תרגול 4 - K-NN ו Decision trees
תקציר התיאוריה
בעיות סיווג
בעיות סיווג הם בעיות supervised learning שבהם הlabels (תוויות) מוגבלות לסט סופי של ערכים.
- בבעיות סיווג נהוג להתייחס לחזאי כאל מסווג (classifier) או discriminator (מקטלג).
- את הערכים השונים שאותם התוויות יכול לקבל מכנים מחלקות.
- את מספר המחלקות נסמן בקורס ב .
- בעיות סיווג שבהם יש רק 2 מחלקות, , מכוונות בעיות סיווג בינארי.
-
בסיווג בינארי, מקובל להשתמש באחת מהאופציות הבאות לסימון המחלקות:
- .
- .
-
בסיווג לא בינארי, מקובל להשתמש באחת מהאופציות הבאות לסימון המחלקות:
- .
- .
דוגמאות:
-
מערכת לזיהוי הונאות בכרטיסי אשראי (המקרה בו אדם לא מורשה משתמש בכרטיס או מספר אשראי של אדם אחר). במקרה זה יכול להיות וקטור אשר מכיל את מאפייני העיסקה, כגון מחיר, שעה, ומיקום, ו יקבל אחד משני ערכים:
- 0 - העסקה לגיטימית.
- 1 - חשד להונאה.
-
מערכת לעיבוד כתב יד (OCR). במקרה זה יכול להיות לדוגמא תמונה של אות ו יהיה שווה למחלקה אשר מייצגת את האות בתמונה:
- 1: a
- 2: b
- 3: c
- ...
Misclassification rate
לרוב בבעיות סיווג לא תהיה משמעות למרחק בין החיזוי לערך האימיתי של . לדוגמא, בניסיון לזהות את האות , חיזוי של האות (אשר מופיעה בצמוד ל באלף בית) הוא לא בהרכח חיזוי טוב יותר מ (אשר נמצא רחוק יותר).
לכן לרוב בבעיות סיווג נפוץ להשתמש ב misclassification rate כפונקציית מחיר. פונקציית מחיר זו הינה מסוג פונקציית risk אשר משתמשת ב zero-one-loss המוגדר באופן הבא:
פונקציית ה misclassification rate אם כן נראית כך:
החזאי האופטימאלי של פונקציית מחיר / risk זו הינו החזאי אשר מחזיר את ה הכי סביר (הכי שכיח, ה mode) בהסתברות של בהינתן :
K-NN (K-Nearest Neighbours)
K-NN הינו אלגוריתם דיסקרימינטיבי לפתרון בעיות סיווג. באלגוריתם זה החיזויים נעשים ישירות על פי המדגם באופן הבא:
בהינתן מסויים:
- נבחר את הדגימות בעלות ה הקרובים ביותר ל . (לרוב נשתמש במרחק אוקלידי, אך ניתן גם לבחור פונקציות מחיר אחרות).
- תוצאת החיזוי תהיה התווית השכיחה ביותר (majority vote) מבין התוויות של הדגימות שנבחרו בשלב 1.
במקרה של שיוון:
- במקרה של שיוויון בשלב 2, נשווה גם את המרחק הממוצע בין ה -ים השייכים לכל תווית. אנו נבחר בתווית בעלת המרחק הממוצע הקצר ביותר.
- במקרה של שיווון גם בין המרחקים הממוצעים, נבחר אקראית.
K-NN לבעיות רגרסיה
ניתן להשתמש באלגוריתם זה גם לפתרון בעיות רגרסיה אם כי פתרון זה יהיה לרוב פחות יעיל. בבעיות רגרסיה ניתן למצע על התוויות במקום לבחור את תווית השכיחה.
Decision trees (עצי החלטה)
עצי החלטה הם כלי נפוץ (גם מחוץ לתחום של מערכות לומדות) לקבלת החלטות על סמך אוסף של עובדות.
טרמינולוגיה:
- root (שורש) - נקודת הכניסה לעץ.
- node (צומת) - נקודות ההחלטה / פיצול של העץ - השאלות.
- leaves (עלים) - הקצוות של העץ - התשובות.
- branch (ענף) - חלק מתוך העץ המלא (תת-עץ).
נוכל להשתמש בעצי החלטה שכאלה לבניית חזאים. הדרך הנפוצה לגדיר את השאלות על הענפים של העץ הינם על ידי תנאים על רכיב יחיד של . ספצפית:
- לרוב נשתמש בתנאי מהצורה , כאשר יש לבחור את ו .
- כאשר הוא מתשנה דיסקרטי אשר מקבל סט קטן של ערכים נוכל גם לפצל לפי הערכים האפשריים של .
