הרצאה 13 - סיכום
תהליך פתרון בעיה בלמידה מונחית
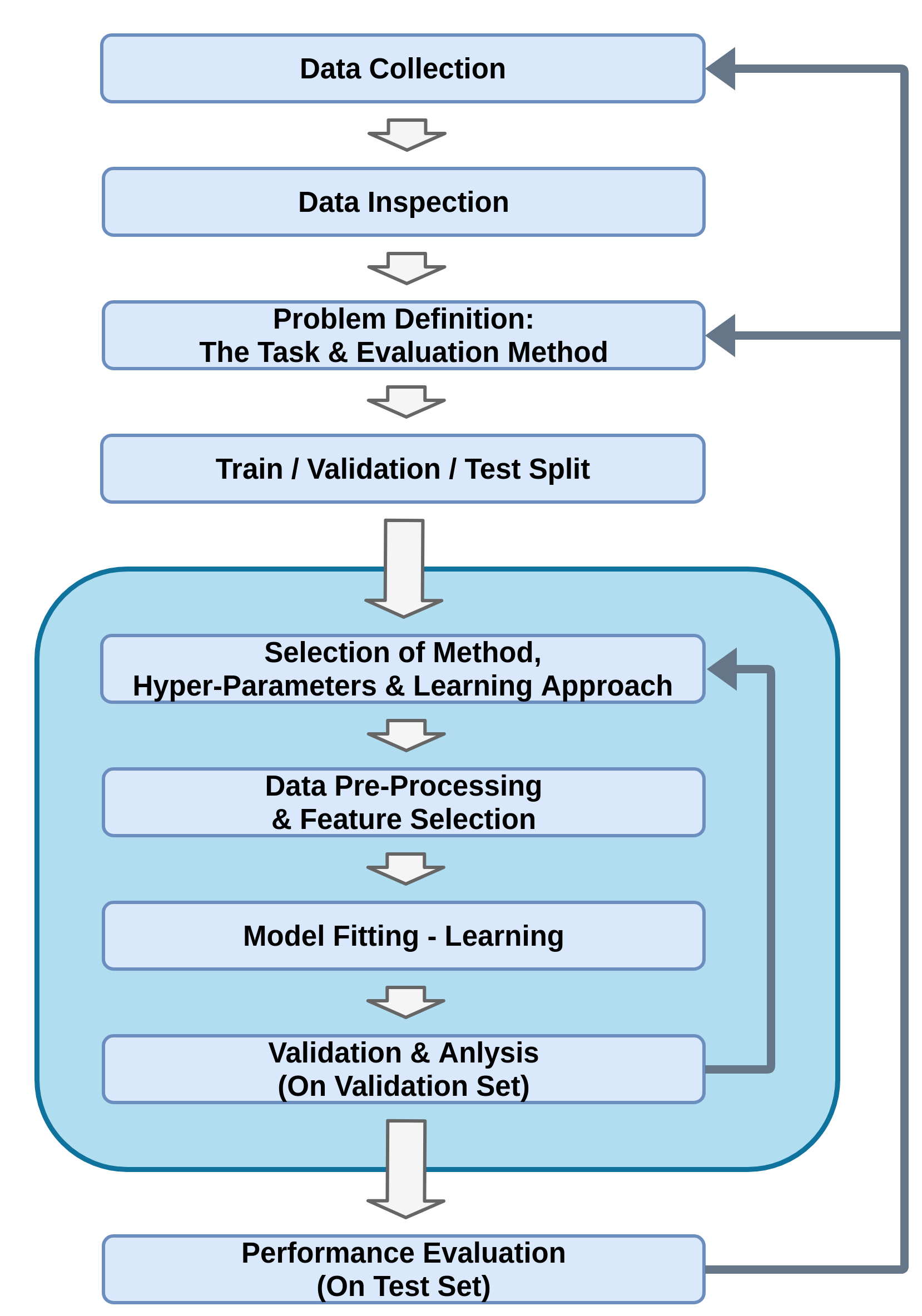
הגדרת הבעיה
ב supervised learning תמיד ננסה למצוא חזאי .
הפרדנו בין שתי מקרים:
- בעיות סיווג (classification): דיסקרטי וסופי.
- בעיות רגרסיה (regression): רציף.
קיימים מקרים בהם מספר התיוגים המותרים לכל קלט גדול מאחד. דוגמה? Multi label problem.
הערכת ביצועים
נגדיר את פונקציית המחיר (cost) שבה נרצה להשתמש בכדי להעריך את החזאי. לרוב נבחר פונקציית מחיר מהצורה:
פונקציות מסוג זה מכונות פונקציות סיכון (risk).
