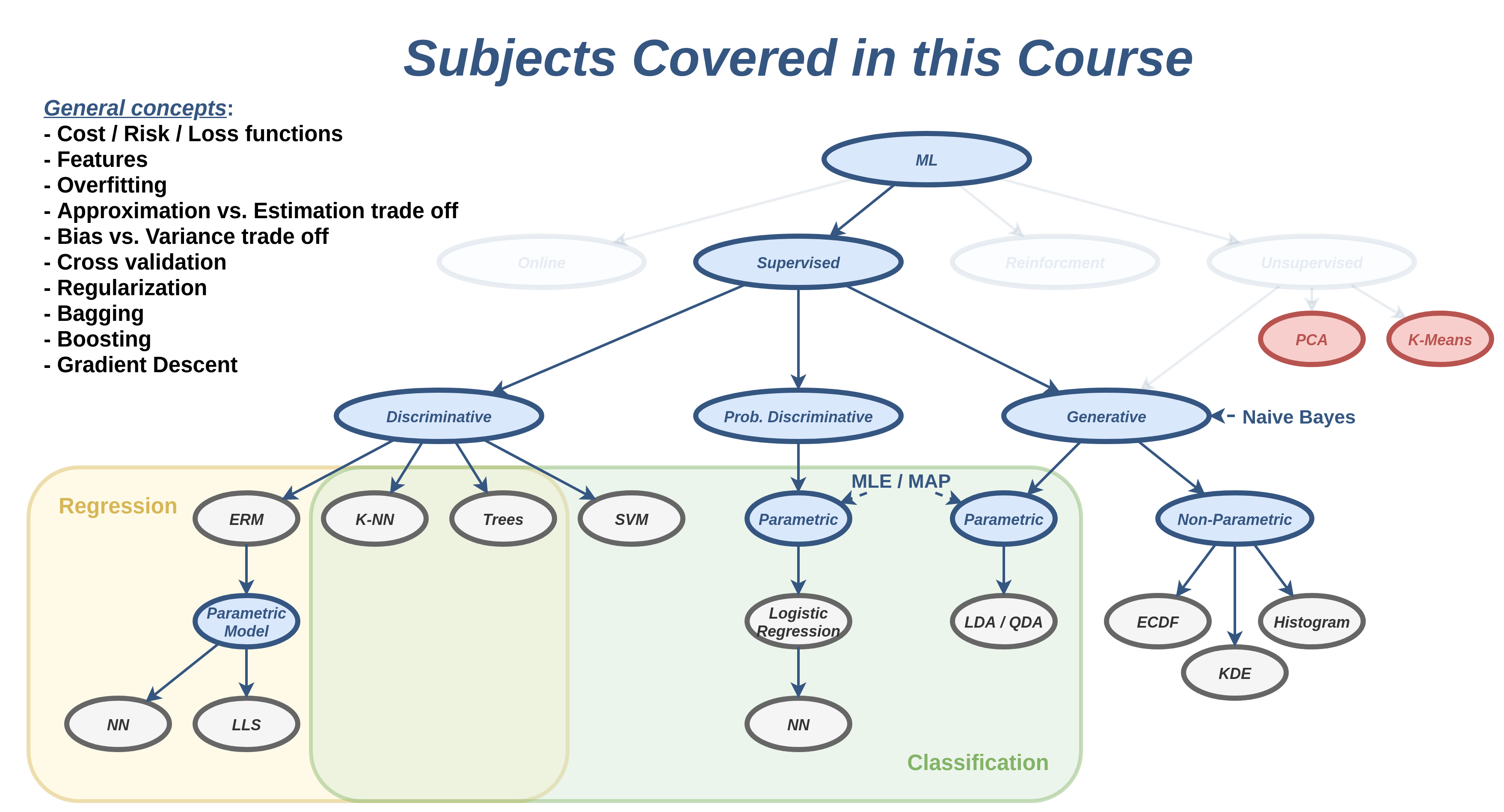
הרצאה 12 - PCA and K-Means
למידה לא מודרכת (Unsupervised Learning)
שם כולל למגוון של בעיות בהם אנו מנסים בהינתן מדגם, ללמוד את התכונות של הדגימות או של המדגם כולו.
המדגם יכיל אוסף של דגימות (x \boldsymbol{x} x y y y
דוגמאות:
אשכול (חלוקה לקבוצות).
מציאת ייצוג "נוח" יותר של הדגימות.
דחיסה.
זיהוי אנומליות.
למידת הפילוג של הדגימות.
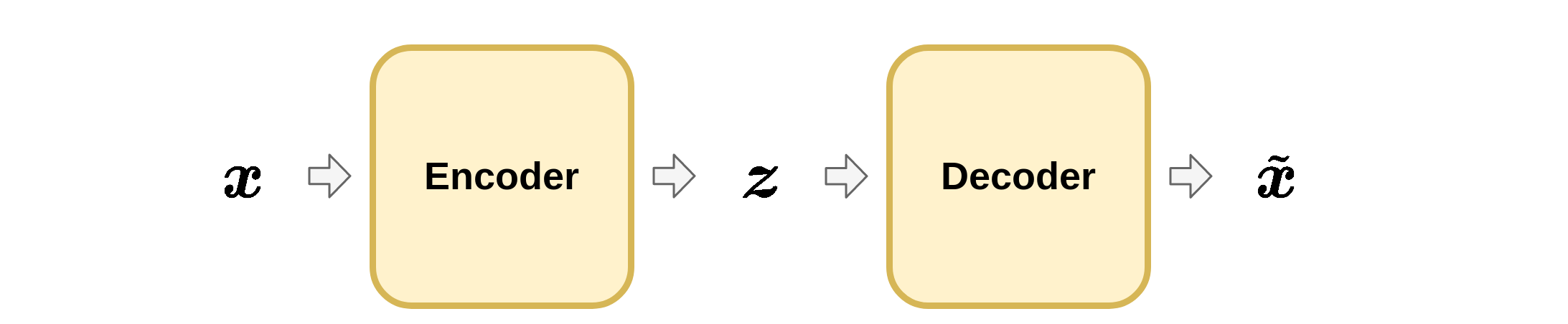
מערכת Encoder-Decoder
דוגמאות לשימושים במערכת encoder-decoder הינם:
דחיסה: נרצה ש z \boldsymbol{z} z
תקשורת: נרצה ש z \boldsymbol{z} z
הצפנה: נרצה שפעולת השחזור של x \boldsymbol{x} x
x ~ \tilde{\boldsymbol{x}} x ~ x \boldsymbol{x} x x ~ = x \tilde{\boldsymbol{x}}=\boldsymbol{x} x ~ = x
Principle Component Analysis (PCA)
ב PCA ננסה לבנות מערכת encoder-decoder שבה:
אנו מגבילים את האורך של הוקטור z \boldsymbol{z} z
אנו דורשים שה encoder וה decoder יהיו פונקציות אפיניות (affine = linear + offset).
התוחלת של שגיאת השחזור הריבועית E [ ∥ x ~ − x ∥ 2 2 ] \mathbb{E}\left[\lVert\tilde{\mathbf{x}}-\mathbf{x}\rVert_2^2\right] E [ ∥ x ~ − x ∥ 2 2 ]
נחליף את התוחלת בתוחלת אמפירית על מדגם.
Principle Component Analysis (PCA)
D D D x \boldsymbol{x} x K K K z \boldsymbol{z} z K ≤ D K \le D K ≤ D
נרצה למצוא encoder:
z = T 1 x + b 1 \boldsymbol{z}=T_1\boldsymbol{x}+\boldsymbol{b}_1 z = T 1 x + b 1 ו decoder מהצורה של:
x ~ = T 2 z + b 2 \tilde{\boldsymbol{x}}=T_2\boldsymbol{z}+\boldsymbol{b}_2 x ~ = T 2 z + b 2 אשר ממזערים את התוחלת האמפירית של שגיאת השחזור הריבועית:
arg min T 1 , T 2 , b 1 , b 2 1 N ∑ i = 1 N ∥ x ~ ( i ) − x ( i ) ∥ 2 2 \underset{T_1,T_2,\boldsymbol{b}_1,\boldsymbol{b}_2}{\arg\min}
\frac{1}{N}\sum_{i=1}^N\lVert\tilde{\boldsymbol{x}}^{(i)}-\boldsymbol{x}^{(i)}\rVert_2^2 T 1 , T 2 , b 1 , b 2 arg min N 1 i = 1 ∑ N ∥ x ~ ( i ) − x ( i ) ∥ 2 2
שימושים
דוגמאות למקרים שבהם נרצה לבצע הורדת מימד (dimensionality reduction) :
בחירת מאפיינים לבעיות supervised learning
ויזואליזציה
דחיסה
הפתרון לבעיית האופטימיזציה
מסתבר שיש מספר רב של פתרונות. ניתן לבחור את הפרמטרים כך שיקיימו את האילוצים:
b 1 = − T 1 μ b 2 = μ T 1 = T 2 ⊤ = T ⊤ T ⊤ T = I \begin{aligned}
\boldsymbol{b}_1&=-T_1\boldsymbol{\mu}\\
\boldsymbol{b}_2&=\boldsymbol{\mu}\\
T_1&=T_2^{\top}=T^{\top}\\
T^{\top}T&=I
\end{aligned} b 1 b 2 T 1 T ⊤ T = − T 1 μ = μ = T 2 ⊤ = T ⊤ = I כאשר μ = 1 N ∑ i = 1 N x ( i ) \boldsymbol{\mu}=\frac{1}{N}\sum_{i=1}^N\boldsymbol{x}^{(i)} μ = N 1 ∑ i = 1 N x ( i )
הערה: שימו לב ש-T ∈ R D × K T\in\mathbb{R}^{D\times K} T ∈ R D × K T ⊤ T ∈ R K × K = I K T^\top T \in \mathbb{R}^{K\times K}=I_K T ⊤ T ∈ R K × K = I K I K I_K I K T T ⊤ ∈ R D × D T T^\top \in \mathbb{R}^{D\times D} T T ⊤ ∈ R D × D I D I_D I D
הפתרון לבעיית האופטימיזציה
לדוגמה, עבור המיפוי הבא
z = T 1 x + b 1 x ~ = T 2 z + b 2 T 1 ∈ R K × D , T 2 ∈ R D × K \boldsymbol{z}=T_{1}\boldsymbol{x}+\boldsymbol{b}_{1}\quad\tilde{\boldsymbol{x}}=T_{2}z+\boldsymbol{b}_{2}\quad T_{1}\in\mathbb{R}^{K\times D},\,T_{2}\in\mathbb{R}^{D\times K} z = T 1 x + b 1 x ~ = T 2 z + b 2 T 1 ∈ R K × D , T 2 ∈ R D × K איברי ההטיה b 1 \boldsymbol{b}_1 b 1 b 2 \boldsymbol{b}_2 b 2
E [ z ] = 0 ⇒ b 1 = − T 1 μ E[\boldsymbol{z}]=0\quad\Rightarrow\quad b_{1}=-T_{1}\boldsymbol{\mu} E [ z ] = 0 ⇒ b 1 = − T 1 μ ו-
E [ x ~ ] = E [ x ] ⇒ b 2 = E [ x ] = μ E\left[\tilde{\boldsymbol{x}}\right]=E\left[\boldsymbol{x}\right]\quad\Rightarrow\quad b_{2}=E\left[x\right]=\boldsymbol{\mu} E [ x ~ ] = E [ x ] ⇒ b 2 = E [ x ] = μ
הפתרון לבעיית האופטימיזציה
הטרנספורמציות במקרה זה הופכות להיות:
z = T ⊤ ( x − μ ) x ~ = T z + μ \begin{aligned}
