בגישה זו ננסה ללמוד מודל פרמטרי אשר ימדל ישירות את py∣x(y∣x) (מבלי ללמוד את הפילוג של x). גישה זו יעילה מאד לבעיות סיווג, בהם קל לבנות מודלים פרמטריים py∣x(y∣x;θ) שהם פונקציות הסתברות חוקיות (חיובית שהסכום עליה הוא 1). את הפרמטרים של המודל הפרמטרי נלמד לרוב בעזרת MLE או MAP.
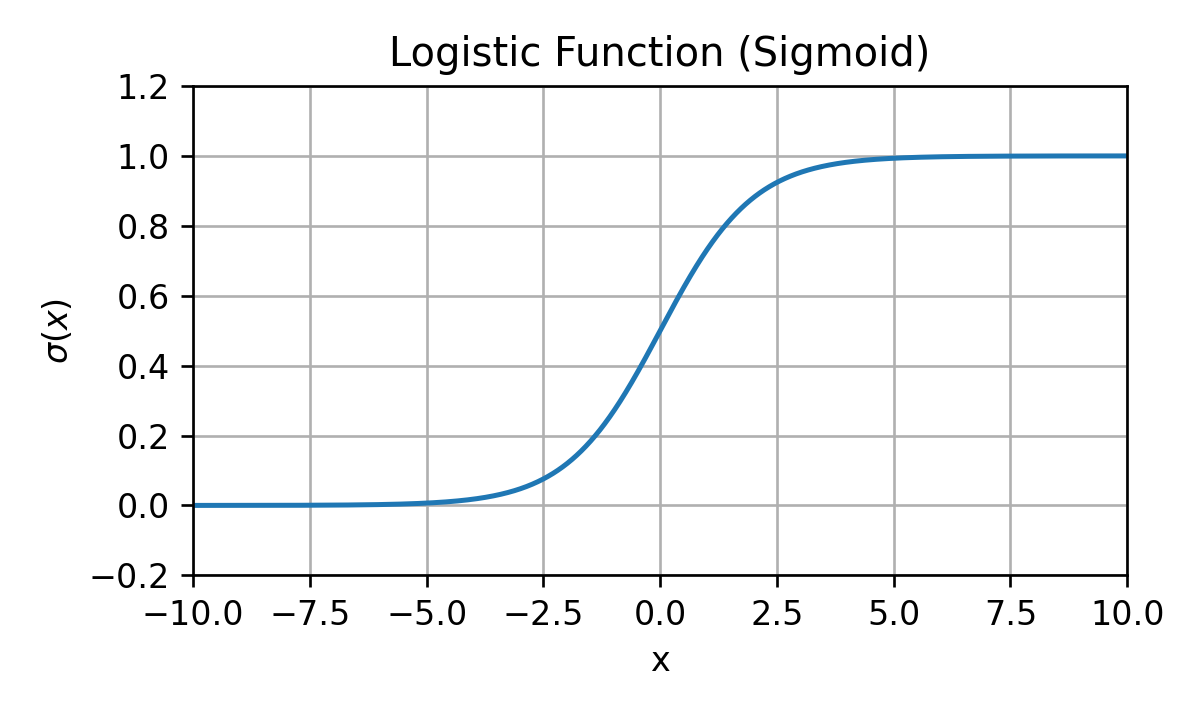
הפונקציה הלוגיסטית (סיגמואיד)
הפונקציה הלוגיסטית מקבלת מספר בתחום [−∞,∞] ומחזירה מספר בין 0 ל 1. היא לרוב מסומנת ב σ:
σ(z)=1+e−z1
והיא נראית כך:
פונקציה זו שימושית לצורך הגדרת מודלים הסתברותיים של משתנים בינארים.
הערה: בתחום של מערכות לומדות מקובל לכנות את הפונקציה הזו סיגמואיד (sigmoid) למרות שמבחינה מתמטית השם הזה מתאר משפחה הרבה יותר רחבה של פונקציות בעלות צורה של S.
תכונות
σ(−z)=1−σ(z).
∂z∂log(σ(z))=1−σ(z)
פונקציית ה Softmax
פונקציית ה softmax היא הרחבה של הפונקציה הלוגיסטית, והיא יכולה לשמש למידול פונקציות הסתברות של משתנים דיסקרטיים לא בינאריים (אך סופיים). הפונקציה לוקחת וקטור כלשהו z באורך C ומייצרת ממנו וקטור חדש חיובי שסכום האיברים שלו הוא 1. הפונקציה מוגדרת באופן הבא:
softmax(z)=∑c=1Cezc1[ez1,ez2,…,ezC]⊤
או לחילופין, הערך של האיבר ה i של הפונקציה הינו:
softmax(z)i=∑c=1Cezcezi
תכונות
אינווריאנטיות לתוספת של קבוע (לכל אברי הוקטור): softmax(z+a)i=softmax(z)i∀i.
בניגוד לשם, logistic regression היא שיטה לפתרון בעיות סיווג בגישה הדיסקרימינטיבית הסתברותית. בשיטה זו אנו נבחר C פונקציות פרמטריות כלשהן fc(x;θc) ונשתמש בהן על מנת לבנות מודל פרמטרי. נסמן:
את הוקטור θ כוקטור אשר כולל את כל C וקטורי הפרמטרים: θ=[θ1⊤,θ2⊤,…,θC⊤]⊤.
את הפונקציה f כפונקציה המאגדת את כל C הפונקציות הפרמטריות: f=[f1(x;θ1),f2(x;θ2),…,fC(x;θC)]⊤
לבעיות ה MLE וה MAP של מודל זה אין פתרון סגור ואנו נחפש את הפתרון לבעיית האופטימיזציה בעזרת gradient descent.
ביטול היתירות של המודל
בגלל האינווריאנטיות של פונקציית ה softmax המודל הפרמטרי המוגדר על ידי הפונקציות fc יהיה אינווריאנטי לשינויים מהצורה של: fc(x;θc)→fc(x;θc)+g(x).
דרך נפוצה לבטל יתירות זו הינה על ידי קיבוע של אחת הפונקציות הפרמטריות, לרוב הראשונה c=1, להיות שווה זהותית ל 0: f1(x;θ1)=0.
המקרה הבינארי
במקרה הבינארי ישנם רק שתי מחלקות (C=2), אותן נסמן ב 0 ו 1. נקבע את הפונקציה הפרמטרית של המחלקה y=0 להיות זהותית 0. נקבל את המודל הפרמטרי הבא:
הגרסא הלינארית של הרגרסיה הלוגיסטית היא המקרה שבו בוחרים את הפונקציות הפרמטריות להיות פונקציות לינאריות:
fc(x;θc)=θc⊤x
במקרה זה פונקציית ה objective שיש למזער היא קמורה (convex) ולכן מובטח ש gradient descnet, במידה והוא מתכנס, יתכנס למינימום גלובלי.
