בתרגול הזה נעבור על המושגים הרלוונטיים בתורת ההסתברות ונדבר על חזאיים.
השימוש במודלים הסתבורתיים נפוץ בתחומים רבים ככלי לתיאור תהליכים ותופעות מסויימות. השימוש העיקרי במודלים אלו הוא לצורך חקירת התכונות של אותה תופעה ולצורך ביצוע חיזוי של משתנים מסויימים על סמך משתנים אחרים.
בתרגול זה, בתור דוגמא, נשתמש במודל הסתברותי אשר מתאר את התכונות של אנשים אשר מגיעים לקבל טיפול בבית חולים. בתור המשתנים האקראיים נגדיר דברים כגון הסימפוטים שאדם מסויים מדווח עליהם, הדופק שלו, לחץ הדם והמחלה/מחלות שמהם אותו אדם סובל. אנו נראה כיצד ניתן להשתמש במודל הסתברותי על מנת לתאר את הקשר בין אותם משתנים אקראיים. באופן כללי, בעזרת מודלים כאלה ניתן לנסות לחזות מהי ההסתברות שאדם חולה במחלה מסויימת בהינתן הסימפטומים והמדדים שלו.
בתרגול הקרוב אנו נעסוק במקרה שבו המודל ההסתברותי ידוע במלואו. זאת בשונה משאר כל שאר הקורס, שבו נעסוק במקרים שבהם המודל לא ידוע ונלמד כיצד ניתן להשתמש בשיטות חלופיות אשר מתבסות על אוסף של דגימות מתוך המודל כתחליף למודל עצמו.
מושגים בסיסיים בהסתברות
נתחיל בתזכורת קצרה למושגים הבסיסיים בתורת ההסתברות. נסתכל לשם כך על התופעה האקראית הבאה:
נניח ואנו לוקחים כוס מיץ, שופכים את תוכלתה על הרצפה ומסתכלים על הצורה של השלולית שנוצרה.
(חשוב לציין שזהו ניסוי מחשבתי ואין צורך לנסות את זה בבית).
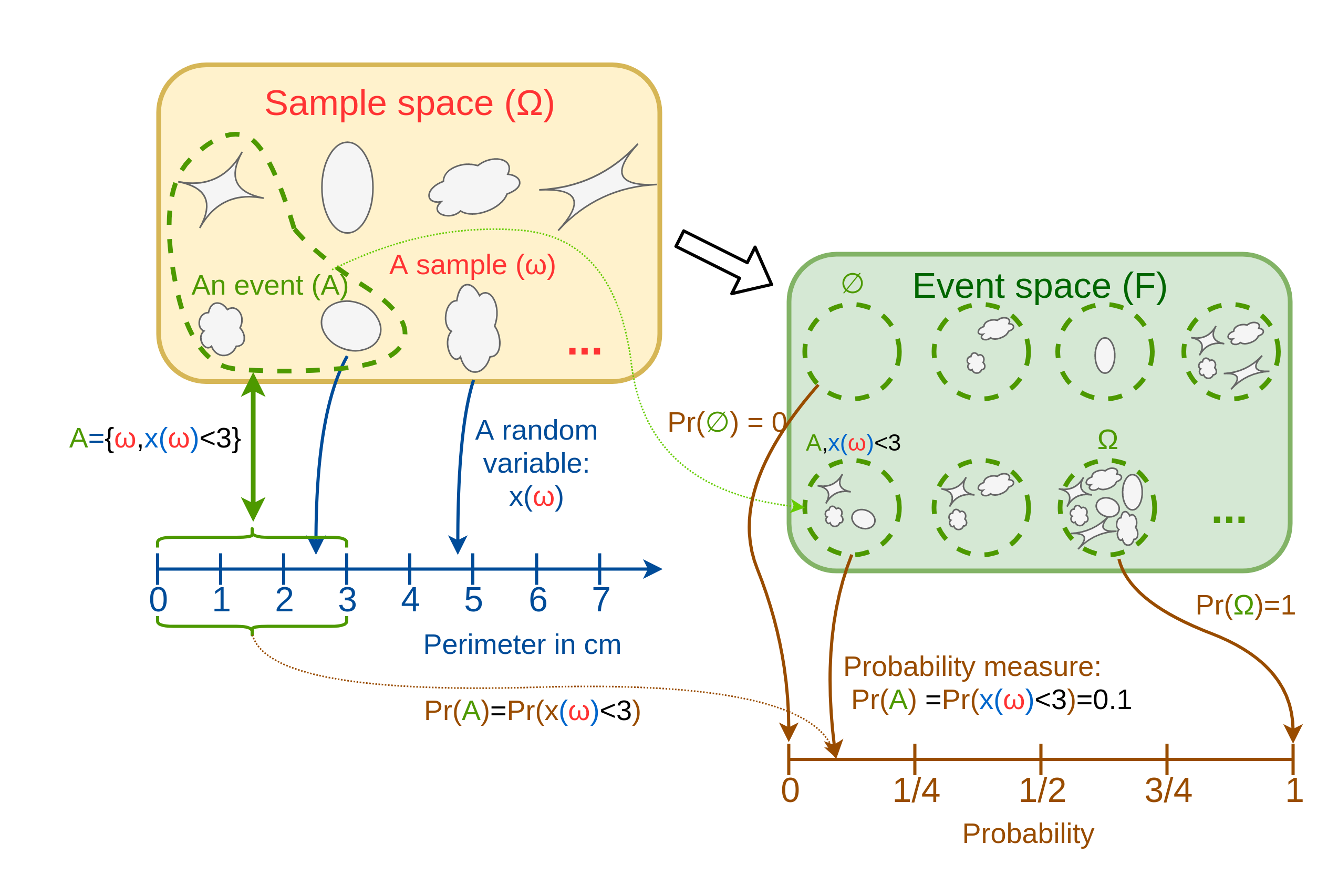
התופעה המתוארת אשר יוצרת בסופו של דבר את השלולית היא תופעה אקראית, שכן ישנו מגוון רחב של תוצאות שיכולות להתקבל מהתהליך הזה. נגדיר בטבלה הבאה את המושגים ההסתברותיים הרלוונטיים הקשורים לתופעה הזו ואת הסימונים המוקובלים (בהם נעשה שימוש בקורס). מתחת לטבלה תמצאו שרטוט אשר ממחיש את הקשר בין המושגים האלו.
המושג
סימון מקובל
הגדרה
בדוגמא שלנו
Random phenomenon (תופעה אקראית)
--
תופעה בעלת תוצר אקראי.
יצירת שלולית על הריצפה על ידי שפיכה של כוס מיץ
Sample (דגימה)
ω
תוצר אפשרי של התופעה האקראית.
צורת שלולית מסויימת (לדוגמא שלושית בצורת ריבוע עם צלע באורך 10 ס"מ")
Sample space (מרחב המדגם)
Ω
המרחב המכיל את כל התוצרים האפשריים של התופעה. Ω={∀ω}
המרחב של כל צורות השלוליות הקיימות
Random Variables (RV) (משתנה אקראי)
x(ω),y(ω),...
פונקציה x:Ω→R אשר משייכת לכל דגימה מספר.
פונקציה אשר מחזירה את ההיקף של כל שלולית: x1(ω) פונקציה אשר מחזירה את השטח של כל שלולית: x2(ω)
Event (מאורע)
A,B,...
אוסף של דגימות. זאת אומרת, תת קבוצה של מרחב המדגם A⊆Ω. הדרך הנוחה ביותר להגדיר מאורעות היא על ידי תנאי על משתנה אקראי כל שהוא.
אוסף כל השלוליות שהרדיוס שלהם קטן מ 2 A={ω:x1(ω)<2} אוסף כל השלושיות שהשטח שלהם גדול מ 1 B={ω:x2(ω)>1}
Event space (מרחב המאורעות)
F
המרחב של כל המאורעות האפשריים שניתן להגדיר A∈F.
--
Probability measure (הסתברות)
Pr(A)
פונקציה Pr:F→[0,1] אשר ממפה כל מאורע למספר בין 0 ו1 אשר מציין את הסיכוי שאותו מאורע יתרחש (זאת אומרת, הסיכוי שדגימה תהיה שייכת למאורע).
פונקציה Pr:F1×F2→[0,1] אשר מחזירה את ההסתברות שמאורע מסויים יקרה, תחת הידיעה שמאורע אחר קרה.
