בגישה הגנרטיבית אנו נשתמש במדגם על מנת לשערך את הפילוג של x ו y מתוך המדגם. על סמך פילוג זה נוכל לבנות חזאי ל y בהיתנן x.
חזאים אידאליים לפונקציות מחיר נפוצות - תזכורת
לרוב אנו נעבוד עם פונקציות מחיר שבהינתן פונקציית הפילוג יש ביטוי סגור לחזאי האידאלי. נזכיר את החזאים האידאליים של פונקציות המחיר הנפוצות:
MSE: התוחלת המותנית:
h∗(x)=E[y∣x]
MAE: החציון של הפילוג המותנה:
h∗(x)=ymedians.t.Fy∣x(ymedian∣x)=0.5
(כאשר Fy∣x היא פונקציית הפילוג המצרפי של y בהינתן x).
Misclassification rate: הערך הכי סביר (ה mode):
h∗(x)=yargmaxpy∣x(y∣x)
שימוש בהסתברות המותנית
בעיות סיווג (שבהם y מקבל סט ערכים בדיד) נוח לשערך את הפילוג המשותף של x ו y בעזת הפירוק הבא:
px,y(x,y)=px∣y(x∣y)py(y)
על פי פירוק זה ניתן למעשה לחשב את הפילוג המשותף על ידי כך שנשערך בנפרד את כל אחת מהפילוגים הבאים:
py(y) - הפילוג של y ללא תלות בערכו של x. שיערוך זה יהיה לרוב פשוט מכיוון ש y הוא משתנה דיסקרטי (בדיד).
px∣y(x∣y) כאשר גם כאן יהיה לרוב נוח לפצל את השיערוך למספר שיערוכים שונים בעבור כל ערך אפשרי של y. זאת אומרת px∣y(x∣1), px∣y(x∣2), וכו'. הדרך לעשות זאת היא על ידי פיצול המדגם על פי הערכים של y ושיערוך הפילוג של x בנפרד על כל חלק של המדגם.
שיערוך של פונקציות פילוג בשיטות א-פרמטריות
נציג מספר שיטות לשיערוך של הסתברויות ופונקציות פילוג של משתנה / וקטור אקראי כל שהוא x על סמך מדגם כל שהוא D={x(i)}. בתרגול זה נעסוק בשיטות אשר לא עושות שימוש במודל פרמטרי ולכן הם מכונות א-פרמטריות, בשבוע הבא נעסוק בשיטות פרמטריות.
מדידה אמפירית / משערך הצבה (Empirical Measure)
המדידה האמפירית, p^A,D, הינה שיערוך של הההסתברות, Pr(A), להתרחשות המאורע A:
p^A,D=N1i=1∑NI{x(i)∈A}
לדגומא, השיערוך של ההסתברות שהנורמה של x קטנה מ 3, זאת אומרת A={∥x∥2<3}, תהיה:
p^{∥x∥2<3},D=N1i=1∑NI{∥x(i)∥2<3}
למעשה אנו משערכים כי ההסתברות להתרחשות של מאורע שווה למספר הפעמים היחסי שהמאורע מופיע בסט המדידות.
שיערוך פונקציית ההסתברות PMF (המקרה של משתנה דיסקרטי)
נוכל לשערך את פונקציית ההסתברות (PMF) של משתנה / וקטור אקראי דיסקרטי על ידי שימוש במדידה האמפירית:
p^x,D(x)=p^{x=x},D=N1i=1∑NI{x(i)=x}
ECDF (Empirical Cumulative Distribution Function)
ECDF הינה שיטה לשערך את פונקציית הפילוג המצרפי (ה CDF):
היסטוגרמה היא שיטה לשערוך פונקציית צפיפות ההסתברות (PDF). שיטה זו נפוצה בעיקר לשם ויזואליזציה של הפילוג של משתנים אקראיים סקלריים. השיערוך מתבצע באופן הבא:
מחלקים את תחום הערכים ש x יכול לקבל ל bins (תאים) לא חופפים אשר מכסים את כל התחום.
לכל תא משערכים את ההסתברות של המאורע ש x נמצא בתוך התא.
הערך של פונקציית הצפיפות בכל תא תהיה ההסתברות המשוערכת להיות בתא חלקי גודל התא.
נרשום זאת בעבור המקרה של משתנה אקראי סקלרי. נסמן ב B את מספר התאים וב lb ו rb את הגבול השמאלי והימני בהתאמה של התא ה b. ההסטוגרמה תהיה נתונה על ידי:
p^x,D(x)=⎩⎪⎪⎪⎨⎪⎪⎪⎧size of bin 11p^{x in bin 1},D⋮size of bin B1p^{x in bin B},Dx in bin 1x in bin B=⎩⎪⎪⎪⎨⎪⎪⎪⎧N(r1−l1)1∑i=1NI{l1≤x(i)<r1}⋮N(rB−lB)1∑i=1NI{lB≤x(i)<rB}l1≤x<r1lB≤x<rB
הערות:
בחירת התאים משפיעה באופן משמעותי על תוצאת השערוך של ה PDF.
כלל אצבע: לחלק את טווח הערכים ל-N תאים בגודל אחיד.
Kernel Density Estimation (KDE)
KDE הינה שיטה נוספת לשערוך ה PDF. בשיטה זו אנו נבחר פונקציה המכונה פונקציית גרעין (kernel) או Parzan window מהם נבנה N פונקציות גרעין מוזזות בעבור כל נקודה מהמדגם. נסמן ב ϕ(x) את פונקציות הגרעין. פונקציית הגרעין המוזזת לנקודה ה x(i) תהיה ϕ(x−x(i)). פונקציית הצפיפות המשוערכת תהיה הממוצע של כל הפונקציות המוזזות:
p^x,ϕ,D(x)=N1i=1∑Nϕ(x−x(i))
הערה: תנאי מספיק והכרחי בכדי שנקבל PDF חוקי, הינו שפונקציית הגרעיון תהיה בעצמה PDF חוקי. זאת אומרת שהיא חייבת להיות חיוביות ושהאינטרגל עליה יהיה שווה ל 1.
הוספת פרמטר רוחב
מקובל להוסיף לפונקציות הגרעין פרמטר h אשר שולט ברוחב שלה באופן הבא:
ϕh(x)=hD1ϕ(hx)
החלוקה ב hD היא על מנת לשמור על הנרמול של הפונקציה. כאשר D הוא המימד של x.
בתוספת פרמטר זה המשערך יהיה:
p^x,ϕ,h,D(x)=NhD1i=1∑Nϕ(hx−x(i))
פונקציות גרעין נפוצות
שתי הבחירות הנפוצות ביותר לפונקציית הגרעין הינן:
חלון מרובע:
ϕh(x)=hD1I{∣xj∣≤2h∀j}
גאוסיאן:
ϕσ(x)=2πσD1exp(−2σ2∥x∥22)
כלל אצבע לבחירת רוחב הגרעין במקרה הגאוסי הסקלרי הינו σ=(3N4⋅std(x)5)51≈1.06std(x)N−51, כאשר std(x) הינה הסטיית תקן של x (אשר לרוב תהיה משוערכת גם היא מתוך המדגם)
תוחלת אמפירית (Empirical mean)
התוחלת האמפירית משערכת את התוחלת של פונקציה מסויימת של המשתנה האקראי f(x), על ידי החלפת התוחלת במיצוע של הפונקציה על הדגימות במדגם:
μ^f(x),D=N1i=1∑Nf(x(i))
ה bias וה variance של משערך
כפי שציינו כאשר עסקנו ב bias-variance tradeoff, בכדי לשערך את הביצועים של שיטה מסויימת נרצה להסתכל על הפילוג של תוצאות השערוך הנובע מהאקראיות של המדגם. נשתמש שוב בסימון ED בכדי לסמן תוחלת על פני הפילוג של המדגם.
Bias
בעבור שיערוך של גודל כל שהוא z בעזרת משערך z^D, ה bias (היסט) של השיערוך מוגדר כ:
Bias(z^)=ED[z^D]−z
כאשר ההטיה שווה ל-0, אנו אומרים שהמשערך אינו מוטה (Unbiased).
אנו נהיה מעוניינים כמובן במשערך שגם ה bias וגם ה variance שלו קטנים.
תרגיל 7.1 - משתנה בינארי (ברנולי)
1) המשתנה האקראי x הוא משתנה בינארי (משתנה אשר יכול לקבל את הערכים 0 או 1). נתון לנו מדגם המכיל N דגימות של x. חשבו את השיערוך של פונקציית ההסתברות של x. בטאו את התשובה בעזרת N0 ו N1, כאשר N0 הוא מספר הדגימות ששוות ל 0 ו N1 הוא מספר הדגימות ששוות ל 1.
נתון כי הפילוג האמיתי של x הינו:
px(x)={10p(1−p)
שני הסעיפים הבאים לא קשורים למדגם הנתון.
2) חשבו את ה bias של המשערך ב x=1.
3) חשבו את ה variance של המשערך x=1.
פתרון 7.1
1)
השיערוך של פונקציית ההסתברות בעבור x=0 הינו:
p^x,D(0)=N1i=1∑NI{x(i)=0}=NN0
ובאופן דומה
p^x,D(1)=N1i=1∑NI{x(i)=1}=NN1
סה"כ
px(x)={NN1NN0x=1x=0
2)
נחשב את התחולת של המשערך p^x,D(1):
ED[p^x,D(1)]=ED[N1i=1∑NI{x(i)=1}]
שימו לב שבחישוב זה אנו לא מתייחסים ל x(i) כאל מספר ידוע אלא כאל משתנה אקראי. נוציא את החלוקה ב N ואת הסכימה אל מחוץ לתוחלת:
=N1i=1∑NED[I{x(i)=1}]
משום שכל ה x(i) הם משתנים אקראיים זהים ומפולגים לפי הפילוג של x, ניתן להסיר את האינדקס של (i):
=N1i=1∑NED[I{x=1}]=ED[I{x=1}]=p
ה bias יהיה:
Bias(p^x(1))=ED[p^x,D(1)]−p=p−p=0
מכאן שהמשערך של ההסתברות של משתנים בדידים הוא משערך לא מוטה.
מכיוון שבעבור i=j המשתנים x(i) ו x(j) הם משתנים בלתי תלויים, נוכל במקרים אלו לפרק את התוחלת של המכפלה למכפלת התוחלות. נפריד אם כן את הסכום למקרים בהם i=j (יש N מקרים כאלה) ולמקרים שבהם i=j (יש N2−N מקרים כאלה):
כפי שהיינו מצפים ניתן לראות כי השונות הולכת וקטנה עם מספר הדגימות, שכן ככל שיש לנו יותר דגימות כך השיערוך יהיה מדוייק יותר. בנוסף, בתור אימות, ניתן להבחין כי בעבור N=1 נקבל שהשיערוך הוא הערך של הדגימה היחידה ובמקרה זה השונות בדיוק שווה לשונות של משתנה בינארי p(1−p).
תרגיל 7.2 - EDCF
בעבור משתנה אקראי רציף כל שהוא x, מהו ה bias וה variance של משערך ה ECDF בנקודה מסויימת x0? בטאו את התשובה בעזרת הפילוג המצרפי האמיתי
פתרון 7.2
למעשה לפתרון תרגיל זה נוכל להשתמש בתוצאת הסעיף הקודם. שיערוך ה ECDF בנקודה x0 נתון על ידי:
F^x,D(x0)=p^{x≤x0},D
נוכל אם כן אז להגדיר משתנה אקראי בינארי חדש z אשר שווה ל-1 אם x≤x0 ו-0 אחרת. בעזרת משתנה זה נוכל לכתוב את שיערוך ה ECDF כשיערוך של ההסתברות ש z=1:
F^x,D(x0)=p^{z=1},D=p^z,D(1)
את ה bias וה variance של המשערך הזה חישבנו בסעיף הקודם וקיבלנו ש:
Bias(p^z(1))=0Var(p^z(1))=N1p(1−p)
כאשר p הוא ההסתברות האמתית ש z=1. במקרה שלנו p=Fx(x0), ולכן נקבל ש:
נתון כי y הינו משתנה אקראי בינארי ו x משתנה אקראי רציף אשר יכול לקבל ערכים בתחום [0,15]. כמו כן נתון לנו המדגם הבא של זוגות של x ו y:
1
2
3
4
5
6
7
x
1
7
9
12
4
4
7
y
0
0
0
0
1
1
1
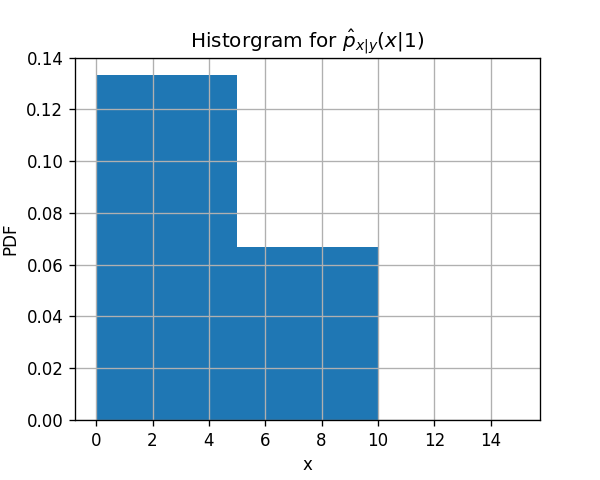
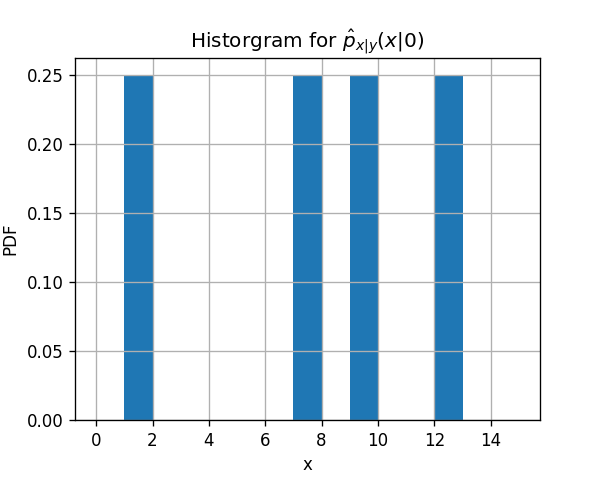
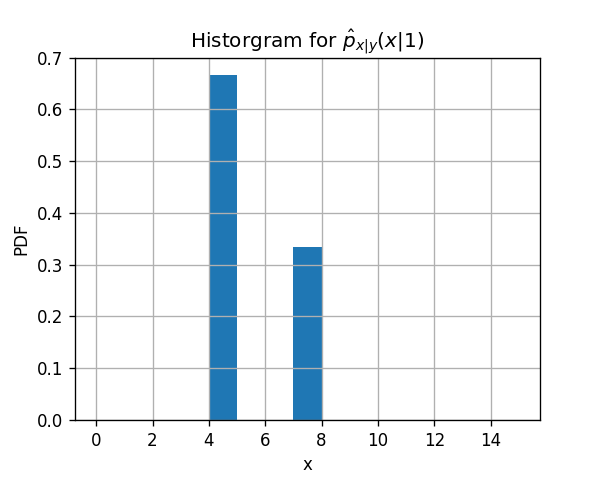
1) חשבו את הפילוג המשותף של x ו y על ידי שימוש בהסטוגרמה לשיערוך של x בהינתן y. חלקו את התחום [0,15] לשלושה חלקים שווים.