\boldsymbol{z}&=T^{\top}(\boldsymbol{x}-\boldsymbol{\mu})\\
\tilde{\boldsymbol{x}}&=T\boldsymbol{z}+\boldsymbol{\mu}
\end{aligned} z x ~ = T ⊤ ( x − μ ) = T z + μ ובעיית האופטימיזציה הינה:
T ∗ = arg min T 1 N ∑ i = 1 N ∥ x ~ ( i ) − x ( i ) ∥ 2 2 s.t. T ⊤ T = I T ∗ = arg min T 1 N ∑ i = 1 N ∥ ( T T ⊤ − I ) ( x ( i ) − μ ) ∥ 2 2 s.t. T ⊤ T = I \begin{aligned}
T^*=\underset{T}{\arg\min}\quad&\frac{1}{N}\sum_{i=1}^N\lVert\tilde{\boldsymbol{x}}^{(i)}-\boldsymbol{x}^{(i)}\rVert_2^2\\
\text{s.t.}\quad& T^{\top}T=I\\
T^*=\underset{T}{\arg\min}\quad&\frac{1}{N}\sum_{i=1}^N\lVert(TT^{\top}-I)(\boldsymbol{x}^{(i)}-\boldsymbol{\mu})\rVert_2^2\\
\text{s.t.}\quad& T^{\top}T=I
\end{aligned} T ∗ = T arg min s.t. T ∗ = T arg min s.t. N 1 i = 1 ∑ N ∥ x ~ ( i ) − x ( i ) ∥ 2 2 T ⊤ T = I N 1 i = 1 ∑ N ∥ ( T T ⊤ − I ) ( x ( i ) − μ ) ∥ 2 2 T ⊤ T = I
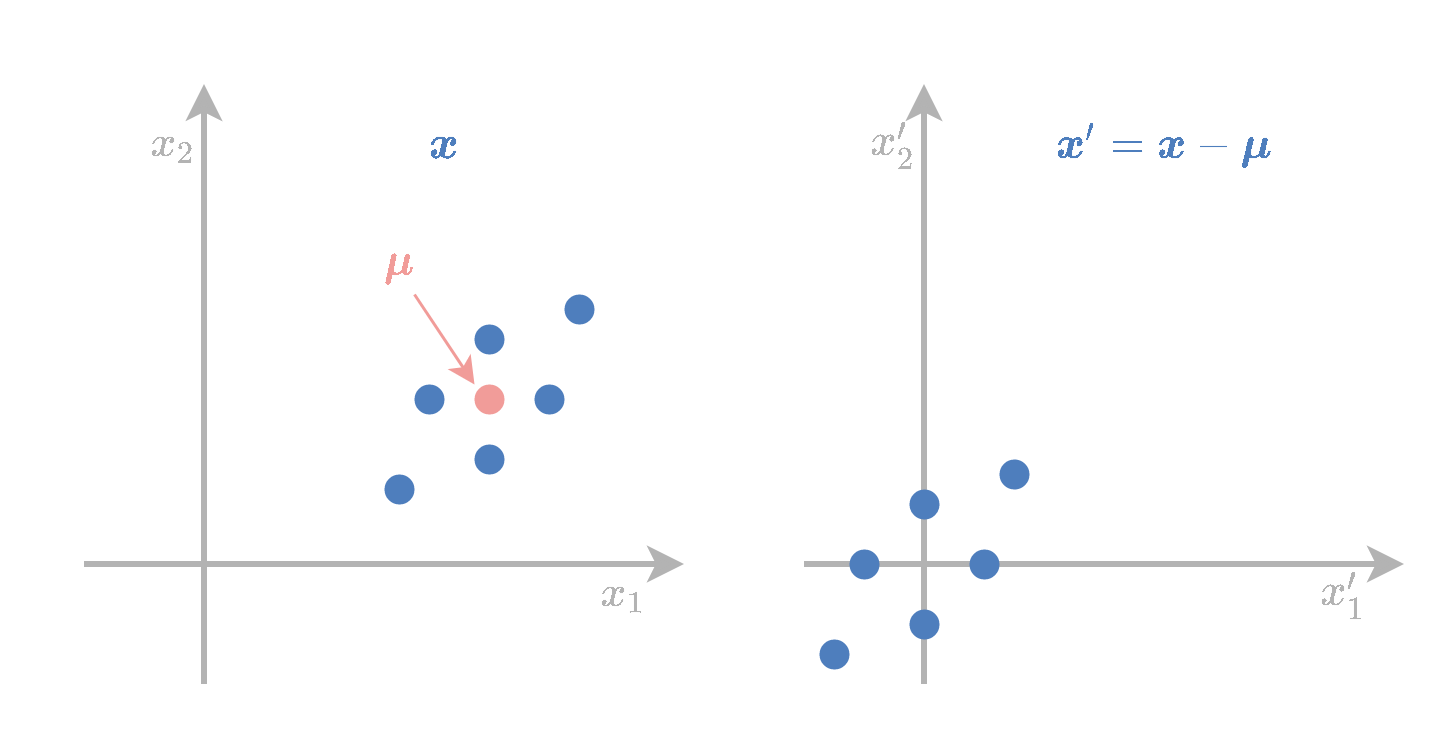
פרשנות גיאומטרית
ה encoder מחסר את הממוצע של x \boldsymbol{x} x
נניח מעתה שהנתונים ממורכזים סביב האפס.
הפתרון לבעיית האופטימיזציה
הטרנספורמציות המתקבלות הינן:
z = T ⊤ x x ~ = T z = T T ⊤ x \begin{aligned}
\boldsymbol{z}&=T^{\top}\boldsymbol{x}\\
\tilde{\boldsymbol{x}}&=T\boldsymbol{z}=TT^{\top}\boldsymbol{x}
\end{aligned} z x ~ = T ⊤ x = T z = T T ⊤ x נתייחס כעת לאילוץ של T ⊤ T = I T^{\top}T=I T ⊤ T = I T T T
נסמן את העמודות של T T T u j \boldsymbol{u}_j u j
T = ( ∣ ∣ ∣ u 1 u 2 … u K ∣ ∣ ∣ ) T=\begin{pmatrix}
| & | & & | \\
\boldsymbol{u}_1 & \boldsymbol{u}_2 & \dots & \boldsymbol{u}_K \\
| & | & & |
\end{pmatrix} T = ⎝ ⎛ ∣ u 1 ∣ ∣ u 2 ∣ … ∣ u K ∣ ⎠ ⎞
פרשנות גיאומטרית
הפעולה של x ~ = T T ⊤ x \tilde{\boldsymbol{x}}=TT^{\top}\boldsymbol{x} x ~ = T T ⊤ x x \boldsymbol{x} x u j \boldsymbol{u}_j u j
פרשנות גיאומטרית
הפעולה של z = T ⊤ x \boldsymbol{z}=T^{\top}\boldsymbol{x} z = T ⊤ x x \boldsymbol{x} x u j \boldsymbol{u}_j u j
פרשנות גיאומטרית
נסתכל כעת על המשמעות הגיאומטרית של שגיאת השחזור
∥ x ~ − x ∥ 2 2 \lVert\tilde{\boldsymbol{x}}-\boldsymbol{x}\rVert_2^2 ∥ x ~ − x ∥ 2 2 בעיית האופטימיזציה היא הבעיה של מציאת תת-המרחב ממימד K K K
הבעיה השקולה
מתוך העובדה ש T ⊤ T = I T^{\top}T=I T ⊤ T = I
∥ x ~ − x ∥ 2 2 = ∥ x ∥ 2 2 − ∥ x ~ ∥ 2 2 = ∥ x ∥ 2 2 − ∥ z ∥ 2 2 \lVert\tilde{\boldsymbol{x}}-\boldsymbol{x}\rVert_2^2
=\lVert\boldsymbol{x}\rVert_2^2-\lVert\tilde{\boldsymbol{x}}\rVert_2^2
=\lVert\boldsymbol{x}\rVert_2^2-\lVert\boldsymbol{z}\rVert_2^2 ∥ x ~ − x ∥ 2 2 = ∥ x ∥ 2 2 − ∥ x ~ ∥ 2 2 = ∥ x ∥ 2 2 − ∥ z ∥ 2 2 שכן, עבור T ⊤ T = I T^{\top}T=I T ⊤ T = I ( I − T T ⊤ ) 2 = ( I − T T ⊤ ) \left(I-TT^{\top}\right)^{2}=\left(I-TT^{\top}\right) ( I − T T ⊤ ) 2 = ( I − T T ⊤ )
∥ x − x ~ ∥ 2 2 = ∥ x − T T ⊤ x ∥ 2 2 = ∥ ( I − T T ⊤ ) x ∥ 2 2 = x ⊤ ( I − T T ⊤ ) x = ∥ x ∥ 2 2 − ∥ z ∥ 2 2 \begin{aligned}
\left\Vert \boldsymbol{x}-\tilde{\boldsymbol{x}}\right\Vert _{2}^{2} & =\left\Vert \boldsymbol{x}-TT^{\top}x\right\Vert _{2}^{2}\\
& =\left\Vert \left(I-TT^{\top}\right)x\right\Vert _{2}^{2}\\
& =\boldsymbol{x}^{\top}\left(I-TT^{\top}\right)\boldsymbol{x}\\
& =\left\Vert \boldsymbol{x}\right\Vert _{2}^{2}-\left\Vert \boldsymbol{z}\right\Vert _{2}^{2}
\end{aligned} ∥ x − x ~ ∥ 2 2 = ∥ ∥ ∥ x − T T ⊤ x ∥ ∥ ∥ 2 2 = ∥ ∥ ∥ ( I − T T ⊤ ) x ∥ ∥ ∥ 2 2 = x ⊤ ( I − T T ⊤ ) x = ∥ x ∥ 2 2 − ∥ z ∥ 2 2 ובנוסף
∥ x ~ ∥ 2 2 = ∥ T z ∥ 2 2 = z ⊤ T ⊤ T z = ∥ z ∥ 2 2 \left\Vert \tilde{\boldsymbol{x}}\right\Vert _{2}^{2}=\left\Vert T\boldsymbol{z}\right\Vert _{2}^{2}=\boldsymbol{z}^{\top}T^{\top}T\boldsymbol{z}=\left\Vert \boldsymbol{z}\right\Vert _{2}^{2} ∥ x ~ ∥ 2 2 = ∥ T z ∥ 2 2 = z ⊤ T ⊤ T z = ∥ z ∥ 2 2
