מרבית הבעיות והשיטות בתחום של מערכות לומדות עוסקות בבעיה של התאמת מודל מתמטי כך שיתאר בצורה מיטבית תופעה או תהליך מסויים על סמך אוסף נתון של תצפיות / מדידות. בהרצאה הראשונה נציג את התחום באופן מפורט יותר, אך לעת אתה הגדרה זו תספק אותנו.
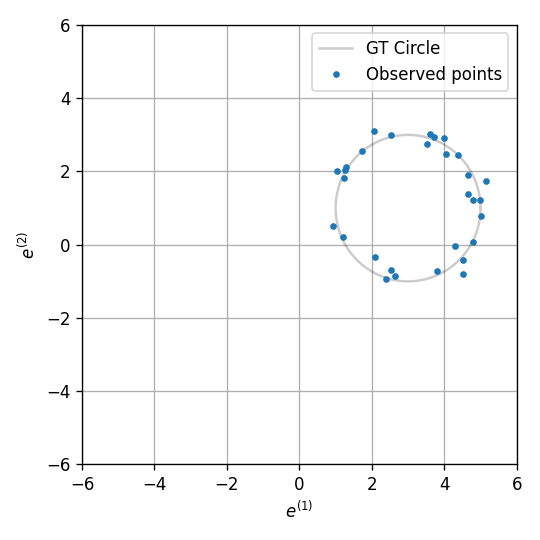
לצורך המחשה נסתכל על הדוגמא הבאה. נניח ונתונים לנו מספר מדידות של נקודות שיושבות על מעגל בעל מרכז ורדיוס לא ידועים. בנוסף נניח ותהליך המדידה עצמו רועש ואנו מקבלים גירסאות מורעשות של הנקודות כפי שמודגם בשרטוט הבא:
מקובל להשתמש בשם ground truth, או בקיצור GT, כדי להתייחס למודל המקורי (הלא ידוע).
כעת נניח ואנו מעוניינים לשחזר את הפרמטרים של המעגל המקורי על פי הדגימות שבידינו. הבעיה של התאמת בעיה כדוגמא זו, של מעגל לאוסף נקודות, מופיעה באלגוריתמי eye-tracking אשר מנסים לעקוב אחרי המיקום של האישון על מנת להבין מהו הכיוון שאליו אדם מביט.
נציין שהבעיה הזו לא מאד מייצגת ונחשבת ליחסית פשוטה בהשוואה לבעיות הטיפוסיות שאותם מנסים לפתור בתחום של מערכות לומדות , אך עם זאת היא תשמש כדוגמא טובה לעקרונות שבהם נעסוק בתרגול הנוכחי.
פערים מתמטיים
לפני שנוכל לצלול לחומר העיקרי של הקורס עלינו להתחיל בהשלמה וריענון של הבסיס המתמטי אשר ישמש אותנו לצורך ניסוח הפתרון של הבעיות בהן נעסוק בקורס. ספציפית אנו נעשה שימוש ב:
אלגברה לינארית: על מנת לתאר את המידע שהמודלים שאיתם נעבוד.
הסתברות: על מנת לתאר את האופן שבו נוצרות המדידות ובכדי לתאר את מידת הסבירות שבה מודל מסויים מתאים לתצפיות.
תורת האופטימיזציה: על מנת למצוא את המודלים אשר מתאימים באופן מיטבי לדגימות שבידינו.
בתרגול הנוכחי נתעסק בבעיות אופטימיזציה סקלריות ווקטוריות ובתרגול הבא נוסיף לכך את ההיבט ההסתברותי.
⟨x,y⟩(=x⊤y=∑ixiyi) - המכפלה הפנימית הסטנדרטית בין x ל y.
∥x∥2(=⟨x,x⟩)- הנורמה הסטנדרטית (נורמת l2) של הוקטור x.
∥x∥l(=l∑i∣xi∣l) - נורמת l של x
A - אותיות לועזיות גדולות מודגשות (bold capittal) - מטריצה
A⊤ - המטריצה Transposed A (המטריצה המשוחלפת).
Ai,j - האיבר הj שורה הi של A.
Ai,: - השורה הi של A.
