תרגול 12 - PCA and K-means
תקציר התיאוריה - PCA
PCA הוא אלגוריתם מאוד נפוץ אשר משמש במקומות רבים על מנת למצוא יצוג נוח יותר לוקטורים על סמך מדגם נתון. אחד השימושים העיקריים של האלגוריתם הינו בכדי לבצע הורדת מימד של הוקטורים. (לייצג וקטורים בעזרת וקטור ממימד נמוך יותר).
הגדרות
בעבור מדגם נתון של וקטורים באורך נגדיר את הגדלים הבאים:
- הממוצע של המדגם: .
-
מטריצת הדגימות:
- הקווריאנס האמפירי של המדגם: .
נתייחס לפירוק (ליכסון) הבא: כאשר היא מטריצה אורתונורמלית אשר העמודות שלה הם וקטורים עצמיים של :
ו היא מטריצה אלכסונית אשר מכילה את הערכים העצמיים של :
כך שהערך העצמי מתאים לוקטור העצמי והערכים העצמיים מסודרים מהגדול לקטן: .
הטרנספורמציה אותה מבצע PCA
PCA מייצר מתוך מדגם נתון טרנספורמציה אפינית (affine = linear + offset) אשר ממפה וקטור באורך לוקטור באורך . כאשר הוא קבוע אשר נבחר מראש. הטרנפורמציה הינה:
כאשר הינה מטריצה המכילה את העמודות הראשונות של (זאת אומרת הוקטורים העצמיים המתאימים ל הערכים העצמיים הגדולים ביותר).
האיברים של נקראים הרכיבים הראשיים (principal components) של .
פרשנות גיאומטרית
הפעולה שאותה מבצעת הטרנספורמציה הינה:
- להזיז את הנקודות של המדגם כך שהמרכז שלהם יהיה בראשית.
- הטלה של הנקודות המוזזות על תת-המרחב שמוגדרת על ידי הוקטורים .
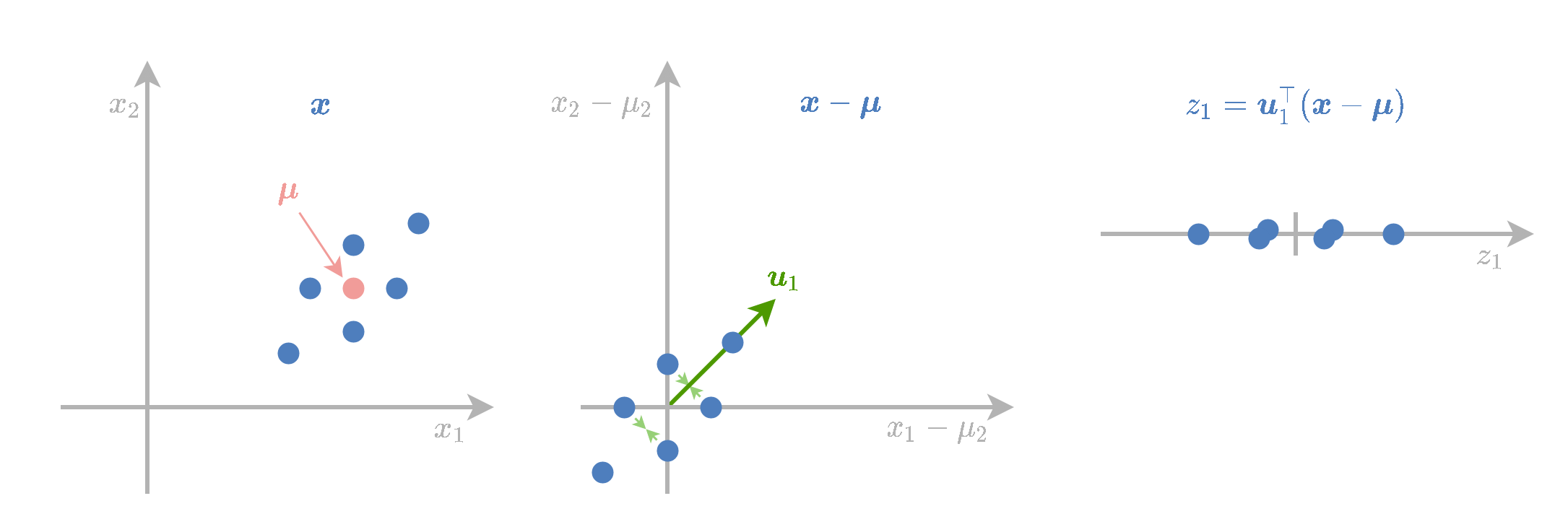
מוטיבציה ראשונה: מקסימום שונות
תחת האילוץ ש הינה מטריצה בגודל בעלת עמודות אורתו-נורמאליות, הבחירה הנוכחית של ממקסמת את הגודל:
אשר מכונה לרוב השונות של אוסף הוקטורים (בפועל זה שווה ל , כאשר מוגדרת בדומה ל רק עם הוקטורים ).