הפונקציה מוכנה פונקציית ההפסד (loss)
- מכיוון שהפילוג של ו לא באמת ידוע לנו אנו נשתמש ב test set ובתוחלת בכדי להעריך את הביצועים.
פונקציות הפסד (פונקציות סיכון) נפוצות
| Common For | Loss Name | Risk Name | Loss Function | Optimal Predictor |
|---|---|---|---|---|
| Classification | Zero-One Loss | Misclassification Rate | ||
| Regression | Mean Absolute Error | Median: |
||
| Regression | Mean Squared Error (MSE) |
שאלה: מתי יש מוטיבציה לפונקציית הפסד שאינה 0-1 במקרה של סיווג? דוגמה?
Discriminative vs. Generative
אנו מבחינים בין 3 גישות אשר משמשות לפתרון בעיות supervised learning:
- גישה דיסקרימינטיבית: -> .
- גישה גנרטיבית: -> -> -> .
- גישה דיסקרימינטיבית הסתברותית: -> -> .
שאלה: מתי יש יתרונות יחסיים לגישות השונות?
פירמול הבעיה
במרבית השיטות נשתמש במודל פרמטרי (לחזאי או לפילוג) ונרשום את הבעיה כבעיית אופטימיזציה על הפרמטרים של המודל:
- לרוב לא נדע לפתור את הבעיה באופן אנליטי ונשתמש בשיטות אלטרנטיביות למציאת פתרון "סביר".
- בדרך כלל משתמשים בגישות מקומיות מבוססות גרדיאנט. גישות אלה מוגבלות בגלל המקומיות של החיפוש. יש דרכים לשפרן, אך אין פתרון אוניברסלי.
Cross-Validation
למרבית השיטות יש מספר hyper-parameters שאינם חלק מבעיית האופטימיזציה שאותם יש לקבוע מראש.
הדרך הנפוצה לבחור hyper-parameters הינה על ידי שימוש ב validation set על מנת לבדוק מספר ערכים שונים ולבחור את אלו אשר נותים את הביצועים הטובים ביותר.
עיבוד מקדים (preprocessing)
במרבית המקרים אנו נרצה לבצע פעולות שונות על המדגם לפני הזנתו לאלגוריתם על מנת להקל על עבודת האלגוריתם.
דוגמאות:
- חילוץ מאפיינים שנבחרו באופן ידני: .
- הורדת מימד (על ידי שימוש באלגוריתם כגון PCA).
- נרמול:
- אוגמנטציה (לא נלמד בקורס)
התפקיד של ידע מוקדם בלמידה
- מושג טכני = inductive bias
- ידע מוקדם – כל מה שיודעים על הבעיה לפני קבלת הנתונים
- מימוש – הגבלות על מבנה מרחב ההשערות, פונקציית המחיר, אלגוריתם האופטימיזציה
- מוטיבציה – שיפור יכולת ההכללה (מניעת התאמת יתר), חסינות לרעש, האצת למידה, "פרשנות" פשוטה יותר של הפתרון
התפקיד של ידע מוקדם בלמידה
דוגמאות
- בחירת מאפיינים מושכלת
- מבנה הרשת – למשל CNN משקף מבנה של תמונות
- רגולריזציה – העדפת מודלים "פשוטים"
- העברת ידע מבעיות קודמות (transfer learning) - לא למדנו
- הרחבת הנתונים (data augmentation) - לא למדנו