לדוגמא
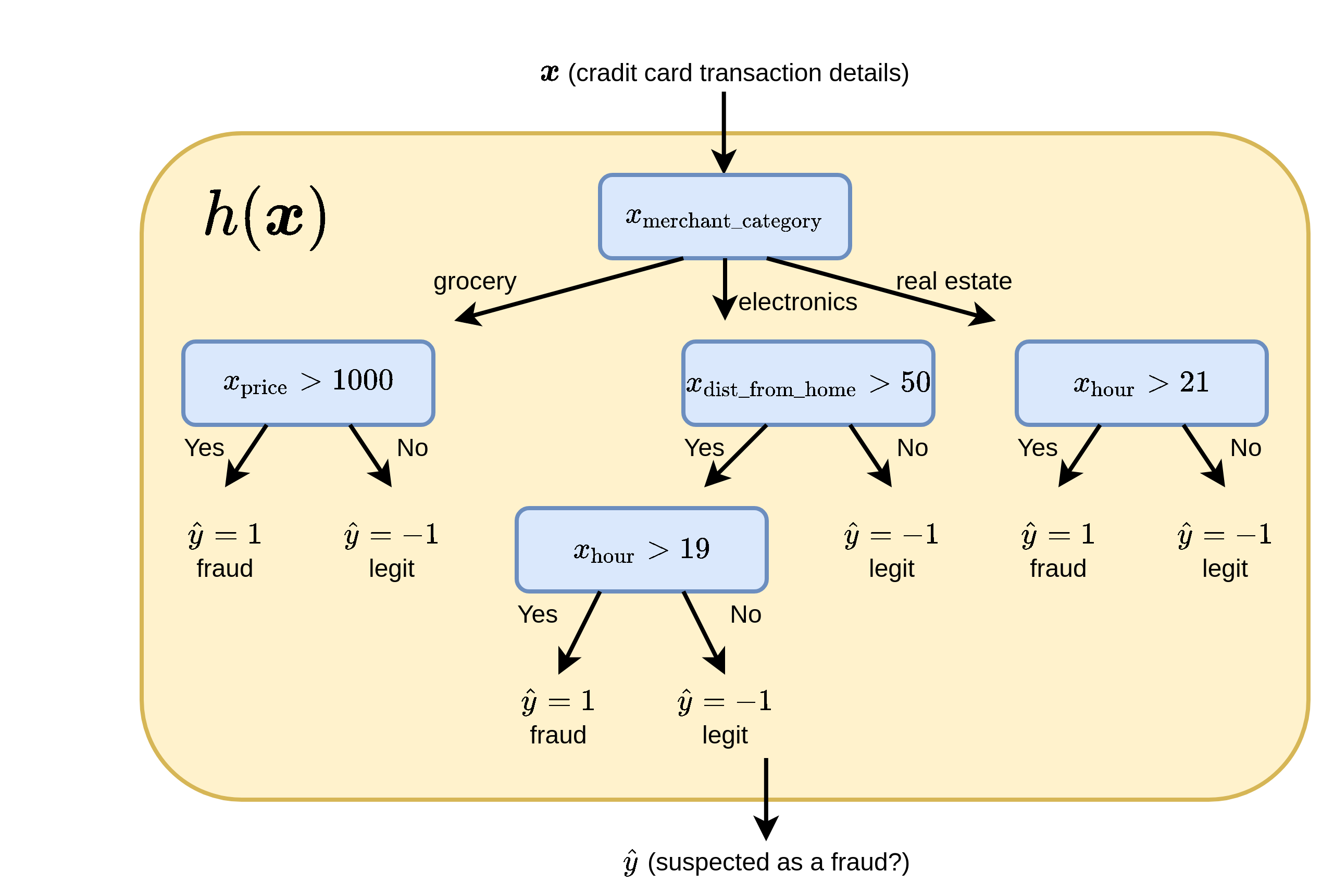
היתרונות של השימוש בעץ החלטה כחזאי:
- פשוט למימוש (אוסף של תנאי if .. else ..).
- מתאים לעבודה עם משתנים קטגוריים (משתנים בדדים אשר מקבלים אחד מסט מצומצם של ערכים).
- Explainable - ניתן להבין בדיוק מה היו השיקולים שלפיהם התקבל חיזוי מסויים.
בניית עץ החלטה לסיווג
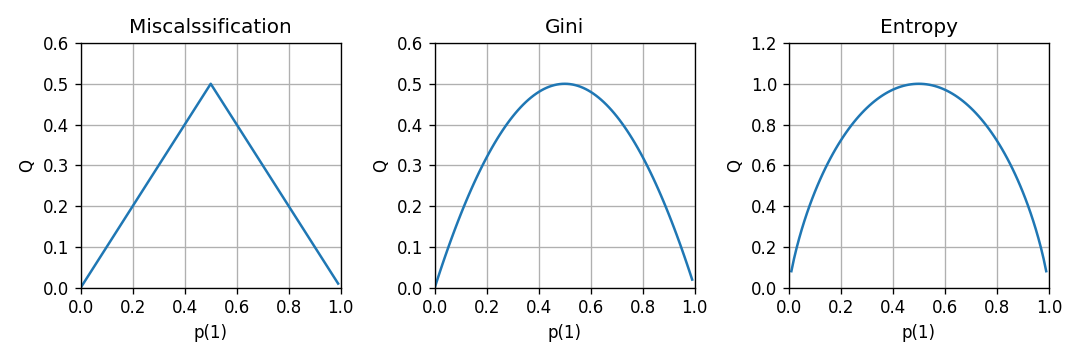
מדדים לחוסר ההומוגניות של פילוג
בהינתן משתנה אקראי דיסקרטי אשר מקבל אחד מ ערכים ועם פונקציית הסתברות , נגדיר כמה מדדים אשר מודדים עד כמה הפילוג של רחוק מלהיות פילוג אשר מייצר דגימות הומוגניות (זאת אומרת פילוג שהוא פונקציית דלתא):
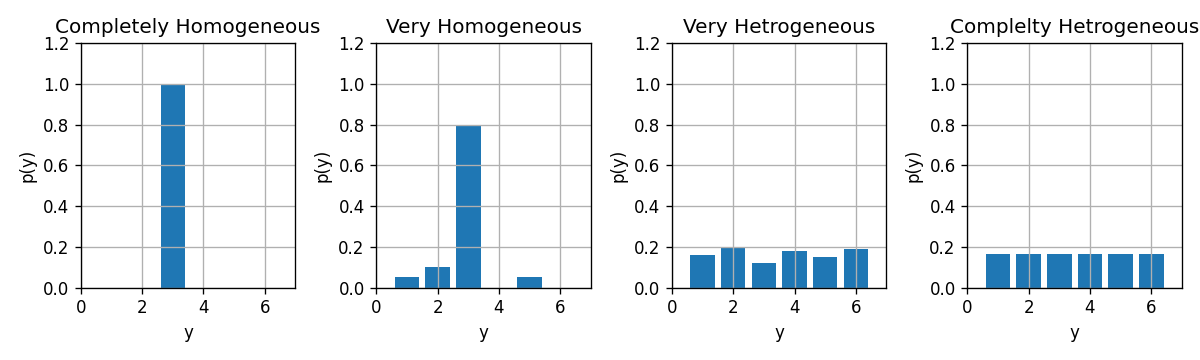
-
שגיאת הסיווג (אשר המתקבלת בעבור חיזוי של הערך הכי סביר)
-
אינדקס Gini:
-
אנטרופיה:
מדדים אלו שווים ל-0 בעבור פילוגים אשר מייצרים דגימות הומוגניות והם גדלים ככל שהפילוג הולך ונעשה אחיד. השרטוטים הבאים מראים את ההתנהגות של הממדים האלה במקרה של משתנה אקראי בינארי:
חוסר הומוגניות ממוצעת של עץ
בהינתן מדגם מסויים ומדד חוסר הומוגניות מסויים נגדיר את הציון של עץ החלטה נתון באופן הבא:
- נעביר את הדגימות מהמדגם דרך העץ ונפצל אותם על פי העלה שאליו הם הגיעו. נסמן את האינדקסים של הדגימות שהגיעו לעלה ה ב . נסמן את כמות הדגימות שהגיעו לעלה ה ב .