הבעיה השקולה
מכאן שנוכל לרשום את בעיית האופטימיזציה באופן הבא:
T ∗ = arg min T 1 N ∑ i = 1 N ( ∥ x ( i ) ∥ 2 2 − ∥ z ( i ) ∥ 2 2 ) s.t. T ⊤ T = I \begin{aligned}
T^*=\underset{T}{\arg\min}\quad&\frac{1}{N}\sum_{i=1}^N\left( \lVert\boldsymbol{x}^{(i)}\rVert_2^2
-\lVert\boldsymbol{z}^{(i)}\rVert_2^2
\right)\\
\text{s.t.}\quad& T^{\top}T=I
\end{aligned} T ∗ = T arg min s.t. N 1 i = 1 ∑ N ( ∥ x ( i ) ∥ 2 2 − ∥ z ( i ) ∥ 2 2 ) T ⊤ T = I נזכור ש ∥ x ∥ 2 2 \lVert\boldsymbol{x}\rVert_2^2 ∥ x ∥ 2 2 T T T
T ∗ = arg min T − 1 N ∑ i = 1 N ∥ z ( i ) ∥ 2 2 s.t. T ⊤ T = I \begin{aligned}
T^*=\underset{T}{\arg\min}\quad&-\frac{1}{N}\sum_{i=1}^N\lVert\boldsymbol{z}^{(i)}\rVert_2^2\\
\text{s.t.}\quad& T^{\top}T=I
\end{aligned} T ∗ = T arg min s.t. − N 1 i = 1 ∑ N ∥ z ( i ) ∥ 2 2 T ⊤ T = I
הבעיה השקולה
T ∗ = arg min T − 1 N ∑ i = 1 N ∥ z ( i ) ∥ 2 2 s.t. T ⊤ T = I \begin{aligned}
T^*=\underset{T}{\arg\min}\quad&-\frac{1}{N}\sum_{i=1}^N\lVert\boldsymbol{z}^{(i)}\rVert_2^2\\
\text{s.t.}\quad& T^{\top}T=I
\end{aligned} T ∗ = T arg min s.t. − N 1 i = 1 ∑ N ∥ z ( i ) ∥ 2 2 T ⊤ T = I הבעיה של מזעור שגיאת השחזור הריבועית שקולה לבעיה של מקסום הגודל ∑ i = 1 N ∥ z ( i ) ∥ 2 2 \sum_{i=1}^N\lVert\boldsymbol{z}^{(i)}\rVert_2^2 ∑ i = 1 N ∥ z ( i ) ∥ 2 2
גדול זה מכונה ה variance של אוסף הוקטורים { z ( i ) } i = 1 N \{\boldsymbol{z}^{(i)}\}_{i=1}^N { z ( i ) } i = 1 N
הפתרון
נגדיר:
X = ( − x ′ ( 1 ) − − x ′ ( 2 ) − ⋮ − x ′ ( N ) − ) = ( − ( x ( 1 ) − μ ) ⊤ − − ( x ( 2 ) − μ ) ⊤ − ⋮ − ( x ( N ) − μ ) ⊤ − ) X
=\begin{pmatrix}
- & \boldsymbol{x}'^{(1)} & -\\
- & \boldsymbol{x}'^{(2)} & -\\
& \vdots & \\
- & \boldsymbol{x}'^{(N)} & -\\
\end{pmatrix}
=\begin{pmatrix}
- & (\boldsymbol{x}^{(1)}-\boldsymbol{\mu})^{\top} & -\\
- & (\boldsymbol{x}^{(2)}-\boldsymbol{\mu})^{\top} & -\\
& \vdots & \\
- & (\boldsymbol{x}^{(N)}-\boldsymbol{\mu})^{\top} & -\\
\end{pmatrix} X = ⎝ ⎜ ⎜ ⎜ ⎜ ⎛ − − − x ′ ( 1 ) x ′ ( 2 ) ⋮ x ′ ( N ) − − − ⎠ ⎟ ⎟ ⎟ ⎟ ⎞ = ⎝ ⎜ ⎜ ⎜ ⎜ ⎛ − − − ( x ( 1 ) − μ ) ⊤ ( x ( 2 ) − μ ) ⊤ ⋮ ( x ( N ) − μ ) ⊤ − − − ⎠ ⎟ ⎟ ⎟ ⎟ ⎞ ומטריצת ה covariance האמפירית של x \mathbf{x} x
P = X ⊤ X P=X^{\top}X P = X ⊤ X
הפתרון
P = X ⊤ X P=X^{\top}X P = X ⊤ X P P P
P = U Λ U ⊤ P=U\Lambda U^{\top} P = U Λ U ⊤ כאשר U U U
U = ( ∣ ∣ ∣ u 1 u 2 … u D ∣ ∣ ∣ ) U=\begin{pmatrix}
| & | & & | \\
\boldsymbol{u}_1 & \boldsymbol{u}_2 & \dots & \boldsymbol{u}_D \\
| & | & & |
\end{pmatrix} U = ⎝ ⎛ ∣ u 1 ∣ ∣ u 2 ∣ … ∣ u D ∣ ⎠ ⎞ ו Λ \Lambda Λ
Λ = ( λ 1 0 … 0 0 λ 2 0 ⋮ ⋱ ⋮ 0 0 … λ D ) \Lambda=\begin{pmatrix}
\lambda_1 & 0 & \dots & 0 \\
0 & \lambda_2 & & 0 \\
\vdots & & \ddots & \vdots \\
0 & 0 & \dots & \lambda_D \\
\end{pmatrix} Λ = ⎝ ⎜ ⎜ ⎜ ⎜ ⎛ λ 1 0 ⋮ 0 0 λ 2 0 … ⋱ … 0 0 ⋮ λ D ⎠ ⎟ ⎟ ⎟ ⎟ ⎞
הפתרון
T T T K K K U U U
T = ( ∣ ∣ ∣ u 1 u 2 … u K ∣ ∣ ∣ ) T=\begin{pmatrix}
| & | & & | \\
\boldsymbol{u}_1 & \boldsymbol{u}_2 & \dots & \boldsymbol{u}_K \\
| & | & & |
\end{pmatrix} T = ⎝ ⎛ ∣ u 1 ∣ ∣ u 2 ∣ … ∣ u K ∣ ⎠ ⎞
הכיוונים u ( j ) \boldsymbol{u}^{(j)} u ( j ) כיוונים העיקריים
הרכיבים של הוקטור z \boldsymbol{z} z רכיבים העיקריים (principal components) .
דוגמא
פירוק תמונות של פנים לכיוונים העיקריים:
דוגמא
תמונה המשוחזרת עבור ערכים שונים של K K K
הרחבות לא לינאריות
קיימות הרחבות לא לינאריות רבות ל-PCA. נידונות בקורס עיבוד וניתוח מידע (ענ"ם).
הפעלת אלגוריתם tSNE על MNIST.
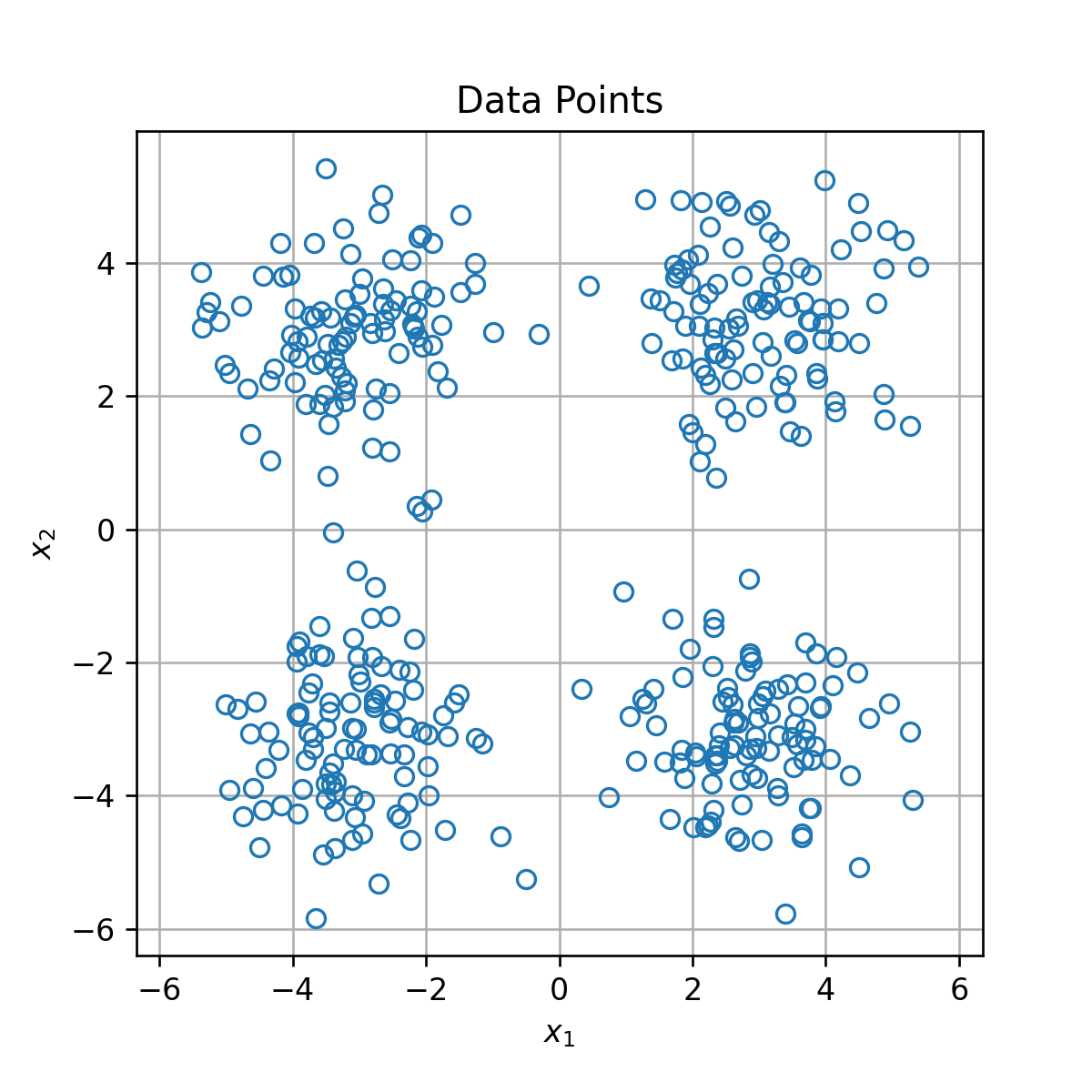
אשכול
באלגוריתמי אשכול ננסה לחלק אוסף של פרטים לקבוצות המכונים אשכולות (clusters), כאשר לכל קבוצה איזשהן תכונות דומות. כמובן, בממדים גבוהים לא רואים זאת בעין.