מוטיבציה שניה: מזעור שגיאת השחזור הריבועית
נסתכל על זוג טרנספורמציות אפיניות כלליות מ ל באורך , ומ ל :
נסמן את שגיאת השיחזור הריבועית באופן הבא: .
הטרנצפורמציות שימזערו את שגיאת השיחזור הריבועית הינם:
תקציר התיאוריה - K-Means
K-Means הוא אלגוריתם אשכול אשר מנסה לחלק את הדגימות במדגם ל קבוצות על סמך המרחק בין הדגימות.
סימונים
- - מספר האשכולות (גודל אשר נקבע מראש).
- - אוסף האינדקסים של האשכול ה-. לדוגמא:
- - גודל האשכול ה- (מספר הפרטים בקבוצה)
- - חלוקה מסויימת לאשכולות
בעיית האופטימיזציה
בהינתן מדגם , K-Means מנסה למצוא את החלוקה לאשכולות אשר תמזער את המרחק הריבועי הממוצע בין כל דגימה לכל שאר הדגימות שאיתו באותו האשכול. זאת אומרת, K-means מנסה לפתור את בעיית האופטימיזציה הבאה:
הבעיה השקולה
נגדיר את מרכז המסה של כל אשכול כממוצע של כל הוקטורים באשכול:
ניתן להראות כי בעיית האופטימיזציה המקורית, שקולה לבעיה של מיזעור המרחק הממוצע של הדגימות ממרכז המסה של האשכול:
האלגוריתם
K-mean הוא אלגוריתם חמדן אשר בכל פעם משייך מחדש את הדגימות ומעדכן את המרכזים.
האלגוריתם מאותחל בצעד על ידי בחירה אקראית של מרכזי מסה: .
בכל צעד מבצעים את שתי הפעולות הבאות:
-
עדכון מחדש של החלוקה לאשכולות כך שכל דגימה משוייכת למרכז המסה הקרוב עליה ביותר. כלומר אנו נשייך כל דגימה לפי:
(במקרה של שני מרכזים במרחק זהה נבחר בזה בעל האינדקס הנמוך יותר).
-
עדכון של מרכזי המסה המסה על פי:
(אם אז משאירים אותו ללא שינוי)
תנאי העצירה של האלגוריתם הינו כשהאשכולות מפסיקות להשתנות.
אחת הדרכים הנפוצות לאיתחול של היא לבחור נקודות מתוך המדגם.
תכונות
- מובטח כי פונקציית המטרה (סכום המרחקים מהממוצעים) תקטן בכל צעד.
- מובטח כי האלגוריתם יעצר לאחר מספר סופי של צעדים.
- לא מובטח כי האלגוריתם יתכנס לפתרון האופטימאלי, אם כי בפועל במרבית המקרים האלגוריתם מתכנס לפתרון אשר קרוב מאד לאופטימאלי.
- אתחולים שונים יכולים להוביל לתוצאות שונות.
תרגיל 12.1 - PCA
עבוד מדגם נתון של וקטורים ב חושבו וקטור הממוצע ומטריצת הקוואריאנס הבאים:
1) איזה מהוקטורים הבאים מייצג את הכיוון הראשון במטריצת ההטלה של PCA?
2) חשבו את שני ה principal componnents של .
פתרון 12.1
1)
נשתמש בעובדה ש צריך להיות וקטור עצמי של ולכן מקיים . נבדוק מי מהוקטורים הבאים מקיים זאת:
מכאן שגם הוקטור הראשון וגם השלישי הם וקטורים עצמיים. הוקטור הראשון בהטלה של PCA יהיה השלישי שכן הוא מתאים לערך עצמי גדול יותר:
2)
הרכיב העיקרי (principal componant) הראשון יהיה נתון על ידי:
והרכיב השני יהיה:
בעבור PCA עם נקבל:
תרגיל 12.2
נתונות נקודות שונות:
- נקודות בקואורדינאטות
- נקודות בכל אחת מהקואורדינאטות

(הנקודות יושבות אחת על השניה בכל קואורדינטה, ומצויירות כעיגולים רק לצורך השרטוט). רוצים לבצע אשכול של הנקודות ל3 אשכולות בעזרת K-Means.
1) מאתחלים את המרכזים על ידי בחירה אקראית של 3 מתוך ארבעת הנקודות A,B,C,D. לאילו חלוקות יתכנס האלגוריתם בעבור כל אחת מארבעת האתחולים האפשריים.
2) מהו האשכול האופטימאלי (הממזער את פונקציית המטרה)? רשמו את הפתרון כתלות בפרמטר . (ניתן להניח כי בפתרון האופטימאלי כל הנקודות שנמצאות באותו המקום משוייכות לאותו האשכול)
3) האם קיים אתחול אשר בעבורו האלגוריתם לא יתכנס לפתרון האופטימאלי שמצאתם בסעיף הקודם? הדגימו.
