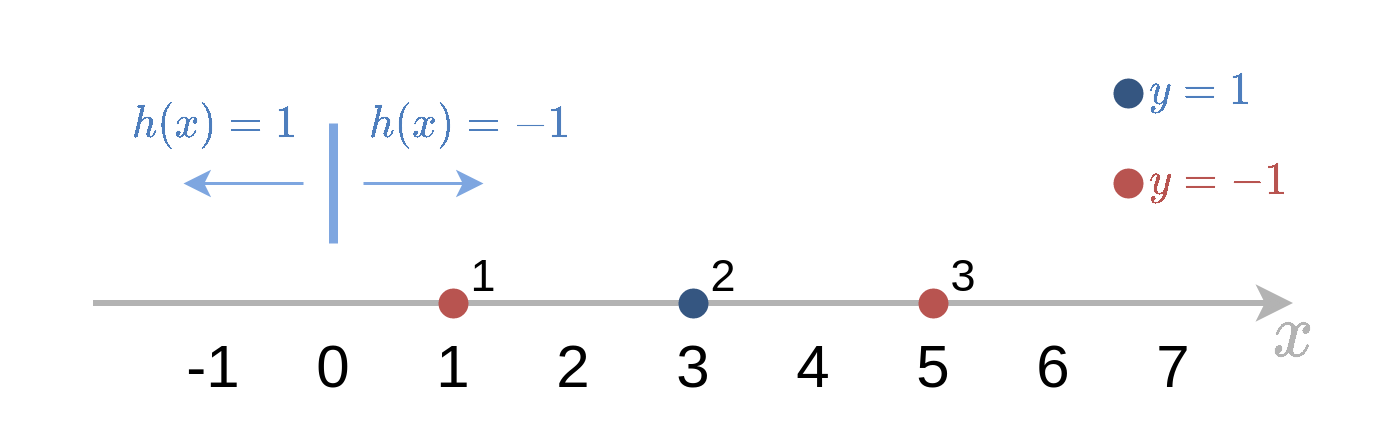Bagging ו Boosting הן שיטות אשר עושות שימוש במכלול (ensemble) של חזאים כדי לקבל חזאי עם ביצועים טובים יותר.
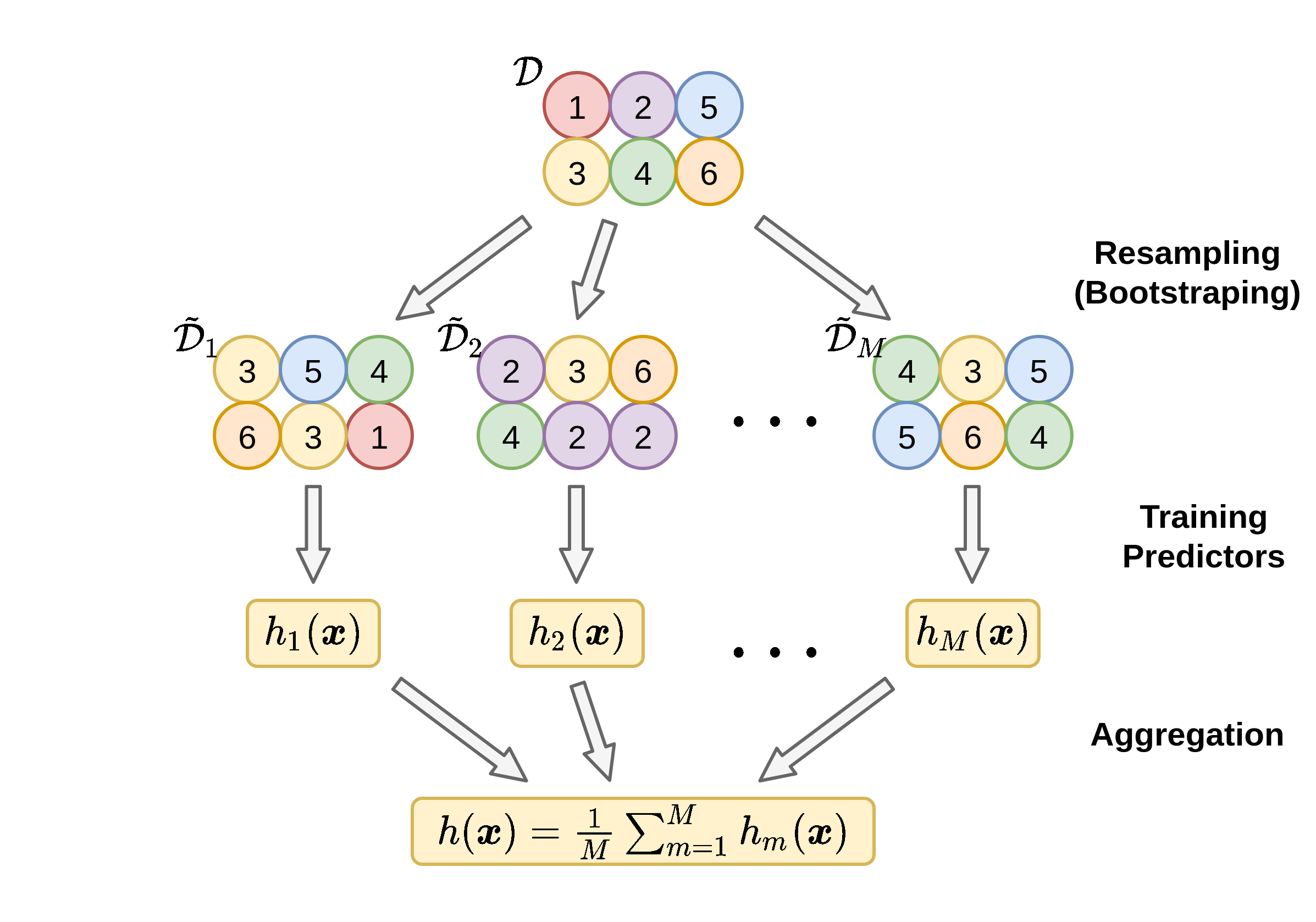
Bagging
Bagging (Bootstrap + Aggregating) הינה שיטה להקטין את ה השונות (ובכך את התאמת היתר) של חזאי על ידי הרכבה של מספר חזאים אשר אומנו על מדגמים מעט שונים.
בשלב ה bootstraping נייצר את המדגמים ולכל מדגם נבנה חזאי ובשלב ה aggregation נאחד את כל החזאים לחזאי יחיד.
Bootstraping
ב Bootstraping נקח מדגם נתון בגודל N ונייצר ממנו p מדגמים בגודל N~ על ידי הגרלה של ערכים מתוך המדגם עם חזרות (כך שניתן להגריל כל ערך מספר פעמים). ב bagging נבחר לרוב את N~ להיות שווה ל N.
Aggregation
בשלב הראשון נבנה באופן בלתי תלוי מתוך כל אחד מהמגדמים שייצרנו חזאי h~i(x). בשלב השני נרכיב את כל החזאים שייצרנו לחזאי אחד כולל.