אשכול
2 דוגמאות למקרים שבהם נרצה לאשכל:
על מנת לבצע הנחות על אחד מהפרטים באשכול על סמך פרטים אחרים באשכול.
לתת טיפול שונה לכל אשכול.
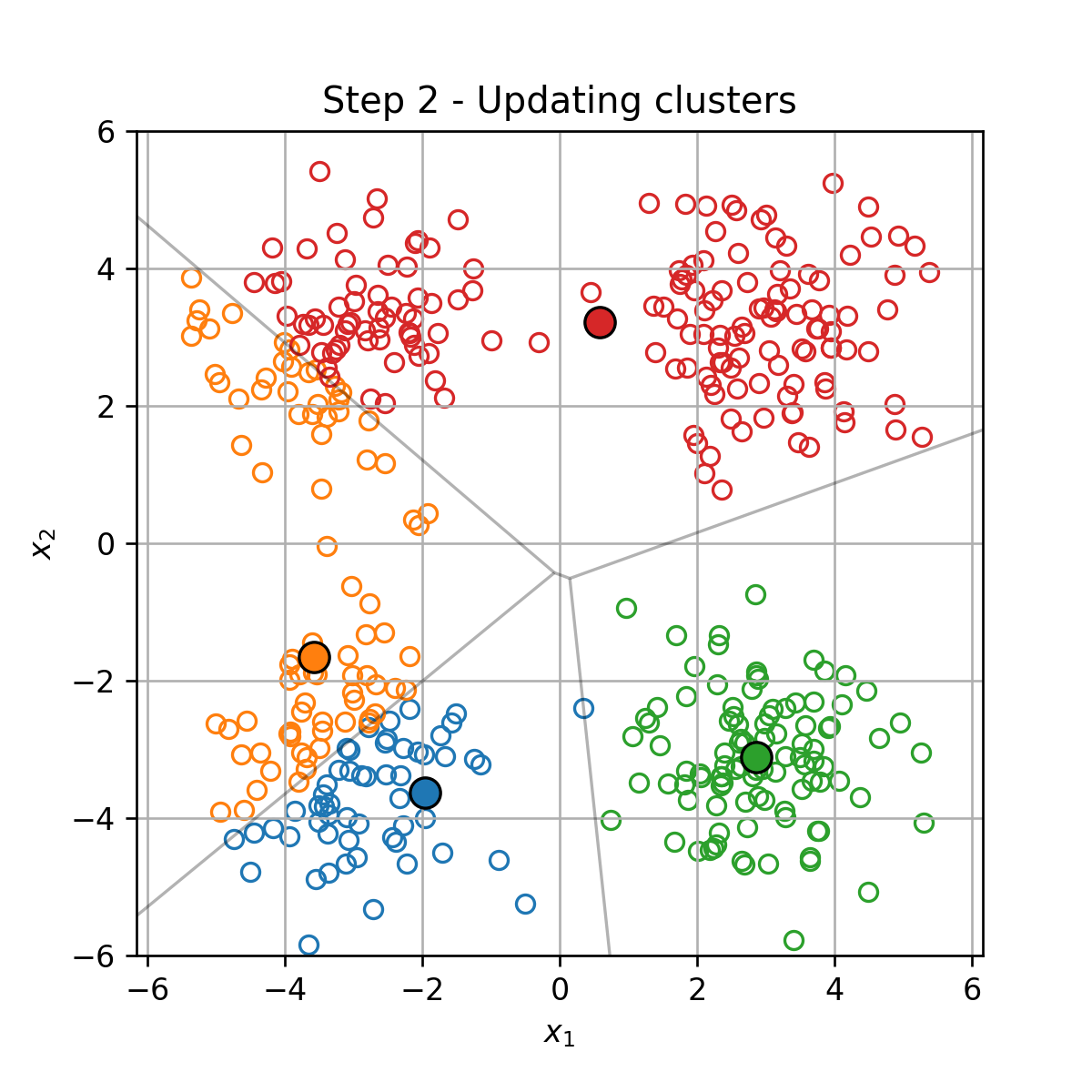
K-Means
K-Means הוא אלגוריתם אשכול אשר מנסה לחלק את הדגימות במדגם ל K K K
סימונים
K K K I k \mathcal{I}_k I k k k k I 5 = { 3 , 6 , 9 , 13 } \mathcal{I}_5=\left\lbrace3, 6, 9, 13\right\rbrace I 5 = { 3 , 6 , 9 , 1 3 } ∣ I k ∣ |\mathcal{I}_k| ∣ I k ∣ k k k { I k } k = 1 K \{\mathcal{I}_k\}_{k=1}^K { I k } k = 1 K
בעיית האופטימיזציה
K-Means מנסה למצוא את החלוקה לאשכולות אשר תמזער את המרחק הריבועי הממוצע בין כל דגימה לכל שאר הדגימות שאיתו באותו האשכול:
arg min { I j } k = 1 K 1 N ∑ k = 1 K 1 2 ∣ I k ∣ ∑ i , j ∈ I k ∥ x ( j ) − x ( i ) ∥ 2 2 \underset{\{\mathcal{I}_j\}_{k=1}^K}{\arg\min}\frac{1}{N}\sum_{k=1}^K\frac{1}{2|\mathcal{I}_k|}\sum_{i,j\in\mathcal{I}_k}\lVert\boldsymbol{x}^{(j)}-\boldsymbol{x}^{(i)}\rVert_2^2 { I j } k = 1 K arg min N 1 k = 1 ∑ K 2 ∣ I k ∣ 1 i , j ∈ I k ∑ ∥ x ( j ) − x ( i ) ∥ 2 2 שאלה: האם פונקציית מרחק ריבועית תמיד מתאימה?