פתרון 12.2
1)
נחשב את תוצאת האלגוריתם בעבור כל אחת מארבעת האתחולים:
מרכזים ב A,B ו C:

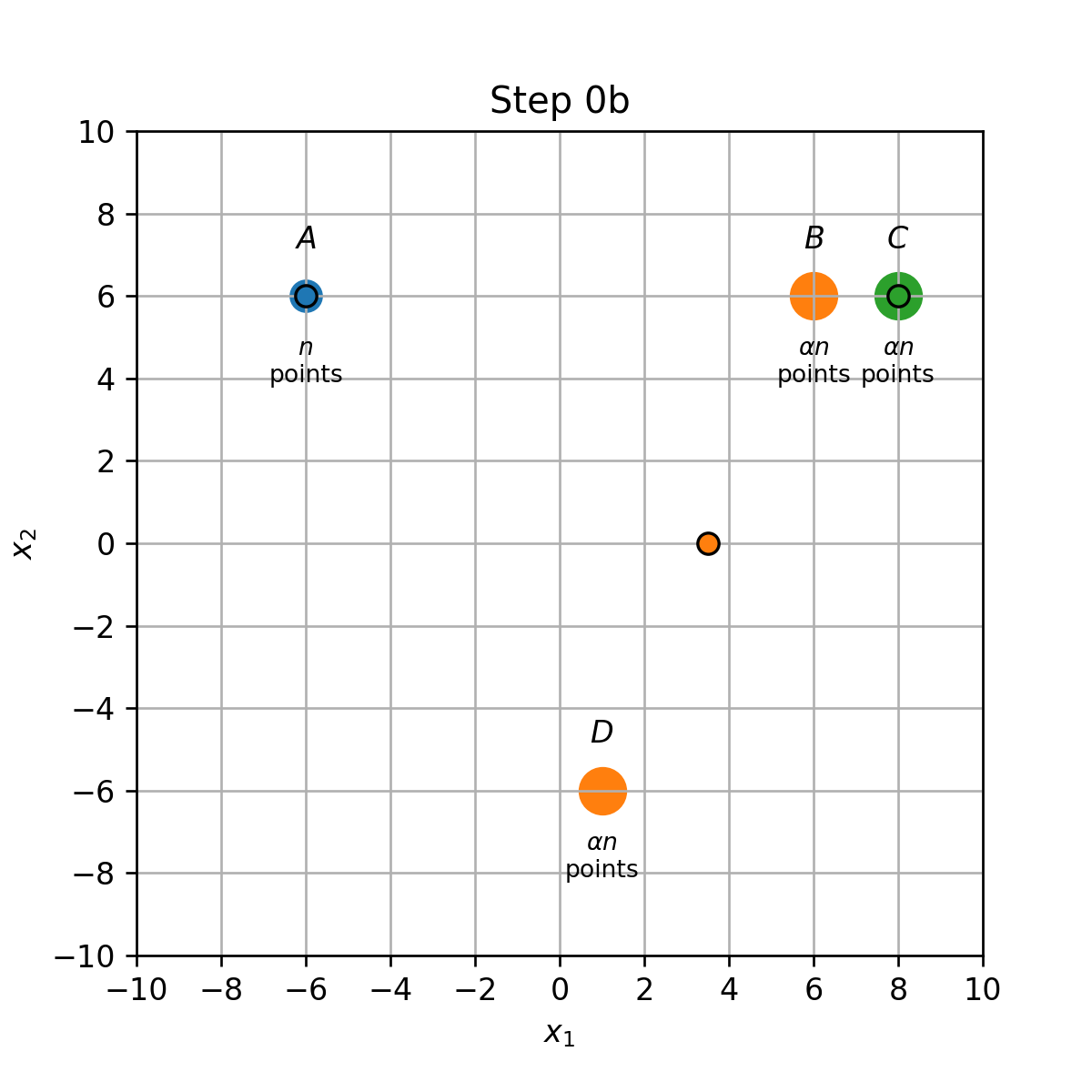

- שיוך התחלתי (0a): נקודות בA,B ו C ישוייכו למרכז אשר הנמצא עליהם, והנקודות בD ישוייכו למרכז שבB.