ההסתברות ששלולית תהיה בעלת היקף קטן מ 2 תחת הידיעה שהשטח שלה גדול מ 1: Pr(A∣B)=Pr(x1<2∣x2>1)=0.02
שתי הערות לגבי הסימונים:
בחרנו לסמן את המשתנים הקראיים באותיות לטיניות קטנות לא מוטות (non-italic) בכדי להישאר צמודים לנוטציות של הספר Deep Learning (ראה תרגול או הרצאה קודמים). סימון מעט יותר נפוץ למשתנים אקראיים הוא אותיות לטיניות גדולות כגון X ו Y. (אשר מתנגש הסימון של מטריצות).
בכתב יד, נשתמש בקו עילי על מנת לסמן את המשתנים האקראיים (לדוגמא: xˉ, xˉ או Xˉ)
בשתי השורות האחרונות השתמשנו בסימונים מהצורה x<2 כקיצור ל {ω:x(ω)<2}. זוהי צורת כתיבה נפוצה ואנו נשתמש בה מכאן והלאה. (מבחינה מתמטית הסימון המקוצר חסר משמעות שכן הוא משווה בין פונקציה לבין מספר).
פונקציות של משתנים אקראיים:
כאשר אנו מפעילים פונקציה נוספת על המוצא של משתנה אקראי (לדוגמא, להעלות את רדיוס השלולית בריבוע) אנו למעשה מרכיבים שני פונקציות ויוצאים משתנה אקראי חדש.
Realizations (ראליזציות) ושיבוש נפוץ
מבחינת המינוח המדוייק, התוצאות שמתקבלות מהפעלה של המשתנים האקראיים, זאת אומרת המספרים שאנו מודדים בפועל, נקראים ריאלוזציות. בפועל, השימוש במושג זה לא מאד נפוץ ולרוב משתמשים בשם דגימות בכדי לתאר את הריאליזציות. לדוגמא: נתונות 20 דגימות של היקפים של שלוליות. בקורס זה, גם אנחנו נכנה את המדידות עצמם בשם דגימות.
סימונים
וקטורים אקראיים
לרוב יעניין אותנו לעבוד עם יותר ממשתנה אקראי יחיד. במקרה כזה נוח לאחד את כל המשתנים האקראיים לוקטור המכונה וקטור אקראי:
x=x(ω)=[x1(ω),x2(ω),…,x3(ω)]⊤
(ניתן באופן דומה להגדיר גם מטריצות וטנזורים אקראיים)
דוגמא - מיון מקדים של חולים
נניח ואנו מעוניינים לעזור בפיתוח של מערכת למיון מקדים של חולים לצורך המשך טיפול, לשם כך אנו רוצים להסתמך על מודל הסתברותי אשר מתאר את המאפיינים של האנשים אשר משתמשים במערכת. אנו נגדיר בתור דגימה בודדת ω משתמש יחיד (בעל מאפיינים מסויימים) אשר מגיע להשתמש במערכת.
רובוט של חברת temi הישראלית אשר יכול לסייע להכוונת חולים להמשך טיפול.
תרגיל 1.1: תרגיל חימום בהסתברות
1) בעבור המודל הנ"ל, תנו דוגמא/ות לגדלים הבאים:
2 משתנים אקראיים דיסקרטים (בדידים)
2 משתנים אקראיים רציפים.
2 מאורעות.
2) המציאו הסתברויות למאורעות שבחרתם.
3) המציאו הסתברות לחיתוך (intersection) של שני המאורעות שבחרתם.
4) מה תהיה הסתברות של האיחוד (union) של המאורעות (על סמך סעיפים 2 ו 3)?
5) מה תהיה ההסתברות של החיסור של המאורע השני מהמאורע הראשון?
6) מה תהיה ההסתברות המותנית של המאורע הראשון בהינתן השני?
פתרון 1.1
1) דוגמאות:
משתנים אקראיים דיסקרטיים:
הדופק של המשתמש: p(ω)
כמות הפעמים שהמשתמש השתעל בשעה האחרונה: c(ω).
משתנה בולינאני (boolian) (בינארי) אשר מציין האם המשתמש חולה בשפעת (1 - חולה, 0 - לא): f(ω).
משתנים אקראיים רציפים:
החום של המשתמש במעלות: t(ω).
לחץ הדם (הסיטולי) של המשתמש: p(ω)
מאורעות:
החום של המשתמש גבוהה מ39°: t>39
המשתמש חולה בשפעת: f=1.