-
לכל עלה נחשב את הפילוג האמפירי של התויות שהגיעו אליו באופן הבא:
( הוא פשוט השכיחות של הערך מבין התוויות בעלה ה )
-
בעזרת הפילוג האמפירי נחשב את חוסר ההומוגניות של כל עלה:
-
הציון הכולל של העץ יהיה הממוצע המושכלל של חוסר ההומוגניות של העלים ביחס לכמות הדגימות שהגיעה לכל עלה:
שלב ראשון - בניה של עץ מלא
בכדי לקבל סיווג כמה שיותר טוב נרצה שהפילוג בעלים של העץ יהיו כמה שיותר הומוגניים, זאת אומרת שמדד חוסר ההומוגניות יהיה 0. בכדי להימנע כמה שיותר מ overfitting נרצה לעשות זאת על ידי שימוש בכמה שפחות nodes.
מכיוון שבכדי למצוא את הפתרון האופטיאמלי יש לעבור על כל העצים האפשריים, אנו נחפש פיתרון שאינו בהכרח האופטימאלי על ידי בניה של העץ בצורה חמדנית (greedy). אנו נתחיל מה root ונוסיף nodes כך שבכל שלב נבחר את ה node אשר מניב את העץ עם מדד החוסר הומוגניות הנמוך ביותר. אנו נעשה זאת על ידי מעבר על כל האופציות האפשריות לבחור את ה node. ממשיכים לפצל את העלים של העץ כל עוד מדד חוסר ההומוגניות יורד.
מלבד במקרים שבהם יש במדגם שתי דגימות עם אותו ה אך שונה, יהיה ניתן להגיע למדד חוסר הומוגניות 0. זאת אומרת שבכל עלה יש דגימות עם תוויות מסוג אחד בלבד. באותם מקרים שבהם לא ניתן להגיע לתווית בודדת לכל עלה, נבחר את תוצאת החיוזי להיות הערך הכי שכיח באותו עלה.
שלב שני - pruning (גיזום)
בכדי להקטין את מידת ה overfitting של העץ ניתן להשתמש ב validation set על מנת לבצע pruning של העץ באופן הבא:
מתחילים מכל אחד מהעלים ובודקים לכל node, האם הסרה שלו משפרת או לא משנה את ביצועי העץ על ה validation set. במידה וזה אכן המצב מסירים אותו. ממשיכים כך עד שאין עוד מה להסיר.
Regression Tree
ניתן להשתמש בעצים גם לפתרון בעיות רגרסיה. במקרה של רגרסיה עם פונקציית מחיר של MSE, הבניה של העץ תהיה זהה מלבד שני הבדלים:
- תוצאת החיזוי בעלה מסויים תהיה הערך הממוצע של התוויות באותו עלה. (במקום הערך השכיח)
- את מדד חוסר ההומוגניות נחליף בשגיאה הריבועית של החיזוי של העץ.
תרגיל 4.1
סטודנט נבון ניגש לבחור אבטיחים בסופרמרקט. ידוע כי זוהי רק תחילתה של עונת האבטיחים וקיים מספר לא מבוטל של אבטיחי בוסר. הסטודנט שם לב כי ניתן לאפיין את האבטיחים ע"פ ההד בהקשה וע"פ קוטר האבטיח. הסטודנט החליט למפות את ניסיון העבר שלו:
| Radius | Echo | Sweetness | |
|---|---|---|---|
| 0 | 8 | 1 | -1 |
| 1 | 10 | 2 | -1 |
| 2 | 5 | 5 | 1 |
| 3 | 7 | 3 | 1 |
| 4 | 7 | 4 | -1 |
| 5 | 10 | 4 | -1 |
| 6 | 11 | 4 | -1 |
| 7 | 7 | 5 | 1 |
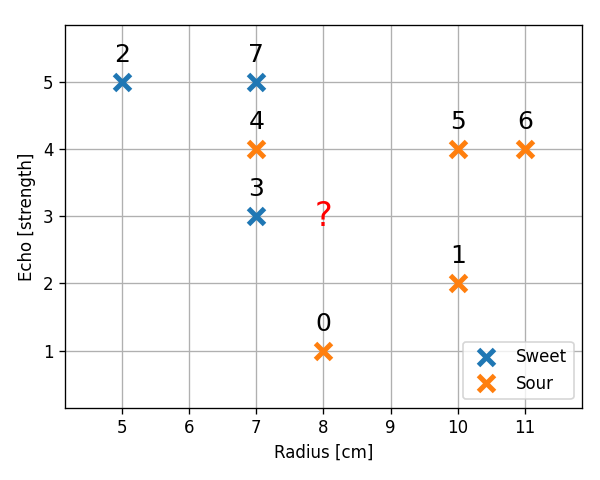
הסטודנט מחזיק בידו אבטיח בעל בעוצמה 3 ורדיוס 8 ס"מ. על מנת לחזות האם האבטיח בידו מתוק או חמוץ נבנה חזאי בעזרת K-NN.
1) (ללא קשר לבעיה בשאלה) כיצד הפרמטר משפיע על השגיאה שאנו צופים לקבל באלגוריתם ה K-NN? ממה תנבע השגיאה כאשר יהיה קטן וממה תנבע השגיאה כאשר יהיה גדול?
2) בעבור המדגם הנתון, מה קורה במקרה שבו ? האם שגיאה זו היא שגיאת overfitting או underfitting?
3) השתמשו ב leave-one-out cross validation על מנת לקבוע את ה האופטימאלי מבין הערכים 1,3,5,7. השתמשו ב missclassification rate כפונקציית המחיר.
4) השתמשו ב שמצאתם בכדי לחשב את החיזוי הסופי.