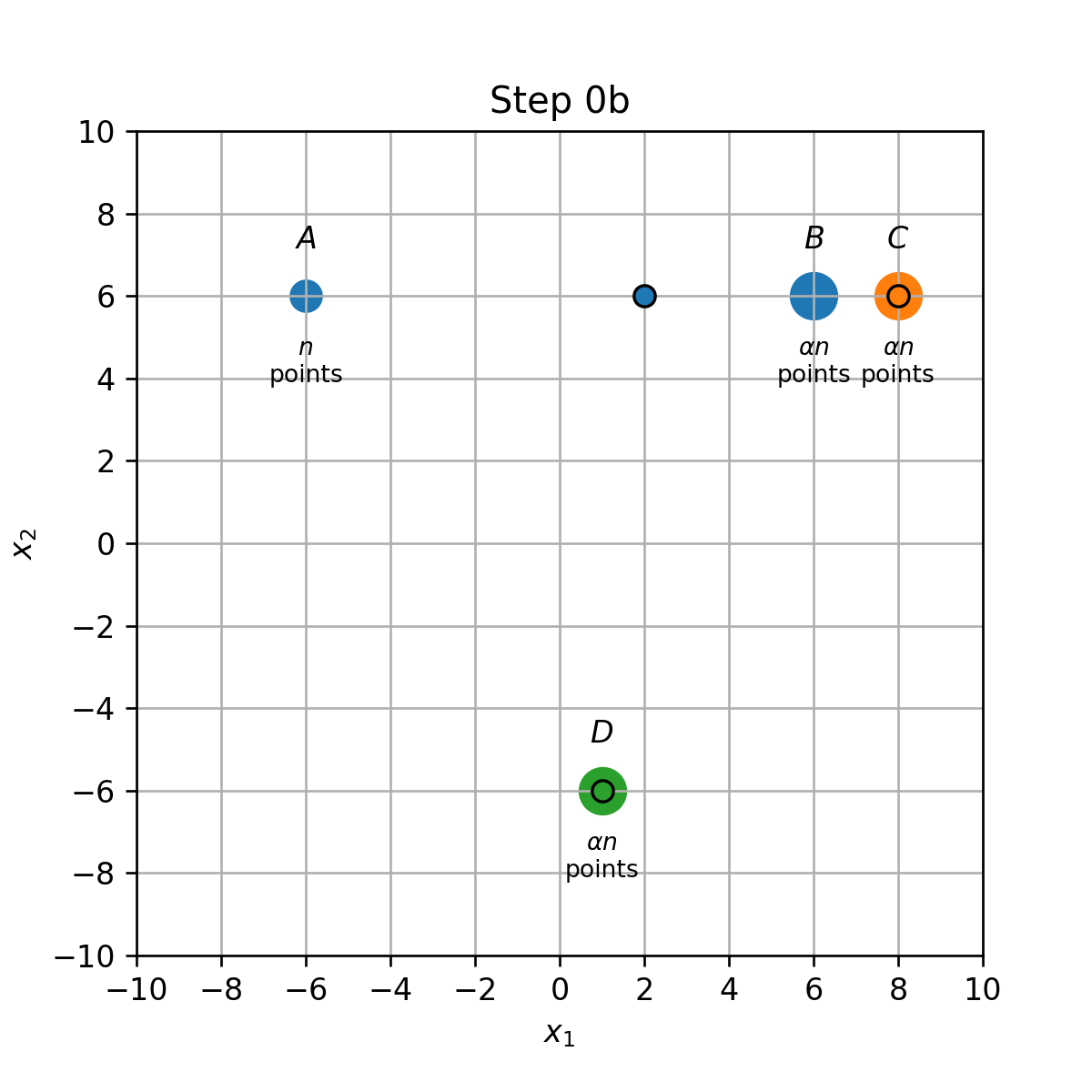
- עדכון מרכזים (0b): המרכז שב B יזוז לאמצע הדרך שבין הנקודות B ו D.
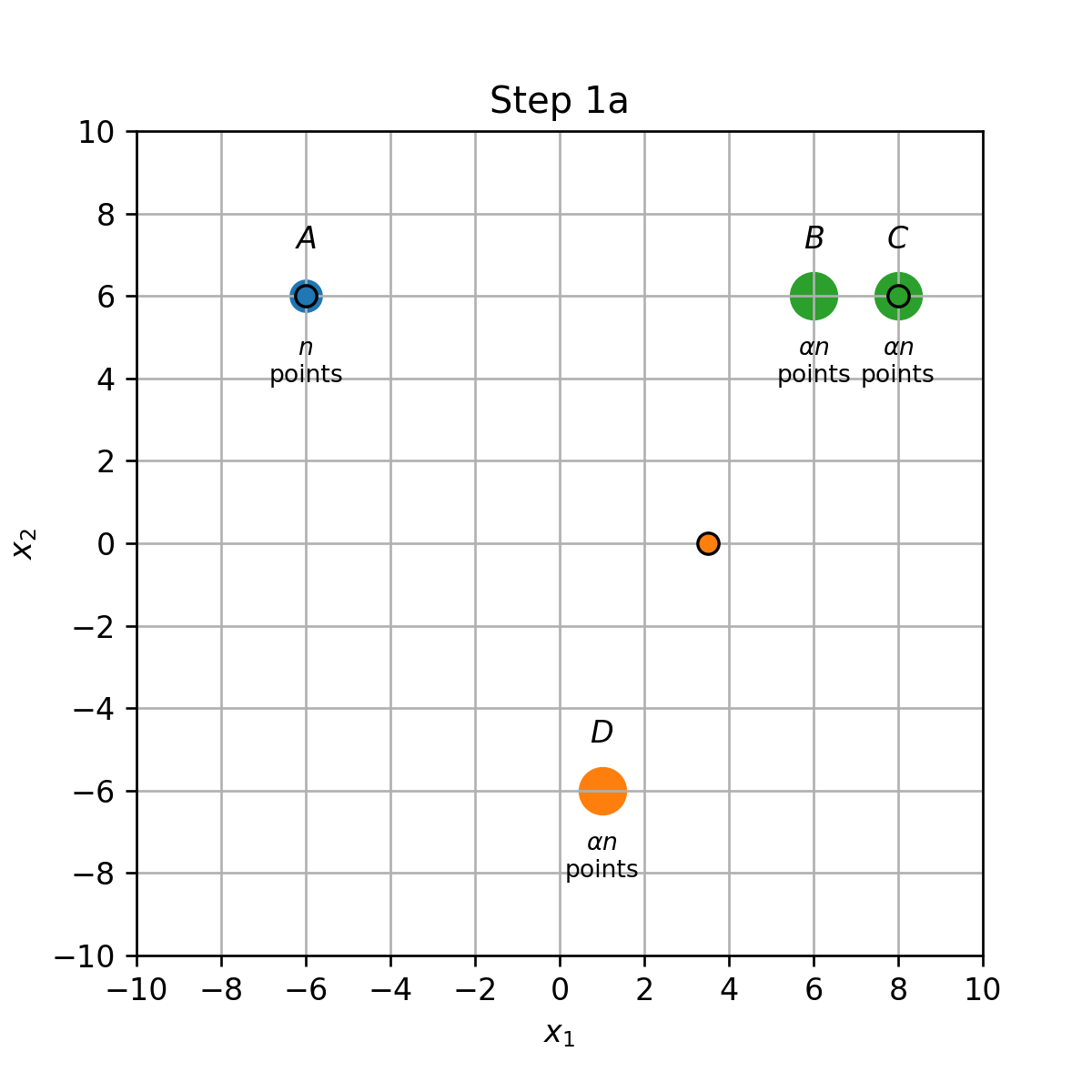
- עדכון אשכולות (1a): הנקודת שבB ישוייכו כעת למרכז שבC.
- עדכון מרכזים (1b): המרכז שבין B ל D יזוז לD, והמרכז שבC יזוז למחצית הדרך שבין B לC.
מרכזים ב A,B ו D:


- שיוך התחלתי (0a): נקודות בA,B ו D ישוייכו למרכז אשר נמצא עליהם, והנקודות בC ישוייכו למרכז שבB.
- עדכון מרכזים (0b): המרכז שב B יזוז לאמצע הדרך שבין הנקודות B ו C.
מרכזים ב A,C ו D:


- שיוך התחלתי (0a): נקודות בA,C ו D ישוייכו למרכז אשר נמצא עליהם, והנקודות בB ישוייכו למרכז שבC.
- עדכון מרכזים (0b): המרכז שב C יזוז לאמצע הדרך שבין הנקודות B ו C.
מרכזים ב B,C ו D:

- שיוך התחלתי (0a): נקודות בB,C ו D ישוייכו למרכז אשר נמצא עליהם, והנקודות בA ישוייכו למרכז שבB.
- עדכון מרכזים (0b): המרכז שב B יזוז לנקודה שהיא המרכז של הנקודות A ו B. (משום שכמות הנקודות בשתי הקבוצות שונה, נקודה זו היא לא אמצע הדרך בניהם).
השלב הבא של עידכון האשכולות תלוי במיקום של המרכז החדש.
מקרה 1: הנקודות ב-B קרובות יותר למרכז החדש מאשר למרכז שב-C ולכן האלגוריתם מסתיים.