Gradient descent (שיטת הגרדיאנט)
בעבור בעיית המינימיזציה:
θargming(θ)
Gradient descent מנסה למצוא מינימום לוקאלי של g(θ) על ידי כך שהוא מתחיל בנקודה אקראית כלשהי במרחב ואז מתקדם בצעדים קטנים בכיוון ההפוך מהגרדיאנט, שהוא הכיוון שבו ה objective קטן בקצב המהיר ביותר. זהו אלגוריתם חמדן (greedy) אשר מנסה בכל צעד לשפר במעט את מצבו ביחס לשלב הקודם.
האלגוריתם
מאתחלים את θ(0) בנקודה אקראית כלשהי.
חוזרים על צעד העדכון הבא עד שמתקיים תנאי עצירה כל שהוא:
θ(t+1)=θ(t)−η∇θg(θ(t))
הפרמטר η קובע את גודל הצעדים שהאלגוריתם יעשה.
תנאי עצירה
ישנם מספר דרכים להגדיר תנאי עצירה לאגוריתם:
הגעה למספר צעדי עדכון שנקבע מראש: t>max-iter.
כאשר הנורמה של הגרדיאנט קטנה מתחת לערך סף מסויים שנקבע מראש: ∥∇θg(θ)∥2<ϵ
כאשר השיפור ב objective קטן מערך סף מסויים שנקבע מראש: g(θ(t−1))−g(θ(t))<ϵ
שימוש בעצירה מוקדמת על מנת להתמודד עם overfitting (נרחיב על כך בהרצאה הבאה)
בעיית הבחירה של גודל הצעד
בכדי לגרום לאלגוריתם להתכנס (ולא להתבדר) אנו נאלץ לבחור גודל צעד שהוא לא גדול מידי. בפועל, בצורתו הפשוטה אלגוריתם ה gradient descent הוא מאד בעייתי משום שבכדי למנוע התבדרות גודל הצעד צריך להיות מאד קטן שידרוש מספר לא פרקטי של צעדים לצורך התכנסות.
תרגיל 9.1 - אופטימליות של כיוון גרדיאנט שלילי
תהי f(x),x∈Rd פונקציה ממשית גזירה פעמיים.
נתונה נקודה
xα=x+αd,d∈Rd,∥d∥=1,α≥0.
מפיתוח טיילור לסדר שני עם שארית מתקיים
f(xα)=f(x)+αd⊤∇f(x)+O(α2)
כאשר O(α2) קטן בהרבה מ-αd⊤∇f(x) עבור α קטנה מספיק.
