נתונים שני משתנים אקראיים x ו y בעלי פילוג לא ידוע.
נתון לנו מדגם של זוגות של x ו y אשר יוצרו מ N דגימות בלתי תלויות:
D={x(i),y(i)}i=1N
מרחב החזאים \ השערות H. במרחב זה נמצאים כל החזאים האפשריים.
נסמן ב y^=h(x) חזאיים אפשריים של y בהינתן x.
נתונה לנו פונקציית מחירC(h) אשר מחשבת מחיר לכל חזאי. (C יכול להיות תלוי בפילוג).
נרצה למצוא את החזאי h∗ עם המחיר הנמוך ביותר.
הערות
את המשתנים y מקובל לכנות labels (תגיות).
את המשתנים x מקובל לכנות observations \ measurements (תצפיות / מדידיות).
גם x וגם y יכולים להיות וקטורים או סקלרים. המקרה הנפוץ הינו ש x הוא וקטור ו y סקלר.
רישום כבעיית אופטימיזציה
את הבעיה של מציאת החזאי האופטימאלי ניתן לרשום כ:
h∗=h∈HargminC(h)
בעיה: לרוב, פונקציית המחיר C תהיה תלויה בפילוג הלא ידוע. לשם כך נאלץ להשתמש במדגם כתחליף לפילוג הלא ידוע. במהלך הקורס נכיר כמה שיטות לעשות זאת.
אבחנה בין שני מקרים
מקובל לחלק את הבעיות בלמידה מונחית לשתי קטגוריות:
בעיות רגרסיה - המקרה בו y הוא משתנה רציף.
בעיות סיווג - המקרה בו y הוא משתנה בדיד המקבל סט סופי של ערכים.
(בעיקרון יכולות להיות גם בעיות בהן y בדיד ולא סופי. בבעיות מסוג זה לרוב פשוט מניחים שy רציף והופכים את הבעיה לבעיית רגרסיה)
פונקציות הפסד וסיכון
דרך נפוצה להגיד את פונקציית המחיר היא כתוחלת על פונקציית הפסד באופן הבא:
נגדיר פונקציה l אשר מחשבת לחיזוי בודד גודל המכונה loss (הפסד).
זאת אומרת שבעבור דגימה בודדת, עם ערכי x ו y כל שהם, ועם תוצאת חיזוי y^=h(x). ההפסד מוגדרת להיות:
l(y^,y)=l(h(x),y)
בעזרת פונקציית הloss ניתן להגדיר את פונקציית המחיר כתוחלת של ההפסד על פני הפילוג של x ו y:
C(h)=E[l(h(x),y)]
במקרים כאלה, מוקבל לכנות את פונקציית המחיר, פונקציית הrisk (סיכון), ולסמנה באות R:
R(h)=E[l(h(x),y)]
Empirical risk minimization (ERM)
אחת הדרכים הנפוצות לנסות ולהתמודד עם חוסר הידיעה של הפילוג, היא להחליף את התוחלת על הפילוג הלא ידוע, בתוחלת אמפירית על המדגם. התוחלת האימפרית מוגדרת כממוצע על פני אוסף של דגימות (במקרה שלנו על המדגם).
נסמן את התוחלת האימפירית על פני מדגם D ב E^D, ואת הrisk האמפירי ב R^D:
R^D(h)=E^D[l(h(x),y)]=N1i=0∑Nl(h(x(i)),y(i))
בעיית האופטימיזציה תהיה במקרה זה:
hD∗=h∈HargminN1i=0∑Nl(h(x(i)),y(i))
שיטה זו מוכנה empirical risk minimization (ERM).
שימו לב: מכיוון שהתוחלת האמפירית היא רק קירוב של התוחלת האמיתית, הפתרון של בעיית ה ERM גם יהיה רק קירוב של הפתרון של הבעיה המקורית. זאת אומרת שבמקרה הכללי hD∗=h∗.
מודלים פרמטריים
לרוב אנו נגביל את החיפוש של החזאי למשפחה מצומצמת של חזאים בעלי צורה קבועה עד כדי מספר סופי של פרמטרים. את הפרמטרים של המודל נסמן בעזרת הוקטור θ. אנו נשתמש ב h(x;θ) לתיאור של חזאי מהמשפחה עם פרמטרים θ.
דוגמא למשפחה פרמטרית:
h(x;θ)=θ1cos(θ2x)e−θ3x
כאשר עובדים עם מודל פרמטרי, האופטימיזציה היא למעשה על על הפרמטרים, והבעיה הופכת להיות:
θD∗=θargminN1i=0∑Nl(h(x(i);θ),y(i))
מאפיינים
בהינתן מודל פרמטרי כל שהוא, ניתן בקלות לייצר מודלים פרמטרים חדשים על ידי ביצוע עיבוד מקדים כל שהוא ל x לפני שהוא מוזן למודל. את העיבוד המקדים ניתן לתאר כאוסף של פונקציות φk אשר פועלות על x. את המידע המעובד (המוצא של ה φ-ים) מקובל לכנות מאפיינים. כמו כן, לרוב נוח לאגד את כל הפונקציות φ לפונקציה אחת Φ אשר פועלת על x ומחזירה את וקטור המאפיינים:
Φ(x)=[φ1(x),φ2(x),⋅,φM(x)]⊤
המודל הפרמטרי החדש יהיה הרכבה של h ו Φ:
hnew(x;θ)=h(Φ(x);θ)
דרך אחרת להסתכל על המאפיינים הינה שאנו כביכול מחליפים את המדגם שקיבלנו במדגם חדש באופן הבא:
xnew=Φ(xold)
רגרסיה לינארית
רגרסיה לינארית עוסקת בבעיות רגרסיה שבהם המודל הינו לינארי בפרמטרים שלו. זאת אומרת, בעיות בהם המודל הינו מהצורה של:
h(x;θ)=θ1x1+θ2x2+⋯+θdxd=x⊤θ
כפי שציינו קודם, וכפי שנראה בתרגיל, תמיד ניתן להשתמש במאפיינים על מנת לקבל פונקציות מורכבות יותר:
h(x;θ)=θ1φ1(x)+θ2φ2(x)+⋯+θMφM(x)=Φ(x)⊤θ
Linear least squares (LLS)
מקרה מיוחד הוא המקרה שבו משתמשים במודל לינארי יחד עם risk עם loss ריבועי:
l(y^,y)=(y^−y)2
במקרה זה, מתקבל בעיית אופטימיזציה אשר ניתן לפתור אותה באופן אנליטי:
בכדי לפתור את הבעיה, נוח יותר לרשום אותה בכתיב מטריצי.
נגדיר את הוקטור y כוקטור של כל התגיות במדגם:
y=[y(1),y(2),⋅,y(N)]⊤
נגדיר את המטריצה X כמטריצה של כל הx-ים במדגם:
X=⎣⎢⎢⎢⎢⎡−−−x(1)x(2)⋮x(N)−−−⎦⎥⎥⎥⎥⎤
בעזרת הגדרות אלו ניתן לרשום את בעיית האופטימיזציה של LLS באופן הבא:
θD∗=θargminN1∥Xθ−y∥22
הפתרון של LLS
את בעית האופטימיזציה הזו ניתן לפתור על ידי גזירה והשוואה ל-0, כפי שנעשה בתרגיל הראשון. הפתרון המתקבל הינו:
θD∗=(X⊤X)−1X⊤y
הפתרון הזה נכון כאשר X⊤X הפיכה. תנאי הכרחי בכדי שזה יקרה הינו שמספר הדגימות N יהיה גדול מהמימד של x (אשר נסמן כ D). כאשר המטריצה לא הפיכה יש לבעיה יותר מפתרון יחיד, כפי שנראה בהמשך.
(המטריצה (X⊤X)−1X⊤ נקראת Moore-Penrose pseudo inverse)
הערה
כשאר משתמשים במאפיינים המטריצה X תהיה:
X=⎣⎢⎢⎢⎢⎡−−−Φ(x(1))Φ(x(2))⋮Φ(x(N))−−−⎦⎥⎥⎥⎥⎤
תרגיל 2.1
הראו כי כאשר X⊤X הפיך, הפתרון של בעיית האופטימיזציה של LLS:
להבא בקורס, נשמיט את הרישום של x ו y בהגדרת המדגם ונרשום אותו בקצרה באופן הבא:
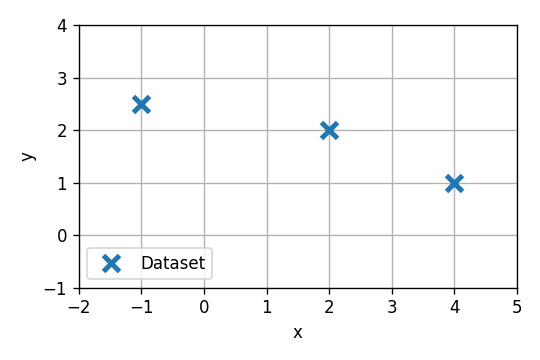
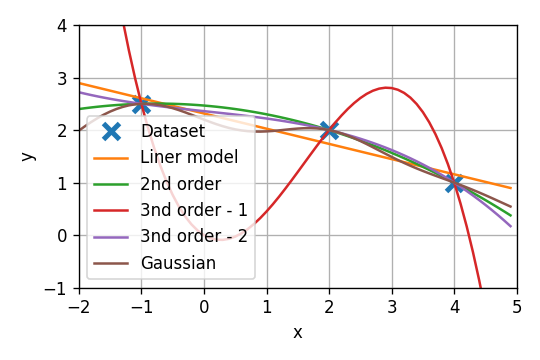
D={{−1,2.5},{2,2},{4,1}}
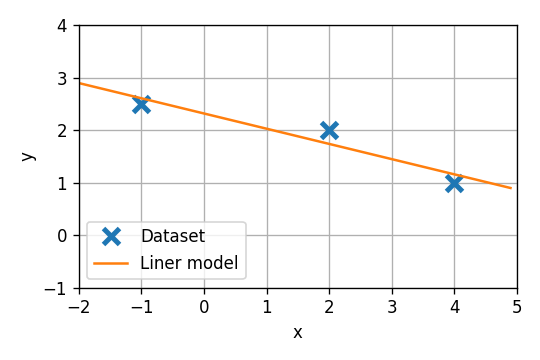
1) נרצה כעת להשתמש במאפיינים בכדי לקבל מודל שהוא פונקציה לינארית (עם איבר היסט) בx. רשמו את המאפיינים המתאימים ואת המודל המתקבל. מצאו את הפרמטרים של המודל האופטימאלי?
2) נרצה כעת להשתמש במאפיינים בכדי לקבל מודל שהוא פולינום מסדר 2 בx. רשמו את המאפיינים ואת המודל המתקבל ומצאו את הפרמטרים של המודל האופטימאלי?
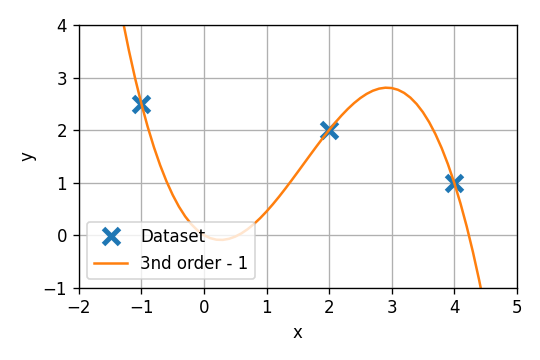
3) נרצה כעת להשתמש במאפיינים בכדי לקבל מודל שהוא פולינום מסדר 3 בx. האם במקרה זה קיים פתרון יחיד?
מצאו את הפתרונות למקרה שבו θ1=0 (איבר ההיסט מתאפס) ולמקרה שבו θ3=0 (המקדם של x2 מתאפס)
4) נרצה כעת להשתמש בפונקציות המאפיינים הבאות:
φm(x)=exp(−2σm2(x−μm)2)m∈1,2,3
כאשר
σ1=1.5,σ2=σ3=1μ1=−1,μ2=2,μ3=4
חשבו את הפרמטרים של המודל האופטימאלי בעבור מאפיינים אלו.
5) בעבור כל אחד מהסעיפים חשבו את הסיכון האמפירי המתקבל. האם לדעתכם סיכון אמפירי קטן יותר בהכרח מעיד על סיכון (לא אמפירי) קטן יותר?
פתרון 2.2
1)
אנו מעוניינים במודל מהצורה:
h(x;θ)=θ1+θ2x
כפי שראינו בהרצאה, ניתן להוסיף את איבר ההיסט על ידי שימוש במאפיינים. אנו נעשה זאת על ידי שימוש במאפיינים הבאים:
φ1(x)=1,φ2(x)=x
או בכתיב וקטורי
Φ(x)=[1,x]⊤
פעולה זו למעשה פשוט מוסיפה את האיבר 1 לx וכביכול יוצר את המדגם הבא:
D={{[1,−1]⊤,2.5},{[1,2]⊤,2},{[1,4]⊤,1}}
נרשום את X ו y:
X=⎣⎢⎡111−124⎦⎥⎤y=⎣⎢⎡2.521⎦⎥⎤
הפרמטרים האופטימאליים של המודל אשר ממזערים את הסיכון האמפירי יהיו אם כן:
כיוון שלמטריצה X יש יותר עמודות משורות (יש יותר פרמטרים מדגימות) המטריצה X⊤X בהכרח לא תהיה הפיכה. ולכן כפי שציינו קודם יהיו לבעיה הרבה פתרונות. (ניתן להראות כי המטריציה לא הפיכה לפי העובדה שלא יכולים להיות ב X⊤X יותר מ3 שורות בלתי תלויות ולכן המימד שלה הוא לכל היותר 3)
נסתכל על שני המקרים הפרטיים θ1=0 ו θ3=0.
θ1=0
במקרה זה המודל הפרמטרי מתנוון ל:
h(x;θ)=θ2x+θ3x2+θ4x3
אנו למעשה יכולים לפתור את זה כבעיית LLS עם וקטור פרמטריים θ=[θ2,θ3,θ4]⊤ ומאפיינים:
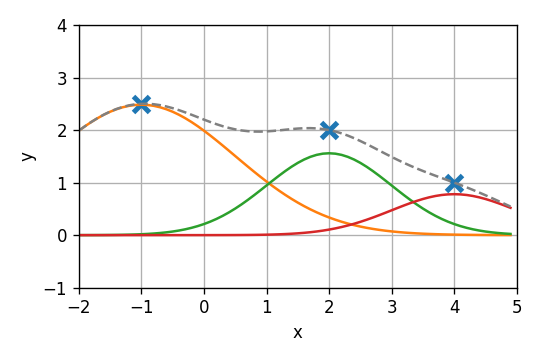
המודל הלינארי הוא פשוט קומבינציה ליניארית של פונקציות של x. לשם המחשה נראה כיצד התוצאה שהתקבלה היא למעשה קומבינציה לינארית של שלושת הגאוסיאנים של המאפיינים:
5)
נציג על גרף אחד את כל התוצאות שהתקבלו עד כה:
מלבד במקרה הלינארי, קיבלנו בכל המודלים שגיאה אמפירית 0.
הסבר: אנו למעשה מנסים למצוא וקטור פרמטרים כך ש Xθ יהיה כמה שיותר קרוב לy. כאשר יש יותר פרמטרים מדגימות ניתן תמיד (עד כדי מקרים שבהם יש תלויות לינאריות בין המאפיינים או הדגימות) למצוא וקטור θ כך שלבעיה הלינארית Xθ=y יהיה פתרון (מצב של יותר נעלמים ממשואות).
לגבי סיכון האמיתי, ללא מידע נוסף על הבעיה לא ניתן לדעת איזה מודל יכליל בצורה טובה יותר (יעבוד טוב יותר על דוגמאות לא מדגם), וכמובן שאין כל הכרח שמודלים עם שגיאה האמפירית הקטנה יותר יכלילו טוב יותר.
ניחושים
אנחנו כן נוכל לנסות להשתמש בניסיון שלנו מתכונות כלליות של מודלים בעולם האמיתי על מנת לשער איזה מודל יכליל טוב יותר. לדוגמא, הינו מצפים שהמודל לא "ישתולל", זאת אומרת שערכים קרובים של x יתנו ערכים יחסית דומים של y. מה שלא קורה במודל הראשון מסעיף 3 (הגרף האדום). ניתן לדוגמא לשער שהמודל הלינארי, שלא מניב שגיאה אמפירית של 0, יכליל בצורה טובה יותר מהמודל האדום.
בתרגול וההרצאה הקרובים, ננסה להשתמש בכלי בשם רגולריזציה בכדי לתרגם את הדרישה שהמודל לא "ישתולל" לדרישה מתמטית על מודל.
תרגיל 2.3
בעבור וקטור אקראי x באורך 2, x=(x1,x2)⊤ (או בכתיב מתמטי x∈R2), מהם המאפיינים בהם יש להשתמש על מנת לקבל פולינום מסדר 2 בערכים של x
כנראה שלא ניתן להשוות ביטוי זה ל-0 ולפתור אותו באופן אנליטי.
3)
תזכורת, אלגוריתם הגרדיאט מנסה למצוא מינימום לוקאלי על ידי התקדמות בכיוון ההפוך מהגרדיאנט של פונקציית המטרה (שאותה רוצים למזער). הוא עושה זאת בעזרת סדרה של צעדים באופן הבא:
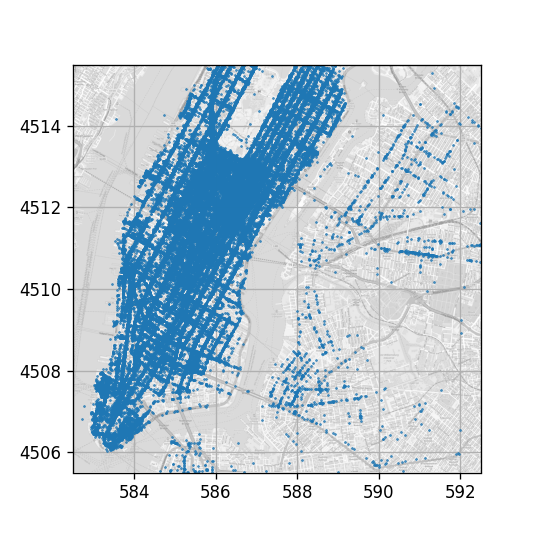
כחלק מהמאמץ של העיר New York להנגיש לציבור את המידע אותו היא אוספת, עריית NYC מפרסמת בכל חודש את הפרטים של כל נסיעות המונית אשר בוצעו בעיר באותו חודש. בקורס זה, אנו נעשה שימוש ברשימת הנסיעות מחודש ינואר 2016. ניתן למצוא את הרשימה, פה.
הרשימה המלאה כוללת מעל 10 מליון נסיעות, בכדי לקצר את זמן החישוב, אנו נעשה שימוש רק ברשימה חלקית הכוללת רק 100 אלף נסיעות (אשר נבחרו באקראי אחרי ניקוי מסויים של הרשימה). את הרשימה החלקית ניתן למצוא פה
המדגם ושדותיו
בטבלה מלטה מוצגים עשרת השורות הראשונות ברשימה
passenger count
trip distance
payment type
fare amount
tip amount
pickup easting
pickup northing
dropoff easting
dropoff northing
duration
day of week
day of month
time of day
0
2
2.76806
2
9.5
0
586.997
4512.98
588.155
4515.18
11.5167
3
13
12.8019
1
1
3.21868
2
10
0
587.152
4512.92
584.85
4512.63
12.6667
6
16
20.9614
2
1
2.57494
1
7
2.49
587.005
4513.36
585.434
4513.17
5.51667
0
31
20.4128
3
1
0.965604
1
7.5
1.65
586.649
4511.73
586.672
4512.55
9.88333
1
25
13.0314
4
1
2.46229
1
7.5
1.66
586.967
4511.89
585.262
4511.76
8.68333
2
5
7.70333
5
5
1.56106
1
7.5
2.2
585.926
4512.88
585.169
4511.54
9.43333
3
20
20.6672
6
1
2.57494
1
8
1
586.731
4515.08
588.71
4514.21
7.95
5
8
23.8419
7
1
0.80467
2
5
0
585.345
4509.71
585.844
4509.55
4.95
5
29
15.8314
8
1
3.6532
1
10
1.1
585.422
4509.48
583.671
4507.74
11.0667
5
8
2.09833
9
6
1.62543
1
5.5
1.36
587.875
4514.93
587.701
4513.71
4.21667
3
13
21.7831
הרשימה כוללת מספר שדות (עמודות), אך בתרגול זה אנו נתמקד רק בשדות הבאים:
pickup_easting - הקואורינאטה האורכית (מזרח-מערב) של נקודת האיסוף.
pickup_northing - הקואורינאטה הרוחבית (צפון דרום) של נקודת האיסוף.
dropoff_easting - הקואורינאטה האורכית של נקודת ההורדה.
dropoff_northing - הקואורינאטה הרוחבית של נקודת ההורדה.
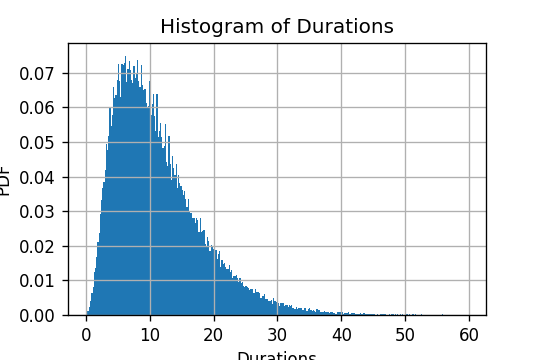
duration - משך הנסיעה בדקות.
(למתעניינים, הקואורדינאטות נתונות בפרומט בשם WGS84-UTM שבהם הקואורדינטות הם ביחידות של בערך קילומטרים)
ויזואליצזיה של נקודות ההורדה
הפילוג של זמן הנסיעה
הגדרה של הבעיה
בדוגמא זו ננסה לחזות את משך הנסיעה על פי נקודת האיסוף ונקודת ההורדה (הנקודות של תחילת הנסיעה וסיום הנסיעה). נסמן את המשתנה האקראי של משך הנסיעה ב y ואת ארבעת המשתנים של האיסוף וההורדה ב x:
נתחיל בלנסות להשתמש במאפיין בודד. מכיוון שאנו מצפים שהדבר שהכי ישפיע על זמן הנסיעה הינו המרחק שאותו יש ליסוע, ננסה להשתמש במרחק האווירי בין נקודת האיסוף לנקודת ההורדה כמאפיין שלנו:
זאת אומרת שהחיזוי שלנו יהיה פונקציה לינארית (ללא היסט) של המרחק האווירי בין נקודת האיסוף להורדה.
מציאת הפרמטר של המודל
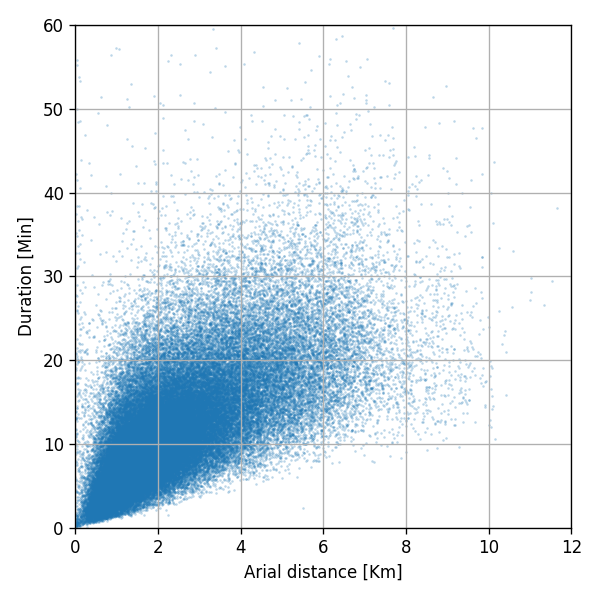
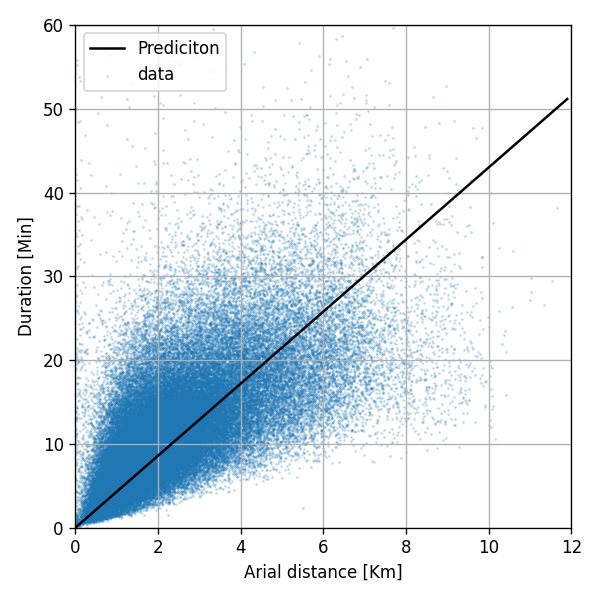
לפני שנחשב את הפרמטר נציג את התלות בין המרחק האווירי ומשך הנסיעה
ניתן לראות שישנו פיזור גדול ושהנקודות לא יושבות קרוב לקו ליניארי, אך עם זאת, ניתן לראות כי ישנה מגמה כללית של הנקודות. אנו נקווה שהמודל הליניארי ינסה ללמוד מגמה זו.
נחשב את הפרמטר של המודל מתוך הנוסחא:
θD∗=(X⊤X)−1Xy
כאשר X הוא הוקטור של המאפיין היחיד φdist
X=[φdist(x(1)),φdist(x(2)),…,φdist(x(N))]⊤
הפרמטר המתקבל מחישוב זה הינו:
θ=4.23
זאת אומרת שתחת המודל הלינארי החיזוי של זמן הנסיעה שווה למרחק האווירי אותו יש לעבור כפול 4.23.
נוסיף את המודל הלינארי על גבי הגרף הקודם:
אכן המודל הלינארי למד את המגמה הכללית של הנקודות.
נחשב את הסיכון האמפירי המתקבל בעבור מודל זה:
R^D(h)=N1i=0∑N(h(x(i))−y(i))2=32.67min2
בחירת מאפיינים - נסיון שני
ננסה להוסיף למודל עוד מאפיינים. ננסה להוסיף למודל פולינום מסדר שני של נקודת האיסוף תחת ההנחה שיש איזורים עמוסים יותר ואיזורים עמוסים פחות בעיר. המודל שלנו כעת יהיה:
מכיוון שמדובר בכמות גדולה של מאפיינים כבר לא ניתן להציג את הנתונים ופונקציית החיזוי בגרף.
חישוב של הפרמטרים והסיכון האמפירי בשיטה דומה לקודם נותנת סיכון אמפירי של:
R^D(h)=N1i=0∑N(h(x(i))−y(i))2=26.42min2
עוד מאפיינים
ניתן להמשיך באופן דומה ולהוסיף עוד ועוד מאפיינים. לרוב, כל הוספה של מאפיין תקטין את השגיאה האפירית. בתרגול ובהרצאה הקרובים נעסוק בבעיתיות של הוספת כמות גדולה מידי של מאפיינים ונדבר על דרכים כיצד לעשות זאת באופן מבוקר.