עבור בעיות רגרסיה: נמצע את תוצאת החיזוי של כל החזאים: h(x)=p1∑i=1ph~i(x)
עבור בעיות סיווג: נבצע majority voting, זאת אומרת: h(x)=majority({h~1(x),h~2(x),…,h~p(x)})
AdaBoost
AdaBoost (Adaptive Boosting) מתייחס לבעיות סיווג בינאריות, שיטה זו מנסה להקטין את ההטיה (ובכך להקטין את התאמת החסר) של מסווג על ידי הרכבה של מסווגים שונים.
ב AdaBoost נסמן את המחלקות ב y=±1.
בהיתן אוסף של מסווגים בינארים, אלגוריתם ה AdaBoost מנסה לבחור סט של t מסווגים ומקדמים {αk,h~k}k=1t ולבנות קומבינציה לינארית ∑k=1tαkh~k(x) שתמזער את בעיית האופטימיזציה הבאה:
האלגוריתם בונה את הקומבינציה הלינארית בצורה חמדנית על ידי הוספת איבר איבר לקומבינציה (והגדלה של t) ועצירה כאשר ביצועי המסווג מספקים או שהאלגוריתם מתחיל לעשות התאמת יתר על ה validation set.
אלגוריתם
ב t=0 נאתחל וקטור משקלים wi(t)=N1.