A:,i - העמודה הi של A.
Sets (קבוצות)
את סדרת התצפיות אנו נסמן כקבוצה (או סדרה) בעזרת הנוטציות הבאות:
{x(1),x(2),…,x(n)} - סדרה של n וקטורים.
בעיית האופטימיזציה
נחזור לדוגמא של התאמת המעגל. דרך אחת לגשת לבעיה מסוג זה הינה לחפש מבין כל המעגלים האפשריים את המעגל אשר המרחק הריבועי הממוצע (MSE - mean squared error) של הדגימות ממנו היא המינימאלית (בהמשך הקורס אנו ניתן הצדקה מתימטית לשימוש במדד שגיאה זה). נרשום זאת באופן מתמטי.
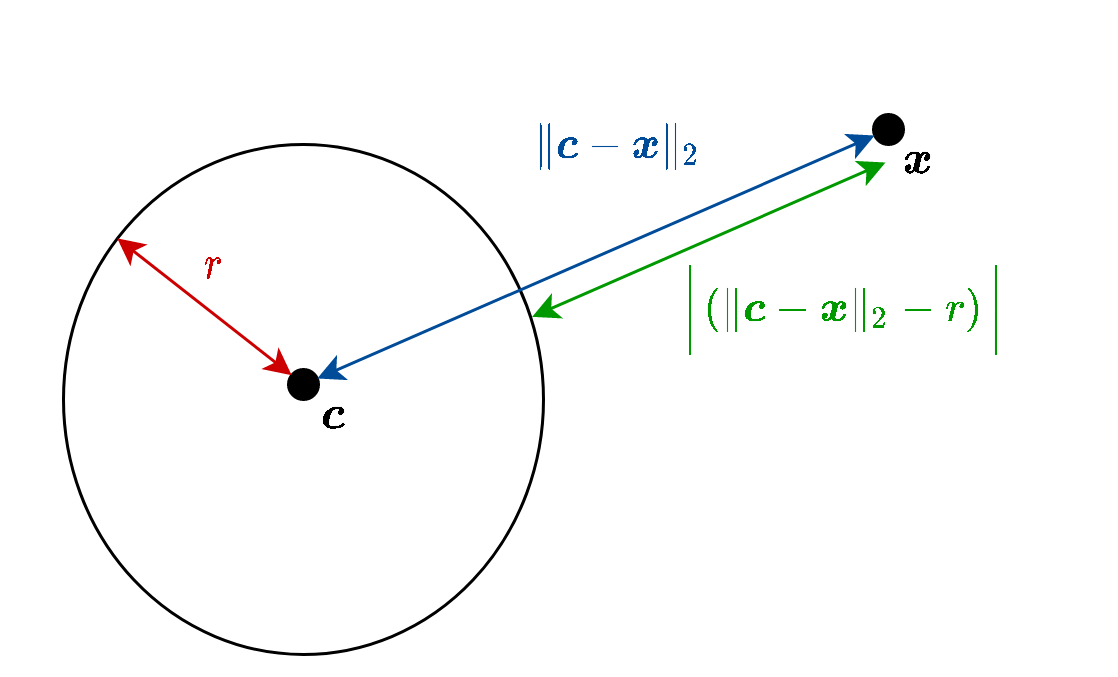
נרשום תחילה את המרחק של נקודה בודדת x ממעגל בעל מרכז ב c ורדיוס r. מרחק זה שווה להפרש בין המרחק בין x ל c והרדיוס, כפי שמופיע בשרטוט הבא:
נסמן את הריבוע של מרחק זה ב e:
e=(∥x−c∥2−r)2
אם כן בעבור n נקודות, {x(1),x(2),…,x(n)}, המרחק הריבועי הממוצע (MSE) של הנקודות מהמעגל הינו:
n1i=1∑nei=n1i=1∑n(∥x(i)−c∥2−r)2
מצאנו אם כן למעשה מדד טיב אשר מאפשר לנו לתת "ציון" לכל מעגל כתלות ב c ו r. נסמן את הפונקציה הזו כ:
f(c,r)=n1i=1∑n(∥x(i)−c∥2−r)2
כעת, אם ברצונינו למצוא את המעגל האופטימאלי, עלינו למצוא את הפרמטרים c ו r אשר מניבים את הערך הנמוך ביותר של f. מקובל לסמן את הפרמטרים האופטימאליים בעזרת ∗ באופן הבא: c∗ וr∗.