פתרון 4.1
1)
כפי שראינו בהרצאה, כאשר יהיה קטן אנו למעשה מתאימים לכל נקודה ב train set איזור החלטה משלה. במצב זה החזאי יתן חיזוי מושלם על המדגם, אך איזורי החלטה אלו, אשר תלויים במקומים המקריים של נקודות בודדות, לא בהכרח ייצגו את האופי של הפילוג האמיתי. זהו בדיוק המקרה של overfitting.
כאשר יהיה גדול מאד אנו למעשה נמצע על איזורים מאד גדולים ולכן החזאי יתעלם מהשינויים העדינים בפילוג של הנקודות, ויתייחס רק למגמה המאד כללית. זה בדיוק המצב של underfitting.
2)
במקרה הקיצוני שבו שווה לגודל ה dataset כל חיזוי יתבצע על סמך כל הנקודות במדגם ולכן יהיה שווה תמיד לתווית השכיחה ביותר במדגם. במקרה זה החיזוי יהיה תמיד , זאת אומרת שאנו נחזה שהאבטיח הוא חמוץ ללא כל תלות בהד וברדיוס.
3)
בכדי לקבוע את הערך האופטימאלי של מתוך הערכים הנתונים בעזרת K-fold cross validation עלינו לחשב את ציון ה validation לכל ערך של ולכל fold (שימוש בנקודה אחרת כ validation set). לאחר מכאן נמצע על ה folds השונים על מנת לקבל את הציון של כל . נרכז בטבלה את החיזוי המשוערך לכל fold ולכל :
| point | Correct label | K=1 prediction | K=3 prediction | K=5 prediction | K=7 prediction |
|---|---|---|---|---|---|
| 0 | -1 | ✓ -1 (nn=[1]) | ✓ -1 (nn=[1 3 4]) | ✓ -1 (nn=[1 3 4 5 7]) | ✓ -1 (nn=[1 3 4 5 7 6 2]) |
| 1 | -1 | ✓ -1 (nn=[5]) | ✓ -1 (nn=[5 0 6]) | ✓ -1 (nn=[5 0 6 3 4]) | ✓ -1 (nn=[5 0 6 3 4 7 2]) |
| 2 | 1 | ✓ 1 (nn=[7]) | ✓ 1 (nn=[7 4 3]) | ✗ -1 (nn=[7 4 3 0 5]) | ✗ -1 (nn=[7 4 3 0 5 1 6]) |
| 3 | 1 | ✗ -1 (nn=[4]) | ✗ -1 (nn=[4 7 0]) | ✗ -1 (nn=[4 7 0 2 1]) | ✗ -1 (nn=[4 7 0 2 1 5 6]) |
| 4 | -1 | ✗ 1 (nn=[3]) | ✗ 1 (nn=[3 7 2]) | ✗ 1 (nn=[3 7 2 5 0]) | ✓ -1 (nn=[3 7 2 5 0 1 6]) |
| 5 | -1 | ✓ -1 (nn=[6]) | ✓ -1 (nn=[6 1 4]) | ✓ -1 (nn=[6 1 4 3 7]) | ✓ -1 (nn=[6 1 4 3 7 0 2]) |
| 6 | -1 | ✓ -1 (nn=[5]) | ✓ -1 (nn=[5 1 4]) | ✓ -1 (nn=[5 1 4 3 7]) | ✓ -1 (nn=[5 1 4 3 7 0 2]) |
| 7 | 1 | ✗ -1 (nn=[4]) | ✓ 1 (nn=[4 2 3]) | ✗ -1 (nn=[4 2 3 5 0]) | ✗ -1 (nn=[4 2 3 5 0 6 1]) |
| Avg. score | 3/8 | 2/8 | 4/8 | 3/8 |
ניתן לראות כי בעבור אנו מקבלים את השגיאה הממוצעת הקטנה ביותר לכן נקבע את לערך זה.
4)
נבדוק את בשלות האבטיח שהסטודנט מחזיק בידו על סמך המדגם כולו עם . שלושת הנקודות הקרובות ביותר לנקודה הינם הנקודות , ו . מכיוון ששתיים מהן עם תווית של אנו נחזה שאבטיח זה הוא בוסר.
שאלה 4.2 – בניית עץ החלטה
בנה עץ החלטה המבוסס על קריטריון האנטרופיה, אשר בהינתן נתוני צבע שער, גובה, משקל, והשימוש בקרם הגנה, חוזה האם עתיד האדם להכוות מהשמש היוקדת.
סט דוגמאות הלימוד לצורך בניית העץ מוצג בטבלה הבאה:
| Hair | Height | Weight | Lotion | Result (Label) |
|---|---|---|---|---|
| blonde | average | light | no | sunburned |
| blonde | tall | average | yes | none |
| brown | short | average | yes | none |
| blonde | short | average | no | sunburned |
| red | average | heavy | no | sunburned |
| brown | tall | heavy | no | none |
| brown | average | heavy | no | none |
| blonde | short | light | yes | none |
פתרון 4.2
נפעל על פי האלגוריתם ונתחיל מה root ונתחיל להוסיף nodes:
במקרה זה יש לנו 4 nodes אפשריים (בעבור כל שדה של ). נחשב את האנטרופיה הממוצעת של כל אחד מהם ונבחר את המינימאלי.
Hair
נעביר את המדגם דרך העץ ונרכז בטבלה הבאה את התוויות ואנטרופיה המתקבלות בכל עלה:
| Leaf () | ||||
|---|---|---|---|---|
| Blonde | 1 | 4 | ||
| Brown | 2 | 3 | ||
| Red | 3 | 1 |
נחשב את הממוצע הממושקל של האנטופיה על שלושת העלים:
נמשיך לשדה הבא.