הבעיה השקולה
נגדיר את מרכז המסה:
μ k = 1 ∣ I k ∣ ∑ i ∈ I k x ( i ) \boldsymbol{\mu}_k=\frac{1}{|\mathcal{I}_k|}\sum_{i\in\mathcal{I}_k}\boldsymbol{x}^{(i)} μ k = ∣ I k ∣ 1 i ∈ I k ∑ x ( i ) ניתן להראות כי בעיית האופטימיזציה המקורית, שקולה לבעיה של מיזעור המרחק הממוצע של הדגימות ממרכז המסה של האשכול:
arg min { I j } k = 1 K 1 N ∑ k = 1 K ∑ i ∈ I k ∥ x ( i ) − μ k ∥ 2 2 \underset{\{\mathcal{I}_j\}_{k=1}^K}{\arg\min}\frac{1}{N}\sum_{k=1}^K\sum_{i\in\mathcal{I}_k}\lVert\boldsymbol{x}^{(i)}-\boldsymbol{\mu}_k\rVert_2^2 { I j } k = 1 K arg min N 1 k = 1 ∑ K i ∈ I k ∑ ∥ x ( i ) − μ k ∥ 2 2
הבעיה השקולה
∑ i , j ∈ I k K ∥ x ( i ) − x ( j ) ∥ 2 2 = ∑ i , j ∈ I k ∥ x ( i ) − μ k + μ k − x ( j ) ∥ 2 2 = ∑ i , j ∈ I k ∥ x ( i ) − μ k ∥ 2 2 + ∑ i , j ∈ I k ∥ x ( j ) − μ k ∥ 2 2 − 2 ∑ i , j ∈ I k ( x ( i ) − μ k ) ⊤ ( x ( j ) − μ k ) = 2 ∣ I k ∣ ∑ i ∈ I k ∥ x ( i ) − μ k ∥ 2 2 − 2 ∑ i ∈ I k ( x ( i ) − μ k ) ⊤ ∑ j ∈ I k ( x ( j ) − μ k ) = 2 ∣ I k ∣ ∑ i ∈ I k ∥ x ( i ) − μ k ∥ 2 2 \begin{aligned}
\sum_{i,j\in\mathcal{I}_{k}}^{K} & \left\Vert \boldsymbol{x}^{(i)}-\boldsymbol{x}^{(j)}\right\Vert _{2}^{2}=\sum_{i,j\in\mathcal{I}_{k}}\left\Vert \boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{k}+\boldsymbol{\mu}_{k}-\boldsymbol{x}^{(j)}\right\Vert _{2}^{2}\\
= & \sum_{i,j\in\mathcal{I}_{k}}\left\Vert \boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{k}\right\Vert _{2}^{2}+\sum_{i,j\in\mathcal{I}_{k}}\left\Vert \boldsymbol{x}^{(j)}-\boldsymbol{\mu}_{k}\right\Vert _{2}^{2}-2\sum_{i,j\in\mathcal{I}_{k}}\left(\boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{k}\right)^{\top}\left(\boldsymbol{x}^{(j)}-\boldsymbol{\mu}_{k}\right)\\
= & 2\left|\mathcal{I}_{k}\right|\sum_{i\in\mathcal{I}_{k}}\left\Vert \boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{k}\right\Vert _{2}^{2}-2\sum_{i\in\mathcal{I}_{k}}\left(\boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{k}\right)^{\top}\sum_{j\in\mathcal{I}_{k}}\left(\boldsymbol{x}^{(j)}-\boldsymbol{\mu}_{k}\right)\\
= & 2\left|\mathcal{I}_{k}\right|\sum_{i\in I_{k}}\left\Vert \boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{k}\right\Vert _{2}^{2}
\end{aligned} i , j ∈ I k ∑ K = = = ∥ ∥ ∥ ∥ x ( i ) − x ( j ) ∥ ∥ ∥ ∥ 2 2 = i , j ∈ I k ∑ ∥ ∥ ∥ ∥ x ( i ) − μ k + μ k − x ( j ) ∥ ∥ ∥ ∥ 2 2 i , j ∈ I k ∑ ∥ ∥ ∥ ∥ x ( i ) − μ k ∥ ∥ ∥ ∥ 2 2 + i , j ∈ I k ∑ ∥ ∥ ∥ ∥ x ( j ) − μ k ∥ ∥ ∥ ∥ 2 2 − 2 i , j ∈ I k ∑ ( x ( i ) − μ k ) ⊤ ( x ( j ) − μ k ) 2 ∣ I k ∣ i ∈ I k ∑ ∥ ∥ ∥ ∥ x ( i ) − μ k ∥ ∥ ∥ ∥ 2 2 − 2 i ∈ I k ∑ ( x ( i ) − μ k ) ⊤ j ∈ I k ∑ ( x ( j ) − μ k ) 2 ∣ I k ∣ i ∈ I k ∑ ∥ ∥ ∥ ∥ x ( i ) − μ k ∥ ∥ ∥ ∥ 2 2 שכן:
∑ i ∈ I k ( x ( i ) − μ k ) = ∣ I k ∣ ⋅ 1 ∣ I k ∣ ∑ i ∈ I k x ( i ) − ∣ I k ∣ μ k = 0 \sum_{i\in I_{k}}\left( \boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{k}\right) = \left|\mathcal{I}_{k}\right| \cdot \frac{1}{\left|\mathcal{I}_{k}\right|}\sum_{i\in I_{k}}\boldsymbol{x}^{(i)}-\left|\mathcal{I}_{k}\right|\boldsymbol{\mu}_{k} = 0 i ∈ I k ∑ ( x ( i ) − μ k ) = ∣ I k ∣ ⋅ ∣ I k ∣ 1 i ∈ I k ∑ x ( i ) − ∣ I k ∣ μ k = 0 האלגוריתם
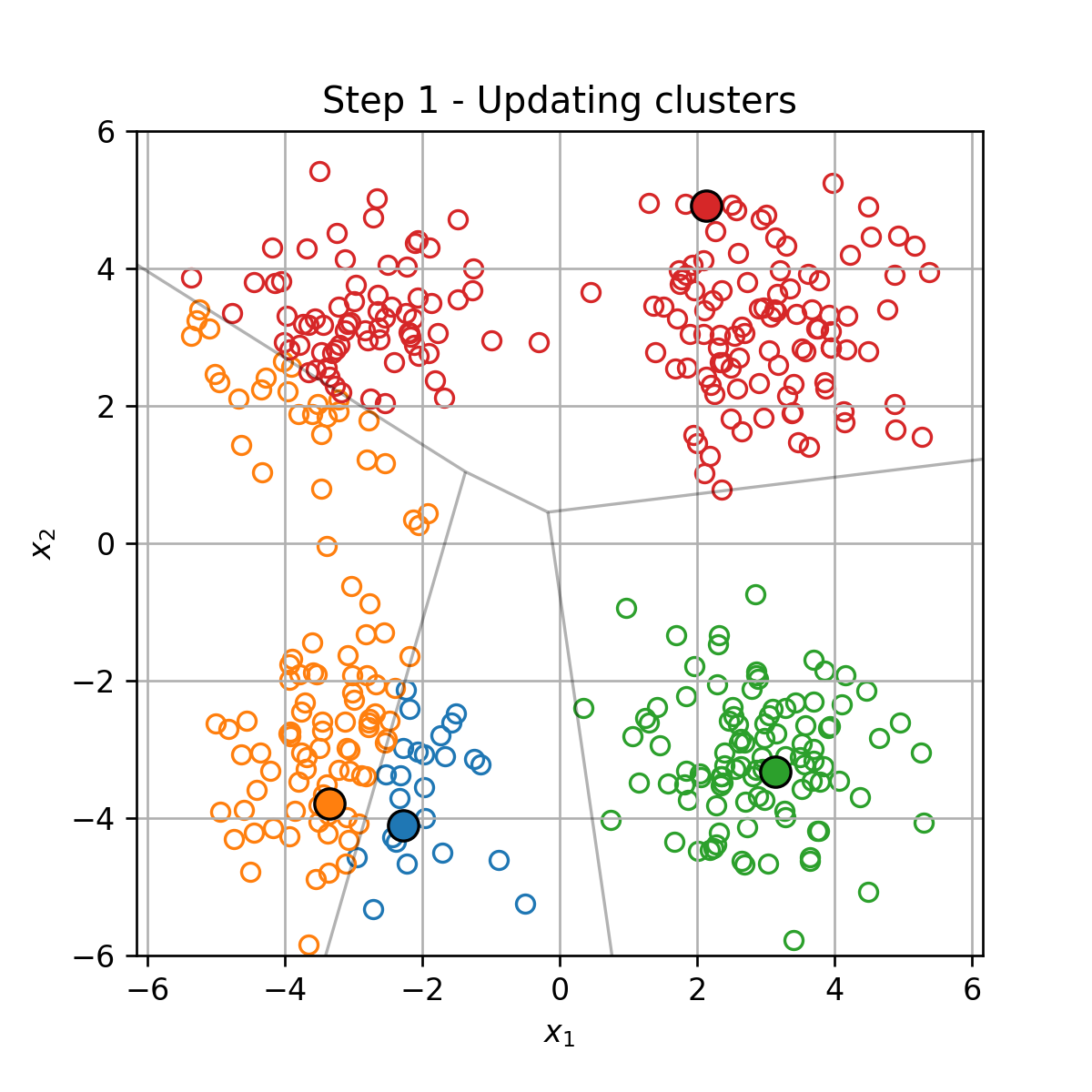
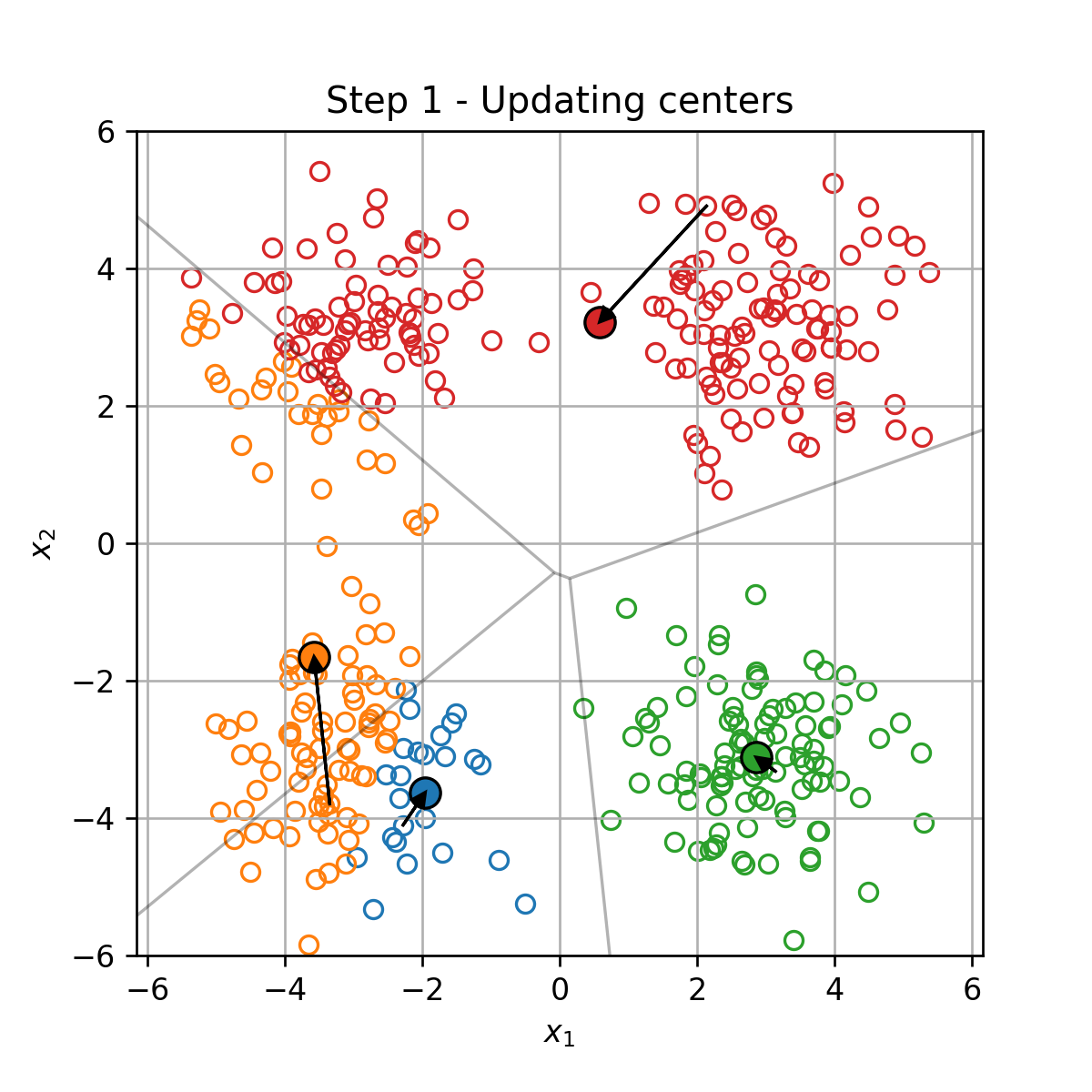
אלגוריתם חמדן.