שאלה מה הכיוון d שמוביל לירידה הכי גדולה בערך של f(x) עבור ערך α קטן?
תזכורת אי שוויון קושי שוורץ קובע כי עבור מרחב מכפלה פנימית V מתקיים לכל x,y∈V
⟨x,y⟩≤∥x∥⋅∥y∥
כאשר שוויון מתקיים כאשר שני הווקטורים באותו הכיוון.
פתרון 9.1
כדי לענות על שאלה זאת נרצה שהביטוי αd⊤(−∇f(x)) יהיה גדול ככל האפשר.
נשים לב כי מדובר במכפלה פנימית ולכן נשתמש באי שוויון קושי שוורץ
αd⊤(−∇f(x))=⟨αd,−∇f(x)⟩≤∥αd∥⋅∥−∇f(x)∥=α∥∇f(x)∥
לכן הכיוון d עבורו נקבל את הירידה הכי גדולה בערך של f(x) הוא
d=−∥∇f(x)∥∇f(x)
מסקנה
הכיוון השלילי של הגרדיאנט, d∝−∇f(x), הוא הכיוון שמוביל לירידה המקסימלית בערך הפונקציה בסביבה מקומית של x.
הבחנה
כל כיוון d עבורו d⊤(−∇f(x))>0 מוביל לירידה בערך הפונקציה f(x).
תרגיל 9.2 - אלגוריתם הגרדיאנט
נתונה בעיית האופטימיזציה הבאה:
θargmin21θ2+5sin(θ)
1) נסו לפתור את הבעיה על ידי גזירה והשוואה ל-0. הגיעו למשוואה (סתומה) אשר מגדירה את נקודות המינימום האפשריות.
2) רשמו את צעד העידכון של אלגוריתם הגרדיאנט.
3) חשבו את שלושת צעדי העדכון הראשונים עבור אתחול של θ(0)=0, וצעד לימוד של η=0.1.
4) חשבו את שלושת צעדי העדכון הראשונים עבור אתחול של θ(0)=2.5, וצעד לימוד של η=0.1. מודע האלגוריתם יתכנס כעת לפתרון אחר מבסעיף הקודם?
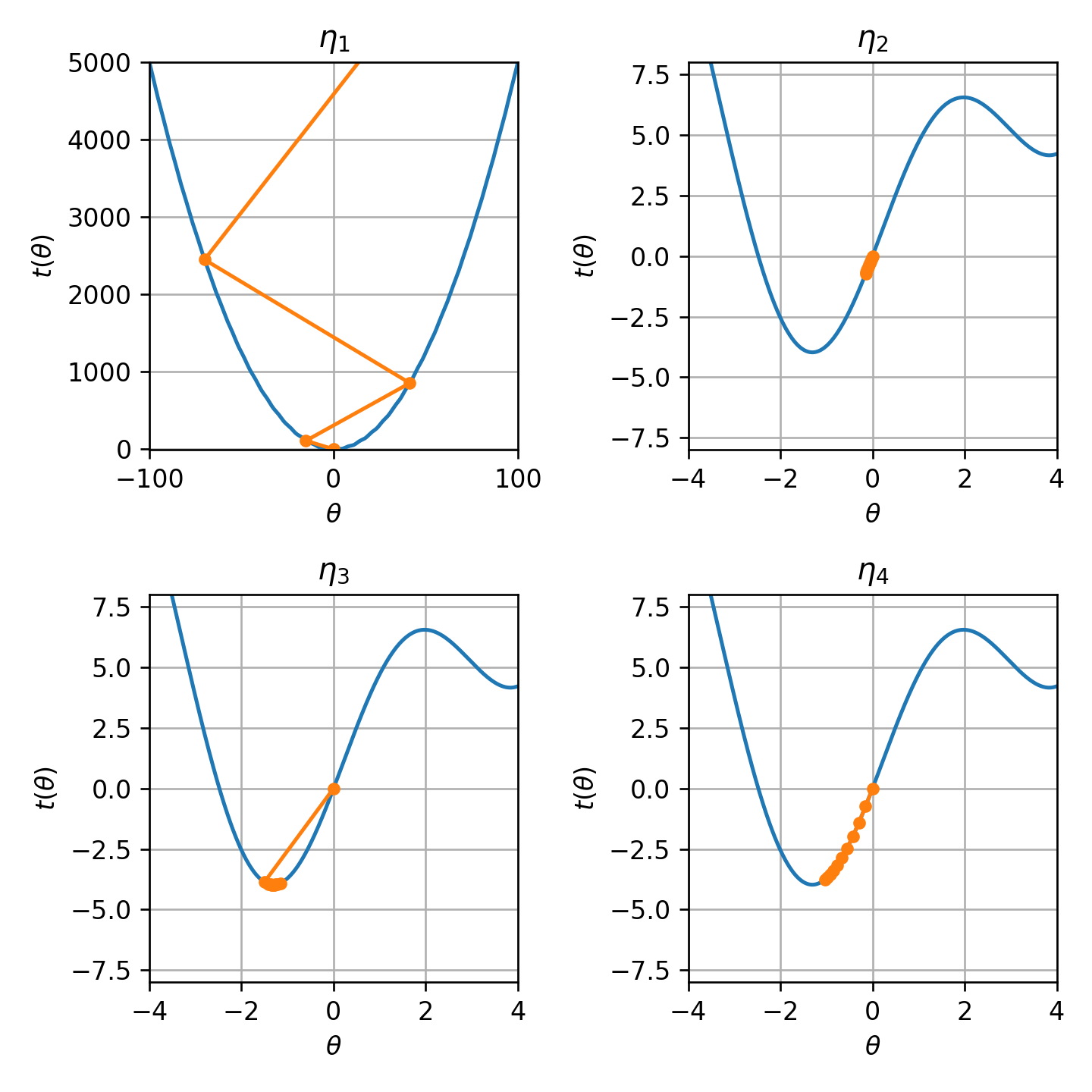
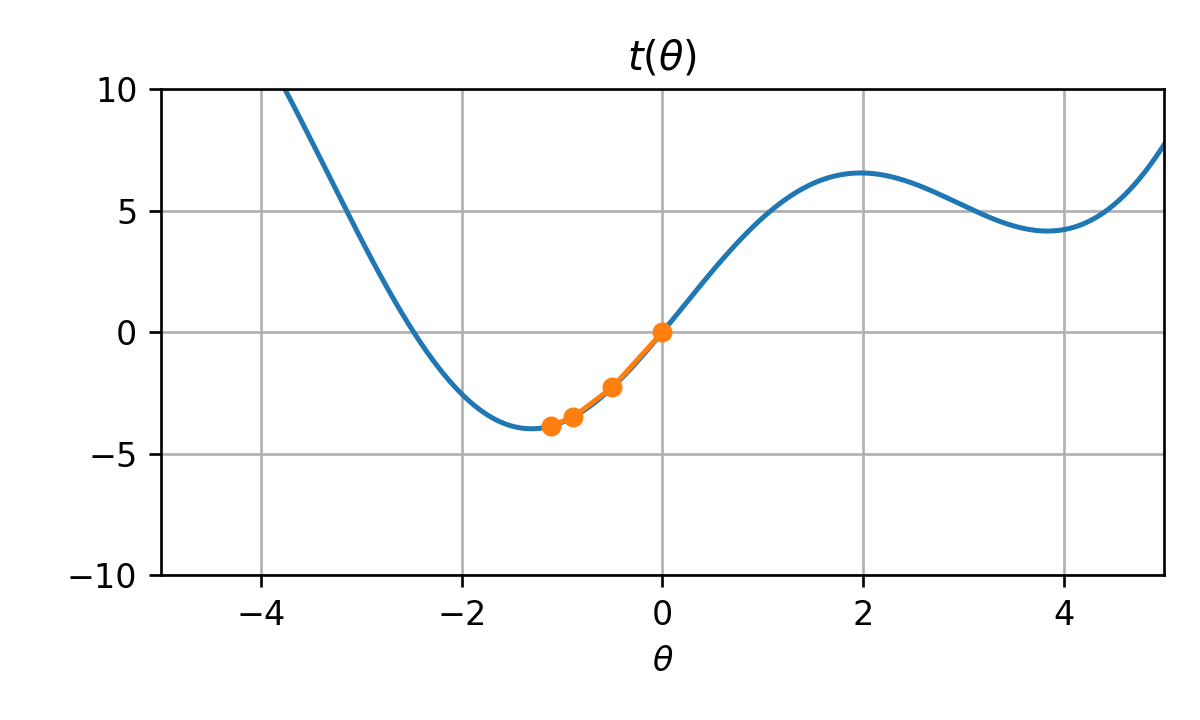
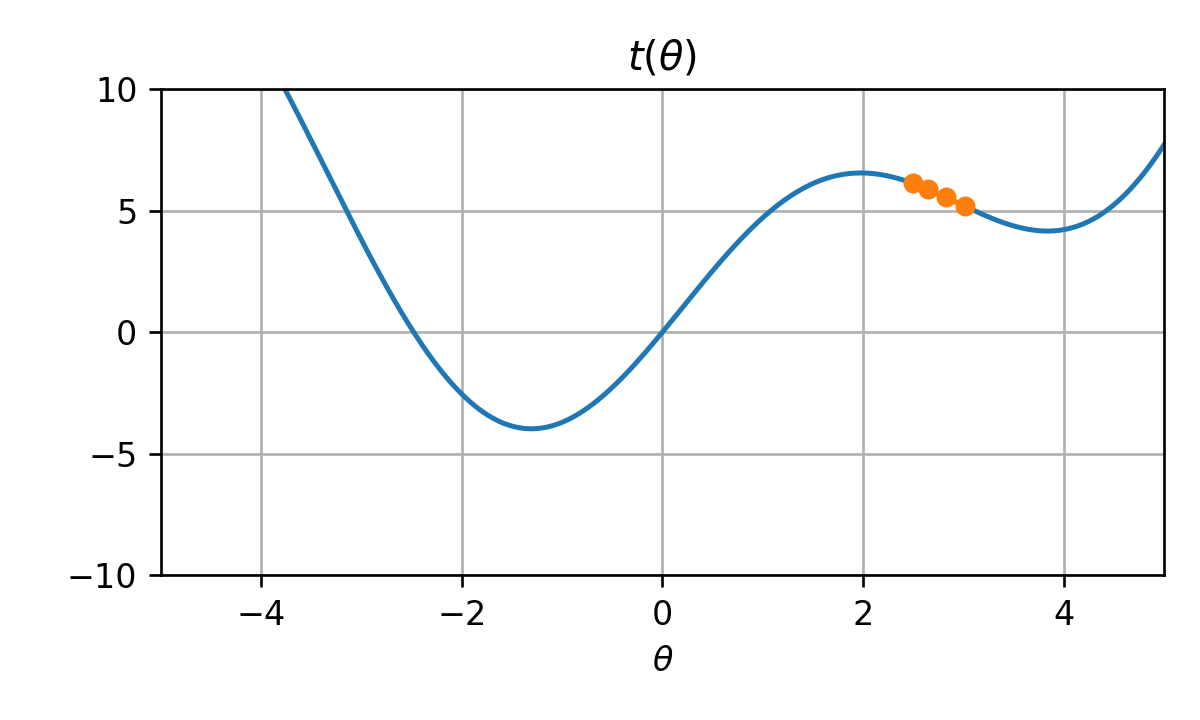
5) הגרפים הבאים מציגים עשר איטרציות של gradient descent בעבור ארבעה ערכים שונים של גודל צעד: η={0.003,0.03,0.3,3}. התאם בין גודל הצעד לגרפים.