Height

| Leaf () | ||||
|---|---|---|---|---|
| Short | 1 | 3 | ||
| Average | 2 | 3 | ||
| Tall | 3 | 2 |
Weight
| Leaf () | ||||
|---|---|---|---|---|
| Light | 1 | 2 | ||
| Average | 2 | 3 | ||
| Heavy | 3 | 3 |
Lotion
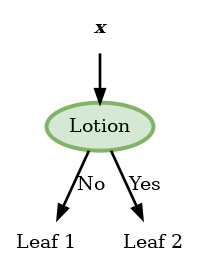
| Leaf () | ||||
|---|---|---|---|---|
| No | 1 | 5 | ||
| Yes | 2 | 3 |
מכאן שהמאפיין האופטימלי לפיצול הראשון (על פי קריטריון האנטרופיה) הוא Hair. לכן נבחר בו להיות ה node הראשון. נשים לב כי בעבור node זה שני הפילוצים של brown ו red כבר הומוגניים לגמרי (מכילים רק סוג אחד של תוויות) ולכן לא נמשיך לפצל אותם ונרשום את החיזוי המקבל בכל עלה:
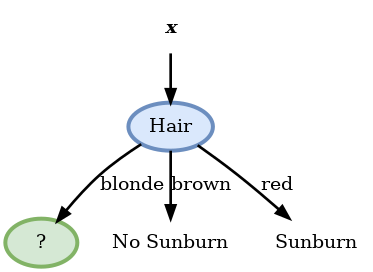
נמשיך כעת באופן דומה לבחור את ה node בעבור הענף של blond. מכיוון שאין טעם לבדוק שוב את ה node של hair נשאר לנו לבדוק רק את שלושת האופציות הנותרות. לשם הנוחות נרכז את הדגימות האשר מגיעות לענף זה:
| Height | Weight | Lotion | Result |
|---|---|---|---|
| average | light | no | sunburned |
| tall | average | yes | none |
| short | average | no | sunburned |
| short | light | yes | none |
Height
בכדי לבחור את ה node האופטימאלי נוכל להתעלם מכל מה שקורה בענפים אחרים ולחשב רק את האנטרופיה המתקבלת בענף הזה (של ה blond).
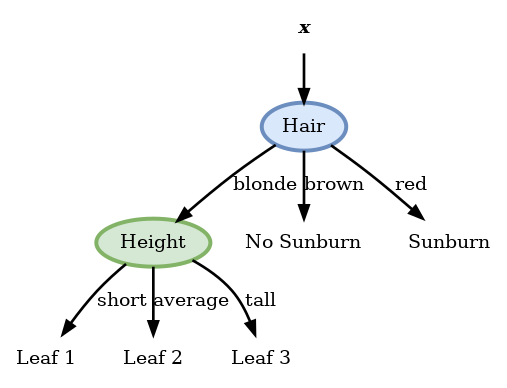
| Leaf () | ||||
|---|---|---|---|---|
| Short | 1 | 2 | ||
| Average | 2 | 1 | ||
| Tall | 3 | 1 |
Weight
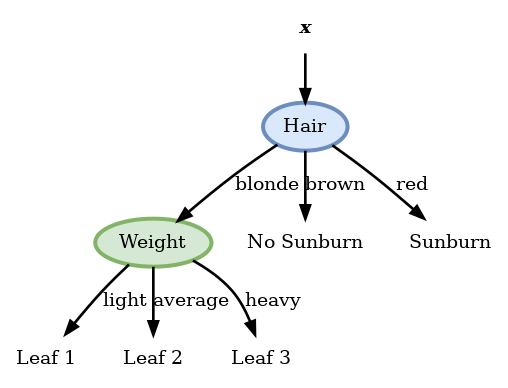
| Leaf () | ||||
|---|---|---|---|---|
| Light | 1 | 2 | ||
| Average | 2 | 2 | ||
| Heavy | 3 | 0 |
Lotion
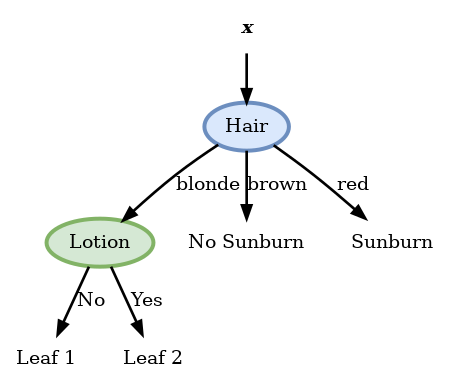
| Leaf () | ||||
|---|---|---|---|---|
| No | 1 | 2 | ||
| Yes | 2 | 2 |
פיצול זה נותן אנטרופיה 0 ולכן הוא הפיצול האופטימאלי ואנו נבחר בו. עץ ההחלטה הסופי יראה אם כן:
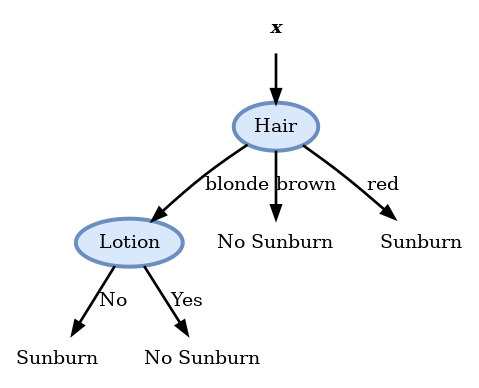
עץ זה ממיין באופן מושלם את המדגם.
תרגיל 4.3
נתון המדגם הבא של ערכי תצפית של ושל תוויות :
| 1 | 1 | 1 | -1 | 1 |
| 2 | 1 | -1 | -1 | 1 |
| 3 | -1 | -1 | -1 | 1 |
| 4 | -1 | -1 | -1 | -1 |
| 5 | 1 | 1 | 1 | -1 |
נרצה לבנות עץ החלטה על מנת לחזות את על סמך . נרצה להשתמש במדד חוסר הומגניות חדש מסוג Squared Root Gini אשר מוגדר באופן הבא:
1) בנו עץ מלא על סמך קריטריון זה. כמה nodes יש בעץ שמצאתם?
2) חשבו את הציון (score) של עץ זה תחת פונקציית המחיר של misclassification rate. האם ניתן להגיע לסיווג מושלם במקרה זה?
3) האם בעבור מקרה זה ניתן לבנות עץ אשר מגיע לאותו ציון כמו העץ שמצאתם בסעיף 1 אך עם פחות nodes? אם כן, הציעו סיבה אפשרית למה האלגוריתם בו השתמשתם בסעיף הקודם לא מצא את העץ הזה.