מקרה 2, המרכז החדש רחוק יותר לנקודה B מאשר הנקודה C, אזי הנקודות בB יהיו מושייכות כעת למרכז בנקודה C, והמשך האלגוריתם יהיה:
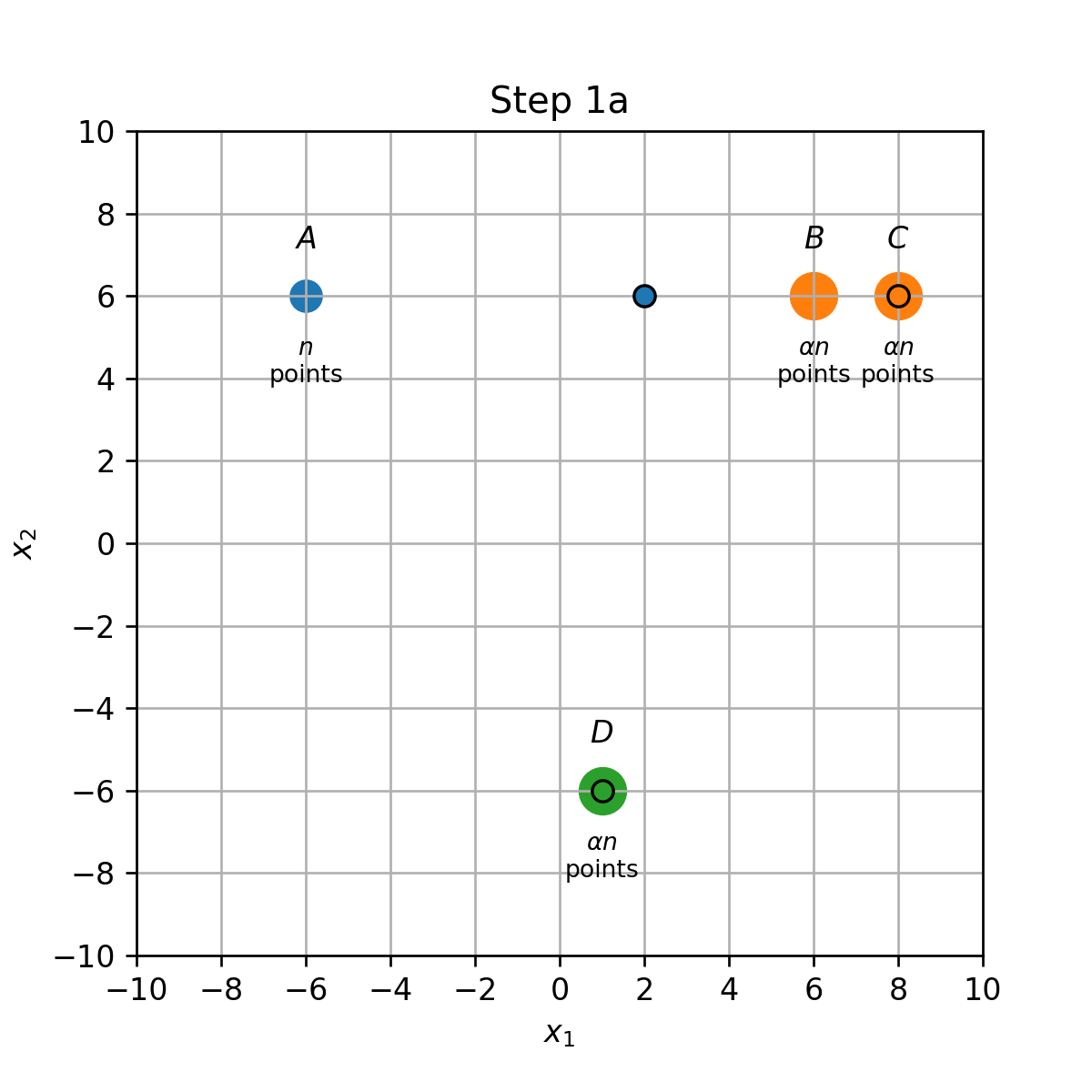

נמצא את התנאי על שבעבורו מתרחש מקרה 2. נסמן ב את המרכז שבין A לB לאחר עדכון המרכזים הראשון. המיקום של נתון על ידי הממוצע המשוכלל של הקואורדיאנטות A ו B:
על מנת שיתרחש עידכון, על המרחק בין המרכז החדש לנקודה B צריך להיות גדול מ2:
2)
ב) אנו מועניינים למצוא את האשכול אשר מביא למינימום את הפונקציית המטרה הבאה:
נוכל לפסול פתרונות בהן ישנו אשכול ריק, משום שבמקרה זה נוכל לשייך אליו נקודות כלשהן על מנת להקטין את פונקציית המטרה. לכן הפתרון האופטימאלי חייב להיות אחד מששת האישכולים הבאים:
- (A,B), (C), (D)
- (A,C), (B), (D)
- (A,D), (B), (C)
- (B,C), (A), (D)
- (B,D), (A), (C)
- (C,D), (A), (B)
התרומה של האשכולות שמכילים קבוצה בודדת לפונקציית המטרה הינה 0, ולכן יש לחשב רק את התרומה של האשכול שמכיל שתי קבוצות של נקודות. למשל, עבור האשכול (A,B), (C), (D) נקבל:
ועבור האשכול (B,C), (A), (D) נקבל:
נחשב את הערך של פונקצייות המטרה בעבור כל אחד מששת האשכולים:
| Clusters | Objective |
|---|---|
| (A,B), (C), (D) | |
| (A,C), (B), (D) | |
| (A,D), (B), (C) | |
| (B,C), (A), (D) | |
| (B,D), (A), (C) | |
| (C,D), (A), (B) |
נשים לב כי הפתרון האופטימאלי יהיה חייב להיות (A,B),(C),(D) או (B,C),(A),(D) (משום שכל השאר בהכרח גדולים מהם). נבדוק בעבור אלו ערכים של האשכול הראשון הינו האופטימאלי:
אם כן, בעבור הפתרון האופטימאלי הינו (A,B),(C),(D) ובעבור הפתרון האופטימאלי הינו (B,C),(A),(D).