פתרון 9.2
1)
נסמן את ה objective (פונקציית המטרה) של בעיית האופטימיזציה ב:
t(θ)=21θ2+5sin(θ)
נגזור אותו ונשווה אותו ל-0:
∂θ∂t(θ)⇔θ+5cos(θ)⇔θ=0=0=−5cos(θ)
בפועל זה אומר שעלינו למצוא את נקודות החיתוך של הפונקציות הבאות:
למשוואה זו אין פתרון אנליטי.
2)
צעד העדכון של הגרדיאנט יהיה:
θ(t+1)=θ(t)−η∂θ∂t(θ)=θ(t)−η(θ(t)+5cos(θ(t)))
3)
נאתחל את האלגוריתם עם θ(0)=0 ונבצע שלושה צעדים (עם η=0.1):
נחזור על הפתרון עם אתחול של θ(0)=2.5 ונבצע שלושה צעדים:
θ(1)=2.65θ(2)=2.83θ(2)=3.02
בעבור האתחול הזה אלגוריתם יתכנס לפתרון אחר מאשר הפתרון בסעיף הקודם. זאת כמובן משום ש gradient descent מתכנס למינימום לוקאלי, לכן בעבור איתחולים שונים האלגוריתם עלול להתכנס לפתרונות שונים.
5)
הפרמטר η קובע כאמור את גדול הצעד.
גודל צעד גדול מידי עשוי להרחיק בכל צעד את האלגוריתם מנקודת המינימום, כפי שקורה במקרה של η1. גודל הצעד שמתאים למקרה זה הינו הערך הגדול ביותר, זאת אומרת 3.
גודל הצעד השני הכי גדול הינו 0.3 והוא מתאים ל η3. במקרה זה הצעדים עושים "over shoot" ועוברים במרבית הפעמים את המינימום אך עדיין מתקרבים אליו בכל צעד.
גודל הצעד השלישי הכי גדול הינו 0.03 הוא מתאים ל η4. כאן האופטימיזציה מתקדמת לאט לאט באופן עקבי לכיוון המינימים.
גודל הצעד הקטן ביות הינו 0.003 והוא מתאים ל η2 במקרה זה ההתקדמות היא מאד איטית ויקח לאלגוריתם מספר רב של צעדים על מנת להתקרב למינימום.
תרגיל 9.3 - צעד העדכון של logistic regression
1) בעבור המקרה של רגרסיה לוגיסטית בינארית, הראו כי ניתן לרשום את המודל של פונקציית ההסתברות המותנית באופן הבא:
py∣x(y∣x;θ)=σ((−1)y+1f(x;θ))
2) נסתכל על אלגוריתם gradient descent אשר מנסה למצוא פיתרון לבעיית ה MLE בעבור רגרסיה לוגיסטית בינארית. הראו שניתן לרשום את צעד העדכון של האלגוריתם באופן הבא:
3) ננסה לתת פרשנות אינטואיטיבית לתפקיד של האיברים השונים בצעד העדכון מהסעיף הקודם.
נתחיל בכך שנתעלם מהביטוי (1−py∣x(y(i)∣x(i);θ)). ונקבל את צעד העדכון הבא:
θ(t+1)=θ(t)−ηi=1∑N(−1)y(i)∇θf(x(i);θ(t))
הסבירו כיצד ישפיע כל צעד עידכון על הפונקציה f(x;θ). ספציפית הסבירו מה יקרה לערך של הפונקציה בנקודות x(i)? התייחסו להשפעה השונה יש לדגימות עם y=1 ולדגימות עם y=0 מהמדגם.
4) נחזיר כעת את האיבר (1−py∣x(y(i)∣x(i);θ)). למה שווה איבר זה במקרים בהם המודל הפרמטרי נותן הסתברות גבוהה לדגימה כלשהי {x(i),y(i)}? ולמה הוא שווה במקרים בהם המודל נותן הסתברות נמוכה לדגימה כלשהי?
התייחסו לאיבר זה כאל איבר מישקול, אשר נותן משקל שונה לכל דגימה מהמדגם. הסבירו מה תהיה ההשפעה של משקול זה על צעד העדכון.
5) (לקריאה עצמית) נרחיב את הדוגמא למקרה הלא בינארי. הראו שניתן לכתוב את צעד העדכון של אלגוריתם ה gradient discent במקרה הלא בינארי באופן הבא:
נסתכל על התרומה של הדגימות מהמדגם ששייכים למחלקה y=1 (אשר גורר: (−1)y=−1). איברים אלו ינסו לשנות את θ בכיוון הגרדיאנט בנקודות x(i) ששיכות למחלקה. זאת אומרת, שהם ינסו לגרום לשינוי של הפרמטריים כך שהערך של הפונקציה הפרמטרית f(x;θ) בנקודות x(i) יהיה גדול יותר.
באופן הפוך, התרומה של הדגימות מהמחלקה y=0 (ו (−1)y=1) תהיה לנסות ולעדכן את θ בכיוון ההפוך מהגרדיאנט. זאת אומרת, שהם ינסו להקטין את הערך של f(x;θ) בנקודות x(i) מהמחלקה y=0.
בסה"כ הכל נקבל שהאלגוריתם ינסה בכל צעד לשנות את f(x;θ) כך שיניב ערכים גבוהים על הנקודות x שמתאימות ל y=1 וערכים נמוכים על הנקודות שמתאימות ל y=0. התנהגות זו הגיונית משום שזה בדיוק מה שאנחנו רוצים מהמודל שלנו, שאמור לחזות את ההסתברות ש y=1 בהינתן x. משום שהסתברות זו שווה ל σ(f(x;θ)) אנו רוצים רוצים ש f יניב ערכים גבוהים באיזורים שבהם y=1 בסבירות גבוהה בהינתן x וערכים נמוכים בשאר המקומות.
4)
נסתכל על הביטוי (1−py∣x(y(i)∣x(i);θ)). נזכור שההסתברות py∣x היא מספר בין 0 ל 1.האיבר כולו יהיה לכן קרוב ל-0 כאשר הסתברות של y מסויים בהינתן x היא גבוהה והוא יהיה קרוב ל-1 כאשר ההסתברות נמוכה.
נזכור גם כי py∣x(y(i)∣x(i);θ) היא אינה ההסתברות האמיתית של x ו y אלא ההסתברות שהמודל שלנו נותן לדגימה כלשהי מהמדגם. (אנו רוצים שבסופו של דבר שמודל זה יהיה קרוב להסתברות האמיתית). היינו מעניינים שככל שנעשה יותר צעדי עדכון המודל יגדיל לאט לאט את ההסתברות שהוא נותן לדגימות במדגם (זו בעצם המטרה של MLE ו MAP).
נסתכל על איבר זה כעל משקל בין 0 ל 1 שמשוייך לכל דגימה במדגם. לדגימות שהמודל חושב הם סבירות הוא נותן משקל קרוב ל 0 ולדגימות שהמודל נותן להם סבירות נמוכה הוא נותן משקל 1. מה שאיבר זה עושה לצעד העידכון הוא לגרום לו יחסית להתעלם מדגימות שכבר מקבלות סבירות גבוהה ולהתמקד בדגימות שהוא עדיין "טועה" עליהם, זאת אומרת, שהוא נותן להם הסתברות נמוכה.
האיבר (δy(i),c−py∣x(c∣x(i);θ(t))) הוא חיובי כאשר c=y(i) ושלילי אחרת. איבר זה גורם לכך שבעבור כל דגימה מהמדגם צעד העדכון ינסה לגדיל את הפונקציה הפרמטרית fc(x(i);θc(t)) שבה c=y(i) ויקטין את הפונקציות הפרמטריות שבהם c=y(i).
בדומה למקרה הבינארי ככל שהסבירות של הדגימה במדגם py∣x(y(i)∣x(i);θ) כך ההשפעה של הדגימה על העדכון יהיה קטן יותר.
תרגיל 9.4 - MLE and KL divergence
בתרגיל זה נציג דרך אחרת לפתח את בעיית האופטימיזציה של משערך ה MLE.
נתון לנו מדגם של N דגימות i.i.d. של משתנה אקראי כלשהו x:
D={x(i)}i=1N
ומודל פרמטרי כל שהוא px(x;θ). נרצה לבחור את הפרמטרים של המודל θ כך שהמודל יתאר בצורה טובה את הדגימות במדגם.
לשם כך נשתמש במדד הבא אשר מודד עד כמה פונקציית צפיפות הסתברות כלשהי qx(x) תהיה טובה בכדי לתאר דגימות המגיעות מצפיפות הסתברות אחרת px(x). המדד נקרא Kullback-Leibler divergence והוא מוגד באופן הבא:
הסימון E(p) הוא תוחלת לפי הפילוג px. מדד זה מגיע מתורת האינפורמציה ואנו לא ניכנס למשמעות ולמקור של מדד זה. ככל שהמדד נמוך יותר כך הפילוגים קרובים יותר.
השתמשו במדד זה על מנת להגדיר בעיית אופטימיזציה שבוחרת את הפרמטרים של המודל כפרמטרים כך שהם ממזערים את ה Kullback-Leibler divergence בין המודל הפרמטרי לפילוג האמיתי. בכדי להיפתר מהתוחלת על הפילוג הלא ידוע החליפו אותו בתוחלת אמפירית על המדגם. הראו כי בעיית האופטימיזציה המתקבלת זהה לזו של משערך ה MLE.
פתרון 9.4
נסמן את הפילוג האמיתי (הלא ידוע) של x ב px(x) (בלי θ). בעיית האופטימיזציה שהיינו רוצים לפתור הינה:
שיטה נפוצה כיום לאבחון של סרטן הינה בשיטת Fine-needle aspiration. בשיטה זו נלקחת דגימה של רקמה בעזרת מחט ומבוצעת אנליזה בעזרת מיקרוסקופ על מנת לאבחן שני מקרים:
Malignant - רקמה סרטנית
or Benign - רקמה בריאה
להלן דוגמא לתמונת מיקרוסקופ של דגימה שכזו:
בתרגול זה נעבוד עם מדגם בשם Breast Cancer Wisconsin Diagnostic אשר נאסף על ידי חוקרים מאוניברסיטת ויסקונסין. הוא כולל 30 ערכים מספריים, כגון שטח התא הממוצע והרדיוס ההמוצע, אשר חושבו בעבור 569 דגימות שונות. בנוסף יש לכל דגימה במדגם תווית של האם הדגימה הינה סרטנית או לא.
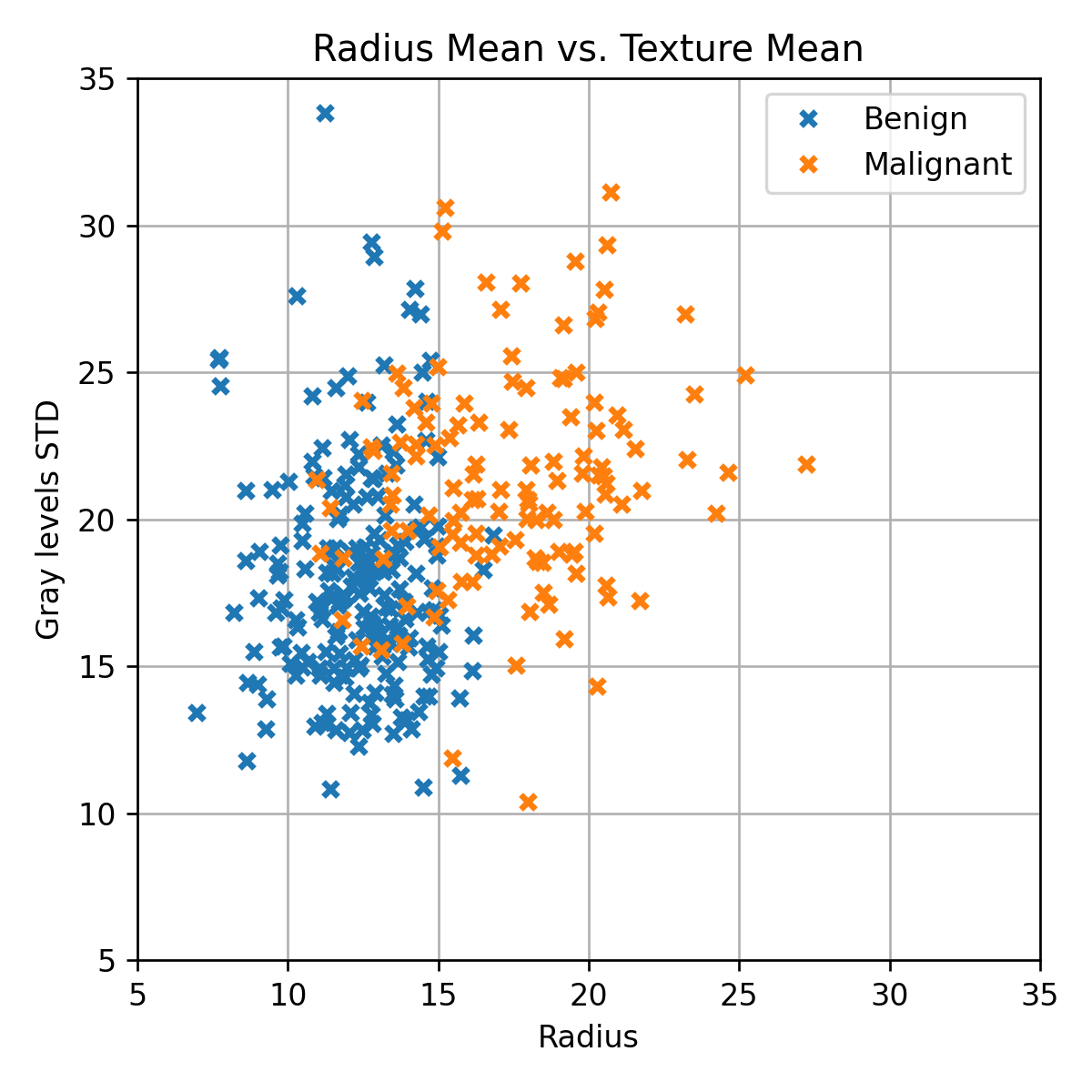
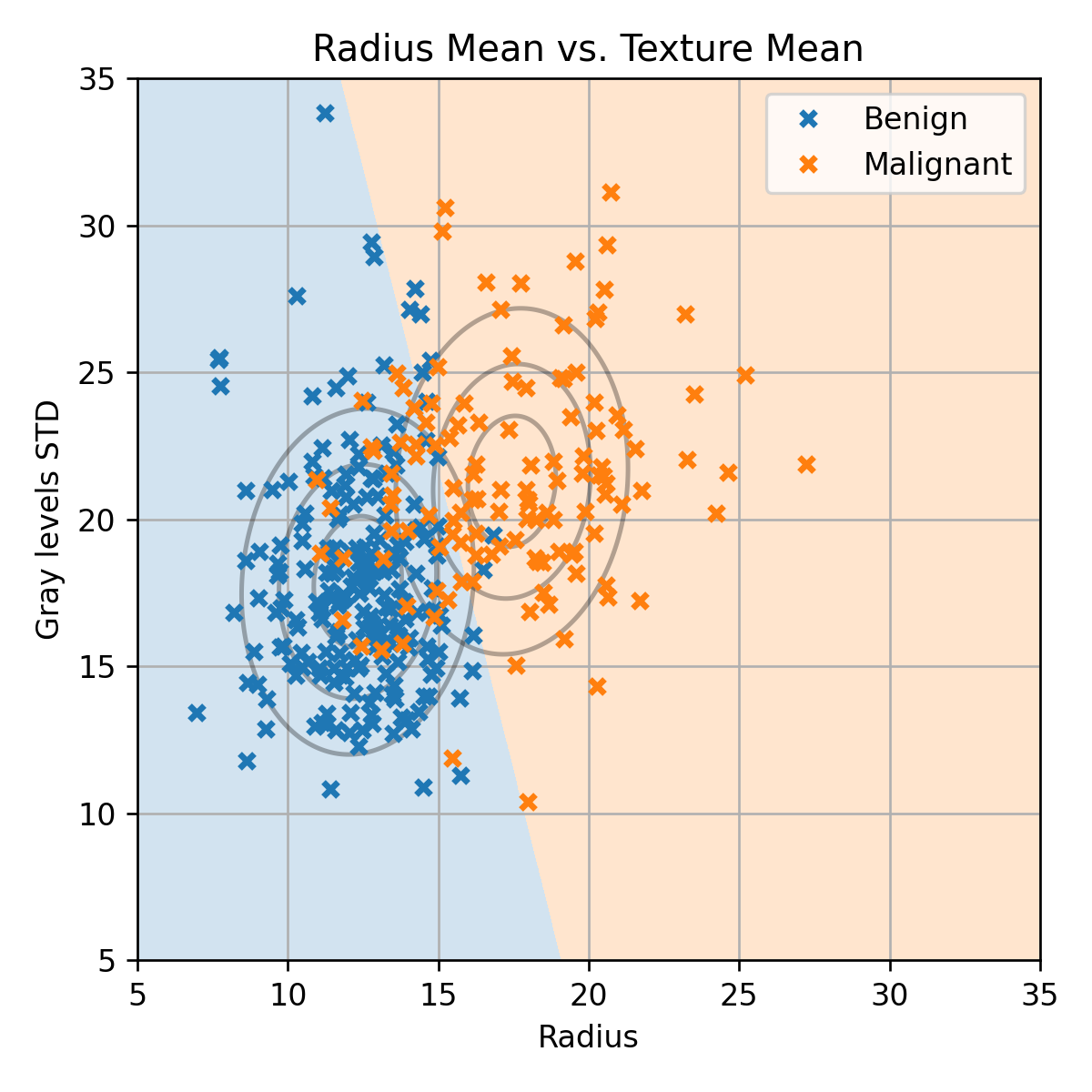
רק לשם המחשה נתחיל בניסיון לחזות האם הרקמה סרטנית או לא רק על פי שני השדות הראשונים:
radius_mean - רדיוס התא הממוצא בדגימה.
texture_mean - סטיית התקן הממוצעת של רמת האפור בצבע של כל תא בדגימה.
השדה של התוויות y הינו:
diagnosis - התווית של הדגימה: M = malignant (סרטני), B = benign (בריא)
(בחרנו להתחיל עם 2 שדות משום שמעבר לכך כבר לא נוכל לשרטט את הפילוג של הדגימות ואת החיזוי).
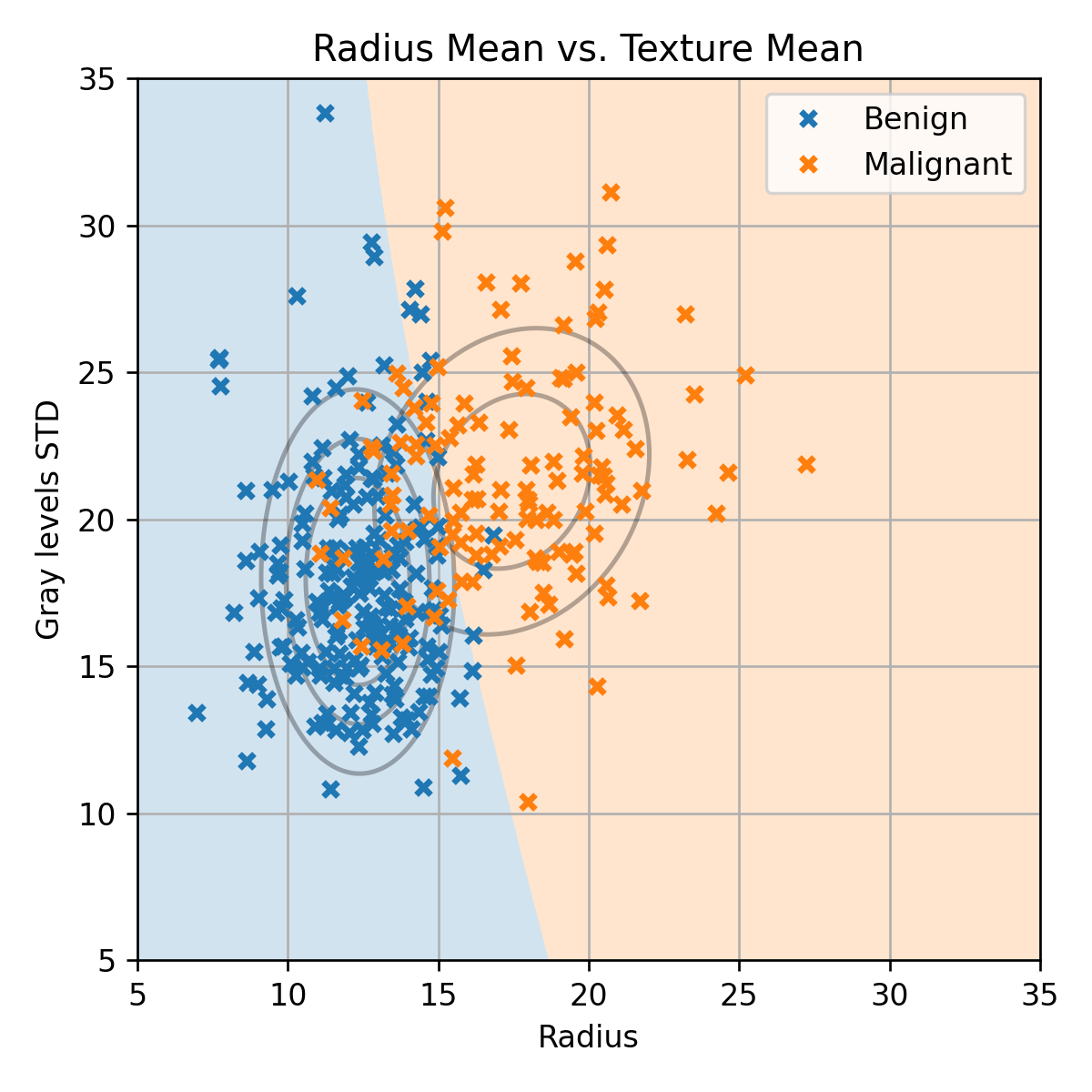
נרצה למצוא חזאי אשר יפריד בין הנקודות הכתומות לנקודות הכחולות. לשם כך נפצל את המדגם ל 60% train / 20% validation / 20% test. נתאים שלושה מודלים: LDA, QDA, linear logistic regression.
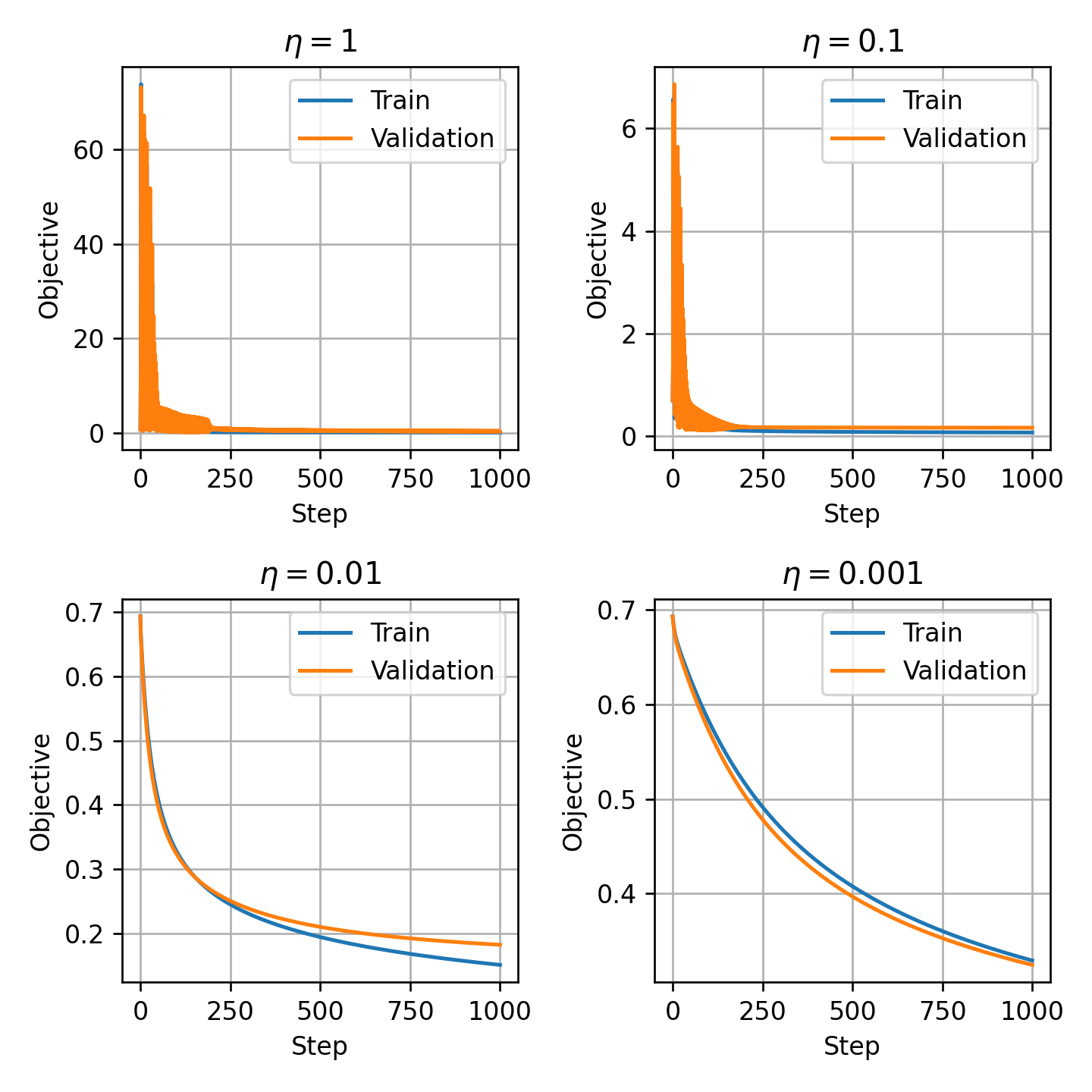
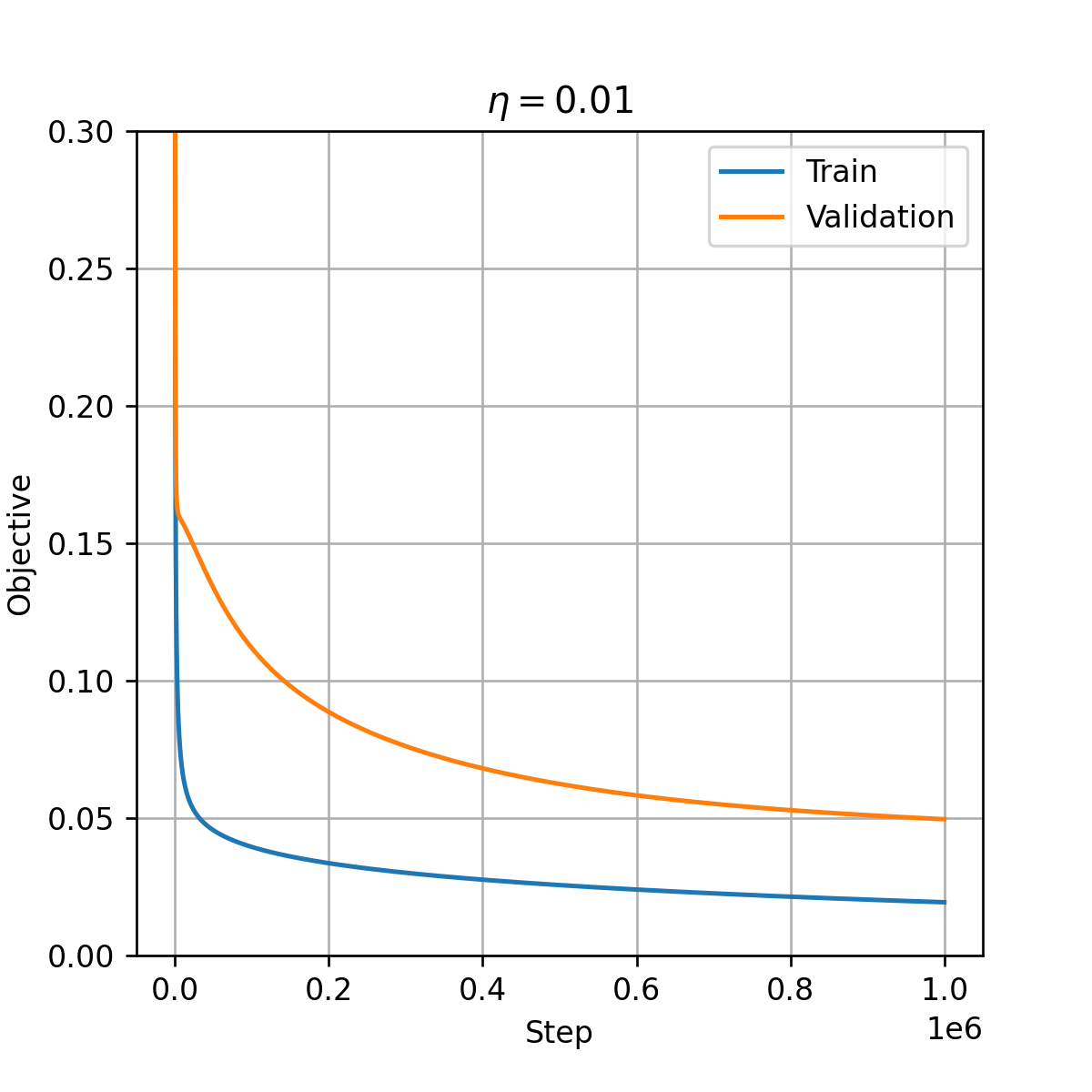
נשתמש ב gradient descent על מנת למצוא את הפרמטרים של המודל. בכדי לבחור את גודל הצעד ננסה כמה ערכים שונים ונריץ את האלגוריתם מספר קטן של צעדים (1000) ונבחר את גודל הצעד הגדול ביותר אשר גורם למודל להתכנס. בדוגמא זו נציג את התוצאות בעבור 4 ערכים של גודל הצעד:
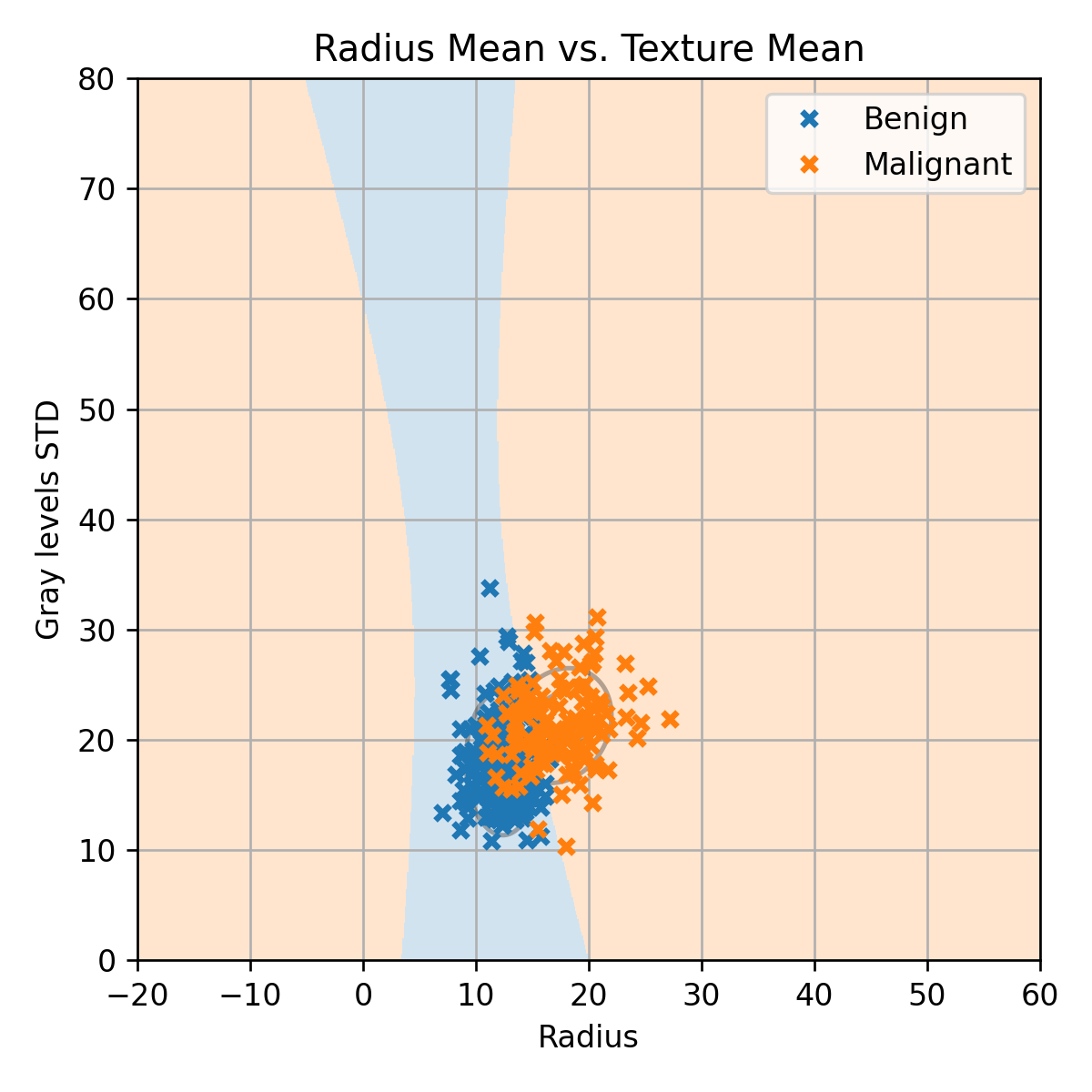
בגרפים האלה רואים את החישוב של ה objective על ה train set ועל ה validation set כפונקציה של מספר הצעדים. נשים לב שבעבור בחירה של η=0.1 או η=1 המודל מתבדר לערכים מאד גדולים וזה ימנע ממנו להתכנס למינימום של הפונקציית המטרה. נבחר אם כן את גודל הצעד להיות η=0.01 ונריץ את האלגוריתם מספר רב של צעדים (1000000):
נראה אם כן שגם אחרי מליון צעדים האלגוריתם עדיין לא התכנס. כפי שציינו זוהי אחת הבעיות העיקריות של אלגוריתם הגרדיאנט בצורתו הפשוטה. למזלנו, ישנן מספר שיטות פשוטות לשפר את האלגוריתם בכדי לפתור בעיה זו אך אנו לא נפרט עליהן בקורס זה.
הביצועים של המודל עם הפרמטרים המתקבלים אחרי מיליון צעדים נותנים miscalssification rate של 0.02 שזה דומה לתוצאה שקיבלנו על ידי שימוש ב QDA.