פתרון 4.3
1)
נתחיל מה root ונבדוק את שלושת ה nodes האפשריים תחת מדד השגיאה החדש:

| Leaf () | ||||
|---|---|---|---|---|
| 1 | 1 | 3 | ||
| -1 | 2 | 2 |
נשים לב ש node זה נותן חלוקה דומה של התוויות לזו של ולכן נקבל את אותו ערך המדד של .
| Leaf () | ||||
|---|---|---|---|---|
| -1 | 1 | 4 | ||
| 1 | 2 | 1 |
לכן נבחר את ה node הראשון להיות התנאי על . מכיוון שהענף של כבר הומוגני לא נחלק אותו יותר:
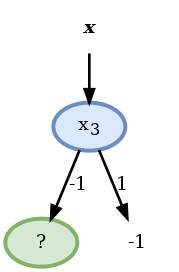
הדגימות הרלוונטיות כרגע הם:
| 1 | 1 | 1 | 1 |
| 2 | 1 | -1 | 1 |
| 3 | -1 | -1 | 1 |
| 4 | -1 | -1 | -1 |
נבדוק את שני השדות שנותרו:
| Leaf () | ||||
|---|---|---|---|---|
| 1 | 1 | 2 | ||
| -1 | 2 | 2 |
| Leaf () | ||||
|---|---|---|---|---|
| 1 | 1 | 1 | ||
| -1 | 2 | 3 |
ה node האופטימאלי כאן הוא הפיצול לפי ונשים לב שהענף של כבר הומוגני:
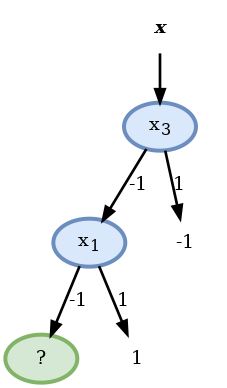
בעבור הענף של הדגימות הרלוונטיות הם:
| 3 | -1 | 1 |
| 4 | -1 | -1 |
במקרה זה למרות שלא הגענו לפילוג הומוגני לא נוכל לפצל יותר את הענף כי הערכים של זהים בעבור שני הדגימות ולכן לא ניתן להבחין בינהם. במקרה זה נחבר את החיזוי באופן שרירותי להיות ונסיים את הבניה של העץ:
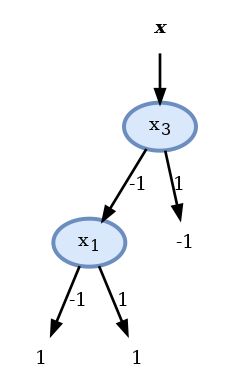
בעץ שמצאנו ישנם 2 nodes.
2)
בעבור העלים אשר הפילוג של התגיות בהם הינו הומוגני החיזוי יהיה מושלם. שגיאות חיזוי יתקבלו רק בעלה של אשר לא הצליח להגיע לפילוג הומוגני. מכיוון שבחרנו (באופן שרירותי) שהחיזוי בעלה זה יהיה 1 הדגימה היחידה אשר תסווג לא נכון היא דגימה 4. מכאן שהחזאי שבנינו יעשה על המדגם שגיאה אחת מתוך 5, זאת אומרת misclassification rate של .
כפי שציינו קודם, מכיוון שלדגימות 3 ו 4 יש את אותו אך שונה לא ניתן להפריד ביניהם ותמיד על אחד מהם החיזוי יהיה לא נכון. לכן הציון של הוא הציון המינימאלי שאותו ניתן לקבל על המדגם הזה.
3)
נשים לב שלמעשה ה node השני בעץ לא עושה כלום משום שללא תלות בערך של הוא חוזה ולכן ניתן באותה המידה להשתמש גם בעץ הבא ולקבל את אותו החיזוי:
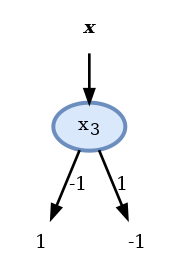
הסיבה שהאלגוריתם לא התכנס לפיתרון זה הינה שבבנייה של העץ ניסינו למזער את מדד ה squared root gini הממוצע ולא את שגיאת החיזוי ומכיוון שאלו שתי בעיות שונות, גם הפתרונות שלהם יכולים להיות שונים.
חלק מעשי - הטיטניק

אחד ה Datasets הנפוצים למשחקים פשוטים והדגמות של מערכות לומדות הוא רשימת הנוסעים של ספינת הטיטניק. רשימה זו מכילה פרטים שונים על כל אחד מהנוסעים יחד עם אינדיקטור של איזה מהנוסעים שרד. בעיית supervised learning שניתן להגדיר על מדגם זה הינה הבעיה של לנסות ולחזות איזה מהנוסעים שרד ואיזה לא על סמך הפרטים של כל נוסע. את המדגם המקורי ניתן למצוא פה, אנו נעבוד עם גרסא מעט יותר נקיה שלו, שאותה ניתן למצוא פה.
נציג את 10 השורות הראשונות במדגם:
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29 | 0 | 0 | 24160 | 211.338 | B5 | S | 2 | nan | St Louis, MO |
| 1 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2 | 1 | 2 | 113781 | 151.55 | C22 C26 | S | nan | nan | Montreal, PQ / Chesterville, ON |
| 2 | 1 | 0 | Allison, Mr. Hudson Joshua Creighton | male | 30 | 1 | 2 | 113781 | 151.55 | C22 C26 | S | nan | 135 | Montreal, PQ / Chesterville, ON |
| 3 | 1 | 0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25 | 1 | 2 | 113781 | 151.55 | C22 C26 | S | nan | nan | Montreal, PQ / Chesterville, ON |
| 4 | 1 | 1 | Anderson, Mr. Harry | male | 48 | 0 | 0 | 19952 | 26.55 | E12 | S | 3 | nan | New York, NY |
| 5 | 1 | 1 | Andrews, Miss. Kornelia Theodosia | female | 63 | 1 | 0 | 13502 | 77.9583 | D7 | S | 10 | nan | Hudson, NY |
| 6 | 1 | 0 | Andrews, Mr. Thomas Jr | male | 39 | 0 | 0 | 112050 | 0 | A36 | S | nan | nan | Belfast, NI |
| 7 | 1 | 1 | Appleton, Mrs. Edward Dale (Charlotte Lamson) | female | 53 | 2 | 0 | 11769 | 51.4792 | C101 | S | D | nan | Bayside, Queens, NY |
| 8 | 1 | 0 | Artagaveytia, Mr. Ramon | male | 71 | 0 | 0 | PC 17609 | 49.5042 | nan | C | nan | 22 | Montevideo, Uruguay |
| 9 | 1 | 0 | Astor, Col. John Jacob | male | 47 | 1 | 0 | PC 17757 | 227.525 | C62 C64 | C | nan | 124 | New York, NY |
במדגם הנקי יש 999 רשומות.