היום – הרבה ידע מוקדם "מסתובב" מפתרונות טובים של בעיות קודמות וניתן להעברה למטלות חדשות. למשל, בנושאים של עיבוד תמונה, עיבוד שפה, חיזוי מבנה חלבונים ועוד הרבה
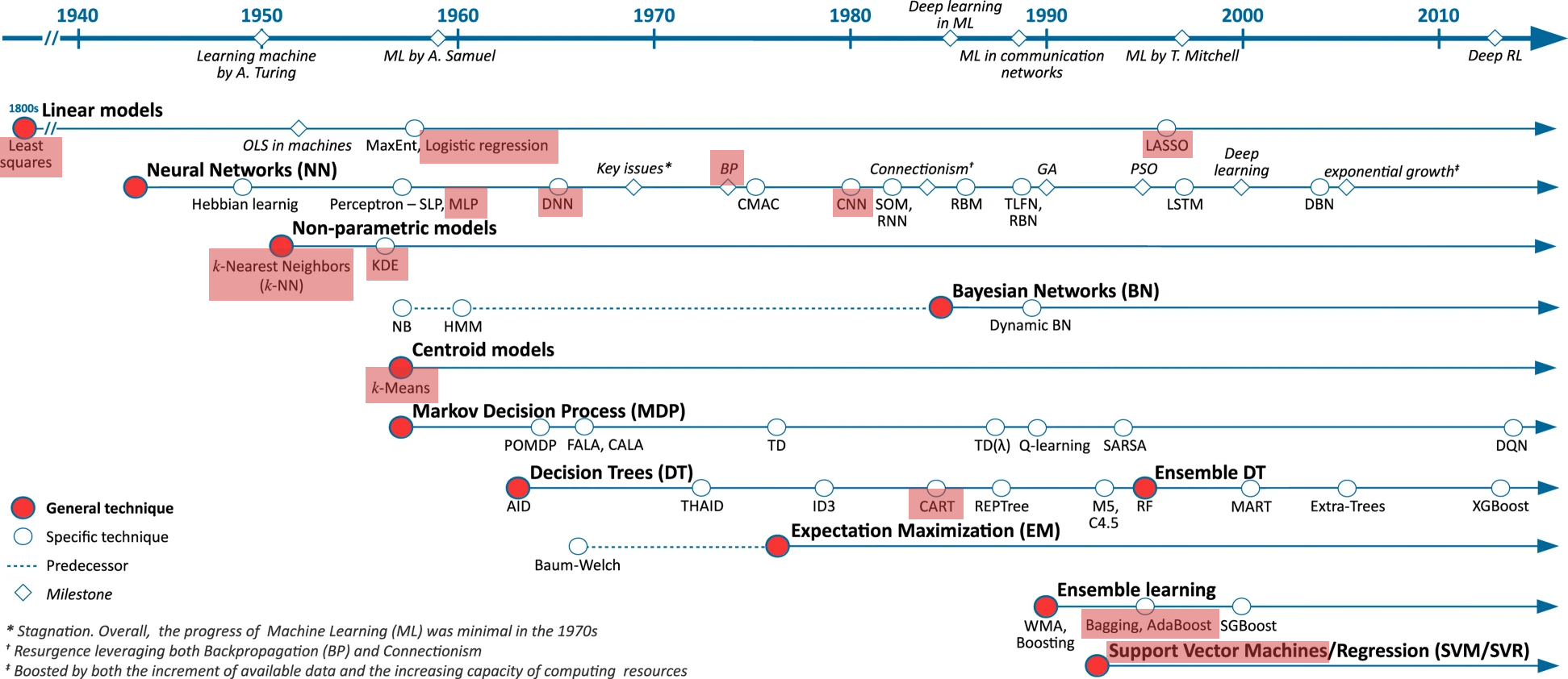
מעבר על האלגוריתמים שנלמדו בקורס
נעבור במהירות על האלגוריתמים שאותם ראינו בקורס ונבחן את המאפיינים שלהם.
Timeline
Empirical Risk Minimization
- Problem type: Regression (Classifcation)
- Approach: Discriminative
- Optimization problem:
Linear Least Squares (LLS)
(also known as ordinary least squares-OLS)
- Problem type: Regression with MSE risk
- Approach: Discriminative
- Model:
- Optimization problem:
- How to solve: Closed-form solution: .
Ridge Regression
(LLS with Tikhonov Regularization ())
- Problem type: Regression with MSE risk
- Approach: Discriminative
- Model:
- Hyper-parameter: Regularization coefficient
- Optimization:
- Question: what is the motivation for the regularization?
- How to solve: , or using Gradient Descent methods.
Least Absolute Shrinkage and Selection Operator (LASSO)
(LLS with Regularization)
- Problem type: Regression with MSE risk
- Approach: Discriminative
- Model:
- Hyper-parameter: Regularization coefficient
- Optimization:
- How to solve: Variants of gradient descent (were not presented in the course).
K-Nearest Neighbors (K-NN)
- Problem type: Classification (and also regression)
- Approach: Discriminative
- Hyper-parameter: Number of neighbors .
- Properties: Required amount of data that is exponential in the dimension. Good for low dimensions with a lot of data. Slow runtime.
-
Questions:
- What is the training process?
- What is the main difference between this method and other parametric methods we have learned?
Decision Trees
- Problem type: Classification or regression
- Approach: Discriminative
- Model: A tree with nodes that threshold a single feature.
- Hyper-parameter: Number of nodes.
-
Optimization:
- Classification: Minimize entropy or the Gini index.
- Regression: Minimize RMSE.
- How to solve: Add nodes in a greedy manner + pruning.
Decision Trees - Cont.
-
Properties:
- Very efficient runtime.
- Usually overfits but can efficiently be combined with bagging or boosting.
- Can work with categorical features.
- More interptable (without ensembles).
Hard SVM
- Problem type: Binary classification
- Approach: Discriminative
- Model:
-
Optimization:
- How to solve: Numerical convex optimization solvers.
- Property: Requires the data to be linearly seperable.
Soft SVM
- Problem type: Binary classification
- Approach: Discriminative
- Model:
- Hyper-parameter: The slack penalty term .
-
Optimization:
Soft SVM - Cont.
- How to solve: Numerical convex optimization solvers.
- Property: Can be very efficient when combined with the right kernal using the kernal-trick.
Histogram
- Approach: Generative
- Model: Piecewise constant probability function.
- Hyper-parameter: Bin edges.
- How to solve: Count relative number of samples in each bin.
-
Properties:
- Not very useful for supervised learning.
- Required amount of data is exponential in the dimension.
- Great for quick visualization.
KDE
- Approach: Generative
- Model: Linear combination of shifted kernel functions.
- Hyper-parameter: The kernel function
-
Properties:
- Required amount of data is exponential in the dimension. Good for low dimensions with a lot of data.
Linear Discriminant Analysis (LDA)
- Problem type: Classification
- Approach: Generative
- Model:
- Optimization: MLE (or MAP)
- How to solve: Has a closed-form solution.
-
Properties:
- Linear separation lines.
- Good when each class is concentrated in a different area of the feature space.
- Can deal with classes with very few examples (even 1).
Quadric Discriminant Analysis (QDA)
- Problem type: Classification
- Approach: Generative
- Model:
- Optimization: MLE (or MAP)
- How to solve: Has a closed-form solution.
-
Properties:
- Quadric separetion lines.
- Good when each class is concentrated in a different area of the feature space.
Logistic Regression
- Problem type: Classification
- Approach: Probabilistic Discriminative
- Model:
- Hyper-parameter: The functions .
- Optimization: MLE (or MAP)
- How to solve: Gradient descent.
Linear Logistic Regression
- Problem type: Classification
- Approach: Probabilistic Discriminative
- Model:
- Hyper-parameter: The matrix .
- Optimization: MLE (or MAP)
- How to solve: Gradient descent.
Multi-Layer Perceptron (MLP)
- Problem type: Either
- Approach: Probabilistic Discriminative / Discriminative
- Model: A neural network of fully connected layers.
- Hyper-parameter: The number of layers and their width + activation functions.
-
Optimization:
- Classification: MLE (or MAP)
- Regression: ERM
- How to solve: Stochastic Gradient descent (and variants) + backpropogation.
- Property: Requires large amounts of data in order to avoid overfiting.
Convolutional Neural Network (CNN)
- Problem type: Either
- Approach: Probabilistic Discriminative / Discriminative
- Model: A NN of convolutional + fully connected layers.
- Hyper-parameter: The architecture.
-
Optimization:
- Classification: MLE (or MAP)
- Regression: ERM
- How to solve: Gradient descent + backpropogation.
- Property: Very efficient when has some spatial structure (e.g. images).
Bagging and Boosting
בנוסף לכל השיטות הנ"ל ראינו גם כיצד ניתן לשלב מספר חזאים באופן הבא:
- בעזרת Bagging בכדי להקטין את ה variance (overfitting) של החזאים.
- בעזרת AdaBoost בכדי להקטין את ה bias (underfitting) של החזאים.
מה הלאה - קורסים?
קורסים נוספים בפקולטה בתחום:
- 046202 - עיבוד וניתוח מידע (unsupervised).
- 046211 - למידה עמוקה.
- 046203 - תכנון ולמידה מחיזוקים (reinforcment).
- 046746 - אלגוריתמים ויישומים בראיה ממוחשבת.
- 046853 - .ארכיטקטורות מחשבים מתקדמות
מה הלאה - Deep learning?
הכרת טכניקות ספציפיות ברשתות נוירונים (ארכיטקטורות, אופטימיזציות, רגולריזציה וכו'):
- מאד דינמי ומשתנה בקצב גבוה.
- משתנה מבעיה לבעיה.
- הכי טוב זה לקחת בעיה ולראות מה השיטות בהם משתמשים כיום בכדי לפתור אותה.
- Google is your friend ...
מה הלאה - צבירת נסיון?
התחום של מערכות לומדות דורש המון נסיון ואינטואיציה שנרכשים עם הזמן.
- פרוייקט בתחום.
- Kaggle.
חברי סגל בתחום
- אביב תמר
- איילת טל
- גיא גלבוע
- דניאל סודרי
- יואב שכנר
- יניב רומנו
- כפיר לוי
- ליהי צלניק-מנור
- נחום שימקין
- ענת לוין
- רון מאיר
- שי מנור
- תומר מיכאלי