בכל צעד t נבצע את הפעולות הבאות:
נבחר את המסווג אשר ממזער את שגיאת 0-1 האמפירית הממושקלת:
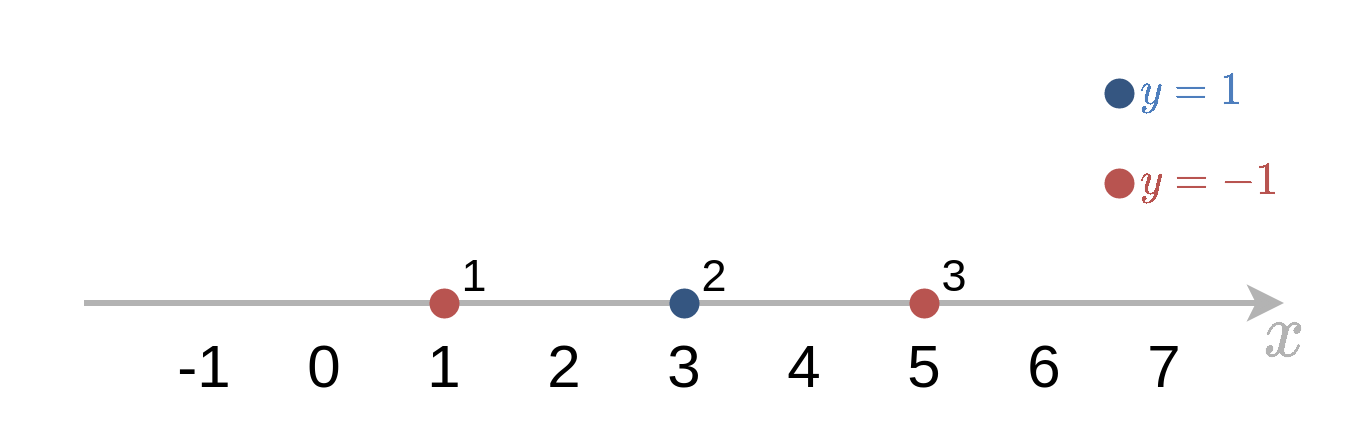
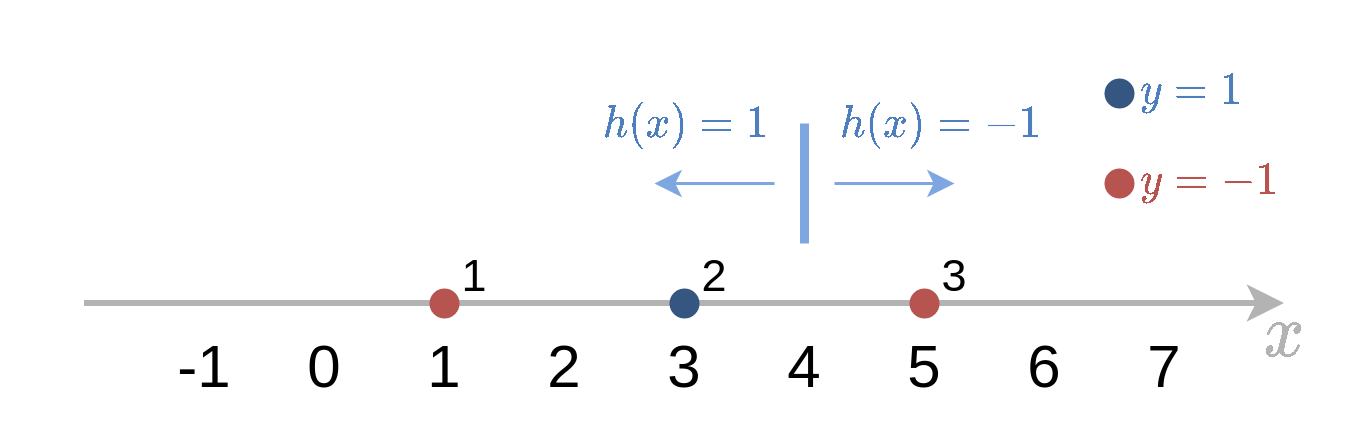
נתבונן בבעיית סיווג חד מימדית עבור סט דוגמאות האימון:
D={{1,−1},{3,1},{5,−1}}.
נרצה להשתמש במסווגים לינארים מסוג h~(x)=±sign(x−b) וב AdaBoost כדי לבנות מסווג. רשמו את ארבעת האיטרציות הראשונות של האלגוריתם ואת החזאי המתקבל אחרי כל צעד. הניחו כי: b∈{0,2,4}.
פתרון 5.1
נאתחל את וקטור המשקלים:
w(0)=[31,31,31]⊤
צעד 1
נבחר מבין המסווגים הנתונים את המסווג אשר ממזער את ה objective שהוא שגיאת 0-1 האמפירית הממושקלת.
i=1∑Nwi(0)I{y(i)=h~(x(i))}
נבחן את שלושת הערכים האפשריים של b:
b=0
במקרה זה עדיף לקחת את המסווג h~(x)=−sign(x) (עם סימון שלילי) כדי למזער את השגיאה האמפירית.
