הערה: בפרק זה נעסוק בסיווג בינארי ונסמן את התוויות של שתי המחלקות ב 1 ו −1.
תזכורת - גאומטריה של המישור
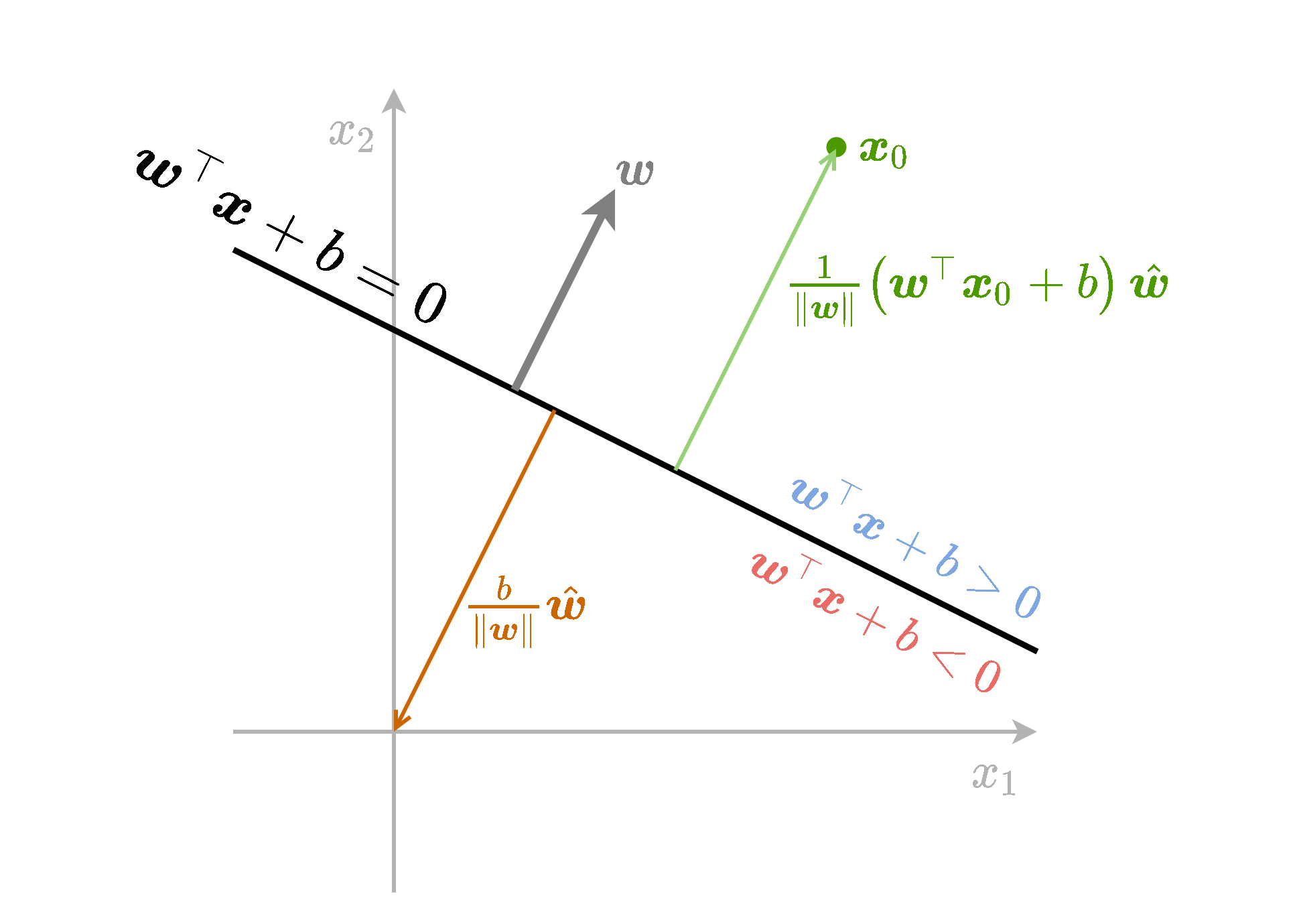
דרך נוחה לתאר מישור במרחב (ממימד כלשהו) היא על ידי משוואה מהצורה w⊤x+b=0. מישור שכזה מחלק את המרחב לשניים ומגדיר צד חיובי ושלילי של המרחב. נתאר מספר תכונות של הצגה זו:
w הוא הנורמל למישור אשר מגדיר את את האוריינטציה שלו וגם את הצד החיובי.
המרחק של המישור מהראשית הינו ∥w∥b. הסימן של גודל זה מציין איזה צד של המישור נמצאת הראשית.
המרחק של נקודה כל שהיא x0 מהמישור הינה ∥w∥1(w⊤x0+b). הסימן של גודל זה מציין את הצד של המישור בו נמצאת הנקודה.
בעבור מישור נתון כל שהוא w ו b מוגדרים עד כדי קבוע. זאת אומרת שהמישור אינווריאנטי (לא משתנה) תחת שינוי של פרמטרים מהצורה של: w→αw,b→αb.
מסווג לינארי
מסווג לינארי הוא מסווג מהצורה של
h(x)=sign(w⊤x+b)={1−1w⊤x+b>0else
עם w ו b כלשהם.
זאת אומרת שמסווג מחלק את המרחב לשני צידיו של המישור w⊤x+b=0 המכונה מישור ההפרדה.
