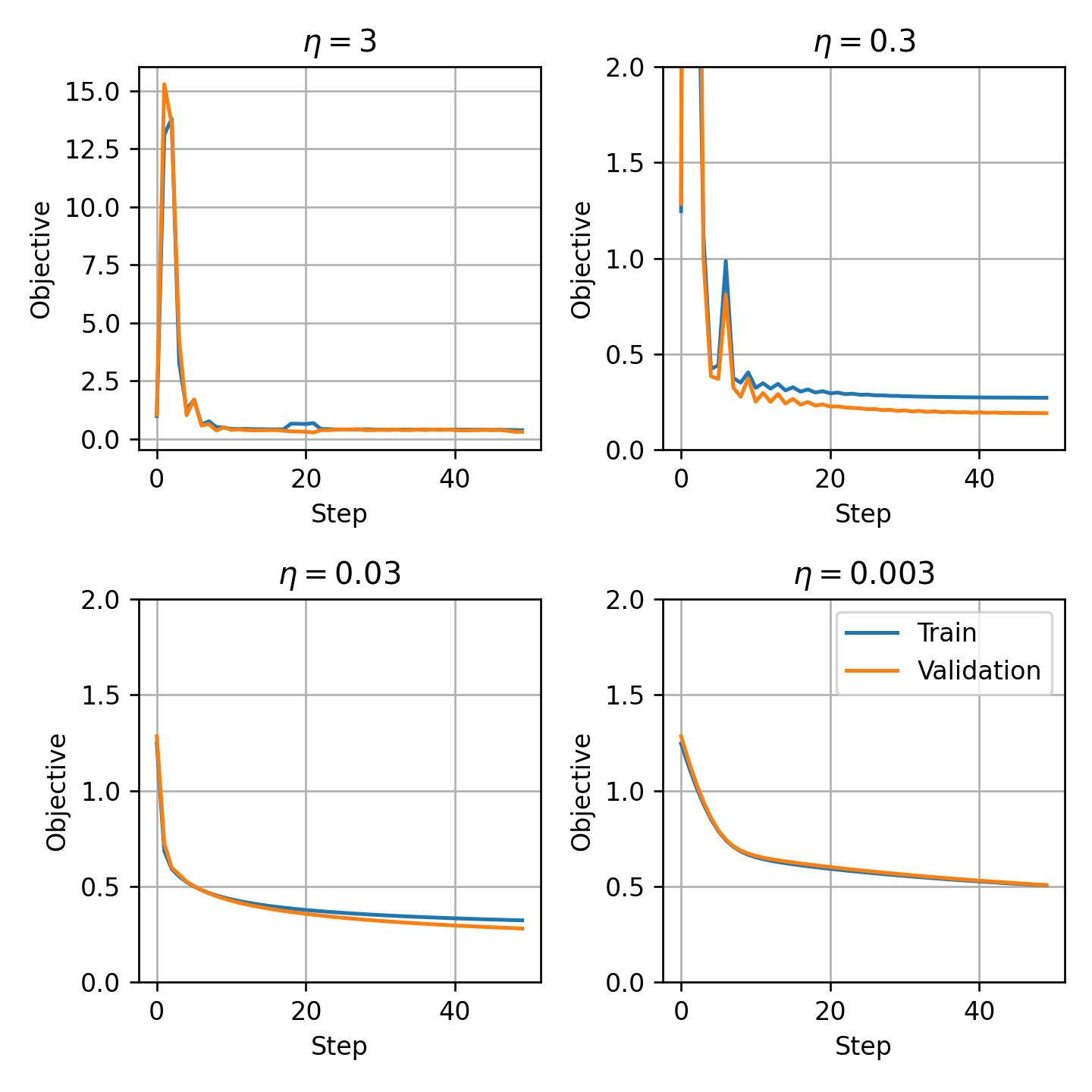
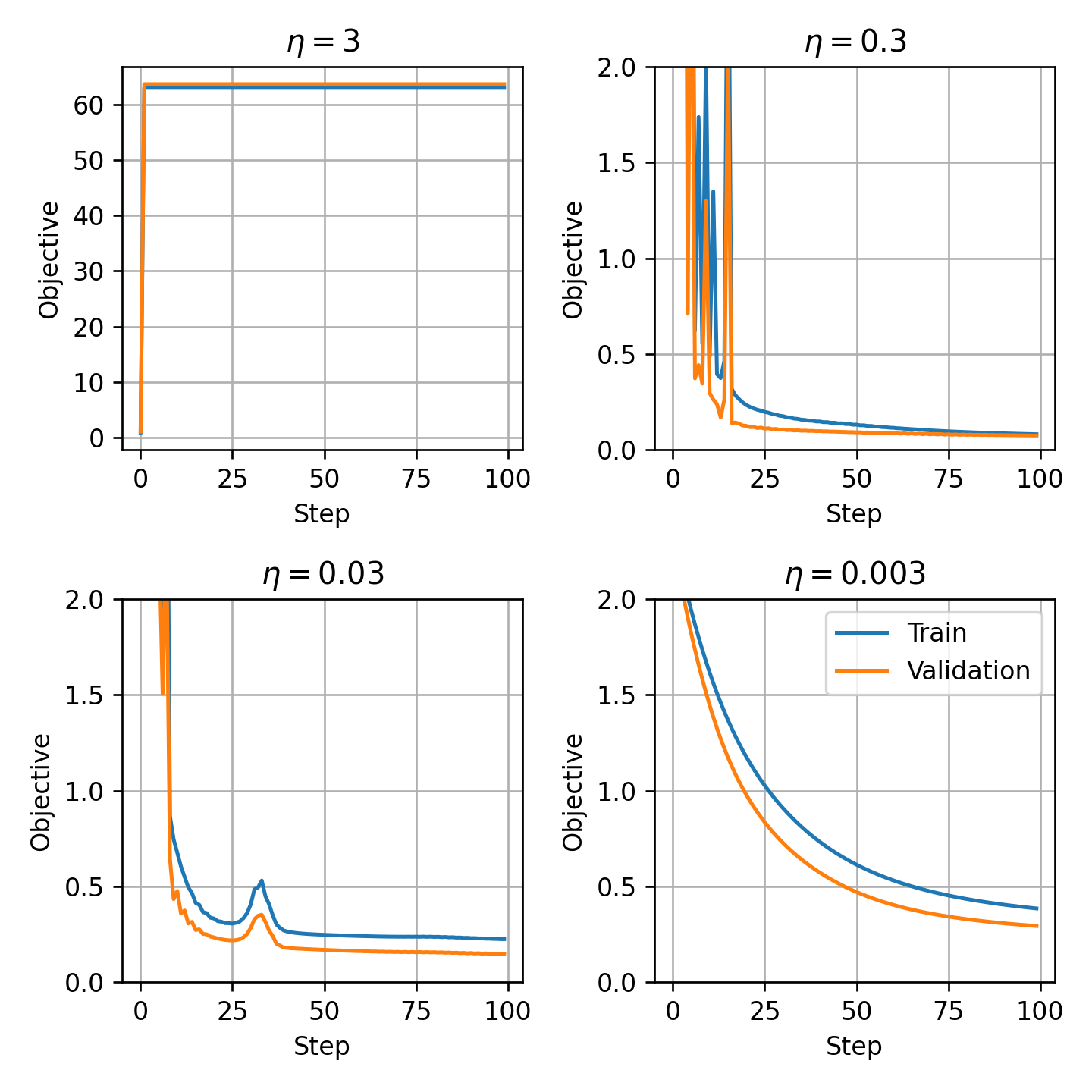
נריץ את אלגוריתם ה gradient descent למספר קטן של צעדים כדי לבחור את קצב הלימוד η \eta η