חזאי זה יטעה רק על הנקודה השניה i=2 ולכן נקבל:
i=1∑Nwi(0)I{y(i)=h~(x(i))}=w2(0)=31
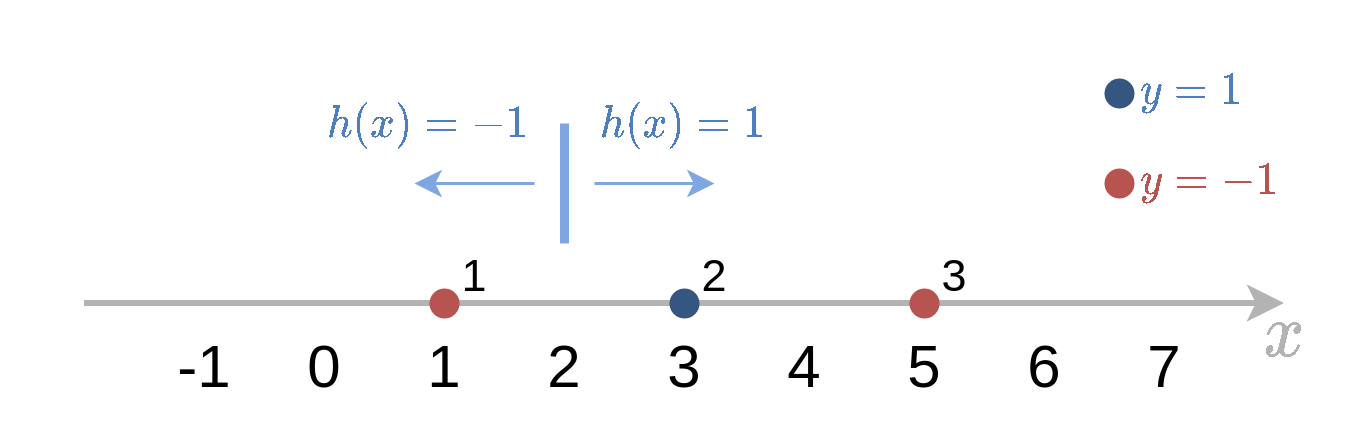
b=2
במקרה זה עדיף לקחת את המסווג h~(x)=sign(x−2) (עם סימון חיובי) כדי למזער את השגיאה האמפירית.
חזאי זה יטעה רק על הנקודה השלישית i=3 ולכן נקבל:
i=1∑Nwi(0)I{y(i)=h~(x(i))}=w3(0)=31
b=4
במקרה זה עדיף לקחת את המסווג h~(x)=−sign(x−4) (עם סימון שלילי) כדי למזער את השגיאה האמפירית.
חזאי זה יטעה רק על הנקודה השלישית i=1 ולכן נקבל:
i=1∑Nwi(0)I{y(i)=h~(x(i))}=w1(0)=31
מכיוון שכל שלושת החזאים מניבים את אותו objective נבחר את אחד מהם באקראי. נבחר אם כן את המסווג הראשון של האלגוריתם להיות h~1=−sign(x).
הסיווג אומנם לא השתנה, אך ככל שנריץ עוד צעדים של האלגוריתם הוא ימשיך לנסות למזער את N1∑i=1Nexp(−∑t=1Tαty(i)h~t(x(i))). במקרים רבים כאשר נמשיך להריץ את האלגוריתם יכולת ההכללה של האלגוריתם תמשיך להשתפר גם אחרי שהאלגוריתם מתכנס לסיווג מושלם על ה train set. (זה לא יקרה במקרה המנוון הזה).
תרגיל 5.2 - שאלות תיאורטיות
הסעיפים הבאים לא תלויים אחד בשני.
1) מדוע נעדיף ב AdaBoost להשתמש במסווגים בעלי יכולת ביטוי חלשה? לדוגמא מדוע נעדיף להשתמש בעצים בעומק 1 מאשר עצים מאד עמוקים?
2) נניח כי עבור מדגם כל שהוא בגודל N, מובטח לנו שבאלגוריתם ה AdaBoost נוכל תמיד למצוא מסווג כזה אשר יתן לנו שגיאה אמפירית קטנה מ 21−γ. מצאו חסם עליון על כמות הצעדים של AdaBoost שיש לבצע כדי לקבל סיווג מושלם.
רמז: מהי השגיאת ההשגיאה האמפירית (הלא ממושקלת) במצב בו המסווג טועה רק על דגימה אחת?
3) הראו שאם באלגוריתם AdaBoost ננסה להשתמש באותו המסווג בשני צעדים רצופים בצעד השני נקבל שגיאה אמפירית ממושקלת ששווה לחצי.