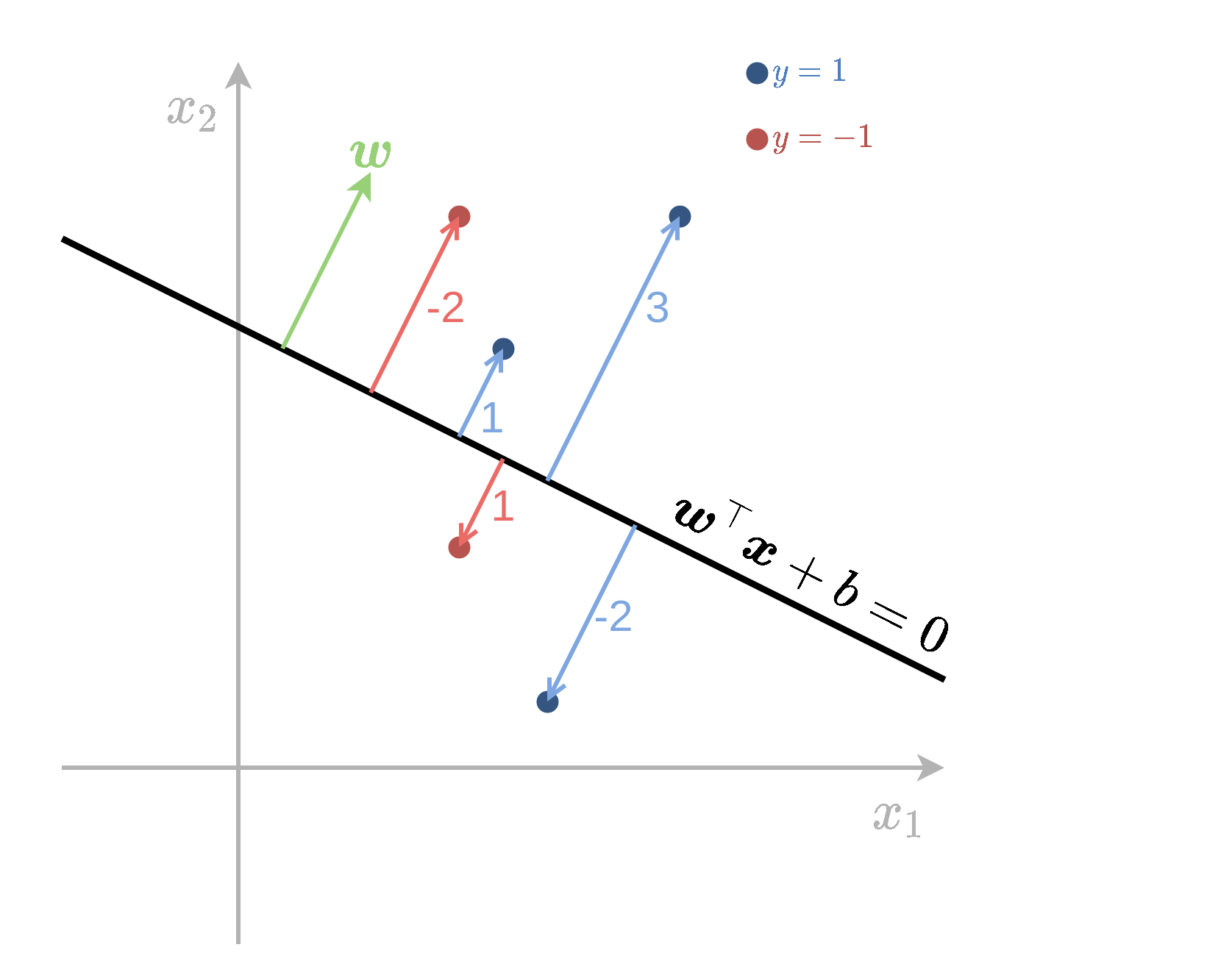
Signed distance (מרחק מסומן)
נסתכל על בעיית סיווג בינארית עם תוויות y=±1. בעבור משטח הפרדה כלשהו נגדיר את ה signed distance של דגימה כלשהי ממשטח ההפרדה באופן הבא:
d=∥w∥1(w⊤x+b)y
זהו המרחק של נקודה מהמישור כאשר המרחק של נקודות עם תווית y=1 הוא חיובי כאשר הן בצד החיובי של המישור ושלילי אחרת והפוך לגבי נקודות עם תווית y=−1.
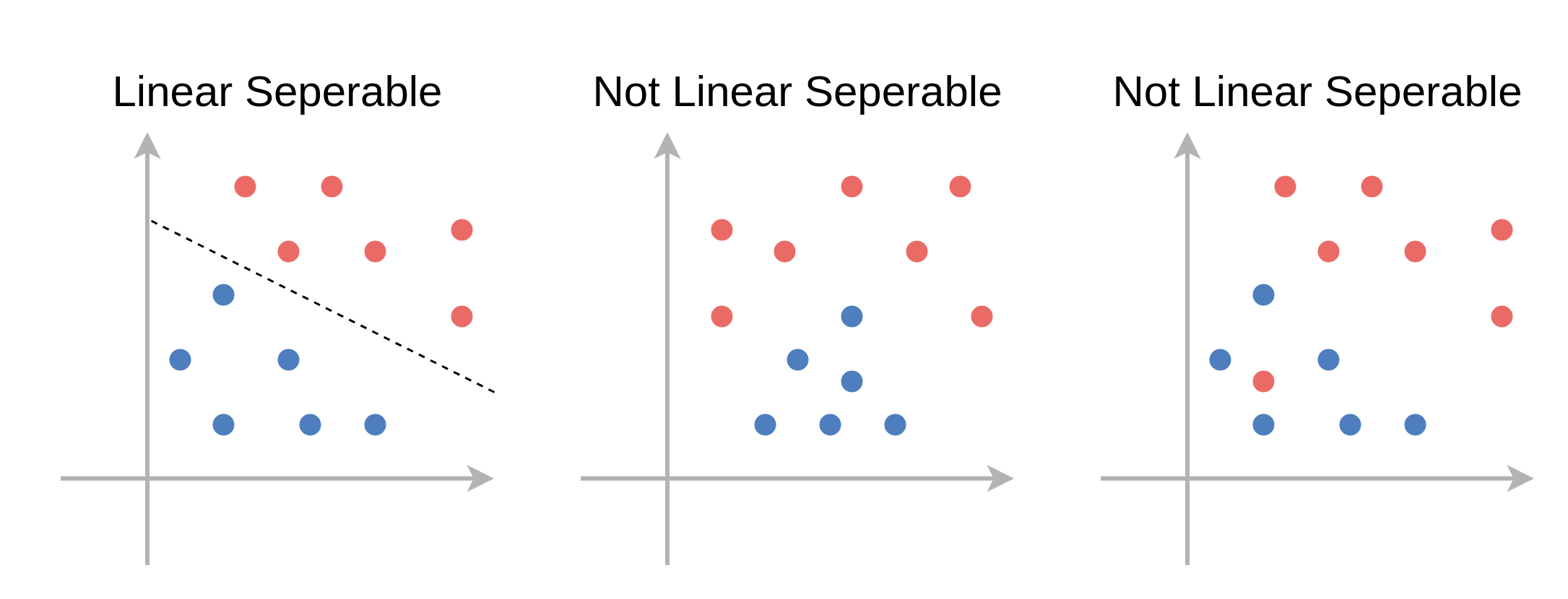
פרידות ליניארית (linear separability)
בבעיות של סיווג בינארי, אנו נאמר על מדגם שהוא פריד לינארית אם קיים מסווג לינארי אשר מסווג את המדגם בצורה מושלמת (בלי טעויות סיווג).