בעיות מסוג זה הן בדיוק סוגי הבעיות שתורת האופטימיזציה באה לפתור. לבינתיים נשים בצד את הפונקציה הזו ונחזור אליה לקראת סוף התרגול.
המקרה הפשוט
בעיות אופטימיזציה עוסקות במציאת הארגומנט θ שבעבורו פונקציה נתונה f(θ) מחזירה את הערך המינימאלי או המקסימאלי שלה. לרוב מקובל לנסח בעיות אופטימיזציה כבעיות minimization (מזעור), כאשר ניתן כמובן לרשום כל בעיית maximization כבעיית minimization של f~(θ)=−f(θ). כמו כן, את פונקציה f(θ) שאותה מנסים למזער (למקסם) נהוג לכנות הobjective או פונקציית המטרה. באופן פורמלי, בעיות אופטימיזציה נרשמות באופן הבא:
θ∗=θargminf(θ)
פונקציות מרובות משתנים
בעיות אופטימיזציה כמובן לא מוגבלות רק לפונקציות של משתנה יחיד וכמו בדוגמא של המעגל, ניתן להסתכל גם על הבעיה של מציאת סט הערכים האופטימאליים θ1∗,θ2∗,…,θd∗ שממזערים פונקציה של מספר משתנים f(θ1,θ2,…,θd):
במקרים רבים נוח יותר לאגד את כל הארגומנטים של f לוקטור אחד θ=[θ1,θ2,…,θd]⊤ ולרשום את בעיית האופטימזציה כ:
θ∗=θargminf(θ)
שיטות לפתרון בעיות אופטימיזציה
בעיות אופטימיזציה הם למעשה חלק מהתהליך של חקירת פונקציה אשר נלמד בחדו"א 1 ובתיכון, שם מצאנו נקודות קיצון על ידי גזירה והשוואה ל-0. שיטה זו טובה למקרים פשוטים בהם המשוואה ∇f(θ)=0 ניתנת לפתרון באופן אנליטי, אך במקרים רבים זהו אינו המצב ויש צורך להשתמש בשיטות נומריות על מנת לפתור את הבעיה.
התחום של תורת האופטימיזציה הוא רחב והוא מציע מגוון רחב של שיטות כאלה המתאימות לפונקציות מטרה שונות. בפועל בקורס זה לא נצלול לעומקו של תחום זה, ולמעשה נפתור בעיות מסוג זה בעזרת אחת משלושת השיטות הבאות:
גזירה והשוואה ל0: מתאים למקרים בהם ניתן לפתור את ∇f(θ)=0 באופן אנליטי.
Brute force (מעבר על כל האופציות): מתאים למקרים בהם הארגומנט של f לקבל רק אחד מסט ערכים סופי וקטן, לדוגמא θ∈{0,1,…,10}.
Gradient descent (שיטת הגרדיאנט): זוהי אחת משיטות האופטימיזציה הבסיסיות ביותר. בשיטה זו מחפשים מינימום לוקאלי על ידי התקדמות בכיוון ההפוך מהגרדיאנט. בתרגול זה אנחנו נדגים כיצד להשתמש בה.
בעיית אופטימזציה עם אילוצים
נשים לב שבדוגמא של התאמת המעגל, ישנו אילוץ מסויים על הפרמטרים של המעגל, רדיוס המעגל חייב להיות מספר חיובי. מגבלות מסוג זה מכונות אילוצים והם מופיעים בבעיות אופטימיזציה רבות. באופן כללי, בעיות אופטימיזציה יכולות להכיל אילוצים משני סוגים:
אילוצי אי-שוויון מהצורה g(θ)≥0.
לדוגמא, האילוץ שכל הערכים של θ יהיו קטנים מ1, יופיע בתור:
gi(θ)=1−θi≥0i=1,…,d
אילוצי שוויון מהצורה h(θ)=0.
לדוגמא האילוץ שהנורמה של θ תהיה שווה ל1, יופיע בתור:
h(θ)=∥θ∥2−1=0
אם כן הצורה הכללית ביותר של בעיית אופטימיזציה הינה:
ראשית נשים לב כי ניתן לפשט את הבעיה על ידי השימוש בעובדה שex היא פונקציה מונוטונית עולה ולכן נוכל לבצע את ההחלפה הבאה מבלי לשנות את תוצאת בעיית האופטימיזציה:
באופן דומה נוכל גם להיפתר מהתוספת של הקבוע (+34) וגם לחלק את פונקציית המטרה 3, ולקבל את בעיית האופטימיזציה הבאה:
=θ1,θ2argminθ12+θ22−6θ1−8θ2
טיפול באילוץ אי-השוויון
במקרים כגון זה, בהם מספר אילוצי אי-השוויון קטן (במקרה זה יש אילוץ בודד) נוכל לפרק כל אילוץ שוויון לשני מקרים פשוטים יותר.
המקרה בו המינימום נמצא על השפה של האילוץ (בתרגיל זה, זאת אומרת שהמינימום נמצאת ממש על מעגל היחידה). במקרה זה האילוץ הופך לאילוץ שוויון.
המקרה בו המינימום לא נמצא על השפה של האילוץ. במקרה זה נחפש נקודות מינימום לוקאליות תוך התעלמות מהאילוץ ואחר כך נבדוק מי מהן מקיימת את האילוץ (אם בכלל יש נקודה כזו).
הפתרון יהיה הפתרון הנמוך יותר מבין השניים. (כאשר יש יותר מאילוץ אי-שוויון יחיד צריך לפרק את כל אילוצי אי השוויון לשני מקרים. זאת אומרת, שכמות המקרים שיש לבדוק הינה 2 בחזקת מספר אילוצי אי-השוויון).
החיפוש בתוך מעגל היחידה
נתחיל במציאת המינימום בחלקו הפנימי של העיגול. תחילה נתעלם מהאילוץ נחפש את כל נקודות המינימום (לוקאליות או גלובליות) של הבעיה. אחר כך נפסול את אלו שלא מקיימות את האילוץ. בעיית האופטימיזציה ללא האילוץ הינה:
θ1,θ2argminθ12+θ22−6θ1−8θ2
בעיה זו ניתנת לפתרון בקלות על ידי גזירה והשוואה ול0:
נקודה זו אומנם חשודה כנקודת קיצון אך היא לא מקיימת את האילוץ ולכן היא אינה יכול להיות פתרון לבעיה. נוכל להסיק אם כן שאין נקודות מינימום בתוך המעגל ולכן נקודת המינימום תהיה חייבת להימצא על השפה.
בהמשך הקורס נלמד שיטה מסודרת לפתרון בעיות אופטימיזציה עם אילוצי שוויון כגון זו, אך לבינתיים נתאר כאן פתרון חליפי אשר משתמש בניסוח מחד של הבעיה (השיטה שמוצגת כאן לא רלוונטית להבנת החומר מופיעה פה רק לשם השלמות).
הדרך בה נימצא את המינימום על המעגל הינה על ידי החלפת הבעיה הנתונה בבעיית אופטימיזציה של משתנה יחיד ללא אילוצים. אנו נשתמש באילוץ (התנאי שהנקודה תמצא על מעגל היחידה) על מנת לבטא את θ2 בעזרת θ1 ורישום מחדש של פונקציית המטרה כפונקציה של θ1 בלבד.
מתוך האילוץ נקבל ש:
⇔1−(θ12+θ22)=0θ2=±1−θ12
כאשר עלינו לבדוק את שני המקרים כאשר θ2 חיובי (החלק העליון של מעגל היחידה) וכשאר הוא שלילי (החלק התחתון). לאחר ההחלפה נקבל את שני בעיות האופטימיזציה הבאות (המקרה החיובי והשלילי):
על ידי בדיקה של הערכים שמניבים ארבעת הנקודות האלה מוצאים כי המינימום הגלובלי של פונקציית המטרה מתקבל במקרה של (θ1,θ2)=(53,54).
סקלרים, וקטורים מטריצות ונגזרות
במהלך הקורס אנו נתקל פעמים רבות בצורך לחשב נגזרות המערבות וקטורים ומטריצות. נזכיר / נסביר בקצרה כיצד נגזרות אלו מחושבות. נתחיל במקרה המוכר של הגרדיאנט, בו אנו מבצעים גזירה של פונקציה סקלרית לפי וקטור. לאחר מכאן נראה כיצד הגדרה זו מורחבת גם למקרים נוספים בהם הפונקציה לא בהכרח סקלרית והגזירה היא לא בהכרח לפי וקטור.
בעבור פונקציה f(x) אשר מקבלת וקטור x באורך d ומחזירה סקלר, פעולת הגרדיאנט מוגדרת באופן הבא:
שימו לב שהתוצאה של הגזירה הינה מטריצה בגודל n×d. באופן כללי, הגדול תוצאת פעולת הגזירה יהיה תמיד הגודל של האובייקט שאותו גוזרים בתוספת הגודל של האיבר שלפיו אנו מבצעים את הגזירה. דוגמאות:
תוצאת הגזירה של מטריצה בגודל n×m לפי וקטור באורך d תהיה טנזור בגודל n×m×d.
תוצאת הגזירה של סקלאר לפי מטריצה בגודל n×m תהיה מטריצה בגודל n×m.
תוצאת הגזירה של מטריצה בגודל n×m לפי מטריצה בגודל o×p תהיה טנזור בגודל n×m×o×p.
למרות שחשוב להבין כיצד נגזרות אלו מודרות ומחושבות, בפועל אנחנו כמעט ולא ניתקל בצורך לחשב אותם על פי ההגדרה. במרבית המקרים, הנגזרות בהם ניתקל יבואו מתוך קבוצה מצומצמת של נגזרות מוכרות (או הרכבה שלהם עם פונקציות אחרות) ונוכל להשתמש בתוצאות מוכרות ולחסוך עבודה מיותרת. ניתן למצוא רשימה של נגזרות בדף הנוסחאות של הקורס.
כפי שציינו קודם, במקרים רבים לא נוכל פתור את בעיות האופטימיזציה על ידי גזירה והשוואה ל0 ונאלץ לעשות שימוש בשיטות נומריות. נתאר כאן בקצרה את שיטת הgradient descent (שיטת הגרדיאנט) שהיא אחת השיטות הבסיסיות ביותר אשר מנסה לפתור בעיות מסוג זה. אנו עוד נדון בהמשך הקורס בהרחבה בתכונות ובבעיות הקיימות בשיטה זו, אך בשלב זה נסתפק בלתאר את אופן פעולתה.
הרעיון מאחורי שיטה זו הינו להתחיל בנקודה אקראית כלשהי במרחב ולהתחיל לזוז בצעדים קטנים לכיוון שבו פונקציית המטרה קטנה באופן המהיר ביותר. הכיוון הזה הוא כמובן הכיוון ההפוך לגרדיאנט של הפונקציה. זהו אלגוריתם חמדן (greedy) אשר מנסה בכל צעד לשפר במעט את מצבו ביחס לשלב הקודם. אלגוריתמים מסוג זה מתכנסים לרוב למינימום לוקאלי ולא למינימום הגלובלי של הפונקציה. אלגוריתם זה רחוק מלתת מענה מושלם לבעיה, אך במקרים רבים הוא מצליח לספק פתרון סביר.
האלגוריתם
מאתחלים את θ(0) בנקודה אקראית כל שהיא
חוזרים על צעד העדכון הבא עד להתכנסות:
θ(t+1)=θ(t)−η∇θf(θ(t))
הפרמטר η אשר קובע את גודל הצעדים אשר נעשה בתהליך ההתכנסות. (את הדיון על קריטריון ההתכנסות ועל הבחירת של η נשאיר לשלב מאוחר יותר)
תרגיל 0.4 - Gradient descent for circle fitting
רישמו את צעד העדכון של אלגורתם הgradient descent בעבור המקרה של התאמת העיגול.
פתרון 0.4
על פי הנגזרת שחישבנו בתרגיל 0.3 נסיק כי צעד העדכון הוא: