Curse of dimensionality: השיטות הלא פרמטריות לומדות את הפילוג בכל איזור על פי הדגימות שנמצאות באותו איזור באופן בלתי תלוי באיזורים האחרים במרחב. עקב כך, שיטות אלו דורשות כמות דגימות כזו שתכסה בצורה מספיק טובה את כל האיזורים הסבירים של מרחב הדגימות האפשריות. הבעיה היא שהגדול האפקטיבי של מרחב הדגימות גדל בצורה מעריכית עם המימד של הדגימות (האורך של הוקטור x), לכן, בעבור מקרים שבהם המימד של דגימות הוא גדול, כמות הדגימות לרוב לא יחסכו בצורה טובה את המרחב ולכן השיערוך יהיה מאד לא מדוייק.
המודלים המתקבלים בשיערוך לא פרמטרי הם לרוב לא פונקציות שנוח לעבוד איתן. לדוגמא, על מנת לחשב את הצפיפות בנקודה מסויימת בעזרת KDE יש לבצע סכימה על כל הנקודות שנמצאות ב train set.
הגישה הפרמטרית
שיטה זו עושה שימוש במודלים פרמטרים בדומה לאופן שבו הדבר נעשה בגישה הדיסקרימינטיבית. בשיטה זו אנו נגביל את החיפוש של הפילוג למשפחה פרמטרית מסויימת, ונחפש את הפרמטרים האופטימאלייים של המודל הנבחר. לרוב הפונקציה שאותה ננסה למדל הינה פונקציית צפיפות הפילוג (הPDF). חשוב לשים לב שבניגוד לשימוש במודלים פרמטרים בגישה הדטרמיניסטית, שם לא הייתה שום מגבלה על המודל הפרמטרי, כאן המודל חייב לייצר פילוג חוקי בעבור כל בחירה של פרמטרים (במקרה של PDF זה אומר פונקציה חיובית שאינטרגל עליה נותן 1)
ישנן שתי דרכים להתייחס לפרמטרים של המודל. שתי דרכים אלו מגיעים משתי גישות הקיימות בתחום של תורת השיערוך וכל גישה מובילה לדרך מעט שונה לבחירה של הפרמטרים האופטימאליים. בשתי הגישות אנו נסמן את וקטור הפרמטרים של המודל ב θ.
הגישה הלא-בייסיאנית (המכונה גם: קלאסית או תדירותית (Frequintist))
בגישה זו אנו נתייחס לפרמטרים באופן דומה לאופן שבו התייחסנו אליהם כאשר עסקנו בשיטות הדיסקרימינטיביות. תחת גישה זו אין כל העדפה של ערך מסויים של הפרמטרים על פני ערך אחר. את המודל הפרמטרי להסתברות / צפיפות הסתברות של משתנה אקראי x נסמן ב:
px(x;θ)
משערך Maximum Likelihood Estimator (MLE)
הדרך הנפוצה ביותר לבחור את הערך של θ תחת הגישה הלא בייסיאנית היא בעזרת MLE. בשיטה זו נחפש את הערך של θ אשר מסביר בצורה הכי טובה את המדגם הנתון. נסמן ב pD(D;θ) את ההסתברות לקבלת מדגם כל שהוא D={x(i)}. גודל זה מכונה הסבירות (likelihood) של המדגם כפונקציה של θ. על מנת להדגיש את העובדה שהמדגם הוא למעשה גודל ידוע ואילו הגודל הלא ידוע שאותו נרצה לבדוק הינו θ, מקובל לסמן את פונקציית ה likelihood באפן הבא:
L(θ;D)≜pD(D;θ)
משערך ה MLE של θ הוא הערך אשר ממקסם את פונקציית ה likelihood (או ממזער את המינוס שלה):
θ^MLE=θargmaxL(θ;D)=θargmin−L(θ;D)
כאשר הדגימות במדגם הן i.i.d (בעלות פילוג זהה ובלתי תלויות, כפי שנניח תמיד שמתקיים בבעיות supervised learning) נוכל להסיק כי:
pD(D;θ)=i∏px(x(i);θ)
ולכן:
θ^MLE=θargmin−L(θ;D)=θargmin−i∏px(x(i);θ)
במקרים רבים נוכל להחליף את המכפלה על כל הדגימות בסכום, על ידי מקסימום של הלוג של פונקציית ה likelihood (בזכות המונוטוניות העולה של פונקציית ה log מובטח לנו שנקבל את אותם פרמטריים אופטימאלים):
בגישה זו אנו מניחים כי וקטור הפרמטרים θ הינו ריאליזציה של וקטור אקראי בעל פילוג כלשהוא pθ(θ). פילוג זה מכונה הפילוג הפריורי (prior distribution) או הא-פריורי (a priori distribution), זאת אומרת הפילוג של θ לפני שראינו את המדגם. תחת גישה זו, המודל שלנו יהיה הפילוג של xבהינתןθ:
px∣θ(x∣θ)
משערך Maximum A-posteriori Probability (MAP)
הדרך הנפוצה ביותר לבחור את הערך של θ תחת הגישה הבייסיאנית היא בעזרת MAP. בשיטה זו נחפש את הערך הכי סביר של θ בהינתן המדגם pθ∣D(θ∣D). פילוג זה מכונה הפילוג הפוסטריורי (posterior distribution) או א-פוסטריורי (a posteriori distribution) (או הפילוג בדיעבד), זאת אומרת, הפילוג אחרי שראינו את המדגם.
אם כן, משערך ה MAP הוא וקטור הפרמטרים אשר ממקסמים את ההסתברות ה א-פוסטריורית:
התנאי θ≥x(i) לכל i שקול ל θ>maxi{x(i)}. מצד אחד נרצה לקיים תנאי זה בכדי שה likelihood לא יתאפס, מצד שני נרצה ש θ יהיה כמה שיותר קטן בכדי למקסם את 1/θN. לכן נבחר את ה θ מינימאלי אשר מקיים את התנאי:
θ^MLE=imax{x(i)}
זאת אומרת, אנו נשערך את θ להיות הערך המסקימאלי במדגם.
בכדי למקסם את הסיכוי לחזות האם היום הוא יום טוב בהינתן המדגם נרצה למצוא איזה ערך יותר סביר בהינתן המדגם (יום טוב או רע), במילים אחרות אנו רוצים את ה y הכי סביר בהינתן D={x(i)}:
y^=yargmaxpy∣D(y∣D)
זוהי למעשה בעיית MAP קלאסית, כאשר y משמש למעשה כפרמטר בפילוג של x∣y. בכדי לשמור על אחידות עם הסימונים שהגדרנו קודם לבעיות שיערוך נסמן את y ב θ. עלינו לפתור אם כן את:
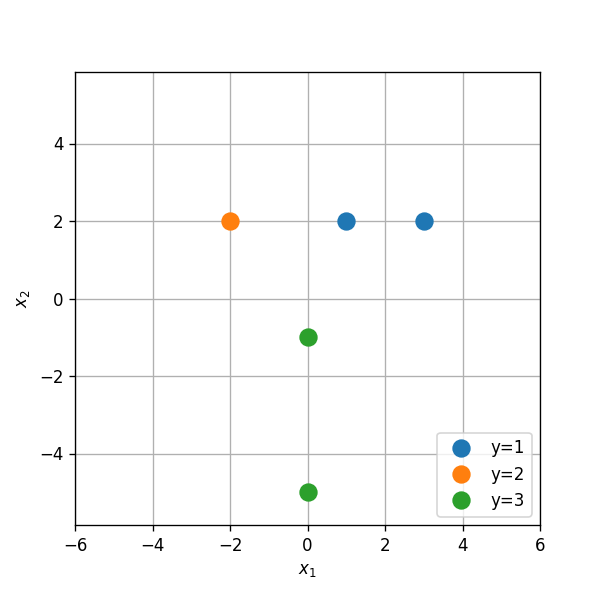
בסוואנה חיים שלושה זני פילים אשר נמצאים בסכנת הכחדה. ידוע כי כל אחד משלושת הזנים ניזון מצמחיה מעט שונה ועל מנת לשמר את אוכלוסיית הפילים מעוניינים לפזר להם אוכל ברחבי הסוואנה. בכדי למקסם את האפקטיביות של פעולה זו מעוניינים לשערך בכל נקודת חלוקה מהו הזן שהכי סביר להמצא באותה נקודה על מנת להתאים את סוג המזון לזן זה.
הפילוג של זני הפילים על פני הסוואנה אינו ידוע אך נתונות לנו התצפית הבאה של הקואורדינטות בהם נצפו הפילים:
Type
x1
x2
1
1
2
1
3
2
2
-2
2
3
0
-1
3
0
-5
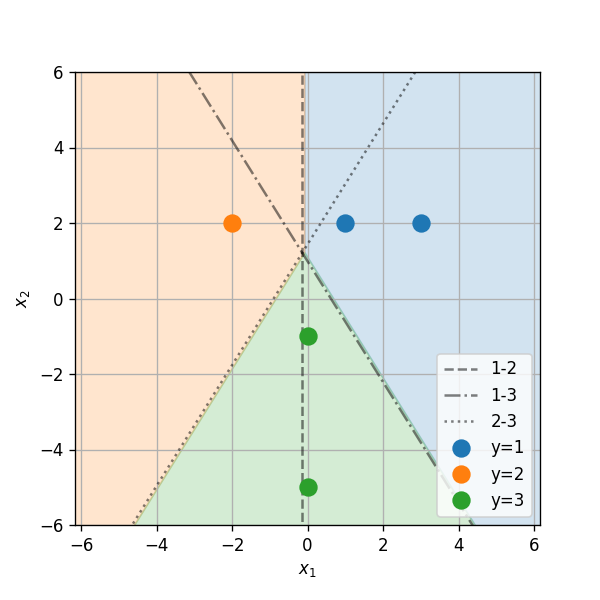
השתמש במסווג LDA על מנת לבנות חזאי אשר ישערך את הזן הנפוץ ביותר בכל קואורדינטה.
נחזור לבעיה מהתרגול הקודם של שיערוך הפילוג של זמן הנסיעה של מונית מתוך מדגם הבא:
passenger count
trip distance
payment type
fare amount
tip amount
pickup easting
pickup northing
dropoff easting
dropoff northing
duration
day of week
day of month
time of day
0
2
2.76806
2
9.5
0
586.997
4512.98
588.155
4515.18
11.5167
3
13
12.8019
1
1
3.21868
2
10
0
587.152
4512.92
584.85
4512.63
12.6667
6
16
20.9614
2
1
2.57494
1
7
2.49
587.005
4513.36
585.434
4513.17
5.51667
0
31
20.4128
3
1
0.965604
1
7.5
1.65
586.649
4511.73
586.672
4512.55
9.88333
1
25
13.0314
4
1
2.46229
1
7.5
1.66
586.967
4511.89
585.262
4511.76
8.68333
2
5
7.70333
5
5
1.56106
1
7.5
2.2
585.926
4512.88
585.169
4511.54
9.43333
3
20
20.6672
6
1
2.57494
1
8
1
586.731
4515.08
588.71
4514.21
7.95
5
8
23.8419
7
1
0.80467
2
5
0
585.345
4509.71
585.844
4509.55
4.95
5
29
15.8314
8
1
3.6532
1
10
1.1
585.422
4509.48
583.671
4507.74
11.0667
5
8
2.09833
9
6
1.62543
1
5.5
1.36
587.875
4514.93
587.701
4513.71
4.21667
3
13
21.7831
ננסה להתאים מודל פרמטרי בעזרת שיערוך MLE.
ניסיון 1: פילוג גאוסי
נשתמש במודל של פילוג נורמלי לתיאור הפילוג של משך הנסיעה. למודל זה שני פרמטרים, התוחלת μ והשונות σ .
סימונים והנחות:
N - מספר הדגמים במדגם.
θ=[μ,σ]T - וקטור הפרמטרים של המודל
pnormal(xi;θ)=2πσ21exp(−2σ2(xi−μ)2),i=1,...,N - המודל
ראינו כי בעבור המודל הנורמלי, ניתן למצוא את הפרמטרים של משערך הMLE באופן מפורש (אנליטית), והפתרון נתון על ידי:
μ=N1i∑xiσ=N1i∑(xi−μ)2
בעבור המדגם הנתון נקבל:
μ^=11.4minσ^=7.0min
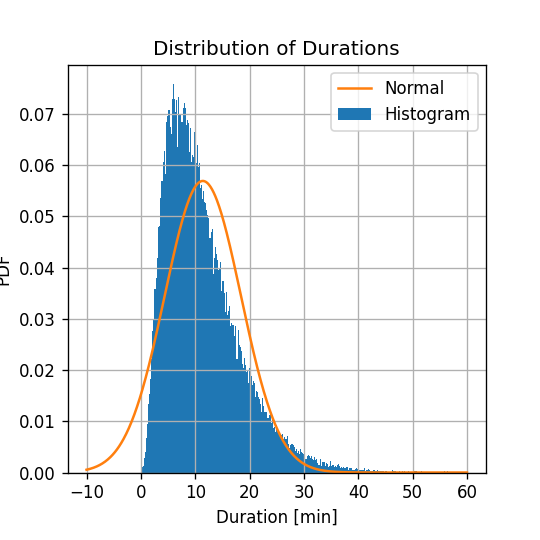
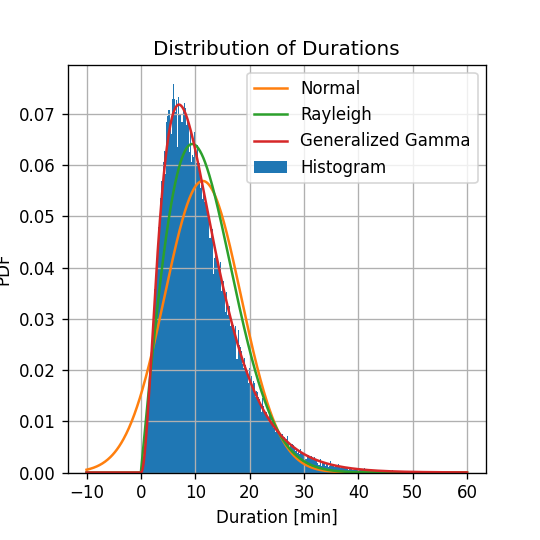
נשרטט את ההיסטוגרמה של של משכי הנסיעה יחד עם הפילוג הנורמלי המשוערך:
נראה כי הפילוג הנורמלי נותן קירוב מאד גס לפילוג האמיתי. במקרים רבים קירוב זה יהיה מספיק, אך במקרה זה ננסה לשפר את השיערוך שלנו.
עובדה אחת שמאד מטרידה לגבי הפילוג שקיבלנו הינה שישנו סיכוי לא אפסי לקבל נסיעות עם משך נסיעה שלילי.
ננסה להציע מודל טוב יותר.
נסיון 2: פילוג Rayleigh
פילוג Rayleigh מתאר את הפילוג של האורך האוקלידי (l2 norm) של וקטור גאוסי דו מימדי עם תוחלת 0 וחוסר קורלציה ופילוג זהה לשני רכיבי הוקטור. במלים אחרות, עבור וקטור בעל הפילוג הבא:
Z∼N([00],[σ200σ2])
פילוג Rayleigh מתאר את הפילוג של הגודל ∥Z∥2=Zx2+Zy2.
פונקציית צפיפות ההסתברות של פילוג Reyligh נתונה על ידי:
pRayleigh(z;σ)=σ2zexp(−2σ2z2),z≥0
נשים לב כי הפילוג מוגדר רק בעבור ערכים חיוביים. לפילוג זה פרמטר יחיד σ שנקרא פרמטר סקאלה (scale parameter). בניגוד לפילוג הנורמלי, פה σ אינה שווה לסטיית התקן של הפילוג.
ניתן מוטיבציה קצרה לבחירה שלנו במודל זה.
מוטיבציה לשימוש בפילוג Rayleigh
נתחיל עם ההנחה שוקטור המחבר את נקודת תחילת הנסיעה עם נקודת סיום הנסיעה הינו וקטור דו מימדי אשר מפולג נרמלית ולשם הפשטות נניח כי רכיביו מפולגים עם פילוג זהה וחסר קורלציה.
בנוסף לשם הפשטות נניח כי המונית נוסעת בקירוב בקו ישר בין נקודת ההתחלה והסיום ולכן המרחק אותו נוסעת המכונית יהיה מפולג על פי פילוג Reyleigh. נניח בנוסף כי מהירות הנסיעה קבוע ולכן משך הנסיעה פורפורציוני למרחק ולכן גם הוא יהיה מפולג על פי פילוג Reyleigh.
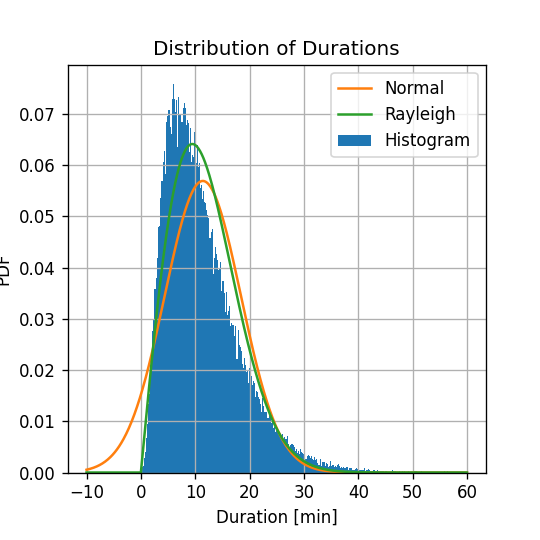
על פי הדמיון בין ההיסטוגרמה לפונקציות הפילוג ששיערכנו, נראה כי המודל של פילוג Rayleigh נותן תוצאה מעט יותר טובה מהמודל הנורמלי, בנוסף ניתן לראות גם כי כעת אין הסתברות שונה מ0 לקבל משך נסיעה שלילי.
ננסה מודל נוסף.
נסיון 3: Generalized Gamma Distribution
פילוג Rayleigh הינו מקרה פרטי של משפחה כללית יותר של פונקציות פילוג המכונה Generalized Gamma Distribution. פונקציית צפיפות ההסתברות של משפחה זו נתונה על ידי:
בעבור c=2 ו a=1 נקבל את פילוג Rayleight כאשר σgamma=2σrayleigh .
בניגוד למקרים של פילוג נורמלי ופילוג Rayleigh, במקרה זה לא נוכל למצוא בקלות את הפרמטרים האופטימאלים של המשערך באופן אנליטי. לכן, לשם מציאת הפרמטרים נאלץ להעזר בפתרון נומרי. בפועל נעשה שימוש באחת החבילה של Python הנקראת SciPy. חבילה זו מכילה מודלים הסברותיים רבים ומכילה מספר רב של כלים הקשורים למודלים אלו, כגון מציאת הפרמטרים האופטימאלים בשיטת MLE על סמך מדגם נתון. את הפונקציות הקשורות למודל הGeneralized Gamma Distribution ניתן למצוא כאן.
אתם תעשו שימוש בפונקציות אלו בתרגיל הבית הרטוב.
שימוש בפונקציה הנ"ל, מניב את התוצאות הבאות:
a^=4.4c^=0.8σ^=1.6
נוסיף את השיערוך החדש שקיבלנו לגרף הקודם:
ניתן לראות המודל של Generalized Gamma Distribution אכן מניב תוצאה אשר דומה מאד לצורת ההסטוגרמה.