כאשר המדגם פריד לינארית יהיה יותר ממסווג לינארי אחד אשר יכול לסווג בצורה מושלמת את המדגם.
Support Vector Machine (SVM)
SVM הוא אלגוריתם דיסקרימינטיבי לסיווג בינארי אשר מחפש מסווג לינארי אשר יסווג בצורה טובה את המדגם.
Hard SVM
Hard SVM מתייחס למקרה שבו המדגם הוא פריד לינארית. באלגוריתם זה נחפש את המסווג הליניארי אשר בעבורו ה signed distance המינימאלי על ה train set הוא המקסימאלי:
w∗,b∗=w,bargmaximin{∥w∥1(w⊤x(i)+b)y(i)}
ניתן להראות כי במקרה שבו המדגם פריד לינארי, בעיה זו שקולה לבעיית האופטימיזציה הבאה:
w∗,b∗=w,bargmins.t.21∥w∥2y(i)(w⊤x(i)+b)≥1∀i
בעיית אופטימיזציה זו מכונה הבעיה הפרימאלית.
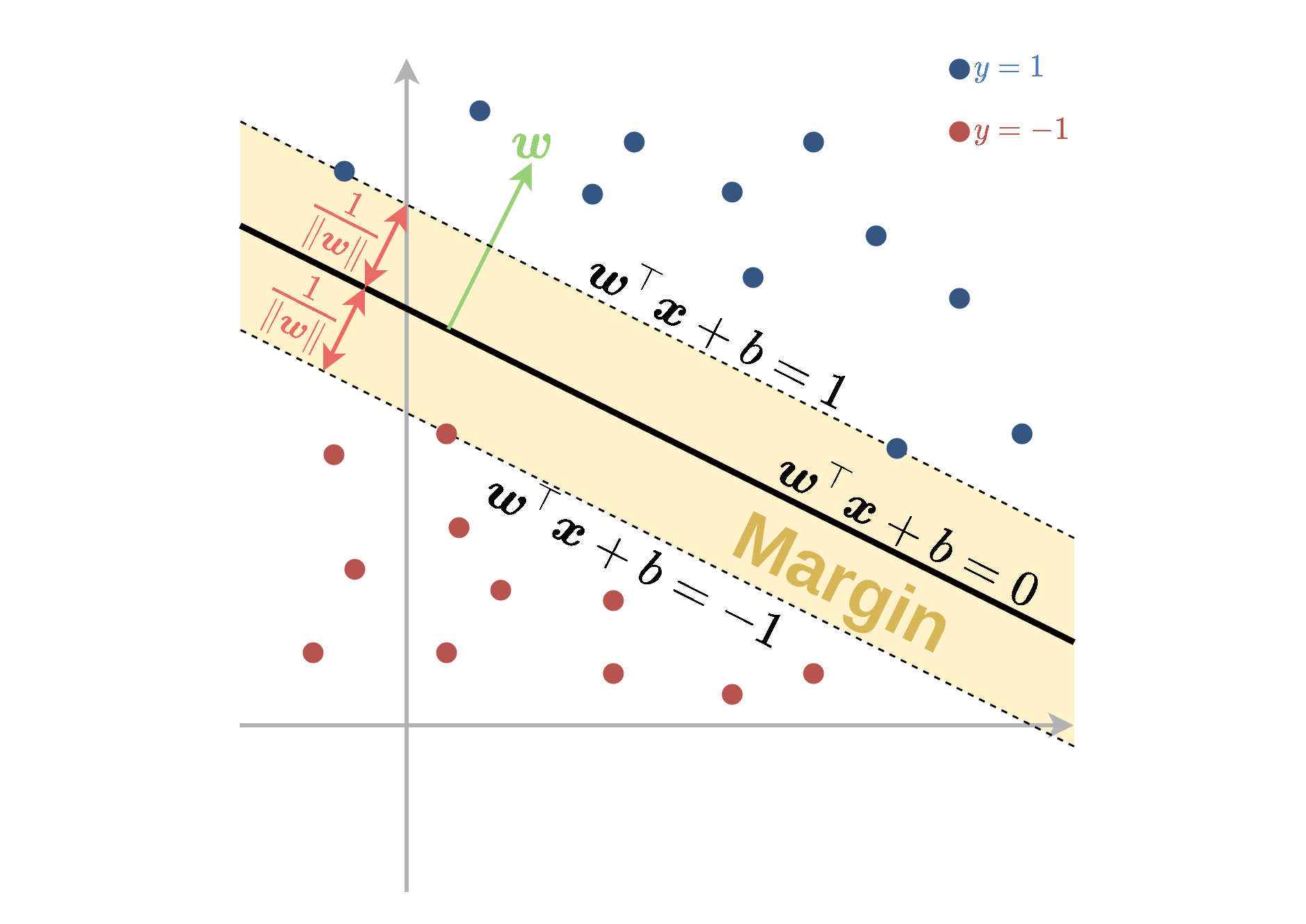
Margin
בכדי להבין את המשמעות של בעיית האופטימיזציה שקיבלנו נגדיר את המושג שוליים (margin) של מסווג. האיזור של ה margin מוגדר כאיזור סביב משטח ההפרדה אשר נמצא בתחום:
1≥w⊤x+b≥−1
הרוחב של איזור זה נקבע על פי הגודל של הוקטור w ושווה ל ∥w∥2.