2) בעבור x=6 מהו החיזוי האופטימאלי של y תחת פנקציית המחיר של missclassification rate.
3) חזרו על שני הסעיפים עם הסטוגרמה שמחלקת את התחום ל15 תאים.
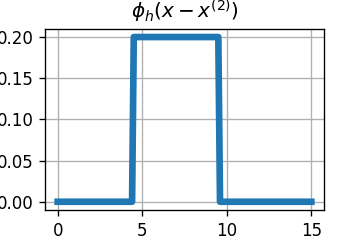
4) חזרו על שני הסעיפים הראשונים עם KDE עם פונקציית גרעין של מסוג חלון מרובע ופרמטר רוחב h=5
פתרון 7.3
1)
נחשב עת הפילוג המשותף על ידי שימוש בתוחלת המותנית:
px,y(x,y)=px∣y(x∣y)py(y)
py
נתחיל בלשערך את py. מכיוון ש y הוא משתנה בינארי, השיערוך של הפילוג שלו יהיה:
py(y)={NN1=73NN0=74y=1y=0
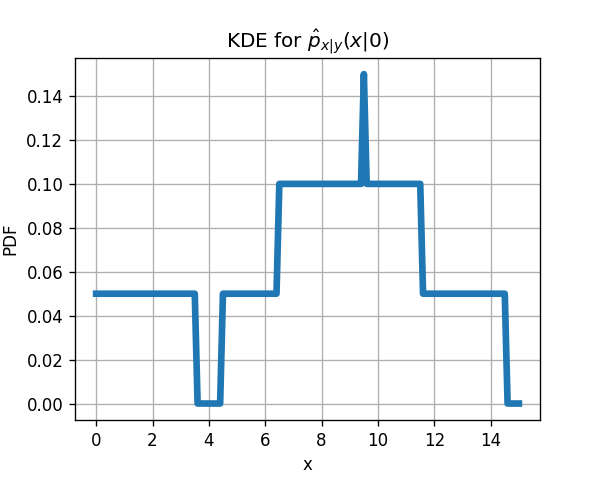
השיערוך של px∣y(x∣y) הוא למעשה שני שיערוכים של שתי פונקציות פילוג, px∣y(x∣0) ו px∣y(x∣1). נתחיל מהמקרה של y=0
px∣y(x∣0)
נסתכל רק על הדגימות שבהן y(i)=0. ישנם ארבע דגימות כאלה. על פי ההנחיה נחלק את התחום ל3 תאים שווים, [0,5], [5,10] ו [10,15]. נחשב את צפיפות ההסתברות בכל תא בעזרת היסטוגרמה. על פי הגדרת ההיסטוגרמה הצפיפות הסתברות בכל תא שווה לכמות הדגימות מהמדגם ששיכות לתא זה חלקי מספר הדגימות הכולל, חלקי גודל התא.
מתוך הדגימות שבהם y(i)=0 ישנה דגימה בודד שהגיעה לתא של [0,5] ולכן צפיפות ההסתברות בתא זה תהיה:
אנו יודעים כי החזאי האופטימאלי תחת פונקציית המחיר של misclassification rate הינו הערך הכי סביר של y בהינתן x. אם כן עלינו להשוות בין py∣x(1∣6) לבין py∣x(0∣6).
בפילוג זה גם py∣x(1∣6) וגם py∣x(0∣6) שיווים ל0 ולכן שני הערכים של y סבירים באותה המידה.
הבעיה עם הפילוג הזה הינה שנראה שלקחנו כמות תאים גדולה מידי ולכן ברוב התאים אין לנו דגימות בכלל וכנראה שהשיערוך שם לא מייצג כלל את הפילוג האמיתי.
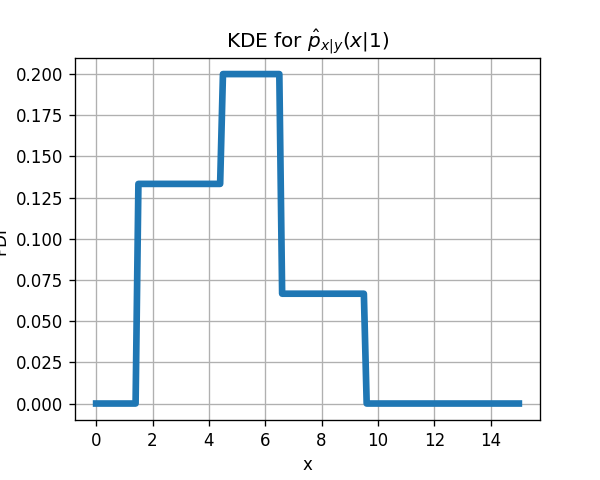
4)
בכדי לבנות כעת את פונקציות הפילוג של px∣y(x∣y) עלינו לקחת כל נקודה מהמדגם (עם ה y המתאים) ולמקם סביבה חלון ריבועי ברוחב 5 ובגובה 51. החלונות של הדגימות המתאימות ל y=0 הם:
פונקציית הפילוג תהיה הממוצע של כל החלונות הריבועיים:
נהג מונית מעוניין לשערך את הפילוג של משך הנסיעות שלו. הוא לקח את הקורס מבוא למערכות לומדות והוא יודע שהוא יוכל לעשות זאת מתוך המידע ההיסטורי אותו אספה עיריית New York. בחלק זה של התרגול אנו נעזור לאותו נהג מונית לבצע שיערוך זה.
באופן פורמלי, אנו מעוניינים לשערך את הפילוג של משך נסיעות המונית בעיר כפונקציית פילוג מצרפי (CDF) או כפונקציית צפיפות הסתברות (PDF).
המדגם שלנו לבעיה זו יהיה אוסף משכי הנסיעה מהמדגם הכולל של פרטי הנסיעה. נסמן את המדגם של משך הנסיעה ב {x(i)}.
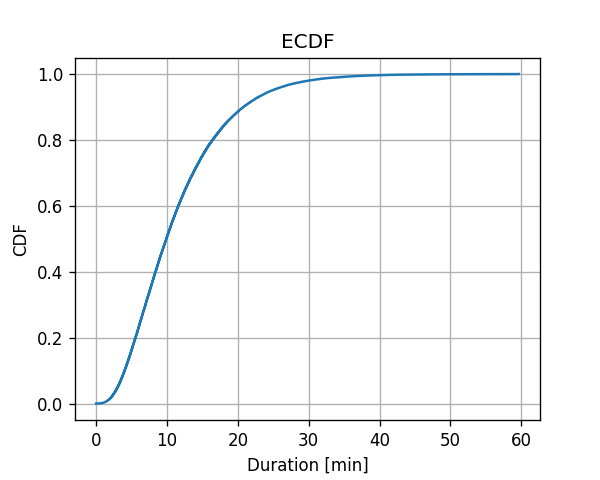
שיטה 1: ECDF
נחשב ונשרטט את ה ECDF על פני grid של ערכים בין 0 ל max({x(i)}) בקפיצות של 0.001:
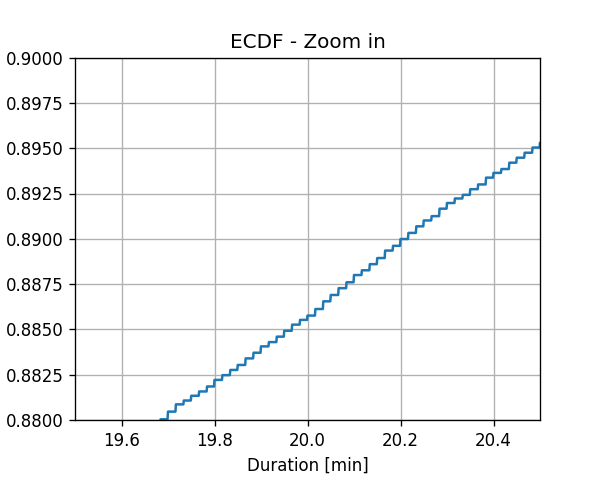
נסתכל מקרוב על איך נראית פונקציית ה ECDF:
נשים לב שמערך ה ECDF יהיה תמיד מורכב מאוסף של פונקציות מדרגה.
שאלה
על פי פונקציית הפילוג המצרפי המשוערכת, מהו הסיכוי שנסיעת מונית תערך יותר מ20 דקות?
תשובה
על פי הגדרת הפילוג המצרפי:
Pr(x>20)=1−Pr(x≤20)=1−Fx(20)≈1−0.89=0.11
התלות בגודל המדגם
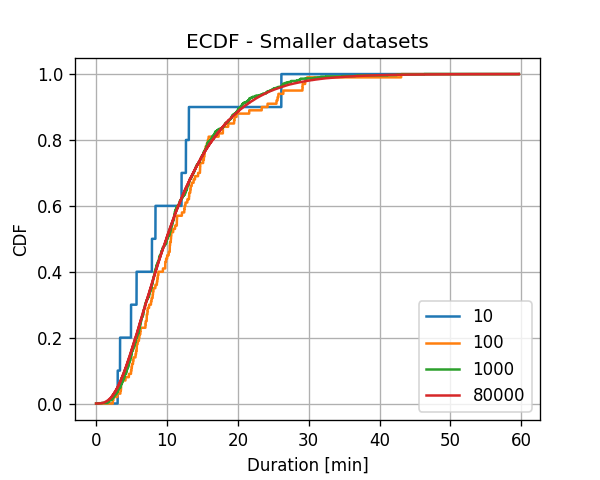
על מנת לראות את התלות של ה ECDF בגודל המדגם נחזור על החישוב עם כמויות קטנות יותר של דגימות במדגם. אנו נבחר בארקאי N=10,10,1000 דגימות מהמדגם ונחזור על החישוב. התוצאה:
באופן לא מפתיע ניתן לראות כי ככל שאנו מגדילים את מספר הדגימות במדגם המשערך מתקרב יותר ויותר לפונקציה חלקה וניתן גם להראות כי השערוך מתקרב (במובן סטיסטי) לפונקציית הפילוג המצרפי האמיתית.
שיטה 2: היסטוגרמה
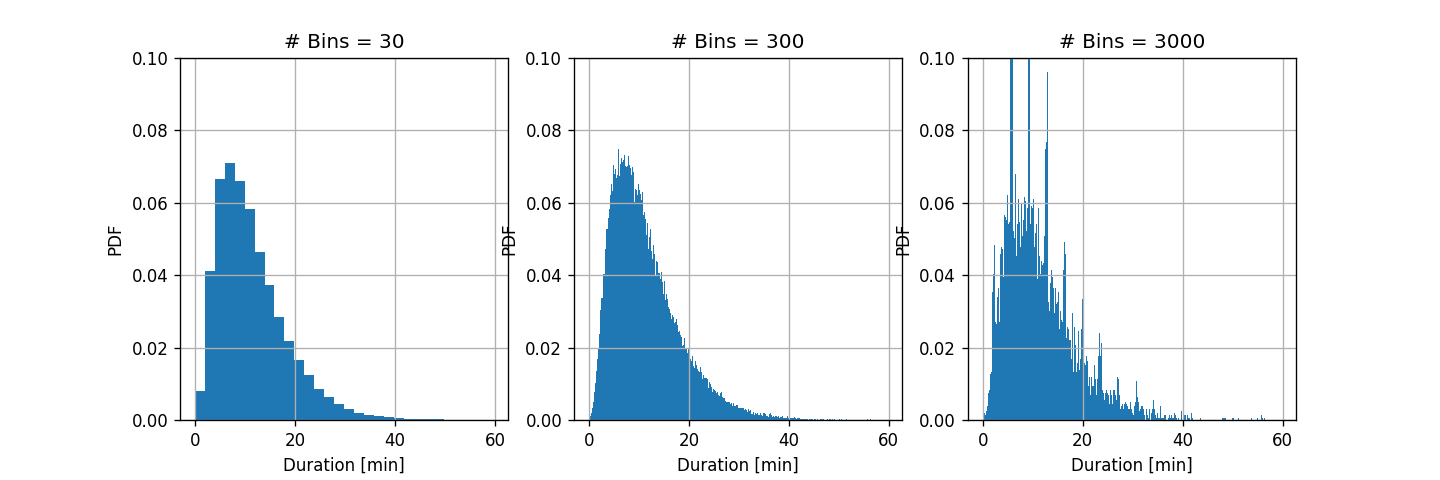
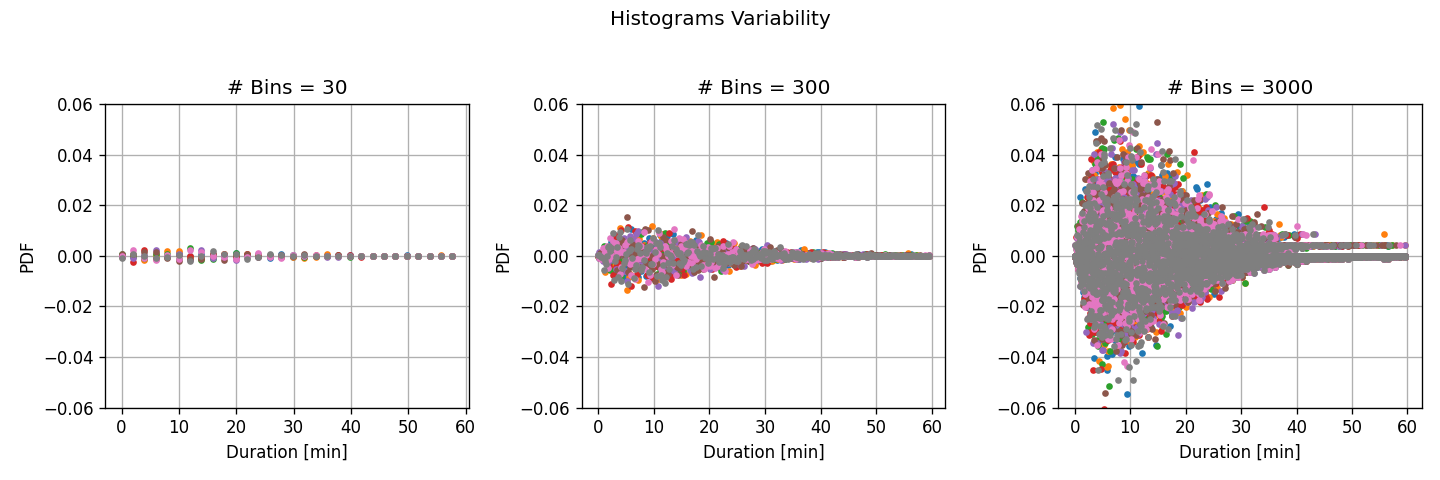
נחשב את ההסטוגרמה של משך הנסיעה בעבור חלוקה של התחום ל30, 300 ו 3000 תאים.
תזכורת: כלל האצבע לבחירה של מספר התאים הינו B=80000≈280$.
תוצאה:
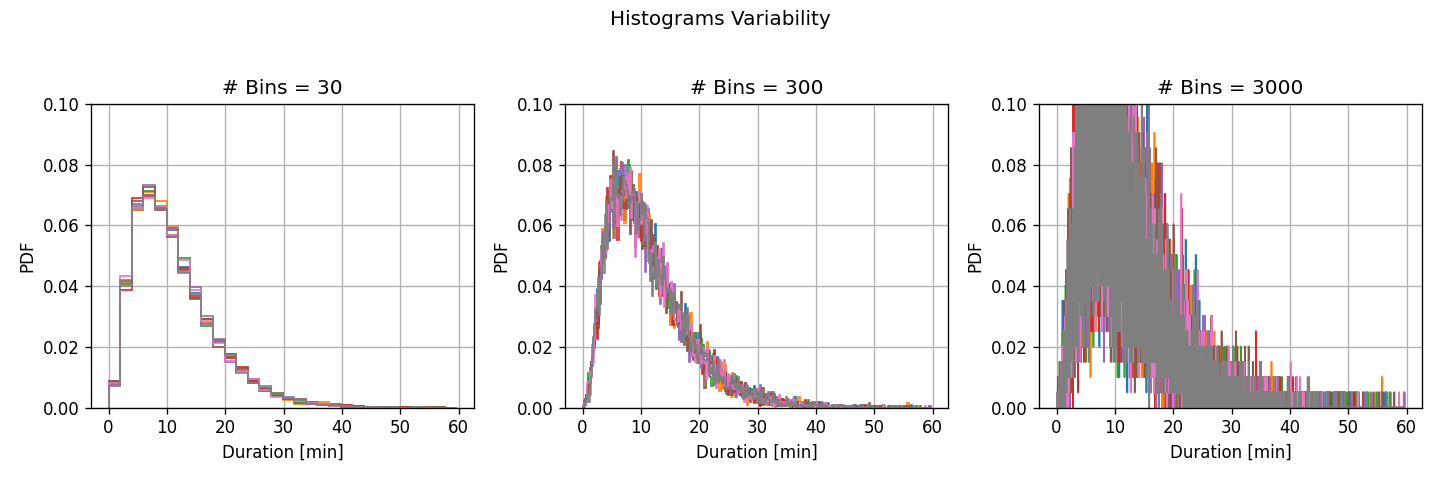
לפני שנבחן את התוצאות, נריץ מבחן נוסף. ננסה לשערך באופן איכותי את ה variance של כל אחת מההיסטוגרמות. לשם כך נפצל את המגדם ל8 תתי מדגמים שווים ונחשב היסטוגרמה בעבור כל אחד משמונת תתי המדגם.
בכדי להגדיר את השונות של השיערוך בצורה טובה יותר נחסר משמונת השיערוכים את הממוצע שלהם:
ניתן לראות כי:
בעבור מספר גדול של תאים, ההבדלים בין תתי המדגם השונים (שונות גדולה) גדול והתאים צרים ולכן ההיסטוגרמה יכולה לקרב בצורה יותר טובה את פונקציית הצפיפות האמיתית (הטיה קטנה)
בעבור מספר קטן של תאים, ההבדלים בין תתי מדגמים שונים קטן (שונות קטנה) אך התאים מאד רחבים ולכן לא יכולים לקרב את הפונקציה האמיתי בצורה טובה (הטיה גדולה)
זהו למעשה אותו bias-variance tradeoff:
כאשר מספר התאים גדול, כל תא יהיה צר ומקור השגיאה העיקרי ינבע מהאקראיות של המדגם הגורמת לשינויים גדולים במספר היחסי של נקודות אשר נופלות בכל תא. שגיאה זו נובעת מה variance של המשערך. שגיאה זו תלך ותקטן ככל שנגדיל את כמות הדגימות במדגם.
כאשר מספר התאים קטן, מקור השגיאה העקרי ינבע מיכולת הייצוג המוגבלת של המודל שלנו. שגיאה זו נובעת מה bias של המשערך.
אנו כמובן נשאף לבחור ערך ביניים אשר לא סובל מ variance גדול מידי וגם לא מ bias גדולה מידי. כלל ההאצבע מנסה לתת לעזור לנו לבחור ערך שכזה.
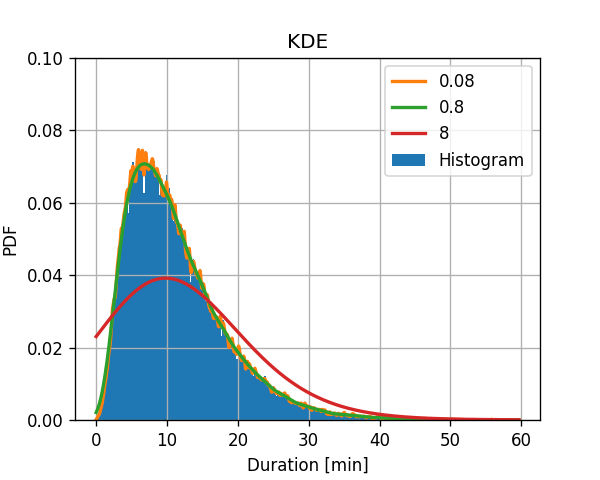
שיטה 3: KDE
נשערך כעת את פונקציית צפיפות ההסתברות בעזרת KDE עם חלון גאוסי. נבחן ערכים שונים לרוחב החלון σ=0.08,0.8,8.
תזכורת, כלל האצבע מציע לבחור רוחב של: σ=1.06std(x)N−51≈0.775
לשם השוואה, נשרטט גם את ההסטוגרמה עם ה 300 תאים:
שוב אנו רואים את ה bias-variance tradeoff:
עבור בחירה של רוחב צר המשערך יכולה לקרב פרטים "עדינים" יותר, אבל השיערוך רועש יותר.זוהי שגיאת ה variance.
עבור בחירה של רוחב רחב המשערך מחליק את הפרטים הקטנים, אבל השיערוך פחות רועש יותר. זוהי שגיאת bias.
בעיית חיזוי: האם נסיעה התרחשה בזמן שעות העבודה
נניח ושעות העבודה ב NYC מוגדרות כשעות שבין 7:00 ו18:00. נגדיר משתנה אקראי בינארי y אשר שווה ל 1 אם נסיעה התרחשה בזמן שעות העבודה ו-0 אחרת.
נרצה לבנות חזאי ל y על סמך x אשר ימזער את הmissclassification rate. נעשה זאת תחת הגישה הגנרטיבית.
נפעל בדומה לתרגיל 5.3. השלבים לפתרון הבעיה:
שיערוך הפילוג השולי של y, זאת אומרת p^y,D(y).
שיערוך הפילוג המותנה של x בהינתן y, זאת אומרת p^x∣y,D(x∣y), בעבור כל אחד משני הערכים של y.
בניית החזאי האופטימאלי בהינתן הפילוג המשוערך על פי: h(x)=yargmaxp^y∣x,D(y∣x).
שלב 1: שיערוך של p^y,D(y)
y הוא משתנה דיסקרטי ולכן השיערוך של הפילוג שלו פשוט:
p^y,D(y)=N1i=1∑NI{y(i)=y}
נקבל כי:
p^y,D(y)={0.510.49y=1y=0
חיזוי עיוור
אם היה ברצונינו לתת חיזוי עיוור (ללא ידיעת x) להאם נסיעה התרחשה במהלך שעות העבודה היינו מעוניינים לתת את החיזוי הבא:
y^=yargmaxp^y,D(y)=1
הסיבה שזהו החיזוי האידאלי נובעת ישירות מן העובדה שיש במדגם יותר נסיעות שהתרחשו בשעות העבודה. שיערכנו שיש סיכוי מעט יותר גדול שנסיעה אקראית תתרחש בשעות העבודה מכיוון שיש לנו סיכוי קטן יותר לטעות בעבור חיזוי זה.
הערכת ביצועים לחיזוי עיוור
נחשב את ה missclassification rate של החיזוי העיוור (חיזוי קבוע של 1) על ה test set. נקבל את הציון של: 0.49.
שלב 2: שיערוך p^x∣y,D(x∣y)
נשתמש פעמיים ב KDE על מנת לשערך את הפילוג המותנה פעם אחת בעבור הדגימות שבהן y=0 ופעם נוספת בעבור הדגימות שבהן y=1:
ניתן לראות כי ישנו שוני קטן בין הפילוגים. לנסיעות מחוץ לשעות העבודה ישנה נטיה קלה יותר לטובת זמני נסיעה קצרים יותר. הבדל קטן זה יעזור לנו לשפר את במעט את יכולת החיזוי שלנו.
שלב 3: בניית החזאי
עלינו לחשב את:
h(x)=yargmaxp^y∣x,D(y∣x)
נתחיל בלהפוך את הפילוג המותנה בביטוי בעזרת חוק בייס על מנת לקבל ביטוי אשר תלוי בפילוגים שחישבנו:
=yargmaxp^x,D(x)p^x∣y,D(x∣y)p^y,D(y)
כפי שציינו בתרגיל 5.3, ניתן להפתר מהאיבר במכנה משום שהוא אינו תלוי ב y:
מכאן שהחיזוי יהיה 1 באיזורים שבהם p^x∣y,D(x∣1)p^y,D(1)>p^x∣y,D(x∣0)p^y,D(0) ו-0 בכל השאר.
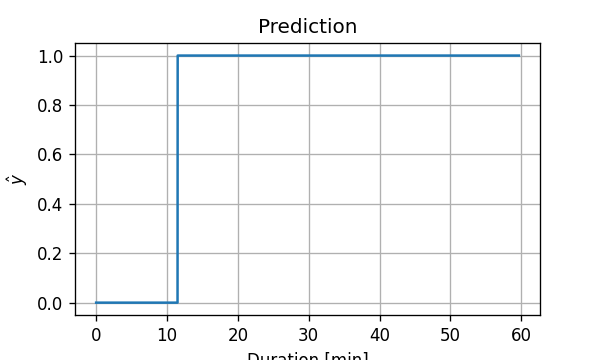
חישוב תנאי זה על פני כל התחום נותן את פונקציית החיזוי הבאה:
מכאן שהחיזוי שלנו יהיה:
y^(x)={10x≥11.4otherwise
הערכת ביצועים
נחשב את ה missclassification rate על ה test set. נקבל את הציון של: 0.46. ציון זה הוא רק מעט יותר טוב מהחיזוי העיוור אשר היה נותן ציון של 0.49. כפי שציינו קודם השיפור הקטן מגיע מההבדלים הקלים שבין שני הפילוגים של הנסיעות בשעות העבודה ומחוצה להן. במקרה זה קיבלנו אומנם שיפור קטן אך ככל שנסתמך בחיזוי שלנו על יותר משתנים השיפורים הקטנים האלו יצברו ונוכל בסוף להגיע לחיזויים מאד מדוייקים.