הראו שקבוע הנרמול של המשקלים נתון על ידי: ∑i=1Nw~i(t)=2εt(1−εt).
חשבו את השגיאה האמפירית הממושקלת עם משקלים wt והחזאי h~t (מהצעד ה t). עשו זאת על ידי הצבה של wi(t) ושל קבוע הנרמול שלו.
פתרון 5.2
1)
AdaBoost מגדיל את ההתאמה של חזאי למדגם על ידי בניית קומבינציה של חזאים. האלגוריתם מקטין את ה underfitting על חשבון ה overfitting. אם נתחיל עם מודלים בעלי יכולת ביטוי גדולה מידי המודלים יעשו overfitting ואותו האלגוריתם לא יוכל להקטין.
בפועל מה שיקרה אם ניקח מודלים בעלי יכולת ביטוי גדולה הוא שנמצא בצעד הראשון מודל שיסווג בצורה טובה את המדגם (אך גם כנראה יעשה הרבה overfitting) לו הוא יתן את מרבית המשקל.
2)
עבור מדגם בגודל N וחזאי עם שגיאת חיזוי אחת על המדגם נקבל שגיאה 0-1 אמפירית של N1. נמצא בעזרת החסם את כמות הצעדים שיש לעשות כדי להגיע לשגיאה קטנה מזו. על פי החסם על השגיאה של AdaBoost אנו יודעים כי:
N1i∑I{h(x(i))=y(i)}≤exp(−2t=1∑Tγ2)=exp(−2Tγ2)
נמצא את מספר הצעדים המינימאלי T אשר מקיים:
exp(−2Tγ2)⇔−2Tγ2⇔T≤N1≤ln(N1)≥2γ21ln(N)
מכאן שעבור T=⌈2γ21ln(N)⌉+1 מובטח לנו שנקבל שגיאה אמפירית קטנה מ N1, זאת אומרת שיש אפס שגיאות סיווג.
3)
נפעל על פי ההדרכה. נתחיל עם השלב הראשון. נשתמש בעובדה ש αt=21ln(εt1−εt) ונראה ש:
נחזור לבעיה מהתרגול על עצי החלטה של חיזוי אלו מהנוסעים על ספינת הטיטניק שרדו על פי הנתונים שלהם ברשימת הנוסעים. המדגם נראה כך:
pclass
survived
name
sex
age
sibsp
parch
ticket
fare
cabin
embarked
boat
body
home.dest
0
1
1
Allen, Miss. Elisabeth Walton
female
29
0
0
24160
211.338
B5
S
2
nan
St Louis, MO
1
1
0
Allison, Miss. Helen Loraine
female
2
1
2
113781
151.55
C22 C26
S
nan
nan
Montreal, PQ / Chesterville, ON
2
1
0
Allison, Mr. Hudson Joshua Creighton