מאותחל ב t = 0 t=0 t = 0 { μ k } k = 1 K \{\mu_k\}_{k=1}^K { μ k } k = 1 K
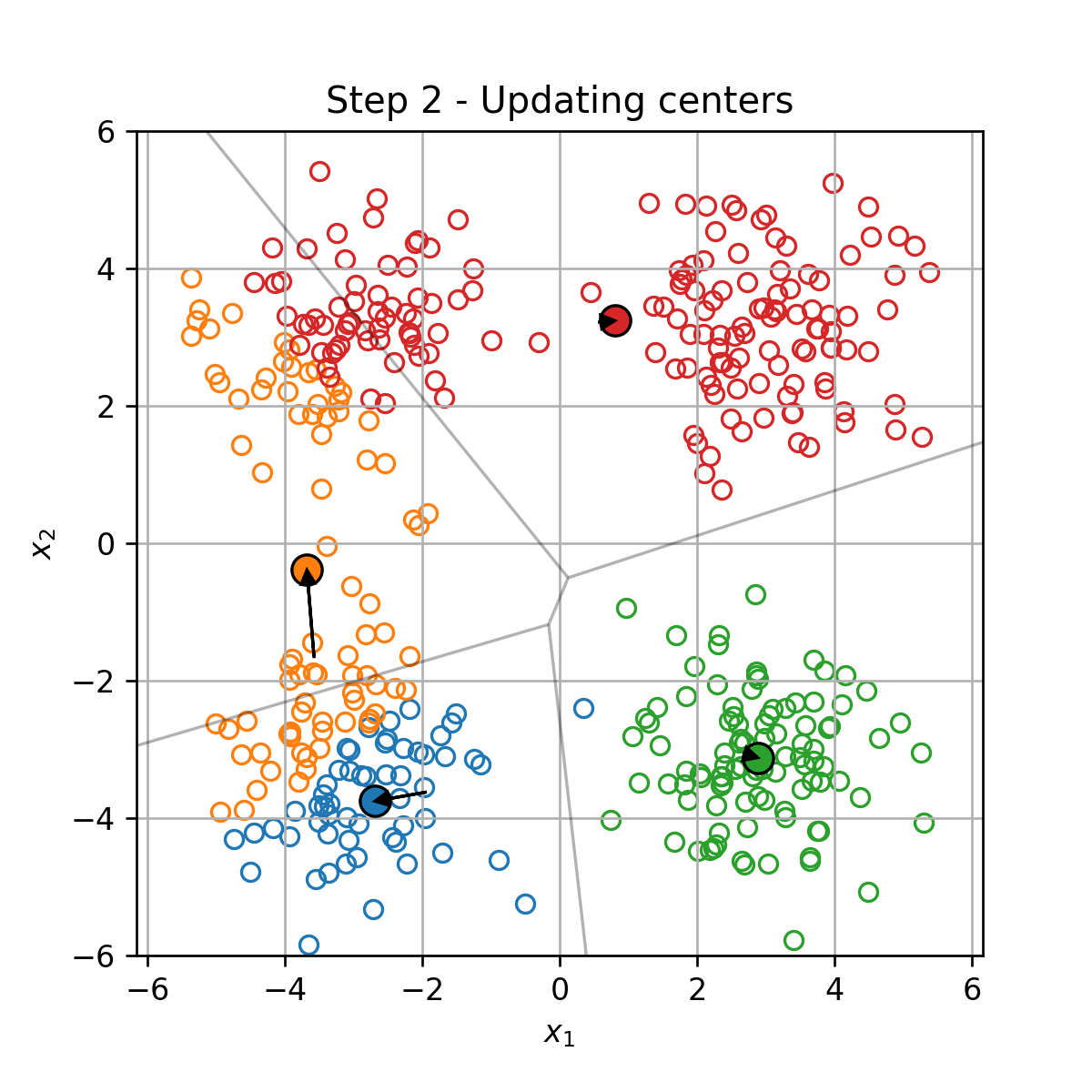
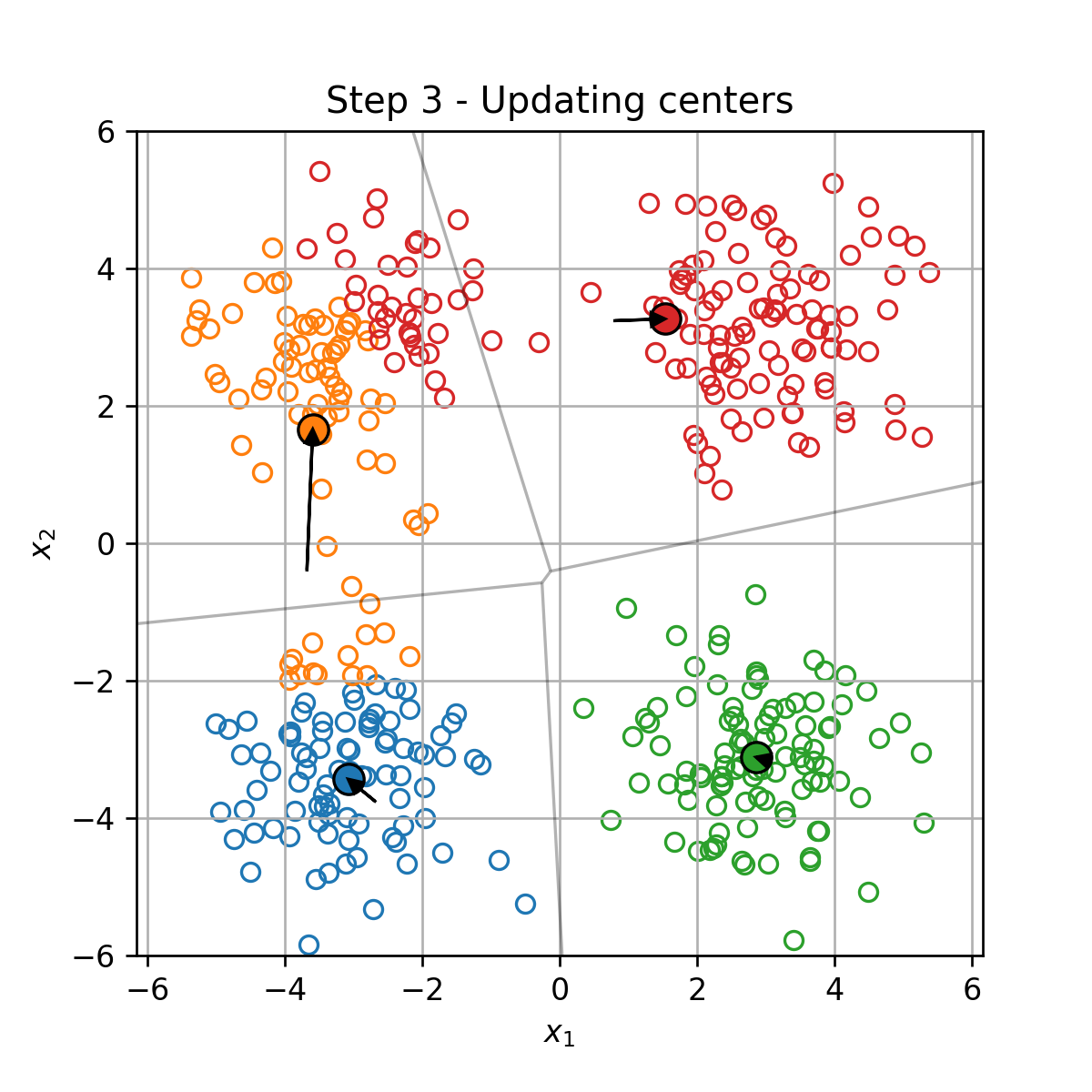
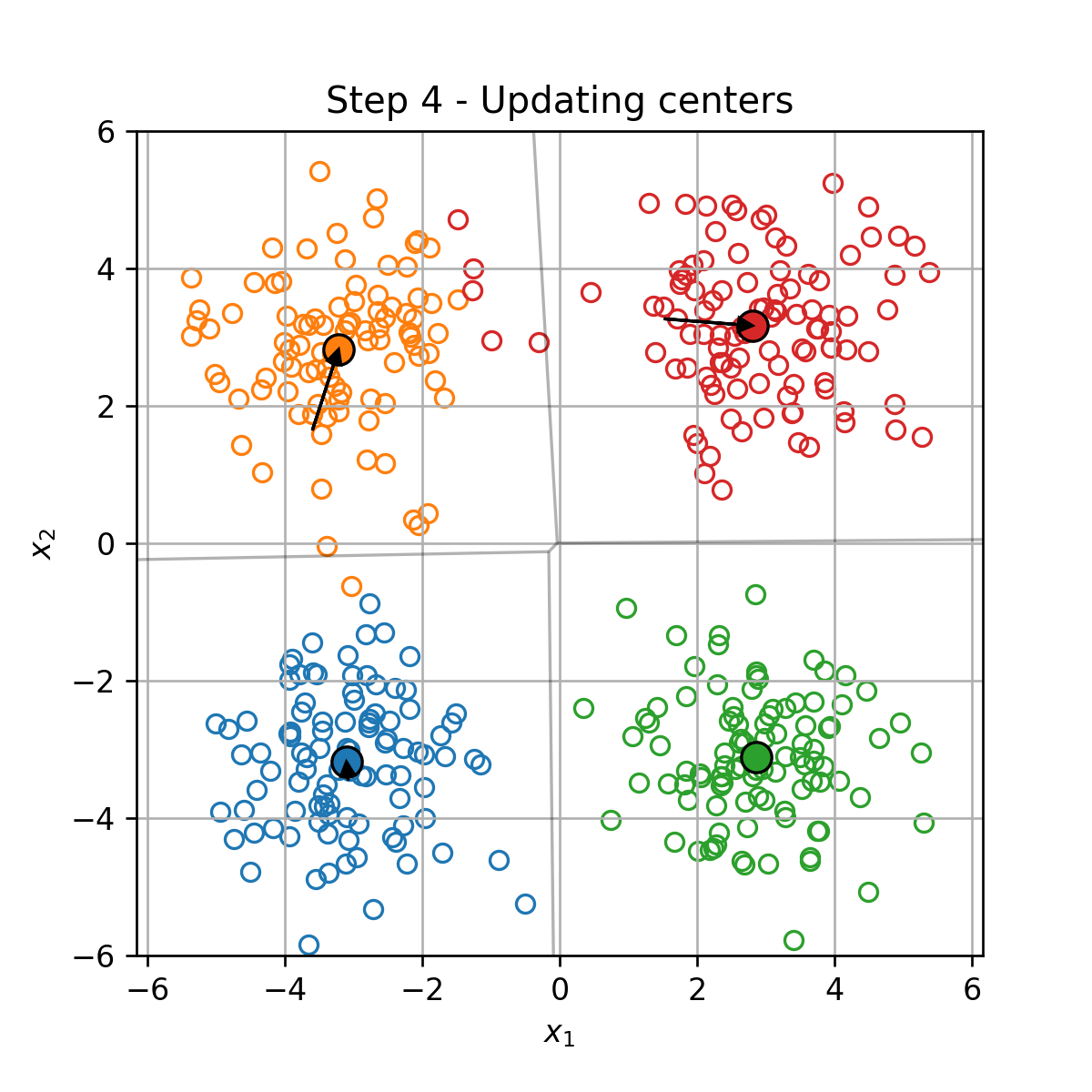
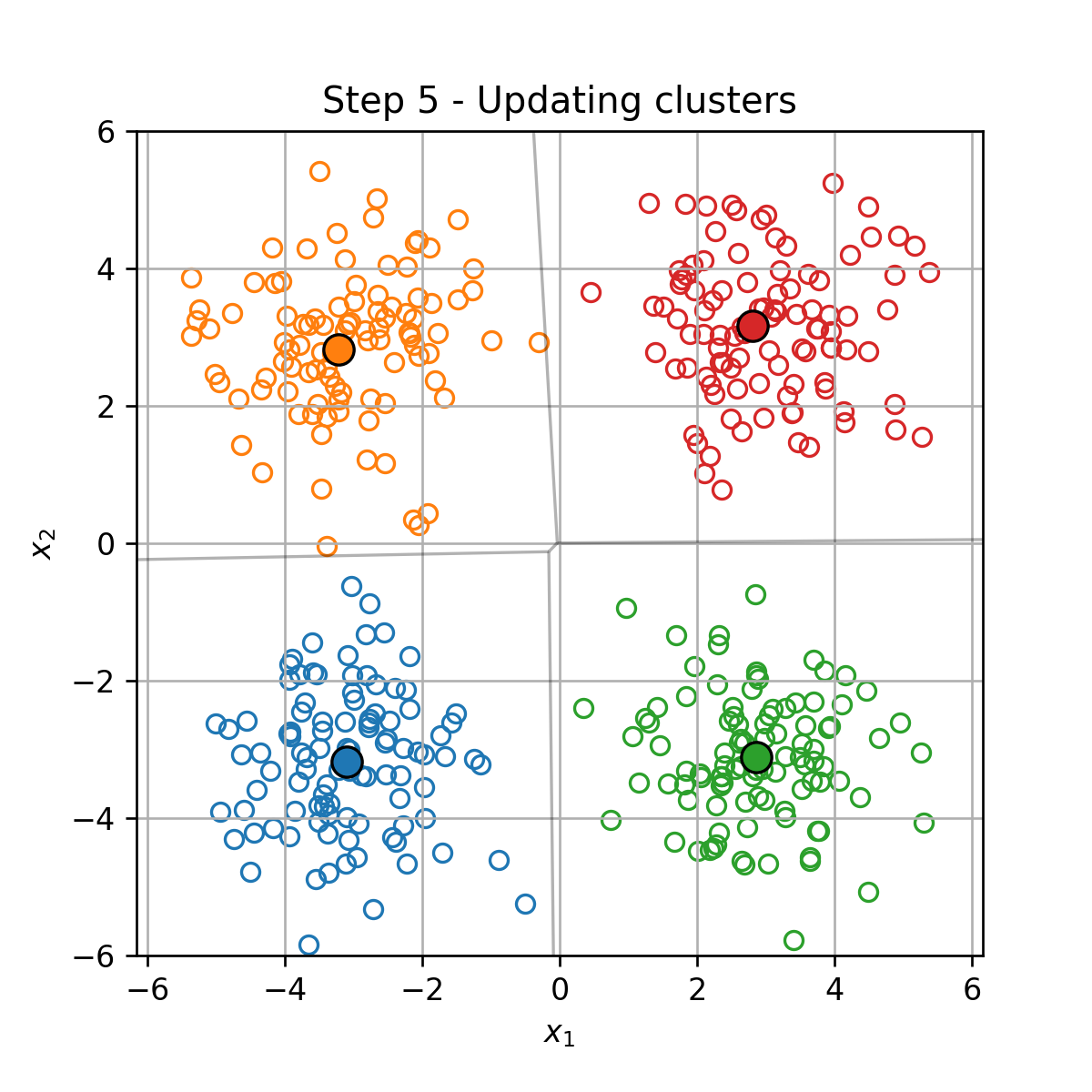
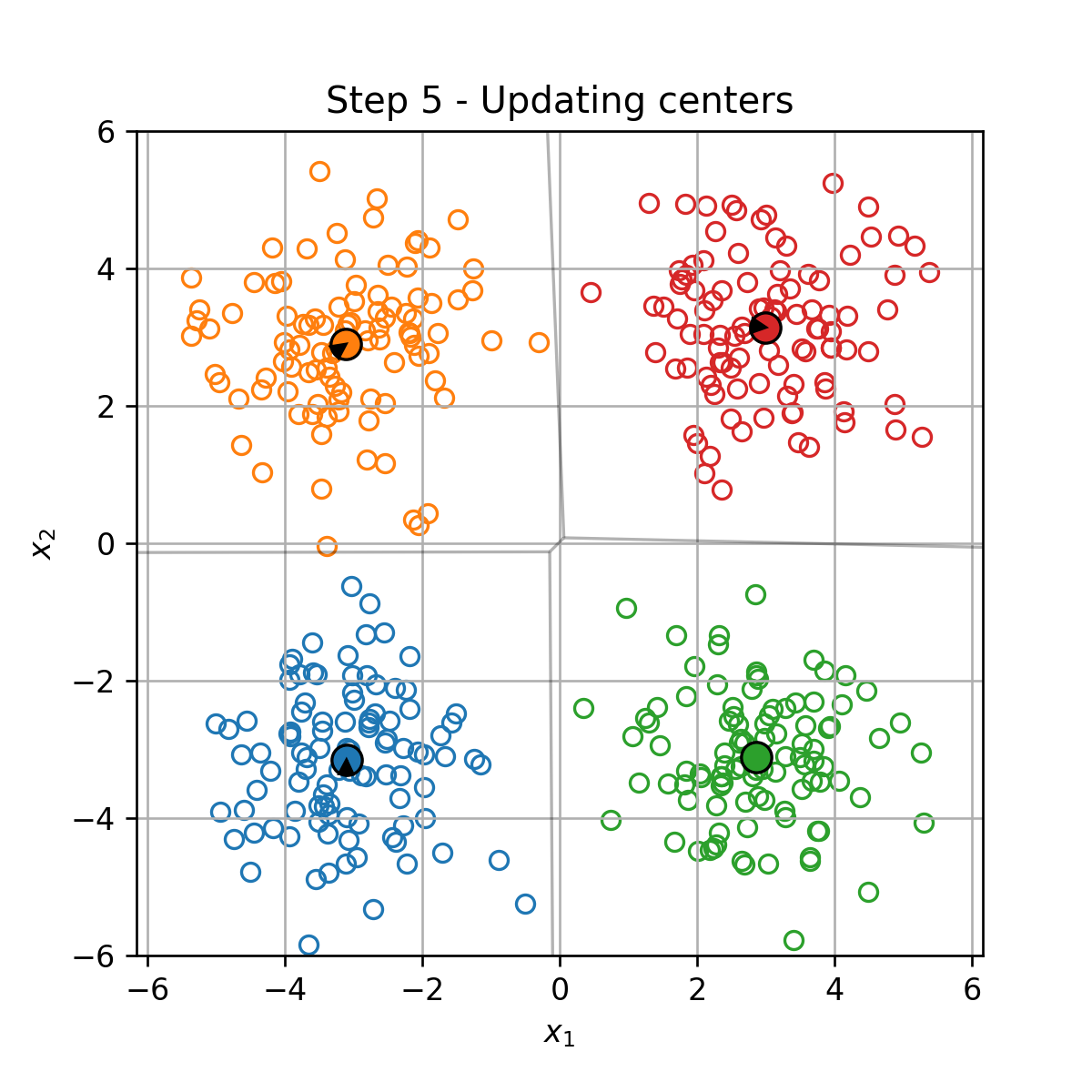
בכל צעד t t t
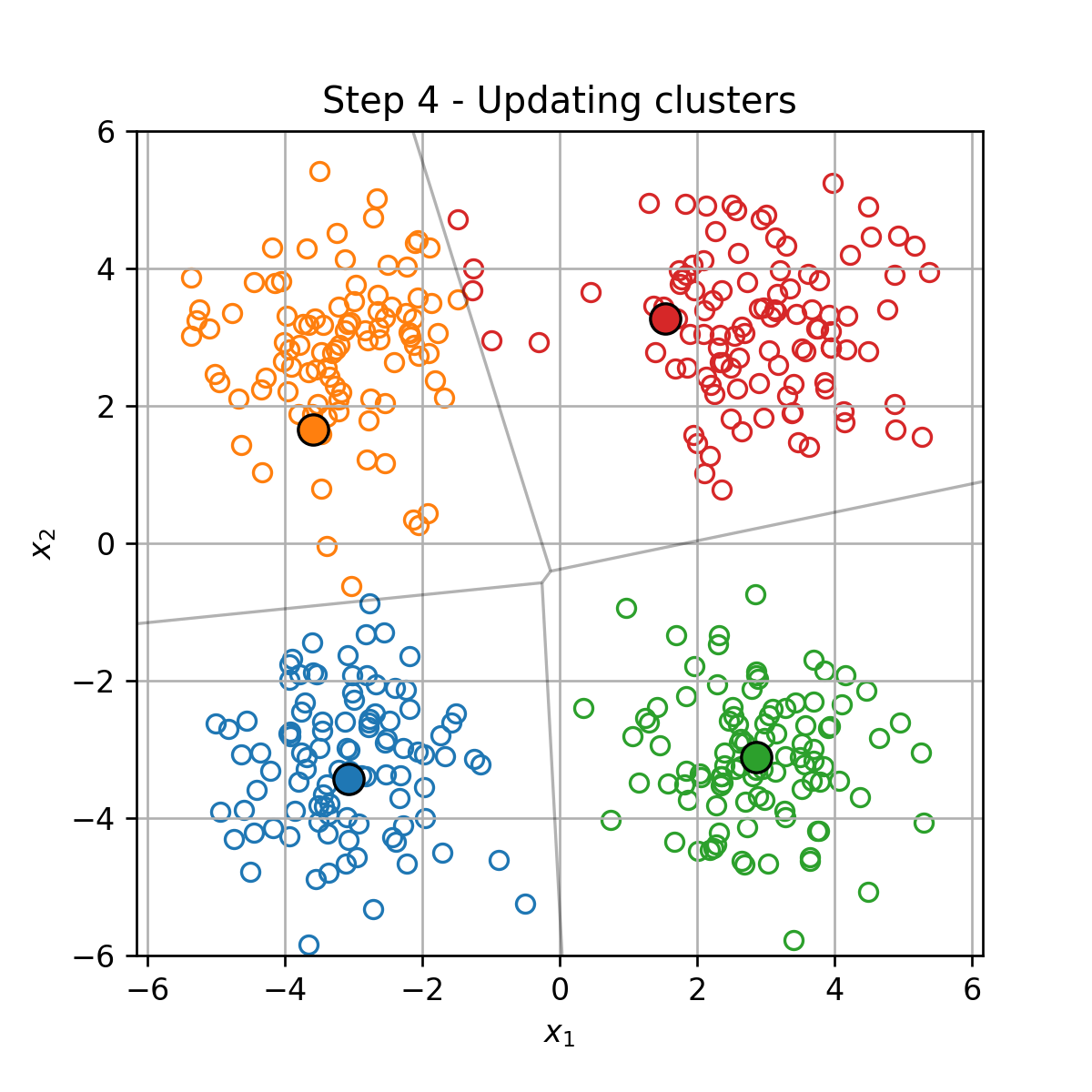
עדכון מחדש של החלוקה לאשכולות { I k } k = 1 K \{\mathcal{I}_k\}_{k=1}^K { I k } k = 1 K
עדכון של מרכזי המסה המסה על פי:
μ k = 1 ∣ I k ∣ ∑ i ∈ I k x ( i ) \boldsymbol{\mu}_k=\frac{1}{|\mathcal{I}_k|}\sum_{i\in\mathcal{I}_k}\boldsymbol{x}^{(i)} μ k = ∣ I k ∣ 1 i ∈ I k ∑ x ( i )
תנאי העצירה הינו כשהאשכולות מפסיקות להשתנות.