בדומה לתרגול הקודם, אנו נבחר את הערך הגדול ביותר שבו הגרף יורד בצורה מונוטונית שבמקרה זה הינו η = 0.03 \eta=0.03 η = 0 . 0 3
נריץ כעת האלגוריתם למספר גדול של צעדים:
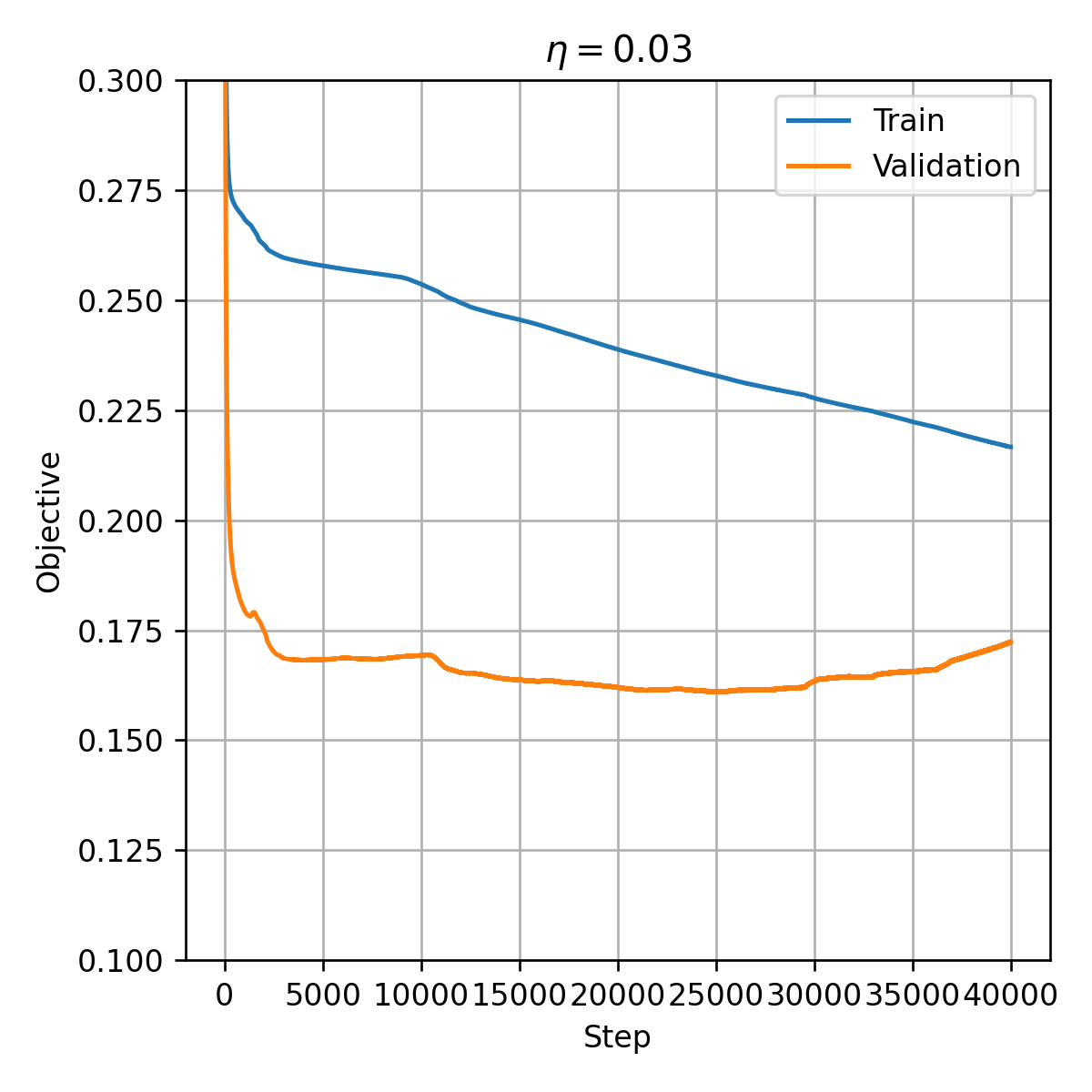
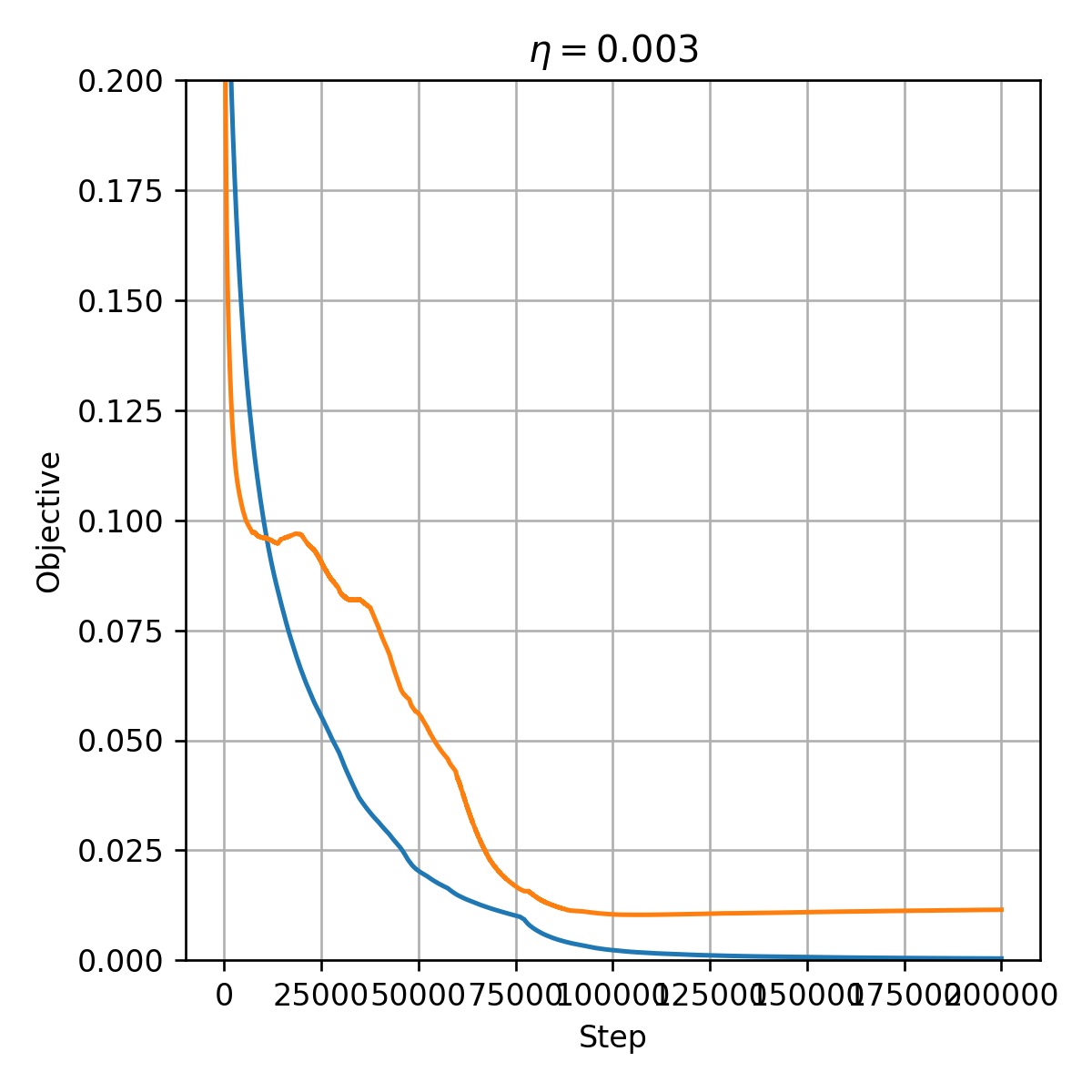
החל מנקודה מסויימת, ה- objective על ה validation set מתחיל לעלות.
הסיבה לכך היא תופעת ה- overfitting.
ניתן להימנע מכך על ידי עצירת האלגוריתם לפני שהוא מתכנס. פעולה זו מכונה early stopping.
נשתמש בפרמטרים מהצעד עם הערך של ה objective הנמוך ביותר על ה validation, במקרה זה זהו הצעד ה 25236.
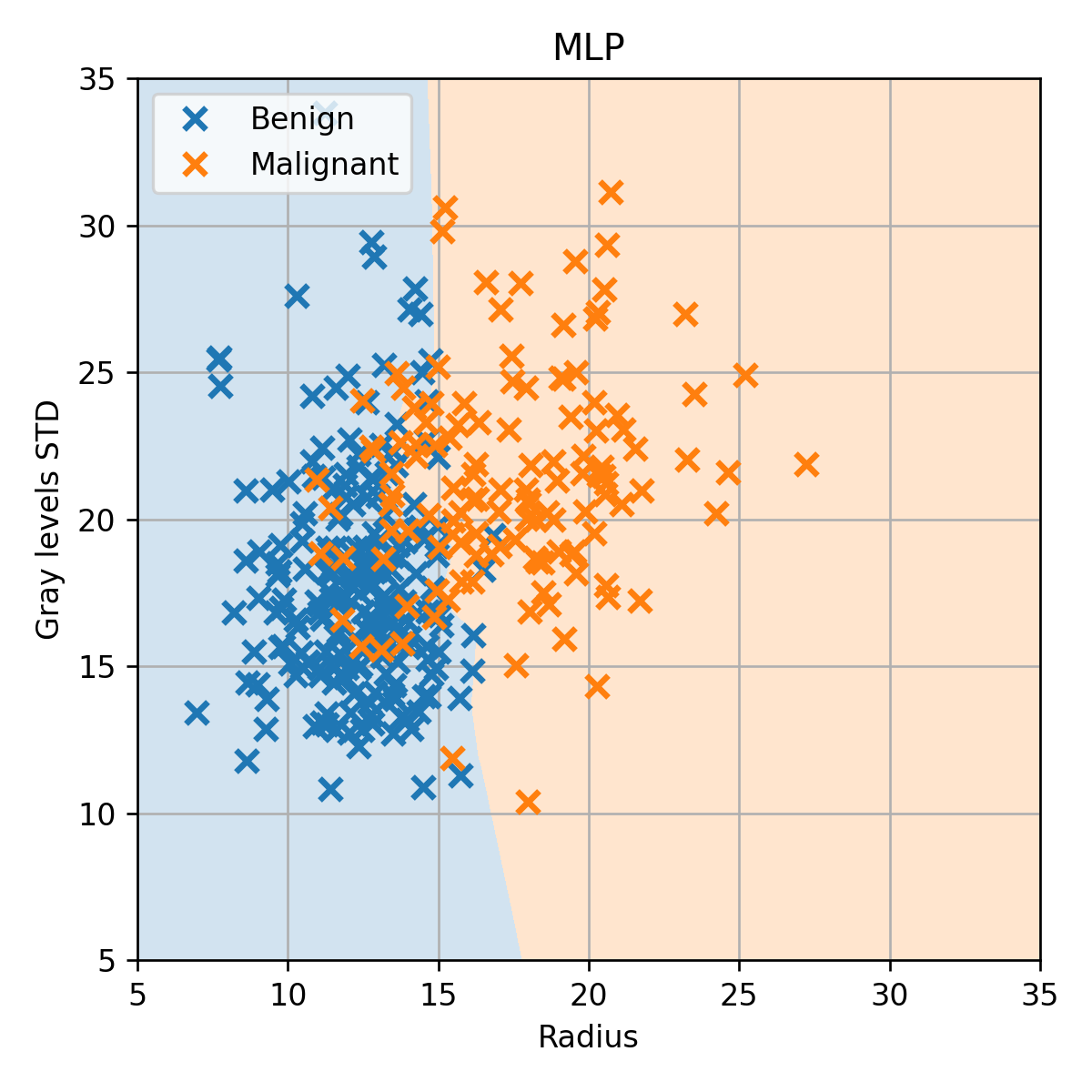
החזאי המתקבל ממודל זה הינו:
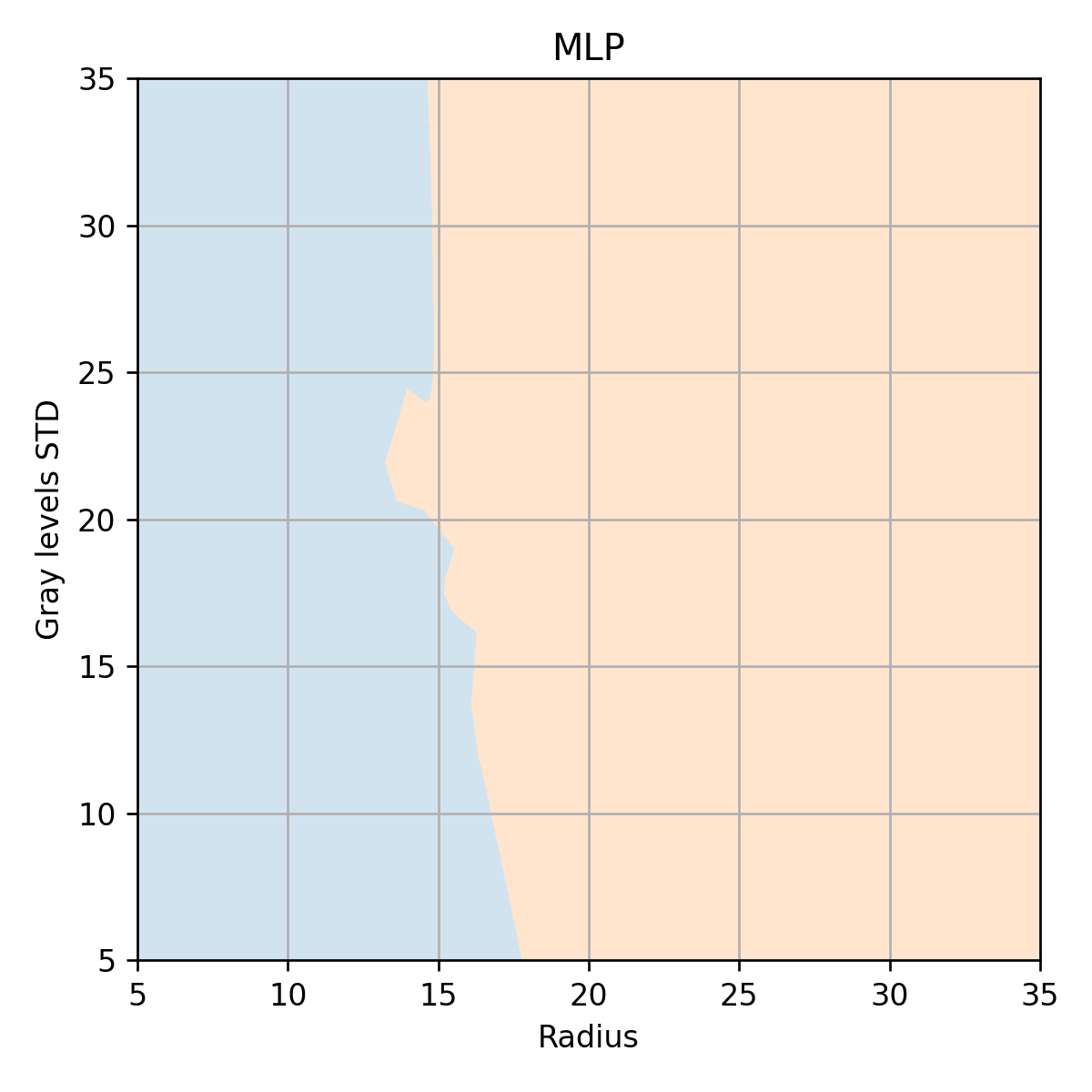
נשרטט גרף זה ללא הדגימות על מנת לראות את קו ההפרדה בין שני השטחים
הרשת מצליחה לייצר חזאי עם קו הפרדה מורכב בהשוואה ל LDA, QDA ו- linear logistic regression.
ביצועי חזאי זה על ה valudation set הינם: 0.08. ביצועים אלו דומים לביצועים של QDA ו linear logistic regresssion.
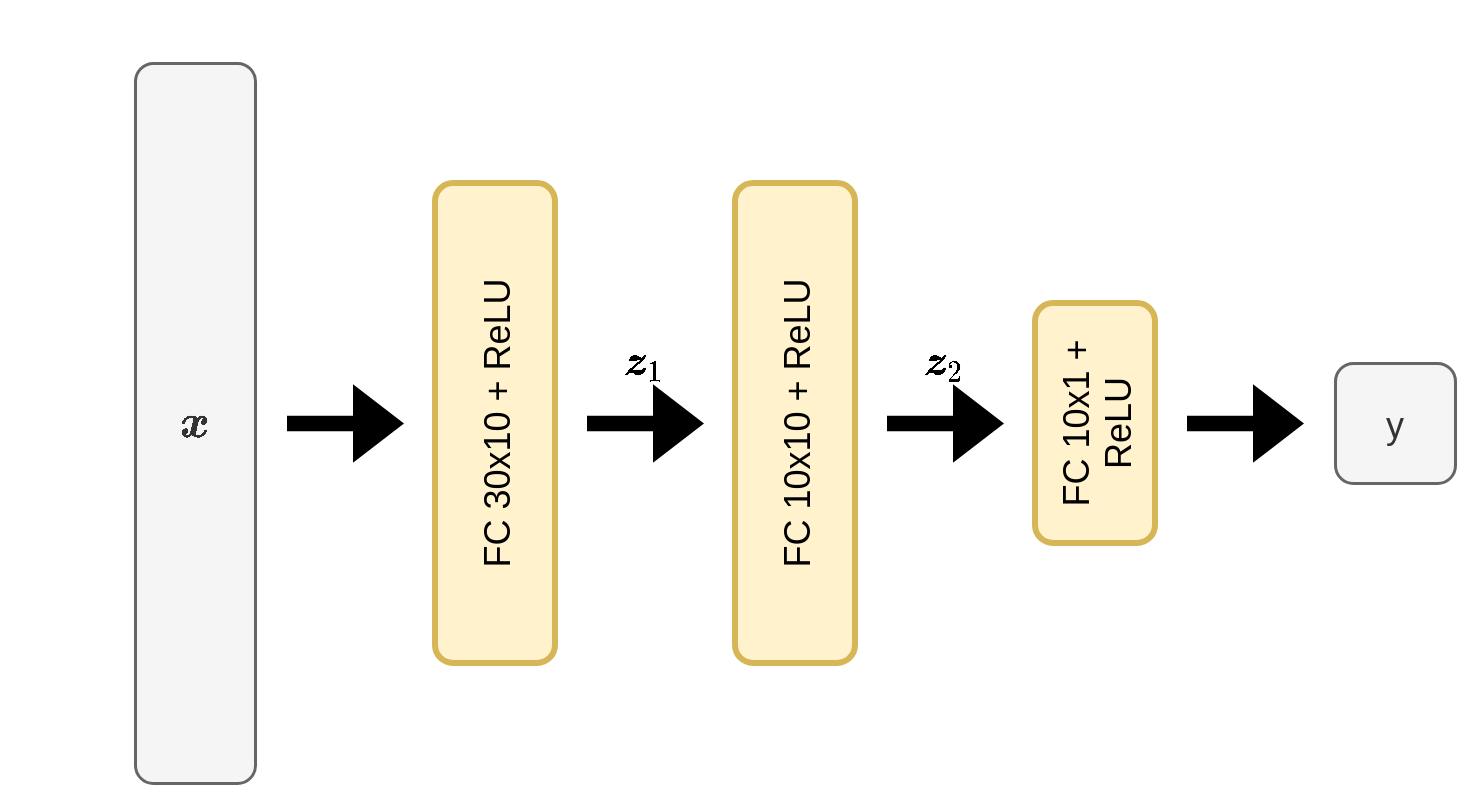
שימוש בכל 30 העמודות במדגם
נעבור כעת להשתמש בכל 30 העמודות במדגם. לשם כך נשתמש ברשת הבאה:
נחפש שוב את הערך המתאים ביותר של η \eta η
במקרה זה נבחר את η = 0.003 \eta=0.003 η = 0 . 0 0 3