האילוץ y(i)(w⊤x(i)+b)≥1, אשר מופיע בבעיית האופטימיזציה הפרימאלית, דורש למעשה שכל הנקודות יסווגו נכונה וימצאו מחוץ ל margin. בעיית האופטימיזציה מחפשת את הפרמטרים של המישור בעל ה margin הגדול ביותר אשר מקיים תנאי זה.
Support Vectors
בעבור פתרון מסויים של בעיית האופטימיזציה, ה support vectors מוגדרים כנקודות אשר יושבות על השפה של ה margin, נקודות אלו מקיימות y(i)(w⊤x(i)+b)=1. אלו הנקודות אשר ישפיעו על הפתרון של בעיית האופטימיזציה, זאת אומרת שהסרה או הזזה קטנה של נקודות שאינןsupport vectors לא תשנה את הפתרון.
הבעיה הדואלית
דרך שקולה נוספת לרישום בעיית האופטימיזציה הינה על ידי הגדרת N משתני עזר נוספים {αi}i=1N. בעזרת משתנים אלו ניתן לרשום את בעיית האופטימיזציה באופן הבא:
את b ניתן לחשב על ידי בחירת support vector אחד ולחלץ את b מתוך y(i)(w⊤x(i)+b)=1.
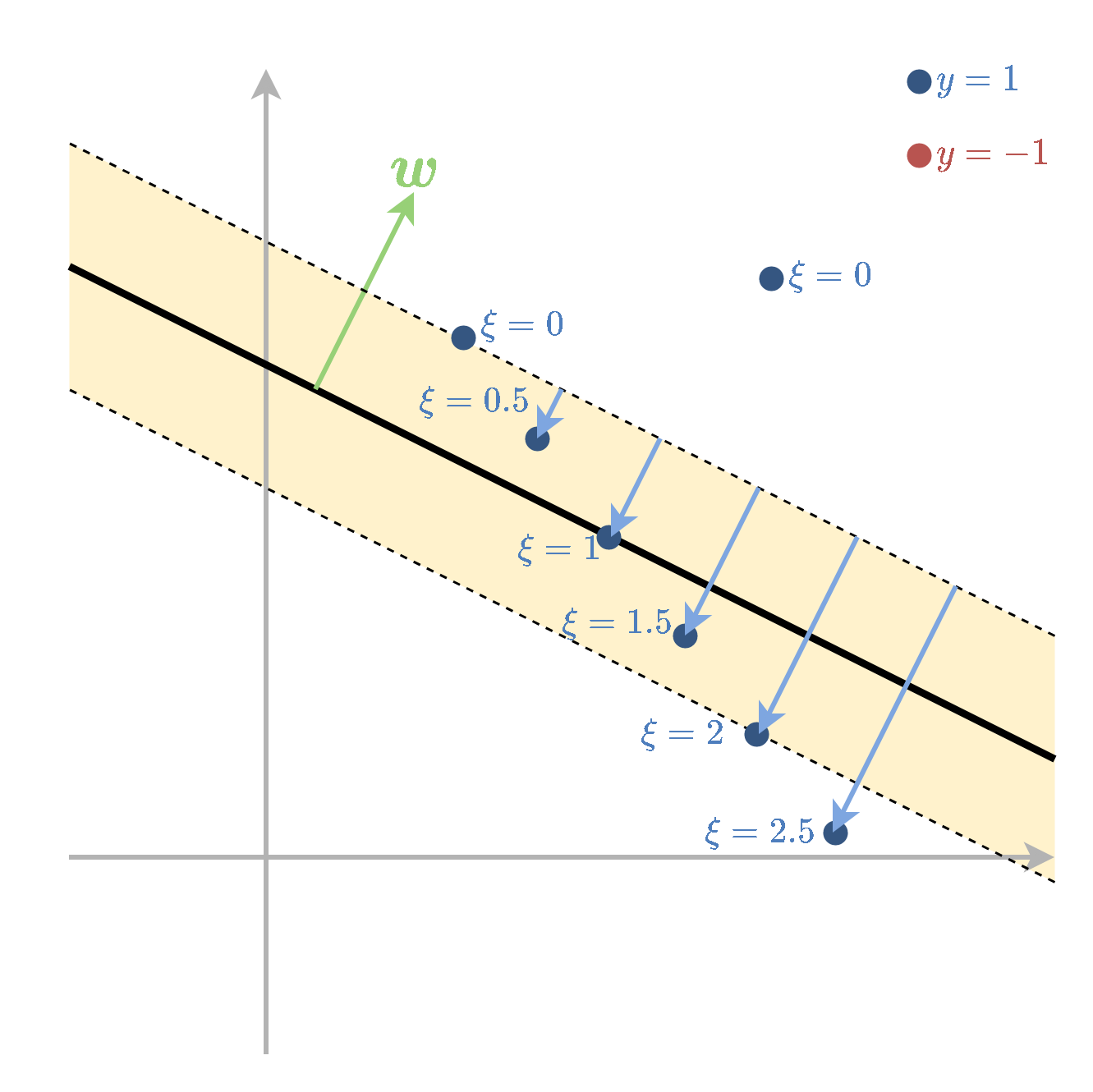
Soft SVM
Soft SVM מתייחס למקרה שבו המדגם אינו פריד לינארית. במקרה זה עדיין מגדירים את ה margin בצורה דומה אך מאפשרים למשתנים להיכנס לתוך ה margin ואף לחצות אותו לצד הלא נכון של מישור ההפרדה. על כל חריגה כזו משלמים קנס ב objective שאותו מנסים למזער. את החריגה של הדגימה ה i נסמן ב ∥w∥1ξi. לנקודות שהן בצד הנכון של המישור ומחוץ ל margin יהיה ξi = 0 .
המשתנים ξi נקראים slack variables ובעיית האופטימיזציה הפרימאלית תהיה:
ה support vectors מוגדרות להיות הנקודות שמקיימות y(i)(w⊤x(i)+b)=1−ξi
תכונות:
.
.
.
נקודות שמסווגות נכון ורחוקות מה margin
y(i)(w⊤x(i)+b)>1
αi=0
נקודות על ה margin (שהם support vectors)
y(i)(w⊤x(i)+b)=1
0≤αi≤C
נקודות שחורגות מה margin (גם support vectors)
y(i)(w⊤x(i)+b)=1−ξi
αi=C
פונקציות גרעין
מאפיינים: תזכורת
נוכל תמיד להחליף את וקטור המשתנים x שעליו פועל האלגוריתם בוקטור חדש xnew=Φ(x), כאשר Φ היא פונקציה אשר נבחרה מראש ונקראת פונקציית המאפיינים שכן היא מחלצת מאפיינים רלוונטים מתוך x שבהם נשתמש.
פונקציות גרעין
במקרים רבים החישוב של Φ(x) יכול להיות מסובך, אך קיימת דרך לחשב בצורה יעילה את הפונקציה K(x1,x2)=Φ(x1)⊤Φ(x2) אשר נקראת פונקציית גרעין. ישנם מקרים שבהם וקטור המאפיינים יהיה אין סופי.
ישנם קריטריונים תחתם פונקציה מסויימת K(x1,x2) היא פונקציית גרעין בעבור וקטור מאפיינים מסויים. בקורס זה לא נכנס לתנאים אלו. נציג שתי פונקציות גרעין נפוצות:
גרעין גאוסי: K(x1,x2)=exp(−2σ2∥x1−x2∥22) כאשר σ פרמטר שיש לקבוע.
גרעין פולינומיאלי: K(x1,x2)=(1+x1⊤x2)p כאשר p≥1 פרמטר שיש לקבוע.
פונקציות המאפיינים שמתאימות לגרעינים אלו הן מסורבלות לכתיבה ולא נציג אותן כאן.
Kernel Trick in SVM
הרעיון ב kernel trick הינו להשתמש ב SVM עם מאפיינים מבלי לחשב את Φ באופן ישיר על ידי שימוש בפונקציית גרעין. בעבור פונקציית מאפיינים Φ עם פונקציית גרעין K הבעיה הדואלית של SVM הינה:
כך שגם בשלב החיזוי ניתן להשתמש בפונקציית הגרעין בלי לחשב את Φ באופן מפורש.
תרגיל 6.1 - 2 Support Vectors
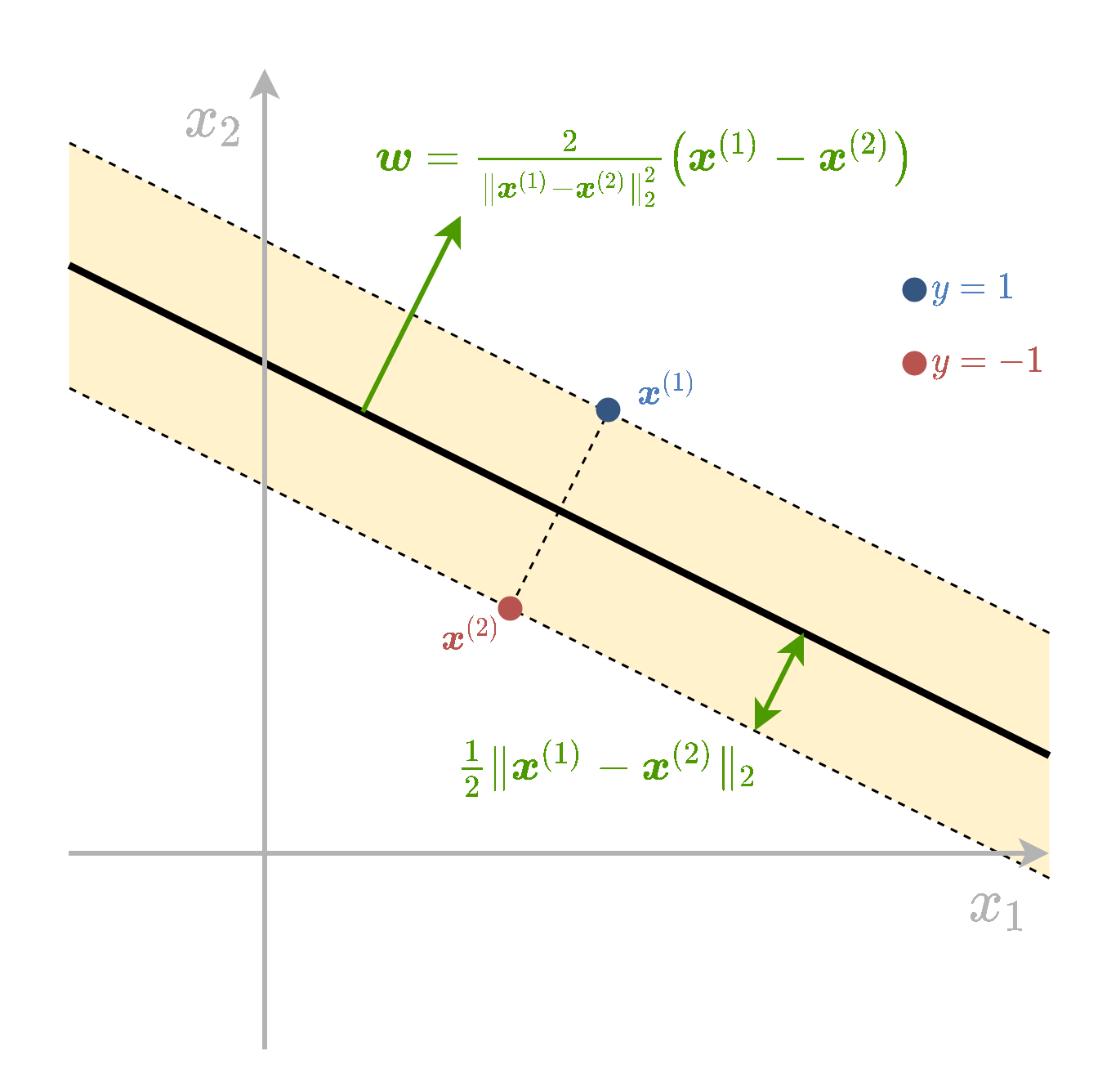
בשאלה זו נראה שבעבור מדגם המכיל 2 נקודות, אחת מכל מחלקה, הפתרון של בעיית hard SVM יהיה - מישור הפרדה שיעבור בדיוק במרכז בין 2 הנקודות, ויהיה ניצב לוקטור המחבר את שתי הנקודות.
במקרה שבו יש רק שתי נקודות, אחת מכל מחלקה, שתיהן בהכרח יהיו support vectors ויקיימו y(i)(w⊤x(i)+b)=1. נניח בלי הגבלת הכלליות ש y(1)=1 ו y(2)=−1. שני האילוצים שנקודות אלו מגדירות הם:
נוכל להשתמש באילוץ השני ולכתוב בעזרתו את בעיית האופטימיזציה רק על w:
w∗=wargmins.t.21∥w∥2w⊤(x(1)−x(2))=2
בעיה זו מחפשת את ה w בעל האורך המינימאלי כך שהמכפלה הסקלרית שלו עם (x(1)−x(2)) היא 2. הוקטור הזה יהיה וקטור בכיוון של (x(1)−x(2)) ובאורך של 2/∥x(1)−x(2)∥2 ולכן w הינו:
w=∥x(1)−x(2)∥222(x(1)−x(2))
תרגיל 6.2 - Hard SVM
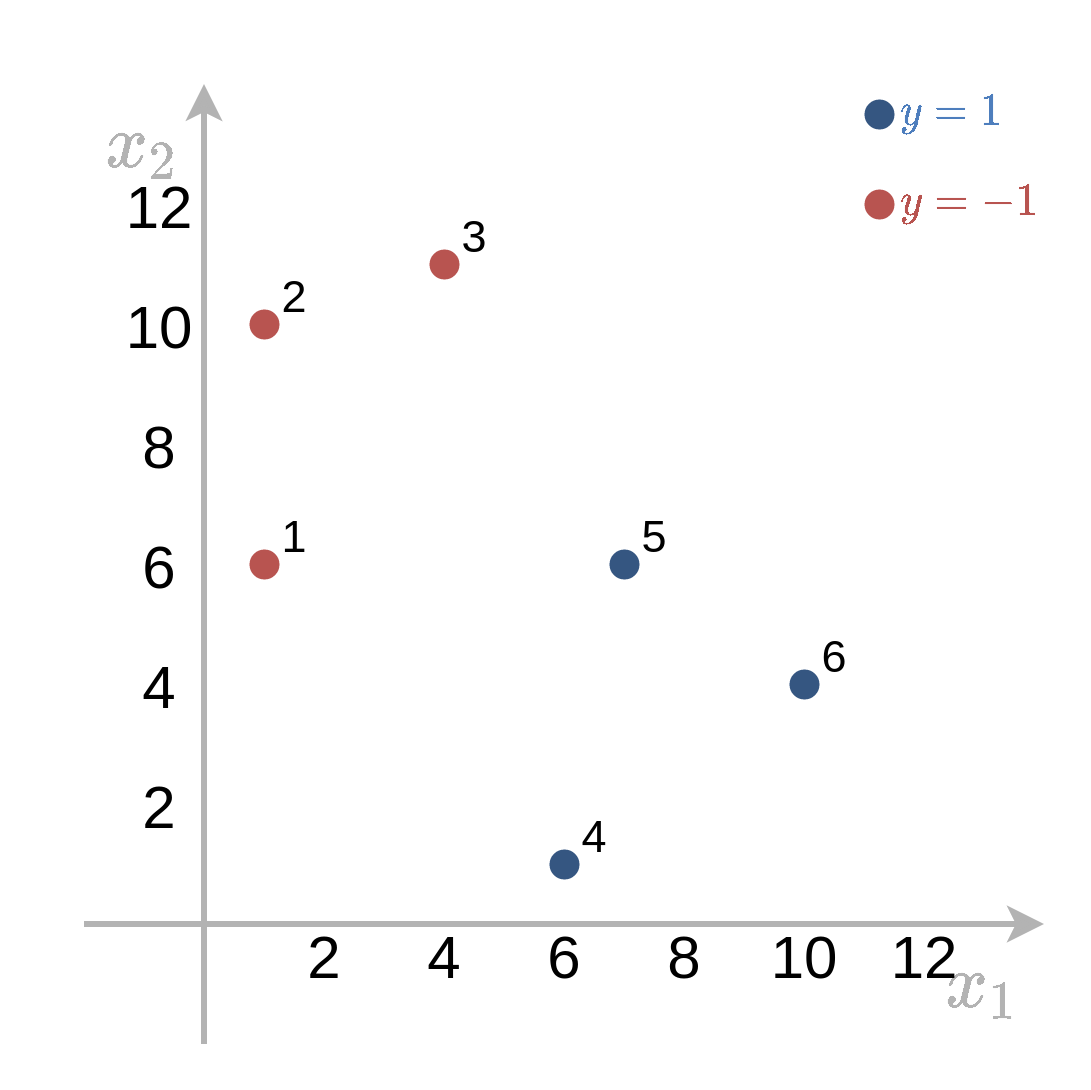
נתון המדגם הבא:
.
1
2
3
4
5
6
y
-1
-1
-1
1
1
1
x1
1
1
4
6
7
10
x2
6
10
11
1
6
4
1) מצא את מסווג ה Hard SVM המתאים למדגם זה. מי הם וקטורי התמיכה?
2) מבלי לפתור את הבעיה הדואלית. אלו ערכים של {αi} בהכרח יתאפסו?
3) מהו הרוחב של ה margin של הפתרון?
פתרון 6.2
1)
בעיית האופטימיזציה הפרימאלית אותה נרצה לפתור הינה:
w∗,b∗=w,bargmins.t.21∥w∥2y(i)(w⊤x(i)+b)≥1∀i
באופן כללי לפתור בעיות מסוג זה באופן ידני הוא קשה, אך בעבור מקרים פשוטים נוכל לפתור זאת תוך שימוש בעיקרון הבא:
במידה ומצאנו את הפתרון האופטימאלי על תת מדגם מתוך המדגם המלא, ומתקיים שבעבור הפתרון שמצאנו, הנקודות שאינן חלק מתת המדגם נמצאות מחוץ ל margin, אז הפתרון הוא בהכרח הפתרון האופטימאלי בעבור המדגם כולו.
(עקרון זה נכון בגלל העובדה שהוספה של אילוצים לבעיית מינימיזציה יכולה רק להגדיל את ה objective המינימאלי).
המשמעות של עיקרון זה הינו שנוכל לנחש מי הם ה support vectors ולפתור את הבעיה רק בעבור נקודות אלו, תוך התעלמות משאר הנקודות. לאחר שנפתור את הבעיה על הנקודות שניחשנו יהיה עלינו לבדוק אם שאר הנקודות במדגם מחוץ ל margin. אם אכן שאר הנקודות מחוץ ל margin אז פתרנו את הבעיה ואם לא, אז עלינו לנחש נקודות אחרות. בעבור ה support vectors האילוצים של y(i)(w⊤x(i)+b)≥1 הופכים להיות אילוצי שיוויון שאיתם הרבה יותר קל לעבוד.
ננסה לנחש מהם ה support verctors. נתחיל ב 0 ונגדיל בהדרגה את כמות ה support vectors.
0 or 1 Support Vectors
באופן כללי בעבור מדגם "נורמלי" אשר מכיל נקודות משתי המחלקות שאותן יש לסווג, מקרים אלו לא יכולים להתקיים.
(באופן תיאורטי במקרה המנוון שבו המדגם מכיל רק תוויות מסוג אחד אז ניתן להגדיר בצורות שונות את כמות ה support vectors, אך מקרים אלו לא מאוד רלוונטיים)
2 Support Vectors
על פי התוצאה של התרגיל הקודם אנו יודעים שבעבור שני support vectors שמישור ההפרדה יעבור בדיוק במרכז בין 2 הנקודות, יהיה ניצב לוקטור המחבר את שתי הנקודות והשוליים של ה margin יעברו דרך הנקודות. אם נסתכל על המדגם וננסה לחפש 2 נקודות שיכולות להיות support vectors נראה שכל בחירה של זוג נקודות יצור איזור של margin שמכיל נקודה אחרת ולכן לא מקיים את האילוצים. לכן הפתרון לא יכול להכיל רק שני support vectors.
3 Support Vectors
ישנן שתי שלשות שיתכן שיהיו ה support vectors של הפתרון:
{1,3,5}
{3,4,5}
בעבור מדגם הכולל את {3,4,5} ה support vectors יהיו הנקודות 3 ו 5 וכבר ראינו כי נקודות אלו יוצרות פתרון שלא מקיים את האילוצים. לעומת זאת השלשה של {1,3,5} מגדירה איזור margin שאינו מכיל נקודות אחרות ולכן מקיים את האילוצים:
לכן נקודות אלו יהיו שלושת ה support vectors שיגדיר את הפתרון לבעיה. נחשב את הפתרון המתקבל משלושת הנקודות האלה.
בעבור שלוש support vectors נקבל מתוך האילוצים 3 משוואות ב3 נעלמים. בעבור הנקודות {1,3,5} משוואות אלו יהיו:
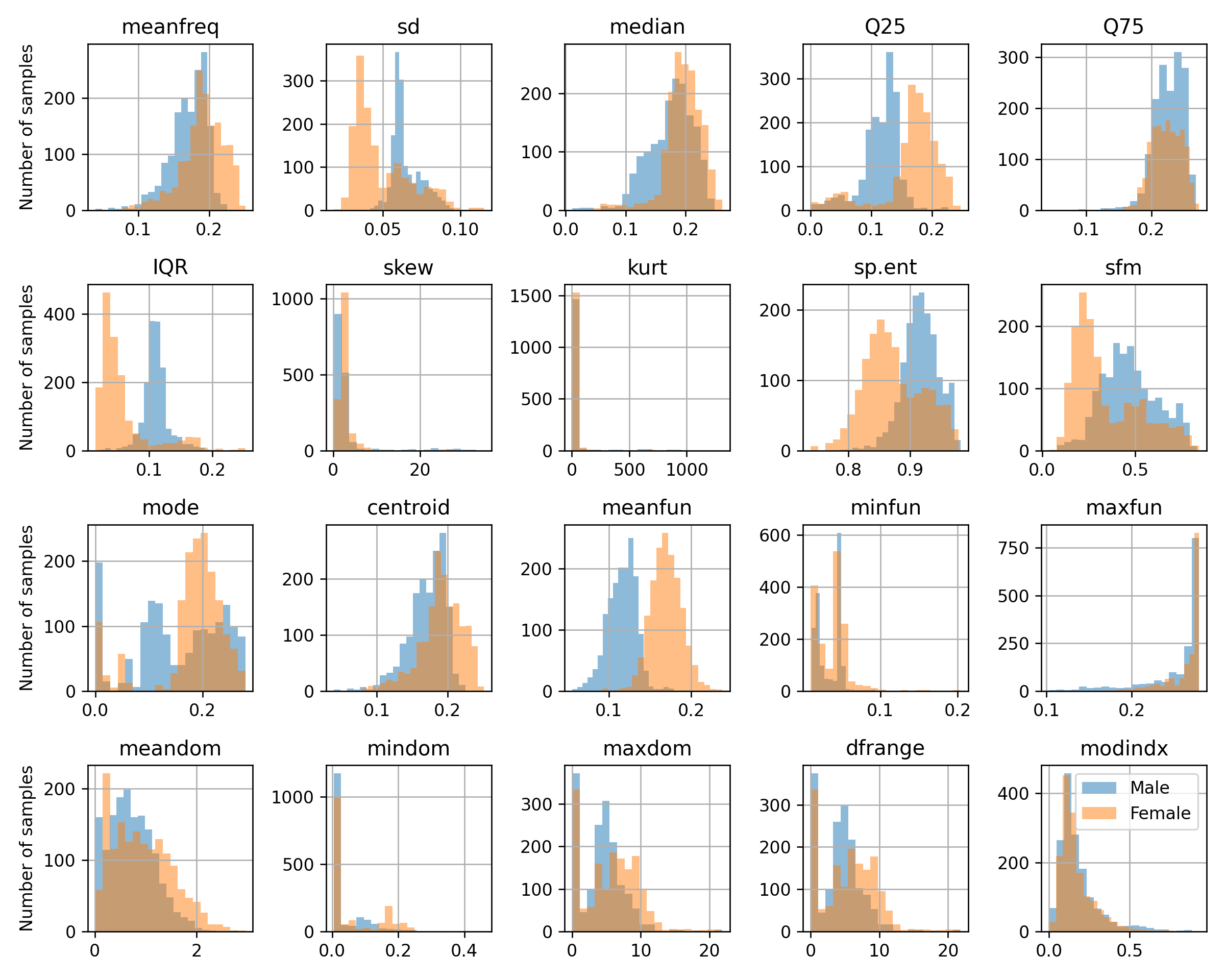
בחלק זה, ננסה להשתמש ב- SVM כדי לזהות את מינו של הדובר באמצעות קולו. מוטיבציה למערכת כזאת יכולה להיות עוזר וירטואלי שרוצה לפנות לדובר לפי מינו. הרחבה לניסיון זה יכולה להיות זיהוי דובר על סמך קולו וכו'.
הרעיון וה- DATA נלקחו מ- Dataset והערכת ביצועים של קורי בקר, אשר נמצאים באתר הבא. בפרוייקט זה נאספו 3168 דגימות קול מתוייגות מהמקורות הבאים:
את b ניתן לחשב על ידי בחירה של נקודה שעבורה 0<αi ולהשתמש במשוואה: yi(wTxi+b)=1−ξi.
בכדי לפתור את הבעיה נצטרך לבחור פרמטר משקל C אשר קובע את גודל הקנס לנקודות שחורגות מה margin. נתחיל ב C=1 ואחר כך ננסה למצוא את הערך המיטבי.
חלוקת המדגם
כרגיל נחלק את המדגם ל 60%-20%-20% שהם train-validation-test.
נרמול
חשוב לנרמל את העמודות של המדגם לפני הרצת האלגוריתם משתי סיבות עיקריות:
המדגם מכיל מאפיינים ביחידות וסקלות שונות.
האלגוריתם מנסה למזער objective אשר מבוסס מרחק, מה שהופך אותו לרגיש לגודל של כל מאפיין. לדוגמא, אם נכפיל מאפיין מסויים בקבוע גדול מ-1 אנו ניתן לו חשיבות יתרה ב objective.
תוצאות
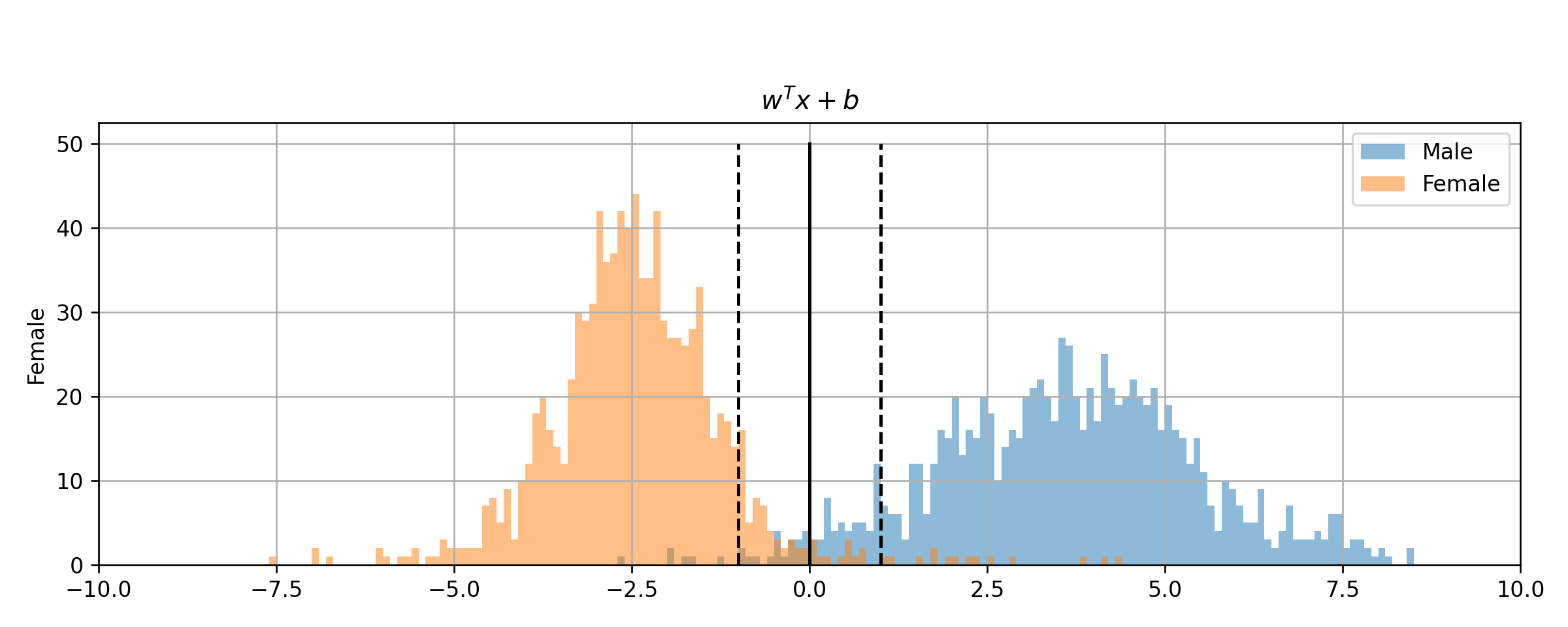
נשתמש באופטימיזציה נומרית על מנת למצוא את הפרמטרים של משטח ההפרדה. לשם המחשה נשרטט את הפילוג של ה signed distance של הנקודות בכל אחת מהמחלקות
ניתן לראות כי המשטח באמת מצליח לחלק את המדגם עד כדי כמה נקודות שחורגות.
ה miscalssification rate שמתקבל על ה test set הינו 0.028.
מציאת ה C האופטימאלי
נבחן סדרה של ערכי C בתחום 10−3 עד 103. כרגיל, בעבור כל ערך נבנה מסווג ונבחן אותו על ה validation set. נקבל את התוצאה הבאה:
קיבלנו כי הערך שאיתו התחלנו של C=1 הוא האופטימאלי מבין הערכים שבחרנו.