השדות
בתרגול זה לא נשתמש בכל השדות אלא רק בשדות הבאים:
- pclass: מחלקת הנוסע: 1, 2 או 3
- sex: מין הנוסע
- age: גיל הנוסע
- sibsp: מס' של אחים ובני זוג של כל נוסע על האוניה
- parch: מס' של ילדים או הורים של כל נוסע על האונייה
- fare: המחיר שהנוסע שילם על הכרטיס
- embarked: הנמל בו עלה הנוסע על האונייה (C = Cherbourg; Q = Queenstown; S = Southampton)
- survived: התיוג, האם הנוסע שרד או לא
התרשמות ראשונית בעזרת גרפים
נציג את הפילוג של כל אחד מהשדות בעבור האנשים ושרדו והאנשים שלא:
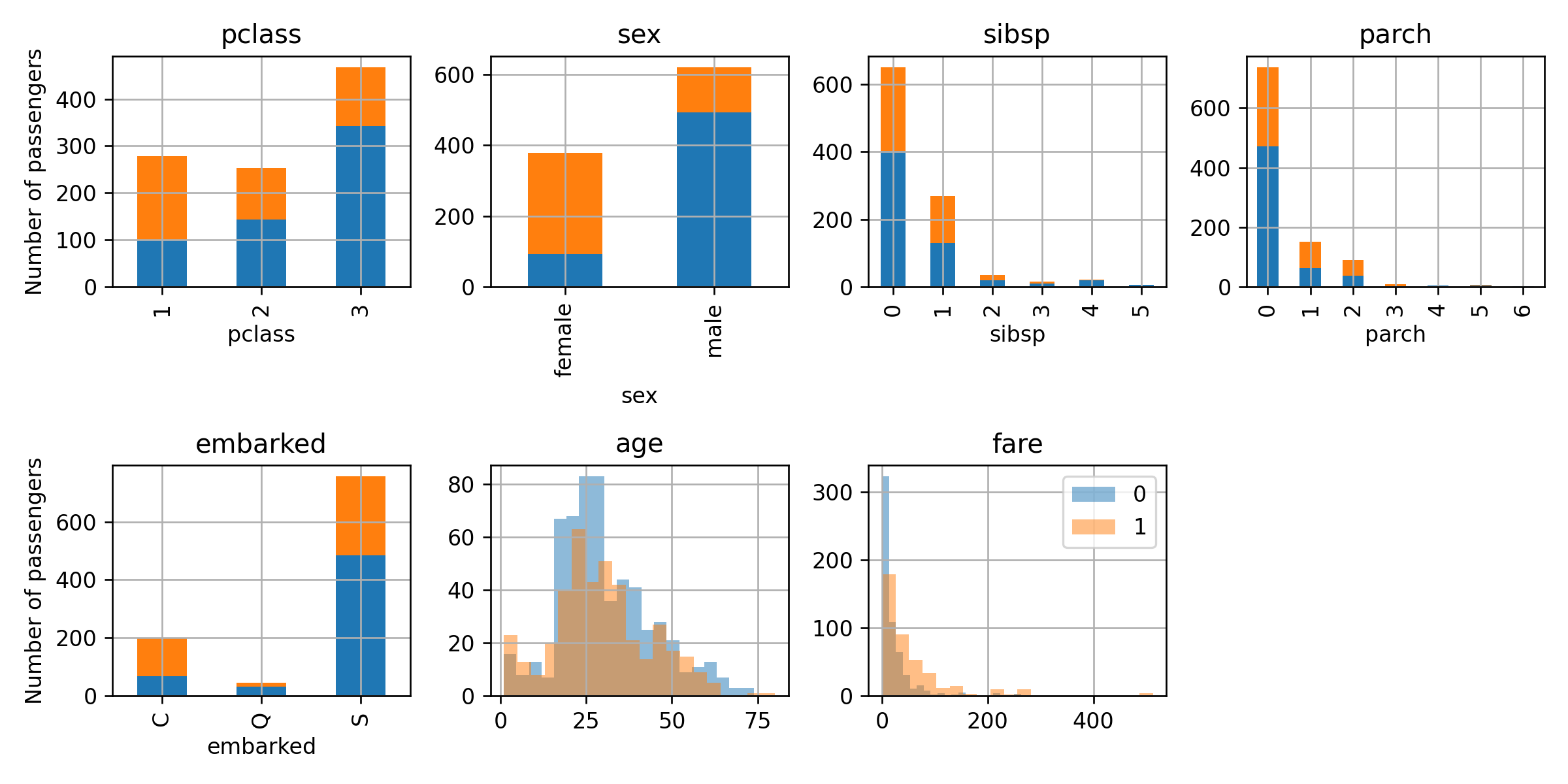
מתוך הגרפיים ניתן לראות כי אכן ישנם מאפיינים שיוכלו לסייע לנו לשפר את החיזוי שלנו. לדוגמא, ניתן לראות כי לנשים היה סיכוי גבוה בהרבה לשרוד לגברים וכך גם לנוסעים במחלקה הראשונה.
הגדרת הבעיה
נסמן:
- : הוקטור האקראי אשר מכיל את כל פרטי הנוסע.
- : המשתנה האקראי של האם הנוסע שרד או לו.
נרצה למצוא חזאי (מסווג) טוב ככל האפשר תחת פונקציית המחיר של miscalssification rate.
אנו נעשה זאת בעזרת decision tree.
חלוקת ה dataset
- נחלק את המדגם ל 80% train set ו 20% test set.
- נחלק את ה train set פעם נוספת ל 75% train set ו 25% validation set.