2) נניח שאלו הם ההסברויות המתאימים למאורעות שבחרנו:
Pr(t>39)=0.2
Pr(f=1)=0.1
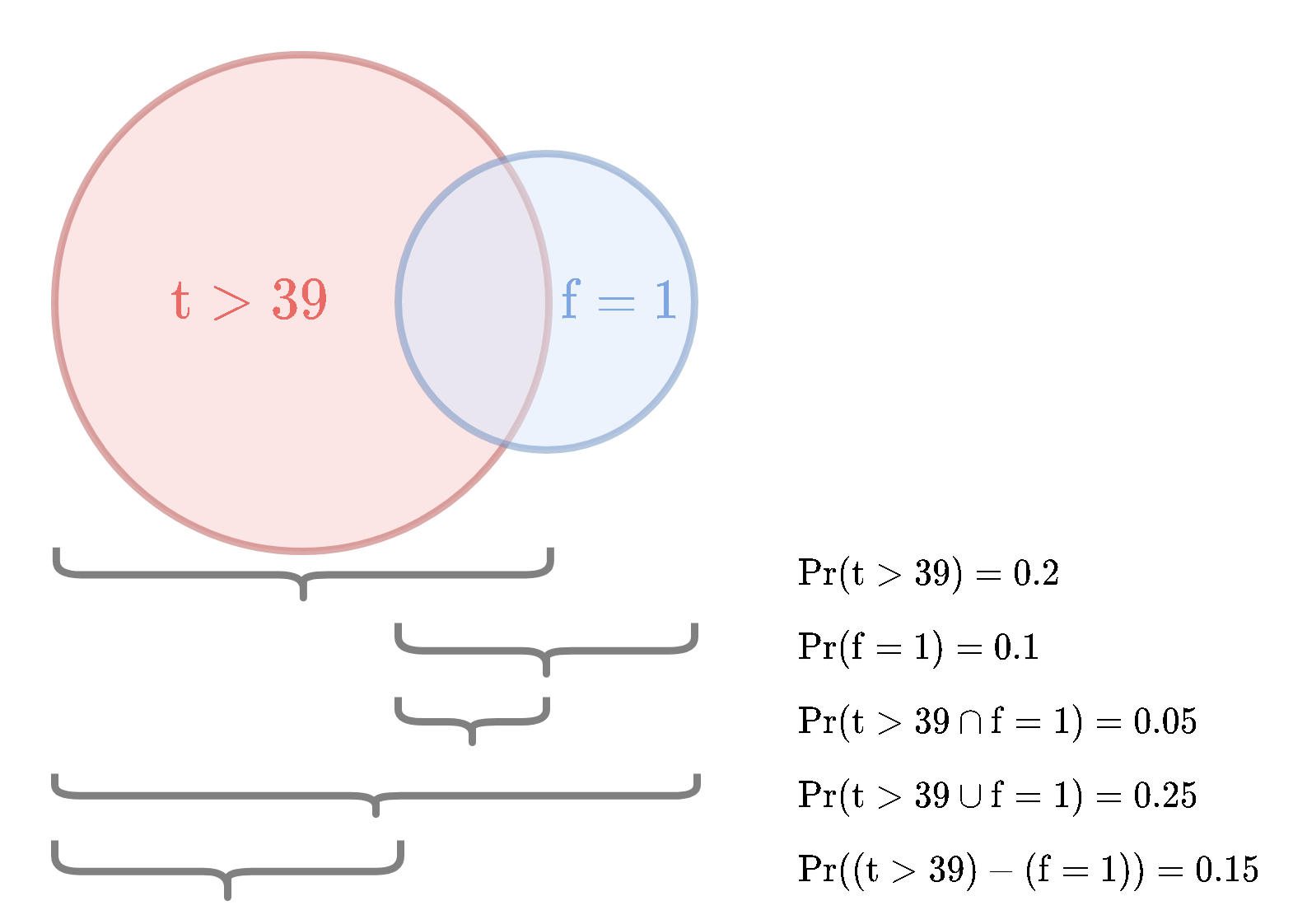
3) נניח כי ההסתברות של החיתוך של שני המאורעות הינו: Pr(t>39∩f=1)=0.05
בכדי לענות על הסעיפים הבאים נשתמש בדיאגרמה הבאה (המכונה דיאגרמת Venn)
6)על פי הגדרה, ההסתברות המותנית של המאורע הראשון בהינתן המאורע השני שווה ל:
Pr(t>39∣f=1)=Pr(f=1)Pr(t>39∩f=1)=0.10.05=0.5
פונקציות פילוג (Distributions)
את ההסתברויות נוח לתאר בעזרת פונקציות פילוג. נרשום את ההגדרה של פונקציות הפילוג בעבור וקטורים אקראיים (פונקציות הפילוג של סקלרים הם כמובן מקרה פרטי של פונקציות אלו)
Cumulative Distribution Function - CDF (פונקציית הפילוג המצרפית)
סימון מקובל לפונקציית הCDF של וקטור אקראי x הוא Fx(x) והוא מוגדר באופן הבא:
Fx(x)=Pr(x1≤x1∩x2≤x2…∩xn≤xn)
Probability Mass Function - PMF (פונקציית ההסתברות)
פונקציה המתארת את הפילוג של משתנים \ וקטורים אקראיים דיסקרטיים. סימון מקובל לPMF הוא fx(x) או px(x) והוא מוגדר באופן הבא:
px(x)=Pr(x=x1∩x2=x2…∩xn=xn)
Probability Density Function - PDF (פונקציית צפיפות ההסתברות)
זו המקבילה של הPMF למקרה הרציף. גם היא מסומנת לרוב על ידי fx(x) או px(x).
במקרים בהם הCDF הוא גזיר, הPDF מוגדרת כ:
px(x)=∂x1∂∂x3∂…∂xn∂Fx(x)
בשאר המקרים היא מוגדרת על ידי האינטגרל הבא:
Fx(x)=∫−∞x1∫−∞x2…∫−∞xnpx(x)dxn…dx2dx1
פונקציות פילוג מותנות
באופן דומה, ניתן להגדיר גם את הגירסא המותנית של פונקציות הפילוג:
CDF
Fx∣y(x∣y)=Pr(x1≤x1∩x2≤x2…∩xn≤xn∣y=y)
PMF
px∣y(x∣y)=Pr(x1=x1∩x2=x2…∩xn=xn∣y=y)
PDF
px∣y(x∣y)=∂x1∂∂x3∂…∂xn∂FX(x∣y)
נוסחאות חשובות
The law of total probability (נוסחאת ההסתברות השלמה)
מכיוון שהמאפיינים של המשתמשים הינם בלתי תלויים הסיכוי לקבל קומבינציה כל שהיא של מאורעות שווה למכפלת ההסתברויות של כל מאורע בנפרד. נתחיל בלחשב את ההסתברות שלמשתמש יחיד יהיה דופק גבוה או שווה ל70. לשם כך נחשב את הפילוג השולי של הדופק של משתמש, נעשה זאת בעזת נוחסאת ההסתברות השלמה:
את המכנה נוכל לחשב בקלות על ידי שימוש בעובדה ש pt(t)=∑p~pt∣p(t∣p~)pp(p~) (נוסחאת ההסתברות השלמה), זאת אומרת שעלינו פשוט לסכום את התוצאות הנ"ל. התפקיד של המכנה הוא למעשה להיות קבוע נרמול (שאינו תלוי ב p) אשר דואג לכך שסכום ההסתברויות השלויות על פני p תהיה 1.
בעבור וקטור אקראי x מגדירים את מטריצת הconvariance כאשר האיבר הi,j של המטריצה הוא הcovariance בין xi ל xj. מקובל לסמן מטריצה זו באות Σ:
Σx,i,j=cov(xi,xj)
ניתן להראות כי את מטריצת הcovariance ניתן לכתוב גם כ:
Σx=E[xx⊤]−μxμx⊤
וקטורים גאוסיים (Gaussian Vectors) - Multivariate Normal Distribution
בדומה למקרה החד מימדי, הפילוג הגאוסי ממשיך לשחק תפקיד מרכזי גם כאשר מגדילים את מספר המימדים. ההרחבה של הפילוג הגאוסי למספר מימדים נקרא פילוג multivariate normal distribution. וקטורים שמפולגים על פי פילוג זה מכונים וקטורים גאוסיים. בדומה למקרה החד מימדי, הפילוג הזה מוגדר על ידי וקטור התוחלות שלו μx ומטריצת הcovariance שלו Σx:
px(x)=(2π)n∣Σx∣1exp(−21(x−μx)TΣx−1(x−μx))
כאשר n הוא מספר המימדים (האורך של הוקטור הגאוסי).
תנאי הכרחי ומספיק בשביל שוקטור אקראי יהיה גאוסי, הינו שכל כקומבינציה לינארית של איברי הוקטור יהיו בעלי פילוג גאוסי (סקלארי).
חזאיים (Predictions)
בפעולת החיזוי אנו מנסים לחזות את ערכו של משתנה אקראי כל שהוא, לרוב על סמך משתנים אקראיים אחרים. מקובל לסמן חזאים בעזרת ^, למשל, את החזאי של המשתנה האקראי x נסמן ב x^.
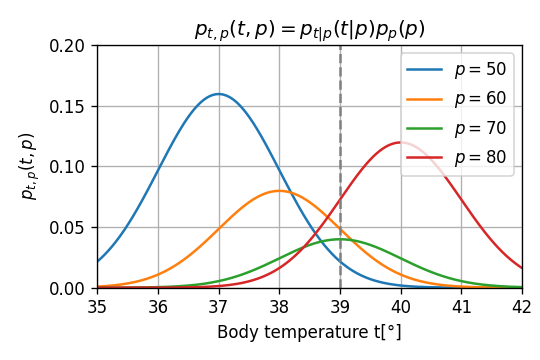
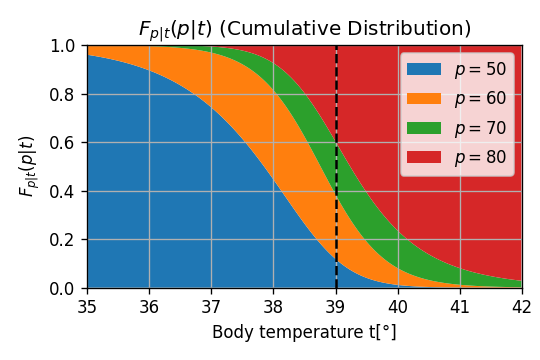
נקח בתור דוגמא את הנסיון לחזות מהו הדופק של משתמש מסויים על סמך חום הגוף שלו. ראינו קודם כיצד ניתן לחשב את הפילוג של הדופק בהינתן הטמפרטורה, קיבלנו את הפילוג המותנה הבא:
נשאלת השאלה אם כן מהו החזאי האופטימאלי של הדופק של המשתמש בהינתן שחום הגוף שלו היא 39°? לשם כך עלינו להגדיר קודם למה אנו מתכוונים ב"חזאי אופטימאלי". מסתבר שאין תשובה אחת לשאלה הזו. נסתכל על כמה אופציות להגדיר חזאי שכזה:
אופציה ראשונה: נניח שהמטרה שלנו היא להגדיל את ההסתברות שהחזאי שלנו יחזה את הדופק במדוייק. במקרה כזה כדאי לנו לבחור את החזאי p^=80, שכן זוהי האופציה בעלת ההסתברות הכי גבוהה להתקבל.
אופציה שניה נניח שהמטרה שלנו היא לדאוג שהשגיאה הממוצעת (הערך המוחלט של ההפרש בין החיזוי לדופק האמיתי) תהיה כמה שיותר קטנה. במקרה כזה כדאי לנו לבחור את החזאי p^=70, אשר יניב שגיאה ממוצעת של 9.
אופציה שלישית נניח והמטרה שלנו היא דווקא למזער את הטעות המקסימאלית. במקרה כזה כדאי לנו לבחור את מרכז התחום שהוא p^=65 (אשר יבטיח לנו שגיאה מירבית של 15).
כפי שניתן לראות, הבחירה של החזאי האופטימאלי תלויה במטרה אותה אנו רוצים להשיג. נראה כעת כיצד ניתן להגדיר את המטרה כבעיית אופטימיזציה שהחזאי האופטימאלי הוא הפתרון שלה.
פונקציית המחיר (Cost Function)
ראשית נגדיר פונקציה המכונה פונקציית המחיר (cost function). פונקציה זו מקבל חזאי ומחזירה את הציון של החזאי. לרוב הציון מוגדר כך שציון נמוך יותר הוא טוב יותר. לדוגמא, פונקציית המחיר הבאה מחזירה את השגיאת החיזוי הממוצעת של הדופק:
C(p^)=E[∣p−p^∣∣t=39]
בהינתן פונקציית מחיר שכזו, ניתן לרשום את החזאי האופטימאלי כחזאי אשר ממזער את פונקציית המחיר:
p^∗=p^argminC(p^)
פונקציית הסיכון (Risk Function) וההפסד (Loss)
דרך נפוצה להגדיר פונקציות מחיר הינה כתוחלת על מרחק כל שהוא בין תוצאת החיזוי לערך האמיתי של המשתנה האקראי (כמו בדוגמא למעלה). במקרים כאלה מקובל לקרוא לפונקציית המחיר פונקציית סיכון (risk function) ולפונקציית המרחק (שעליה מבצעים את התוחלת) פונקציית ההפסד (loss function). סימונים מקובלים לפונקציות ההפסד ופונקציית הסיכון הינם ℓ ו R בהתאמה, כאשר:
R(p^)=E[ℓ(p^,p)]
הטבלה הבאה מציגה את שלושת פונקציות הסיכון וההפסד הנפוצות ביותר:
המשמעות
פונקציית ההפסד
השם של פונקציית ההפסד
השם של פונקציית הסיכון
ההסתברות לעשות טעות
ℓ(x,x^)=I{x^=x}
Zero-one loss
Misclassification rate
השגיאה הממוצעת
ℓ(x,x^)=∣x^−x∣
l1
MAE (mean absolute error)
השיגאה הריבועית הממוצעת
ℓ(x,x^)=(x^−x)2
l2
MSE (mean squared error)
הסימון I{⋅} מציין פונקציית אינדיקטור (אשר שווה ל1 כאשר התנאי שבסוגריים מתקיים ו0 אחרת).
במקרים רבים משתשמים גם בשורש השגיאה הריבועית הממוצעת RMSE כפונקציית סיכון. מבחינת מעשית, אין הבדל בין השתיים שכן בעיית האופטימיזציה המתקבל היא שקולה (בגלל המונוטוניות של פונקציית השורש). זאת אומרת שלMSE וRMSE יש את אותו החזאי האופטימאלי.
פונקציית הסיכון הראשונה הינה הנפוצה ביותר למקרים בהם מנסים לחזות משתנה אקראי דיסקרטי.
פונקציית הסיכון האחרונה הינה הנפוצה ביותר למקרים בהם מנסים לחזות משתנה אקראי רציף.
תרגיל 1.4 - החזאים האופטימאלים של פונקציות הסיכון הנפוצות
1) בעבור משתנה אקראי דיסקרטי x, עם misclassification rate כפונקציית סיכון, הראו כי החזאי האופטימאלי הינו הערך הסביר ביותר:
x^∗=x^argminE[I{x^=x}]=x^argmaxpx(x^)
2) בעבור משתנה אקראי רציף x עם MAE כפונקציית סיכון, הראו כי החזאי האופטימאלי הינו הmedian:
x^∗=x^argminE[∣x−x^∣]⇒Fx(x^∗)=21
(בעבור המקרה הבדיד, ראו דוגמא בתרגיל 1.5)
3) בעבור MSE (או RMSE) כפונקציית סיכון, הראו כי החזאי האופטימאלי הינו התוחלת:
x^∗=x^argminE[(x−x^)2]=E[x]
פתרון 1.4
1)
x^∗=x^argminE[I{x^=x}]
נרשום את התוחלת באופן מפורש:
=x^argminx∑I{x^=x}px(x)
הסכימה פה היא למעשה על כל הערכים של x מלבד x^. נוכל לרשום את הסכום הזה כסכום על כל הערכים פחות הערך בx^:
השתמשו בתוצאות הסעיף הקודם על מנת לקבוע בעבור כל אחד מ3 פונקציות הסיכון הנפוצות מהטבלה מהו החזאי האופטימאלי של הדופק של המשתמש בהינתן שחום הגוף שלו הינו 39°.
בעבור misclasification rate החזאי האופטימאלי הוא הערך הסביר ביותר:
p^∗=p^argmaxpp∣t(p^∣39)=80
בעבור MAE:
מכיוון שמדובר במשתנה אקראי דיסקרטי לא קיים לו median. במקרה החזאי האופטימאלי הוא המספר אשר ההסתברות לקבל ערך גדול ממנו וההסתברות לקבל ערך קטן ממנו, שניהם קטנים מ-0.5.
בדוגמא שלנו המספר הזה הוא p^=70. (עם הסתברות של 0.39 לקבל ערך קטן ממנו והסתברות של 0.4 לקבל ערך קטן ממנו)