נסכם כי עבור אתחול המרכזים בנקודות B,C ו-D נקבל:
- עבור האלגוריתם ישדך את B ו-C וזהו הפתרון האופטימאלי גלובלית.
- עבור האלגוריתם ישדך את A ו-B וזה הפתרון האופטימאלי גלובלית.
- עבור האלגוריתם ישדך את A ו-B אולם זהו אינו הפתרון הגלובלי.
נבדוק בעבור האתחולים מהסעיף הקודם, מהם המקרים שבהם האלגוריתם אינו מתכנס לפתרון האופטימאלי:
- בעבור הפתרון האופטימאלי הינו (A,B),(C),(D), אך עבור 3 מתוך 4 האיחולים שבדקנו האלגוריתם התכנס לפתרון של (B,C),(A),(D).
- בעבור הפתרון האופטימאלי הינו (B,C),(A),(D), אך במקרה של ואתחול של מרכזים ב B,C ו D מתקבל הפתרון של (A,B),(C),(D).
ג) כל המקרים שצויינו בסעיף הקודם. בנוסף, ניתן לדוגמא לאתחל שניים מתוך שלושת המרכזים בנקודות מאד רחוקות, ואז כל הנקודות ישוייכו למרכז השלישי.
חלק מעשי - מיקום חניונים בניו יורק
תזכורת: מדגם נסיעות המונית ב New York
נחזור למדגם של נסיעות מונית בניו-יורק בו השתמשנו בתרגולים הראשונים לחיזוי זמן הנסיעה. נציג את 10 הדגימות הראשונות במדגם (סה"כ במדגם זה 100,000 נסיעות).
| passenger count | trip distance | payment type | fare amount | tip amount | pickup easting | pickup northing | dropoff easting | dropoff northing | duration | day of week | day of month | time of day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2.76806 | 2 | 9.5 | 0 | 586.997 | 4512.98 | 588.155 | 4515.18 | 11.5167 | 3 | 13 | 12.8019 |
| 1 | 1 | 3.21868 | 2 | 10 | 0 | 587.152 | 4512.92 | 584.85 | 4512.63 | 12.6667 | 6 | 16 | 20.9614 |
| 2 | 1 | 2.57494 | 1 | 7 | 2.49 | 587.005 | 4513.36 | 585.434 | 4513.17 | 5.51667 | 0 | 31 | 20.4128 |
| 3 | 1 | 0.965604 | 1 | 7.5 | 1.65 | 586.649 | 4511.73 | 586.672 | 4512.55 | 9.88333 | 1 | 25 | 13.0314 |
| 4 | 1 | 2.46229 | 1 | 7.5 | 1.66 | 586.967 | 4511.89 | 585.262 | 4511.76 | 8.68333 | 2 | 5 | 7.70333 |
| 5 | 5 | 1.56106 | 1 | 7.5 | 2.2 | 585.926 | 4512.88 | 585.169 | 4511.54 | 9.43333 | 3 | 20 | 20.6672 |
| 6 | 1 | 2.57494 | 1 | 8 | 1 | 586.731 | 4515.08 | 588.71 | 4514.21 | 7.95 | 5 | 8 | 23.8419 |
| 7 | 1 | 0.80467 | 2 | 5 | 0 | 585.345 | 4509.71 | 585.844 | 4509.55 | 4.95 | 5 | 29 | 15.8314 |
| 8 | 1 | 3.6532 | 1 | 10 | 1.1 | 585.422 | 4509.48 | 583.671 | 4507.74 | 11.0667 | 5 | 8 | 2.09833 |
| 9 | 6 | 1.62543 | 1 | 5.5 | 1.36 | 587.875 | 4514.93 | 587.701 | 4513.71 | 4.21667 | 3 | 13 | 21.7831 |
הבעיה: מציאת חניונים
חברת מוניות רוצה לשכור מגרשי חניה ברחבי העיר NYC בהם יוכלו לחכות המוניות שלה בין הנסיעות.
לשם כך היא מעוניינת לבחור באופן אופטימאלי את המיקומים של מגרשי החניות האלו כך שהמרחק הממוצע מנקודת הורדת הנוסע למרגש החניה הקרוב יהיה מינימאלי.
שדות רלוונטיים
הפעם נתמקד בשני השדות הבאים מהמדגם:
- dropoff_easting - הקואורדינאטה האורכית (מזרח-מערב) של סיום הנסיעה
- dropoff_northing - הקואורדינאטה הרוחבית (צפון-דרום) של סיום הנסיעה
(למתעניינים: הקואורדינאטות נתונות בUTM-WGS84, היחידות הן בקירוב קילומטר).
ויזואליזציה של נקודות ההורדה
הגדרה פורמאלית של הבעיה
נשתמש בסימונים הבאים:
- הוקטור האקראי של מיקום סיום הנסיעה
- : מספר הנסיעות במדגם.
- הוקטור של מיקום סיום הנסיעה ה .
- : המיקום של מגרש החניה ה .
המטרה: למצוא את מיקומי החניונים האופטימאליים אשר ממזערים את הגודל הבא
מכיוון שהפילוג האמיתי של לא ידוע ננסה למזער את התוחלת האמפירית:
נרשום את הבעיה על ידי חלוקת המדגם לאשכולות. נגדיר את האשכול כאוסף של כל הנסיעות שהחניון ה הוא הקרוב ביותר לנקודת הסיום שלהן. באופן זה נוכל לרשום את בעיית האופטימיזציה באופן הבא:
פתרון באמצעות K-Means
נשים לב כי הבעיה שקיבלנו דומה מאד לבעיה אותה K-Means מנסה לפתור, עם הבדל משמעותי אחד. K-Means ממזער את המרחק הריבועי הממוצע בעוד שאנו מחפשים למזער את המרחק האוקלידי. ישנם אלגוריתמים מורכבים יותר אשר פותרים את הבעיה שלנו, אך לבינתיים נשאר עם K-Means.
נציין שזהו מצב נפוץ שבו איננו מסוגלים לפתור בעיה מסויימת באופן ישיר אז אנו פותרים בעיה דומה לה בתקווה לקבל תוצאות מספקות, אך לא בהכרח אופטמאליות.
נשתמש באלגוריתם K-means על מנת לבחור את המיקום של 10 מגרשי חניה.

המרחק נסיעה הממוצע המתקבל הינו:
חושב לציין שהפתרון הזה הוא לא בהכרח הפתרון האופטימאלי משתי סיבות:
- K-Mean לא מבטיח התכנסות למינימום הגלובלי. דרך אחת לשפר את תוצאות האלגוריתם הינה להריץ אותו מספר פעמים עם איתחולים שונים.
- כפי שציינו קודם K-Mean ממזערת את השגיאה הריבועית הממוצעת. ניתן אם כן לשפר קלות את התוצאות על ידי שמירה על האשכולות אך תיקון המרכז לנקודה אשר ממזערת את המרחק עצמו.
הערה הנקודה אשר ממזערת את המרחק האוקלידי (בלי הריבוע) בינה לבין כל הנקודות באשכול נקראת החציון הגיאומטרי The Geometric Median (wiki). ניתן למצוא נקודה זו על ידי שימוש באלגוריתם המוכונה Weiszfeld's algorithm.
מציאת מספר החניונים האופטימאלי
עד כה השתמשנו ב10 חניונים, נרצה כעת לבחור גם מספר זה בצורה מיטבית. באופן כללי ככל שנגדיל את מספר החניונים מרחק הנסיעה לחניונים יקטן, אך מנגד התחזוקה של כל חניון עולה כסף.
נניח כי:
- עלות האחזקה של חניון הינה 10k$ לחודש.
- בכל חודש יהיו בדיוק 100k נסיעות.
- עלות הנסיעה של מונית בדרך לחניון הינה 3$ לקילומטר.
נרשום תחת הנחות אלו את העלות החודשית של אחזקת החניונים והנסיעה אליהם:
והמקבילה האמפירית:
מספר החניונים כ Hyper parameter
כעת עלינו לבצע אופטימיזציה גם על מספר החניונים וגם המיקום שלהם. ראינו כיצד ניתן למצוא פתרון בעבור נתון, אך אין לנו דרך פשוטה להכליל את זה ל כלשהו. נוכל לעבור על כל ערכי הרלוונטים, לפתור את הבעיה עבורם ולבסוף לקחת את הפתרון הטוב ביותר. הוא למעשה hyper-parameter של הבעיה.
נריץ את אלגוריתם ה K-Means בעבור כל ערך של , נשרטט את עלות הנסיעה, עלות אחזקת החניונים והעלות הכוללת:
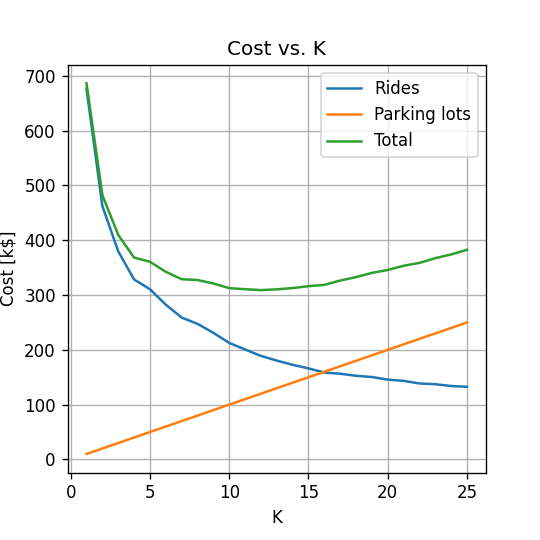
נקבל כי:
- מספר החניונים האופטימאלי הינו: 12.
- מרחק הנסיעה הממוצע יהיה 630 מ'.
- העלות הכוללת תהיה 308.12k$ לחודש.