בניית עץ בעל שלוש רמות
נבנה את העץ על פי קריטריון Gini. נתחיל מה root ונוסיף בכל פעם את ה node שמזער את המדד. בעבור ה node הראשון:
האופציות הם:
Score before split: 0.492
Scores:
- pclass: 0.436
- sex: 0.360 <-
- sibsp: 0.479
- parch: 0.473
- embarked: 0.460
- age >= 9: 0.488
- fare >= 15.7417: 0.448ולכן נבחר למיין לפי המגדר. נמשיך באופן זהה לכל שאר ה nodes.
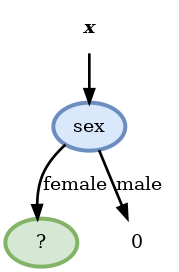
Score before split: 0.146
Scores:
- pclass: 0.109 <-
- sex: 0.146
- sibsp: 0.140
- parch: 0.143
- embarked: 0.130
- age >= 48: 0.142
- fare >= 10.5: 0.126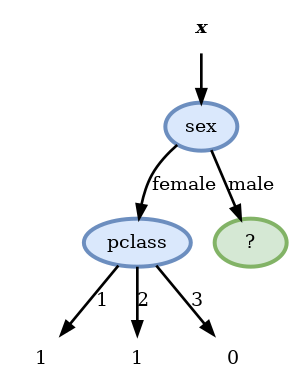
Score before split: 0.214
Scores:
- pclass: 0.202 <-
- sex: 0.214
- sibsp: 0.212
- parch: 0.209
- embarked: 0.205
- age >= 10: 0.207
- fare >= 26.2875: 0.205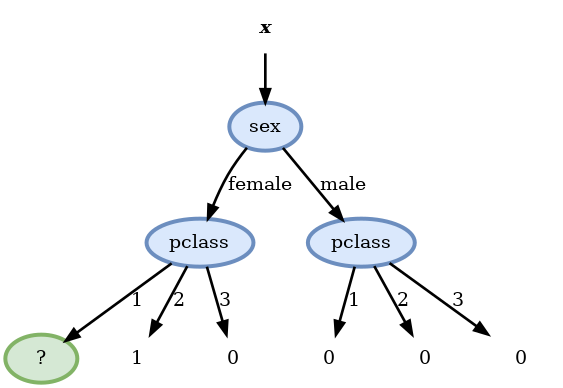
Score before split: 0.010
Scores:
- pclass: 0.010
- sex: 0.010
- sibsp: 0.009
- parch: 0.008
- embarked: 0.009
- age >= 15: 0.007 <-
- fare >= 151.55: 0.009נמשיך עד שנמלא את כל השיכבה השלישית ונקבל
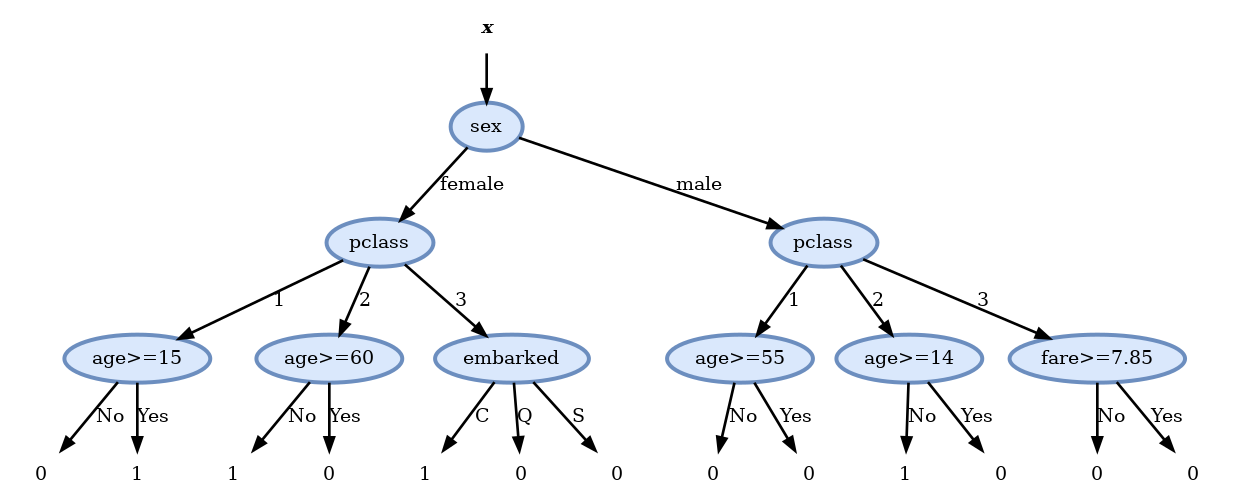
Pruning
לאחר חישוב העץ המלא נשתמש ב validation set על מנת להסיר את הענפים שלא משפרים (או פוגעים) בציון על ה validation set. בדיקה זו מראה שיש ארבעה node שלא תורמים לשיפור התוצאה ולכן נסיר אותם ונקבל את העץ הסופי הבא:
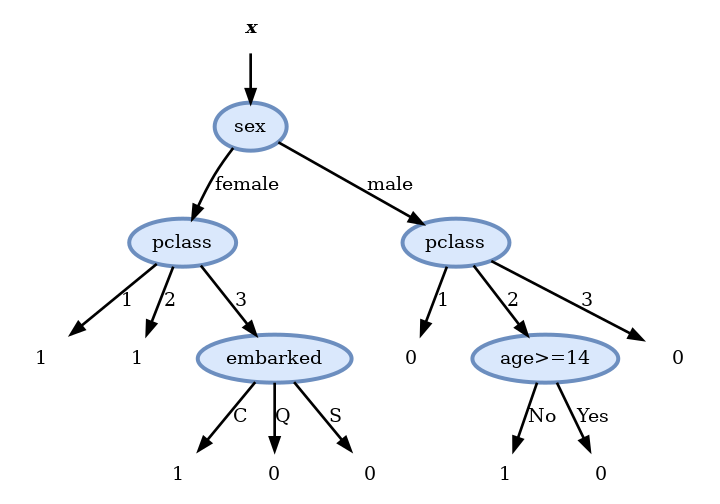
ביצועים
נחשב את הציון (misclassification rate) המתקבל על ה test set:
- הציון על ה test set הינו: 0.205
זאת אומרת שיש לנו סיכוי של 80% לחזות נכונה האם אדם מסויים שרד או לא.