תכונות
מובטח כי פונקציית המטרה תקטן בכל צעד.
מובטח כי האלגוריתם יעצר לאחר מספר סופי של צעדים.
לא מובטח כי האלגוריתם יתכנס לפתרון האופטימאלי. בפועל במרבית מתכנס לפתרון קרוב מאד לאופטימאלי.אתחולים שונים יכולים להוביל לתוצאות שונות.
דוגמא
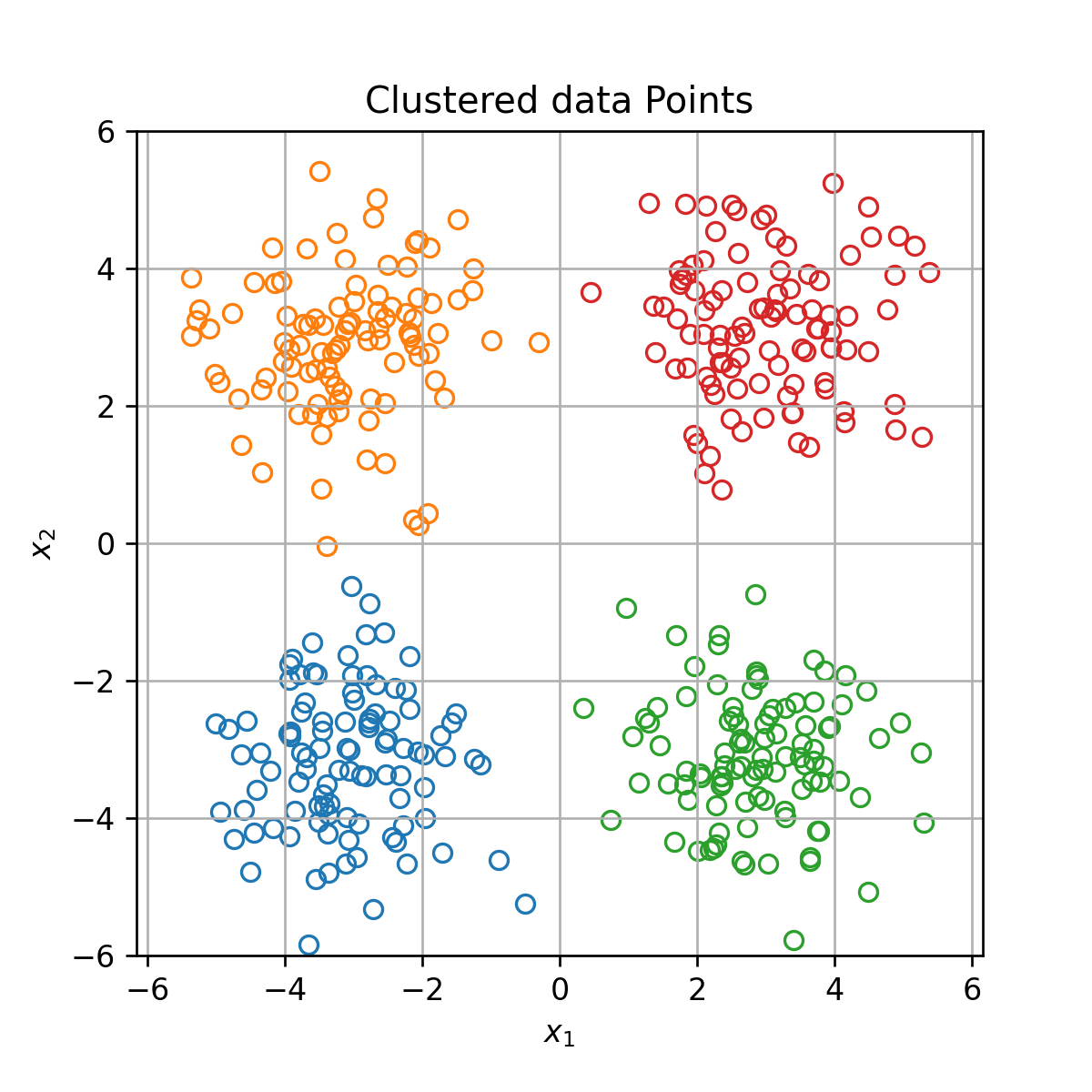
אתחול (וחלוקה ראשונית לאשכולות):
דוגמא
וחוזר חלילה (הסדר הוא מימין לשמאל):
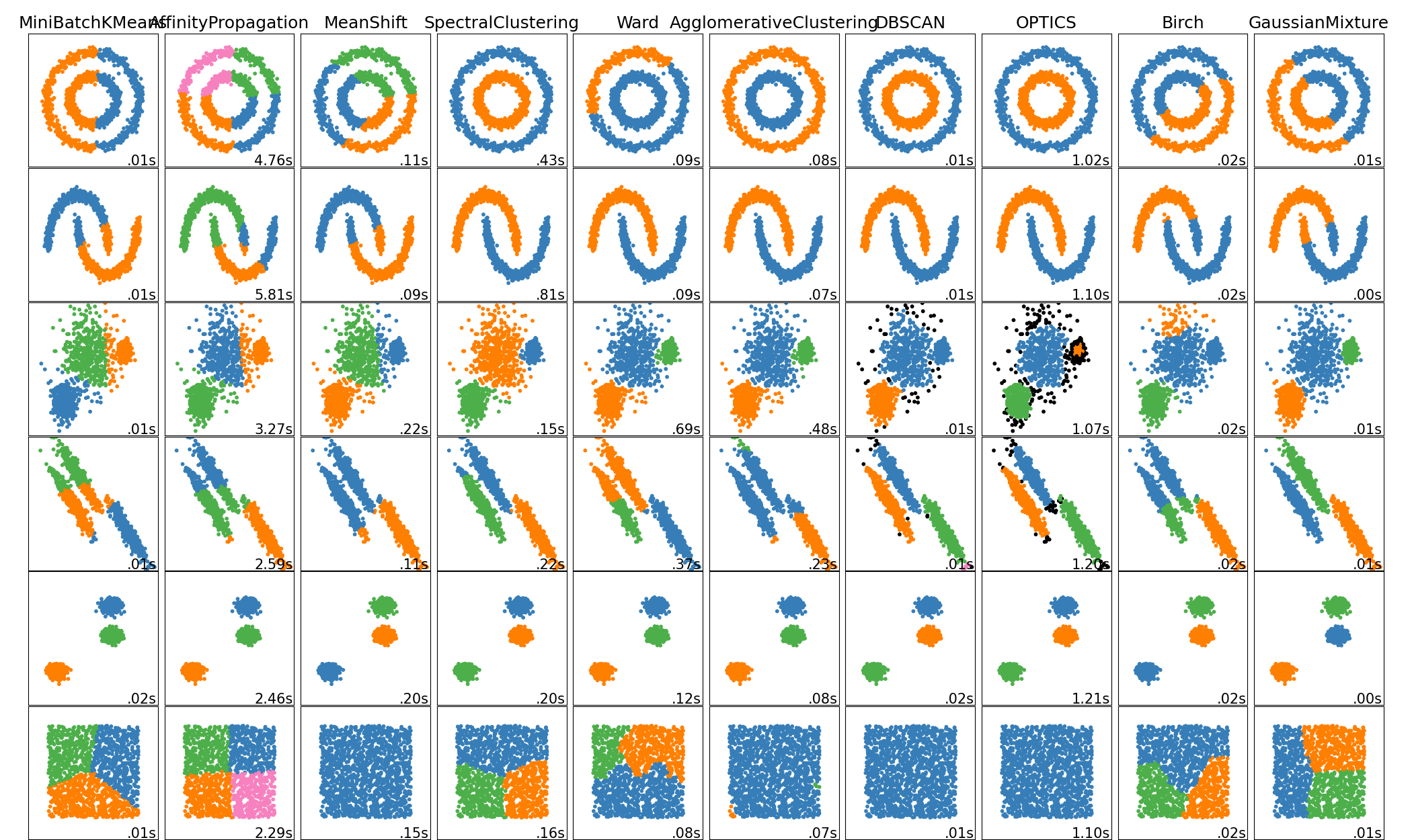
אלגוריתמי אשכול שונים
לרוב לא נוכל לצייר את האשכולות בשני ממדים.