male
30
1
2
113781
151.55
C22 C26
S
nan
135
Montreal, PQ / Chesterville, ON
3
1
0
Allison, Mrs. Hudson J C (Bessie Waldo Daniels)
female
25
1
2
113781
151.55
C22 C26
S
nan
nan
Montreal, PQ / Chesterville, ON
4
1
1
Anderson, Mr. Harry
male
48
0
0
19952
26.55
E12
S
3
nan
New York, NY
5
1
1
Andrews, Miss. Kornelia Theodosia
female
63
1
0
13502
77.9583
D7
S
10
nan
Hudson, NY
6
1
0
Andrews, Mr. Thomas Jr
male
39
0
0
112050
0
A36
S
nan
nan
Belfast, NI
7
1
1
Appleton, Mrs. Edward Dale (Charlotte Lamson)
female
53
2
0
11769
51.4792
C101
S
D
nan
Bayside, Queens, NY
8
1
0
Artagaveytia, Mr. Ramon
male
71
0
0
PC 17609
49.5042
nan
C
nan
22
Montevideo, Uruguay
9
1
0
Astor, Col. John Jacob
male
47
1
0
PC 17757
227.525
C62 C64
C
nan
124
New York, NY
השדות
בדומה למקרה של עצי ההחלטה נשתמש בשדות הבאים:
pclass: מחלקת הנוסע: 1, 2 או 3
sex: מין הנוסע
age: גיל הנוסע
sibsp: מס' של אחים ובני זוג של כל נוסע על האוניה
parch: מס' של ילדים או הורים של כל נוסע על האונייה
fare: המחיר שהנוסע שילם על הכרטיס
embarked: הנמל בו עלה הנוסע על האונייה (C = Cherbourg; Q = Queenstown; S = Southampton)
survived: התיוג, האם הנוסע שרד או לא
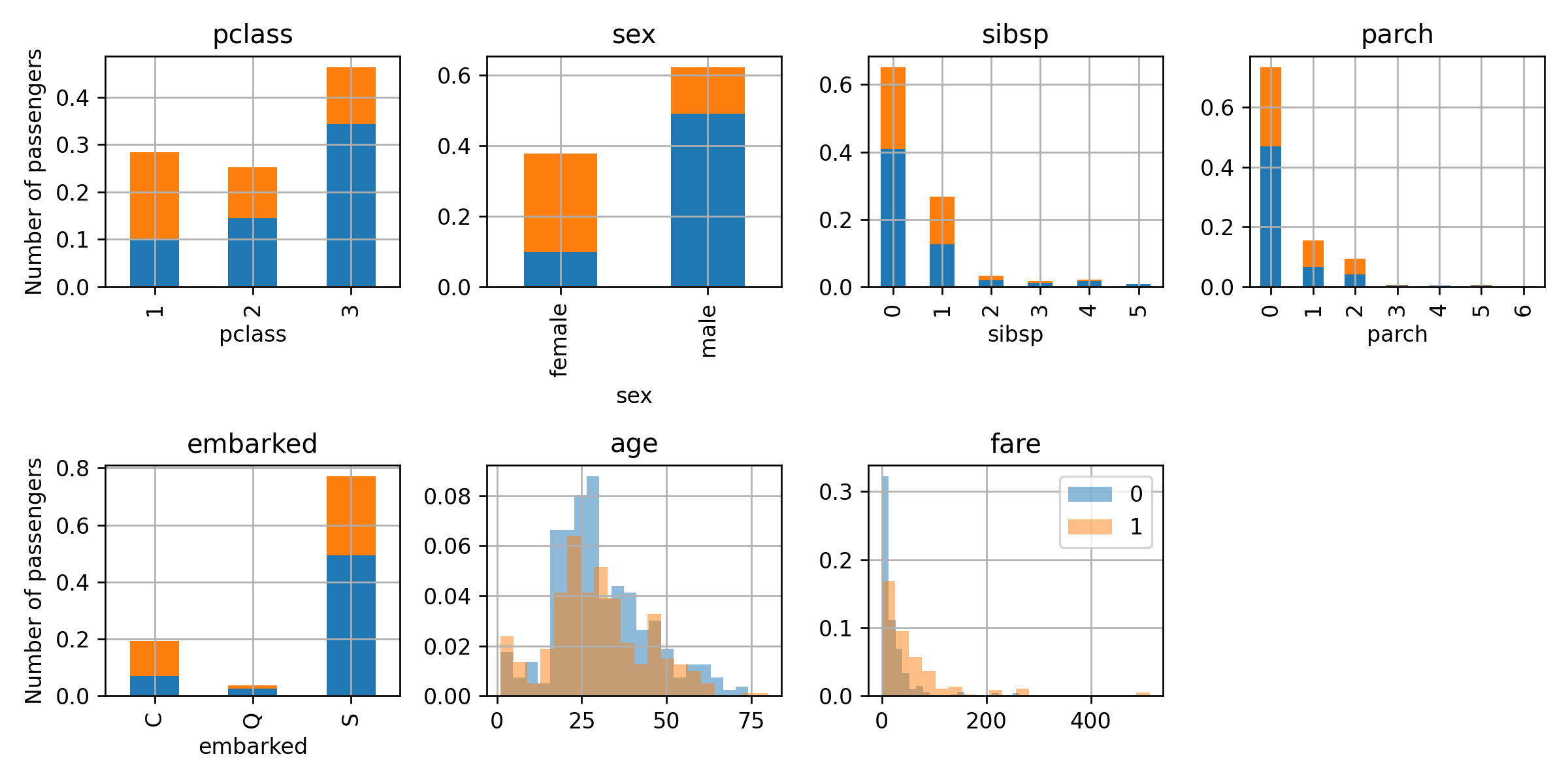
הפילוג של ערכים
הפילוג של כל אחד מהשדות עבור האנשים ששרדו והאנשים שלא:
סט המסווגים - Stumps
המסווגים בהם נשתמש הינם stumps (עצים בעומק 1). למשתנים הקטגוריים נעבור על כל האפשרויות לחלק את הקטגוריות.
בניית המסווג
אחרי שנחלק את המדגם ל train-validation-test נשתמש ב train בשביל לבנות את הקומבינציה של המסווגים.
גודל ה train set הוא 599. נאתחל את וקטור המשקלים w(0) להיות וקטור שמכיל את הערך 5991.
צעד 1
נעבור על כל ה stumps האפשריים ונחפש את זה שממזער את השגיאה האמפיריצ הממושקל. נקבל שה stump האופטימאלי הוא זה שמפצל לפי המגדר וחוזה שהנשים שרדו והגברים לא. המסווג שנקבל יהיה:
h(x)=sign(0.598⋅I{sex=female})
הציון על ה train set יהיה: 0.232
הציון על ה validation set יהיה: 0.226
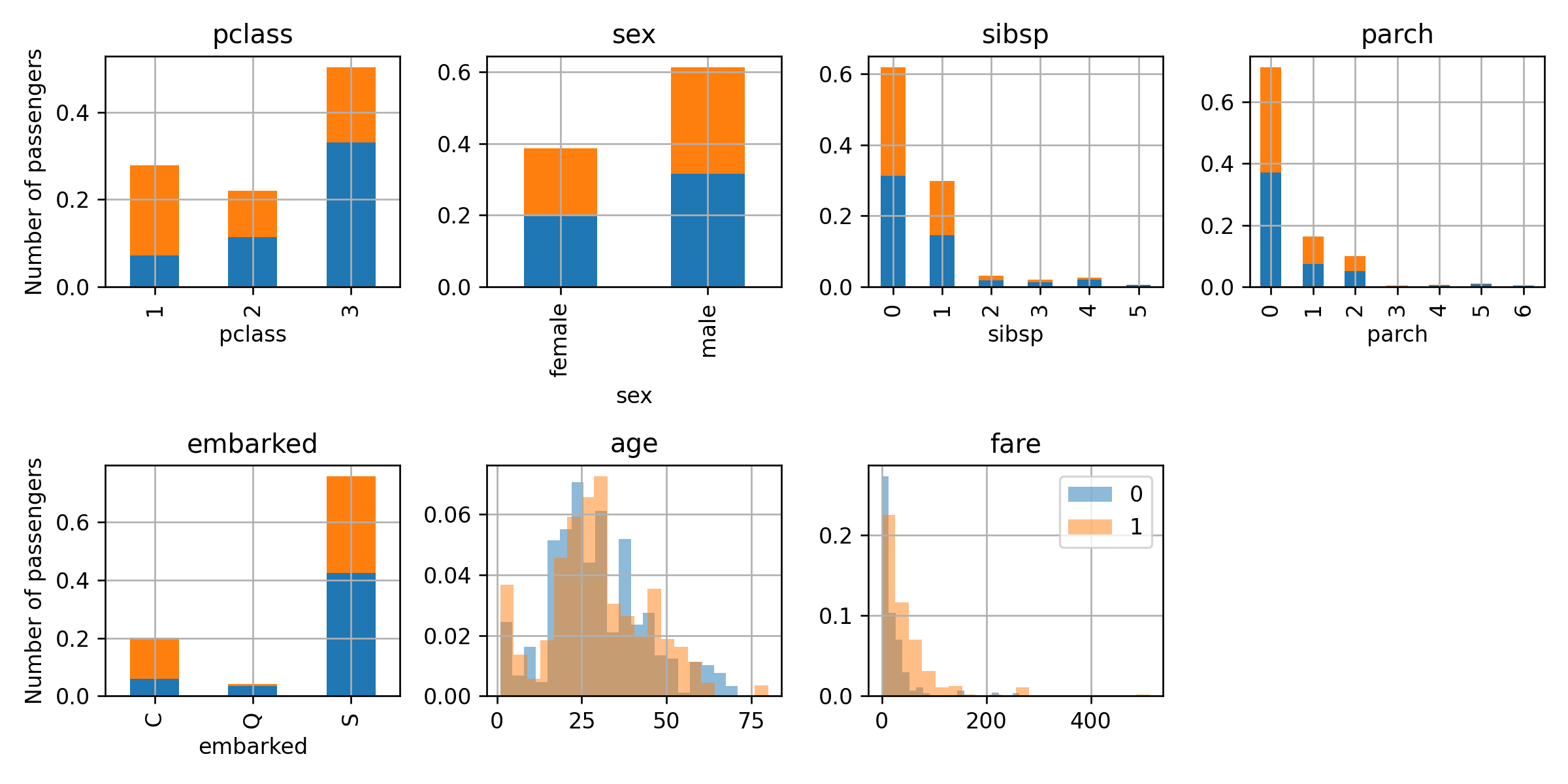
צעד 2
נצייר את הפילוג של הדגימות ממושקלות על ידי המשקלים המעודכנים:
ה stump האופטימאלי כעת יהיה זה שמפצל לפי המחלקה של הנוסעים וחוזה שנוסעים ממחלקה ראשונה שרדו והאחרים לא. המסווג שנקבל יהיה:
h(x)=sign(0.598⋅I{sex=female}+0.31⋅I{class=1})
הציון על ה train set וה validation set ישאר זהה.
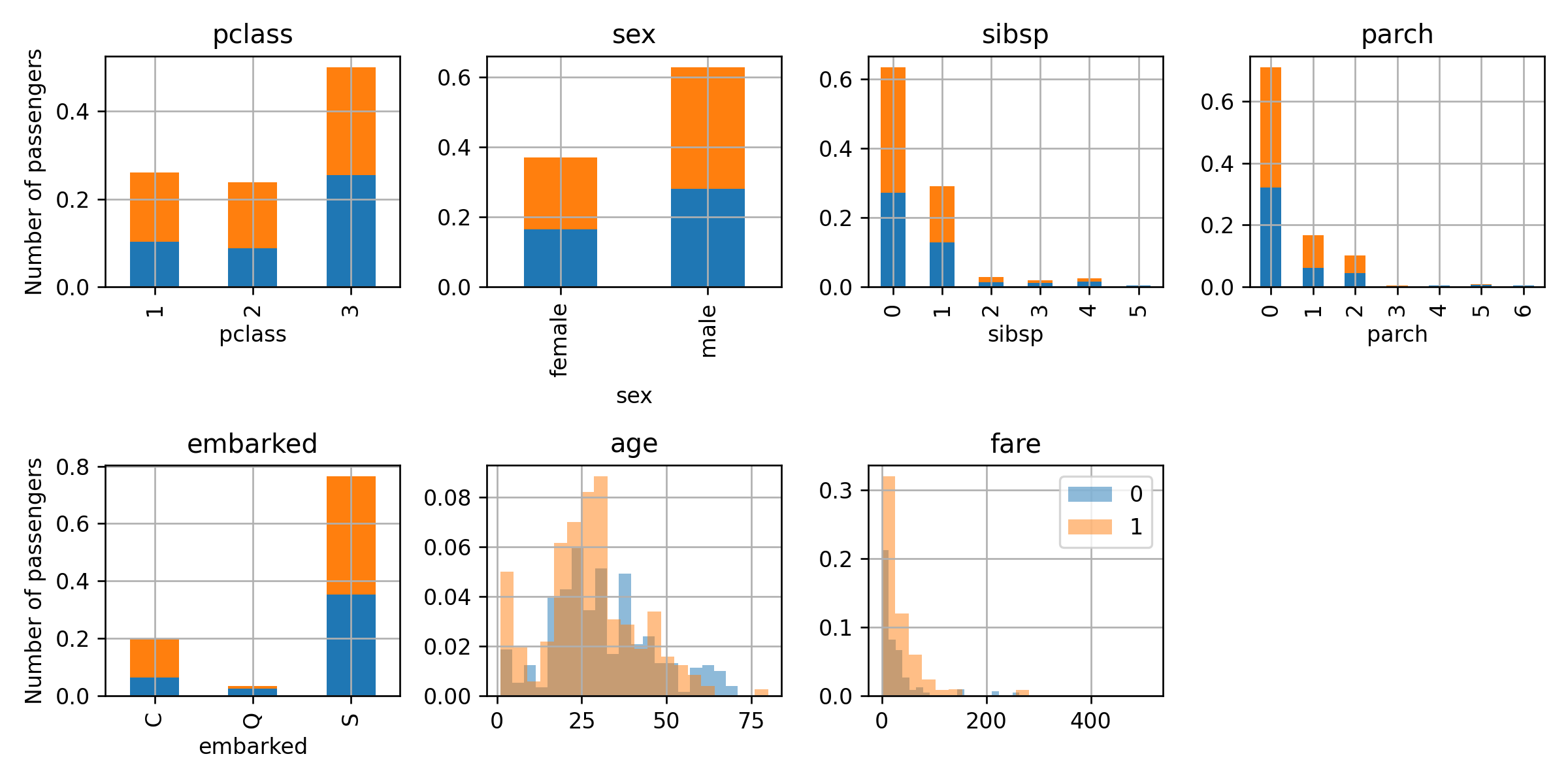
צעד 3
נצייר את הפילוג של הדגימות ממושקלות על ידי המשקלים המעודכנים:
ה stump האופטימאלי כעת יהיה זה שמפצל לפי הגיל וחוזה שנוסעים מתחת לגיל 35.5 שרדו. המסווג שנקבל יהיה: