Unsupervised learning הינה שם כולל למגוון של בעיות בהם אנו מנסים בהינתן מדגם, ללמוד את התכונות של הדגימות או של המדגם כולו. בניגוד ל supervised learning, ב unsupervised learning המדגם יכיל רק אוסף של דגימות (x), ללא תווית (y). להלן דוגמאות לכמה בעיות ב unsupervised learning:
אשכול (חלוקה לקבוצות).
מציאת ייצוג "נוח" יותר של הדגימות.
דחיסה.
זיהוי אנומליות.
למידת הפילוג של הדגימות.
כפי שציינו בעבר, בקורס זה לא נציג את הנושא של unsupervised learning באופן מקיף אלא רק נלמד על שני אלגוריתמים פופולריים מתחום זה, PCA ו K-Means.
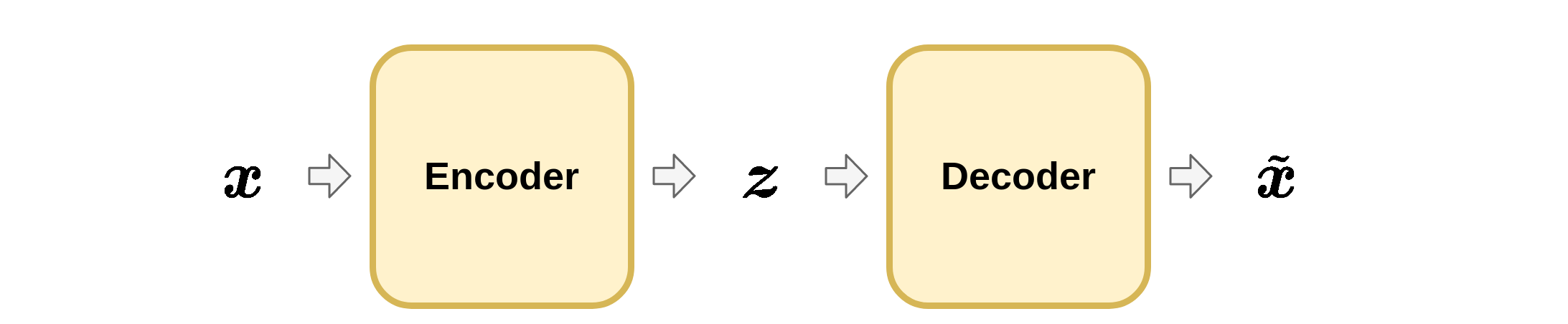
מערכת Encoder-Decoder
תצורה נפוצה של מערכות שמטפלות במידע הינה:
במערכת מסוג זה נרצה להשתמש בפונקציית ה encoder על מנת למפות את הוקטור x לייצוג אלטרנטיבי z אשר יהיה מתאים יותר לשימושים כל שהם. בכדי לנסות שחזר את x נוכל להעביר את z דרך ה decoder.
דוגמאות לשימושים במערכת encoder-decoder הינם:
דחיסה: כאן נרצה ש z יהיה קטן ככל האפשר (במובן של כמות הביט שנדרשים בכדי לייצג אותו).
תקשורת: כאן נרצה ש z יהיה כמה שפחות רגיש לרעשים של התווך.
הצפנה: כאן נרצה שפעולת השחזור של x תהיה כמה שיותר קשה ללא ה decoder המתאים.
הוקטור x~ המתקבל מהפעלה של ה decoder על הוקטור z נקרא השחזור של x. בחלק מהמערכות ניתן להגיע לשיחזור מושלם, x~=x, ובחלק מהמערכות לא.
Principle Component Analysis (PCA)
ב PCA ננסה לבנות מערכת encoder-decoder שבה:
אנו מגבילים את האורך של הוקטור z.
אנו דורשים שה encoder וה decoder יהיו פונקציות אפיניות (affine = linear + offset).
התוחלת של שגיאת השחזור הריבועית E[∥x~−x∥22] היא מינימאלית.
מכיוון שהפילוג של x לרוב לא יהיה ידוע נשתמש במדגם ונחליף את התוחלת בתוחלת אמפירית על המדגם.
נסמן את האורך של הוקטור z שאותו אנו מעוניינים לייצר ב K ואת האורך של x ב D ונגדיר את הבעיה באופן יותר פורמאלי. אנו מעוניינים למצוא encoder מהצורה:
z=T1x+b1
ו decoder מהצורה של:
x~=T2z+b2
כאשר:
T1 הינה מטריצה בגודל K×D.
T2 הינה מטריצה בגודל D×K.
b1 הינה וקטור באורך K.
b2 הינה וקטור באורך D.
אשר ממזערים את התוחלת האמפירית של שגיאת השחזור הריבועית:
T1,T2,b1,b2argminN1i=1∑N∥x~(i)−x(i)∥22
שימושים
ישנם מקרים רבים בהם נרצה למצוא לוקטורים יצוג ממימד נמוך. פעולה זו מכונה הורדת מימד (dimensionality reduction) ודוגמאות למקומות שבהם נרצה להשתמש בפעולה זו הינם:
בחירת מאפיינים לבעיות supervised learning - בהם נרצה להשתמש בוקטורים ממימד נמוך יותר על מנת להקטין את ה overfitting.
ויזואליזציה - בהם נרצה להפוץ וקטורים ממימד גבוה למימד 2 או 3 שאותם אנו יודעים לשרטט.
דחיסה.
הפתרון לבעיית האופטימיזציה
נתחיל בלהציג את הפתרון לבעיה.
הפשטת הבעיה תוך ביטול היתירות
מסתבר שלבעיה זו יש מספר רב של פתרונות. בתהליך פיתוח הפתרון ניתן להראות שניתן לבחור את הפרמטרים כך שיקיימו את האילוצים הבאים מבלי לפגוע באופטימאליות של הפתרון:
b1b2T1T⊤T=−T1μ=μ=T2⊤=T⊤=I
לדוגמה, עבור המיפוי הבא
z=T1x+b1x~=T2z+b2T1∈RK×D,T2∈RD×K
איברי ההטיה b1 ו-b2 יכולים להיקבע ע"י הדרישות
E[z]=0⇒b1=−T1μ
ו-
E[x~]=E[x]⇒b2=E[x]=μ
כאשר μ=N1∑i=1Nx(i). הטרנספורמציות במקרה זה הופכות להיות:
שימו לב:T∈RD×K כך שמתקיים כי T⊤T∈RK×K=IK כאשר IK היא מטריצת היחידה. בנוסף, מתקיים TT⊤∈RD×D והיא לא שווה בהכרח ל-ID.
פרשנות גיאומטרית
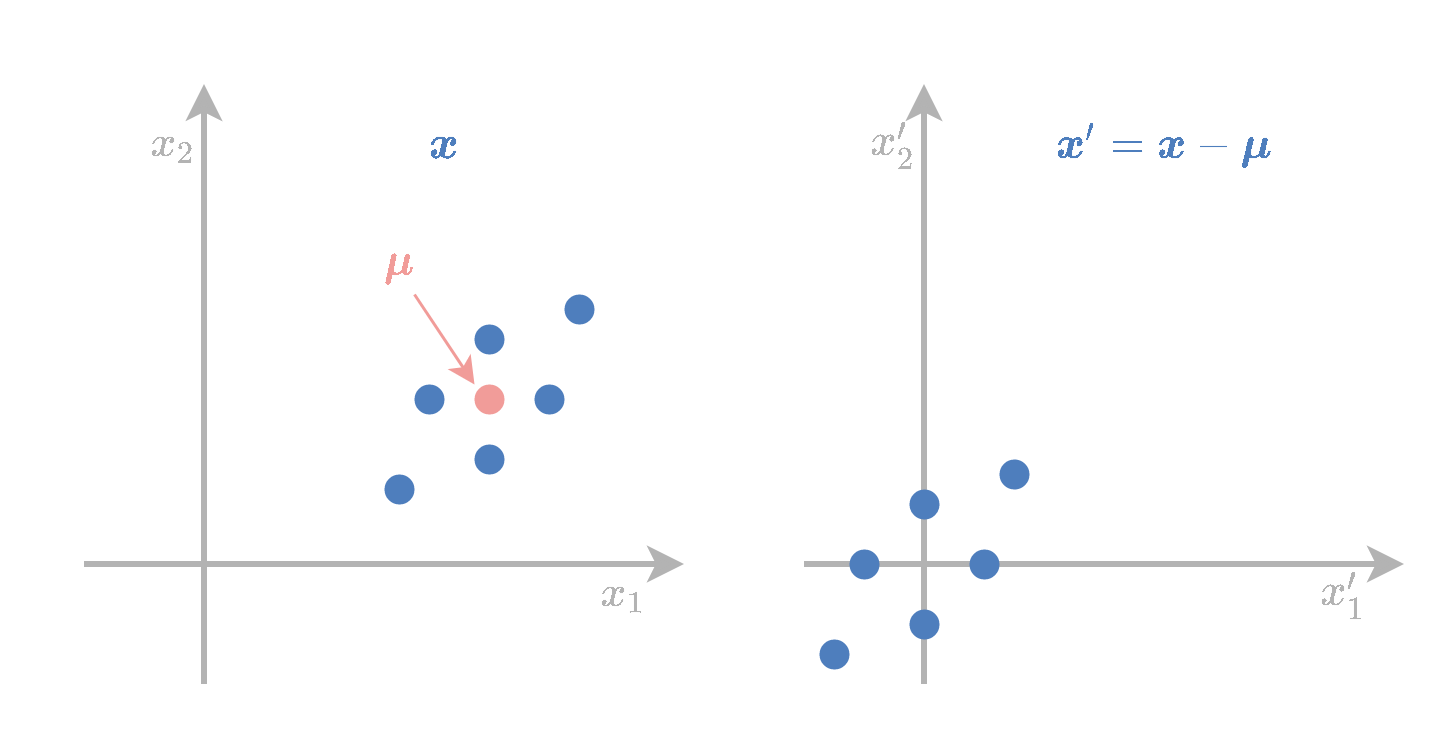
ראשית נשים לב שה encoder מתחיל בלחסר את הממוצע של x וה decoder מסיים בלהוסיף אותו בחזרה. נניח מעתה שהנתונים ממורכזים סביב האפס.
נדגים זאת עבור המקרה של D=2 ו K=1:
הטרנספורמציות המתקבלות הינן:
zx~=T⊤x=Tz=TT⊤x
נתייחס כעת לאילוץ של T⊤T=I. נציין רק שאילוץ זה הוא לא הכרחי בשביל שהפתרון יהיה אופטימאלי אך הוא לא מפשט מאד את הבעיה ומקיים ולא פוגע באופטימאליות של הפתרון. אילוץ זה אומר שהעמודות של T צריכות להיות אורתונורמאליות (אורתוגונאליות ומנורמלות). נסמן את העמודות של T ב uj:
T=⎝⎛∣u1∣∣u2∣…∣uK∣⎠⎞
הפעולה של x~=TT⊤x′ מטילה את הוקטור x על תת-המרחב הלינארי הנפרס על ידי הוקטורים uj. נדגים זאת על המקרה הקודם:
הפעולה של z=T⊤x למעשה גם כן מטילה את x על אותו תת-מרחב, היא רק משאירה אותו במערכת הצירים אשר מוגדרת על ידי הוקטורים uj:
נסתכל כעת על המשמעות הגיאומטרית של שגיאת השחזור ∥x~−x∥22:
הוקטור x~−x הוא וקטור המחבר את x ל x~. שגיאת השחזור הריבועית הינה האורך של וקטור זה בריבוע. בעיית האופטימיזציה היא אם כן הבעיה של מציאת תת-המרחב ממימד K אשר ההטלה של נקודות המדגם עליו הם הקרובות ביותר לנקודות המקוריות.
נזכור ש ∥x∥22 והוא תכונה של הוקטורים במדגם; הם אינם תלויים ב T ולכן:
T∗=Targmins.t.−N1i=1∑N∥z(i)∥22T⊤T=I
לכן הבעיה של מזעור שגיאת השחזור הריבועית שקולה לבעיה של מקסום הגודל ∑i=1N∥z(i)∥22 אשר מכונה לרוב ה variance של אוסף הוקטורים {z(i)}i=1N (בפועל זה ה trace של מטריצת ה covariance האמפירית של z)
הפתרון
בכדי לתאר את הפתרון של בעיות האופטימיזציות האלה (מזעור שגיאת השחזור או מקסום ה variance של z) נגדיר את המטריצות הבאות:
מכיוון ש המטריצה P היא ממשית וסימטרית מובטח כי ניתן לפרק אותה באופן הבא (ליכסון של המטריצה) P=UΛU⊤ כאשר U היא מטריצה אורתונורמלית אשר העמודות שלה הם וקטורים עצמיים של P:
U=⎝⎛∣u1∣∣u2∣…∣uD∣⎠⎞
ו Λ היא מטריצה אלכסונית אשר מכילה את הערכים העצמיים של P:
Λ=⎝⎜⎜⎜⎜⎛λ10⋮00λ20…⋱…00⋮λD⎠⎟⎟⎟⎟⎞
כך שהערך העצמי λj מתאים לוקטור העצמי uj והערכים העצמיים מסודרים מהגדול לקטן: λ1≥λ2≥⋯≥λD.
בעזרת מטריצות אלו ניתן כעת לרשום את הפתרון למטריצה T האופטימאלית. מטריצה זו תהיה מטריצה אשר העמודות שלה הם K העמודות הראשונות במטריצה U:
T=⎝⎛∣u1∣∣u2∣…∣uK∣⎠⎞
הכיוונים u(j) מכונים הכיוונים העיקריים והרכיבים של הוקטור z מכונים הרכיבים העיקריים (principal components).
קווים כלליים לפתרון
נציג את הרעיון הכללי לפתרון הבעיה בלי הפיתוחים המתימטיים מלאים.
חישוב ה offsets
ראשית ניתן למצוא תנאי על b1 ו b2 על יד גזירה והשוואה ל-0. תנאי זה הינו:
T2b1+b2=−T2T1μ+μ
כאשר μ=N1∑i=1Nx(i). כאשר כל בחירה של b1 ו b2 שמקיימת את התנאי תהיה אופטימאלית. בפרט נוכל לבחור:
b1=−T1μ,b2=μ
ומכאן אנו מקבלית את הטרנספורמציות של:
z=T1(x−μ)x~=T2z+μ
הקשר בין T1 ו T2
על ידי קיבוע T2 וחיפוש ה z אשר ממזער את בעיית האופטימיזציה מקבלים ש:
T1=(T2⊤T2)−1T2⊤
בפרט ניתן להראות שניתן לבחור את T2 כך ש T2⊤T2=I. נסמן את T2=T ונקבל ש:
ניתן להראות שהפתרון לבעיה זו הינה המטריצה T שתוארה בפתרון על ידי שימוש באינדוקציה, כאשר מתחילים מ K=1 ומגדילים אותו כל פעם ב 1.
דוגמא
נציג דוגמא לפירוק PCA של תמונות. נתייחס לתמונות בעל וקטור ארוך של פיקסלים. בדומא הבאה נסתכל על תמונות של 381 פיקסלים. 20 הכיוונים העיקריים (הוקטורים העצמיים המתאימים לערכים העצמיים הכי גדולים) הינם:
נציג כעת את התמונה המשוחזרת בעבור ערכים שונים של K:
אשכול
באלגוריתמי אשכול ננסה לחלק אוסף של פרטים לקבוצות המכונים אשכולות (clusters), כאשר לכל קבוצה איזשהן תכונות דומות.
⇦
2 דוגמאות למקרים שבהם נרצה לאשכל אוסף נתונים:
על מנת לבצע הנחות על אחד מהפרטים באשכול על סמך פרטים אחרים באשכול. לדוגמא: להציע ללקוח מסויים בחנות אינטרנט מוצרים על סמך מוצרים שקנו לקוחות אחרים באשכול שלו.
לתת טיפול שונה לכל אשכול. לדוגמא משרד ממשלתי שרוצה להפנות קבוצות שונות באוכלוסיה לערוצי מתן שירות שונים: אפליקציה, אתר אינטרנט, נציג טלפוני או הפניה פיסית למוקד שירות.
אלגוריתמי אשכול שונים
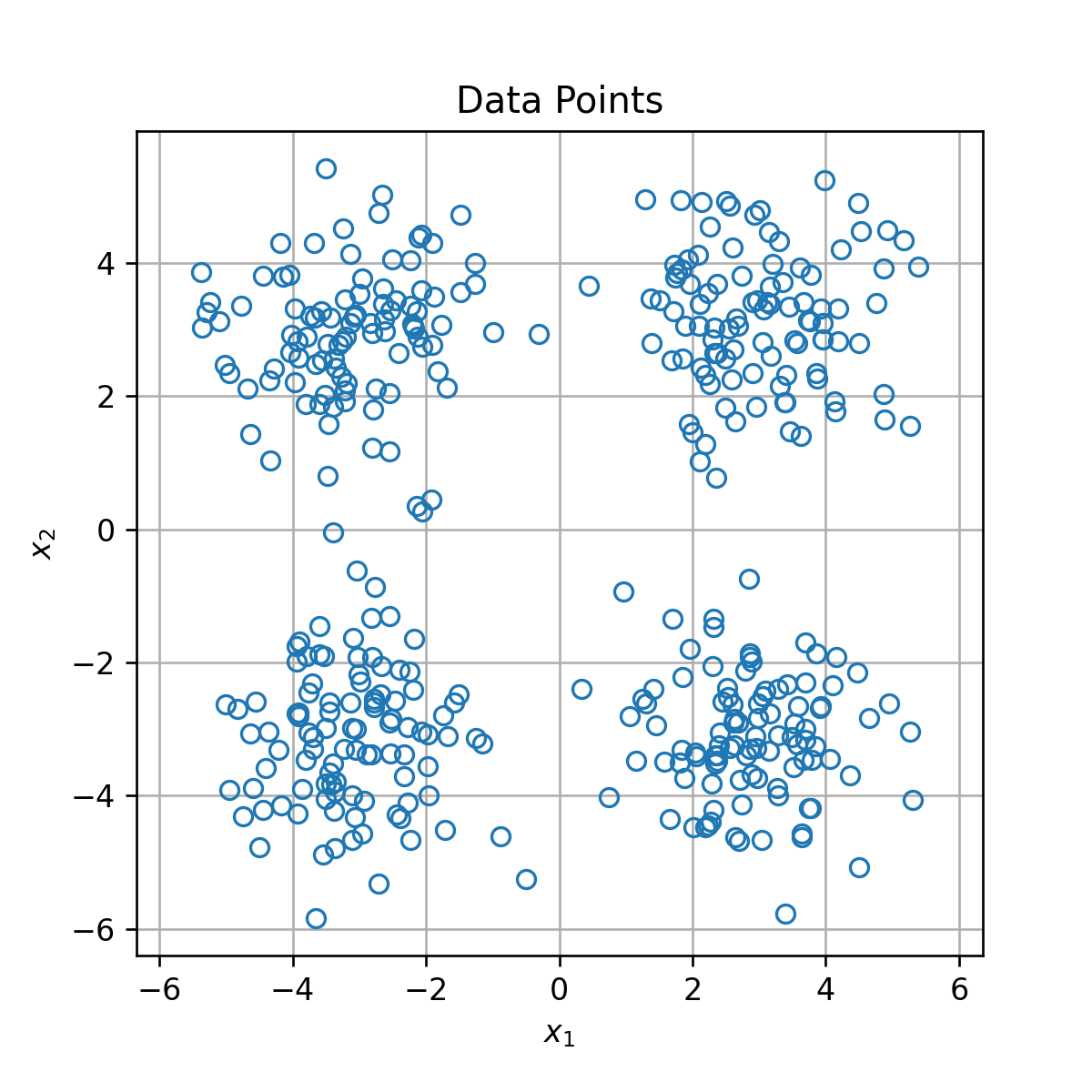
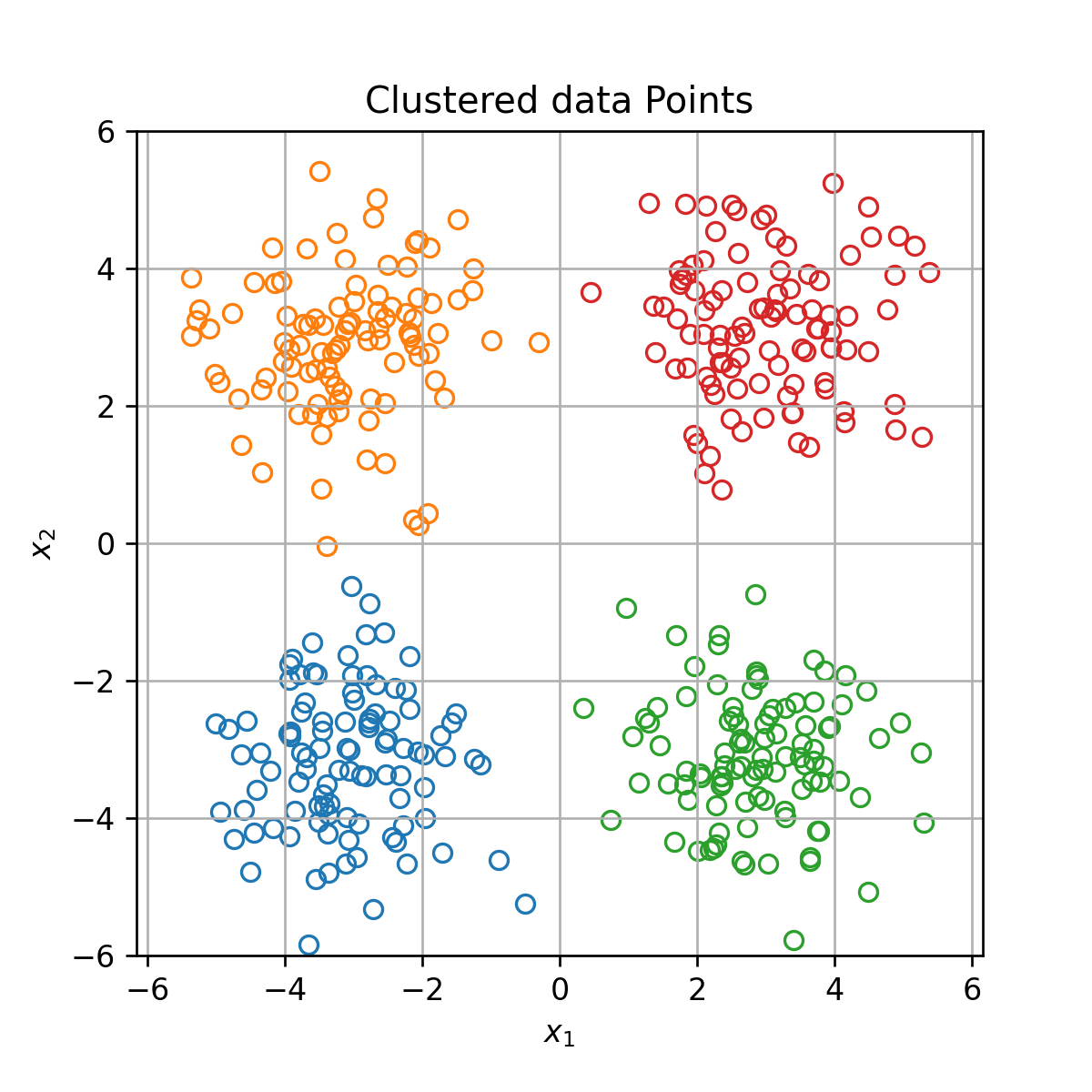
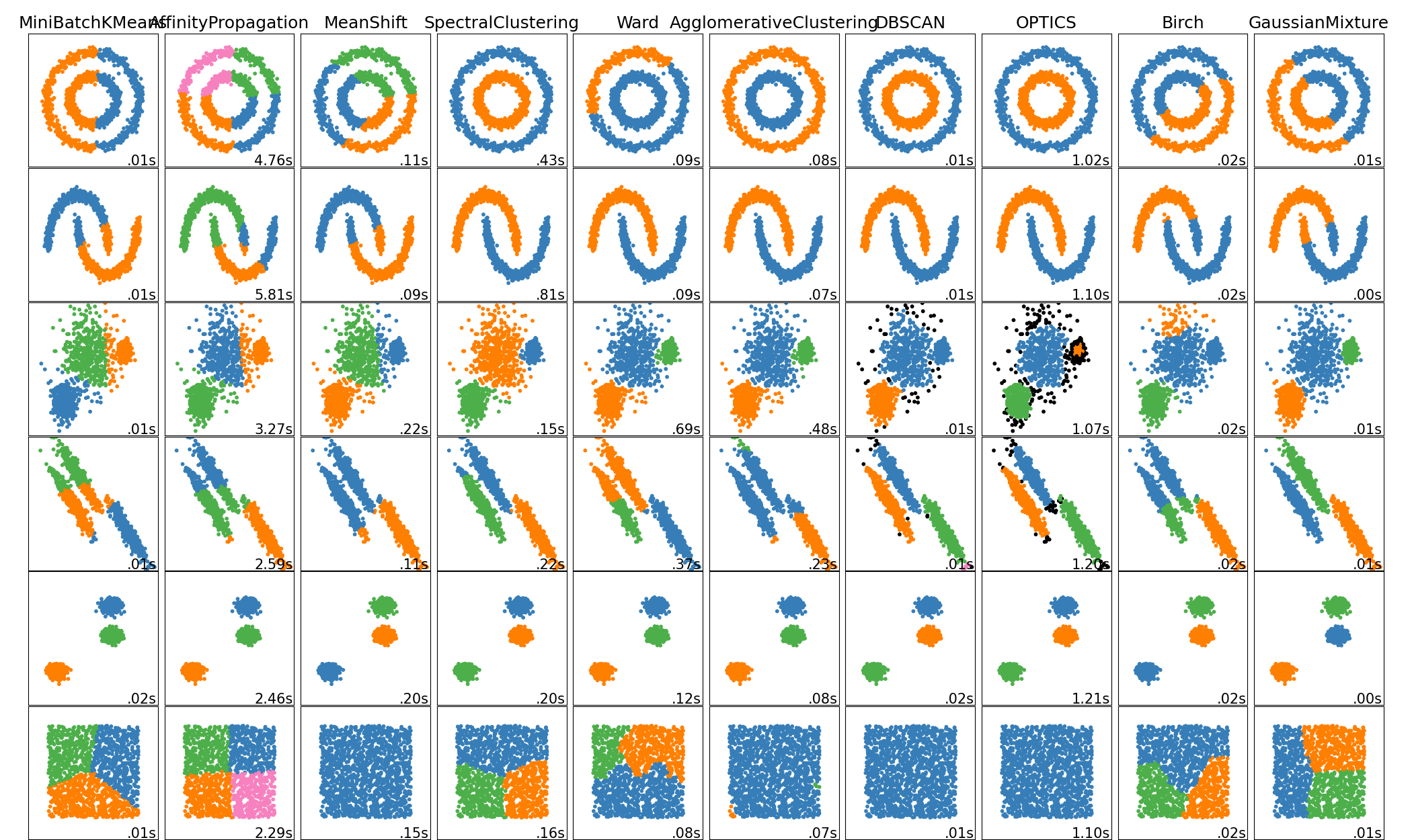
קיימות דרכים רבות לבצע אישכול לאוסף של נתונים. בהתאם לכך קיימים גם מספר רב של אלגוריתמים לעשות כן. בתיעוד של החבילה הפייתונית scikit-learn, בה נעשה שימוש רב בתרגילים הרטובים בקורס, ישנה השוואה בין האשכולות המתקבלים מאלגוריתמים האישכול השונים בחבילה, בעבור שישה toy models דו מימדיים:
נציין כי לרוב נעבוד עם נתונים ממימד גבוה, שם לא נוכל, כמו כאן, לצייר את האשכולות על מנת להבין את אופי החלוקה.
בקורס זה נלמד על האלגוריתם K-means (העמודה השמאלית ביותר).
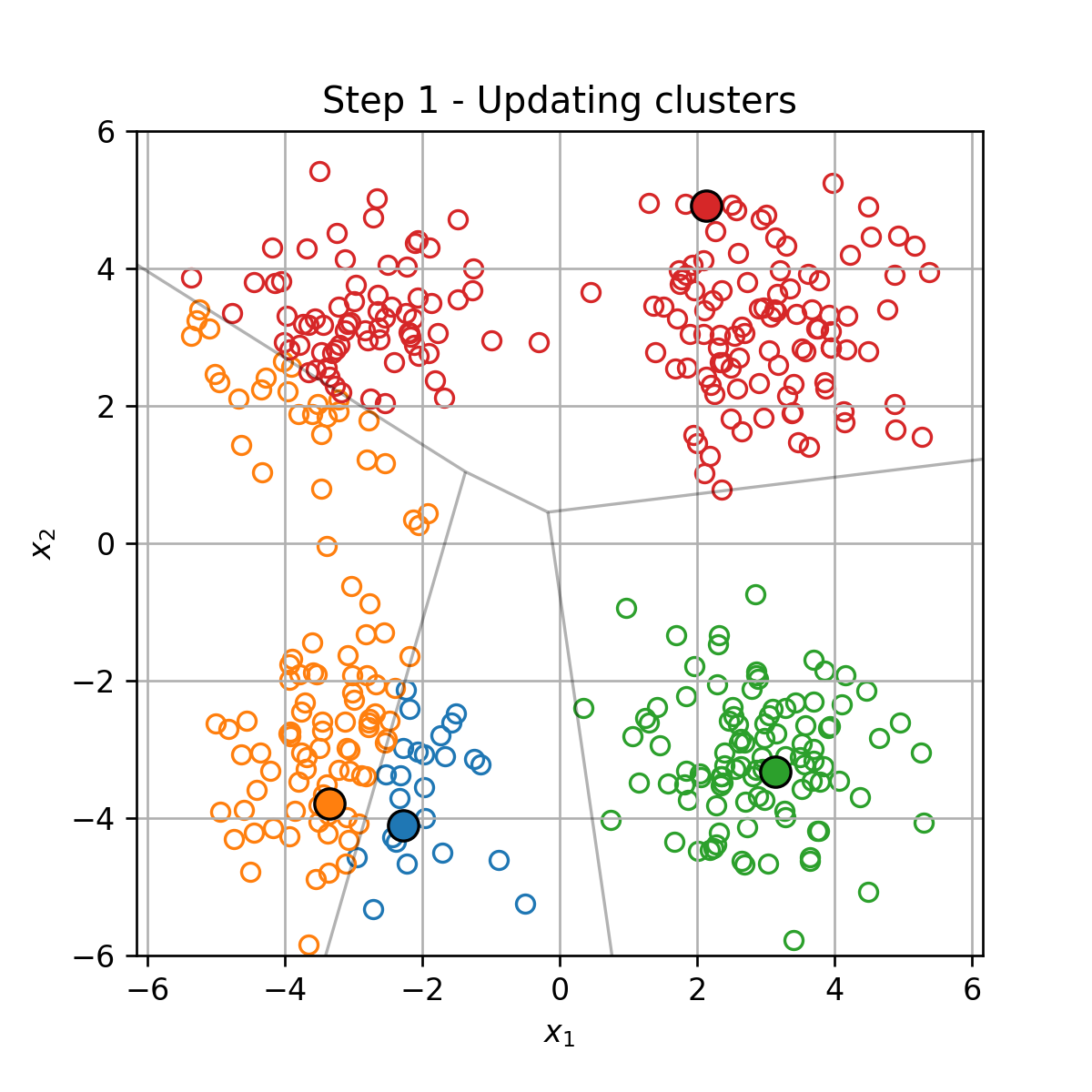
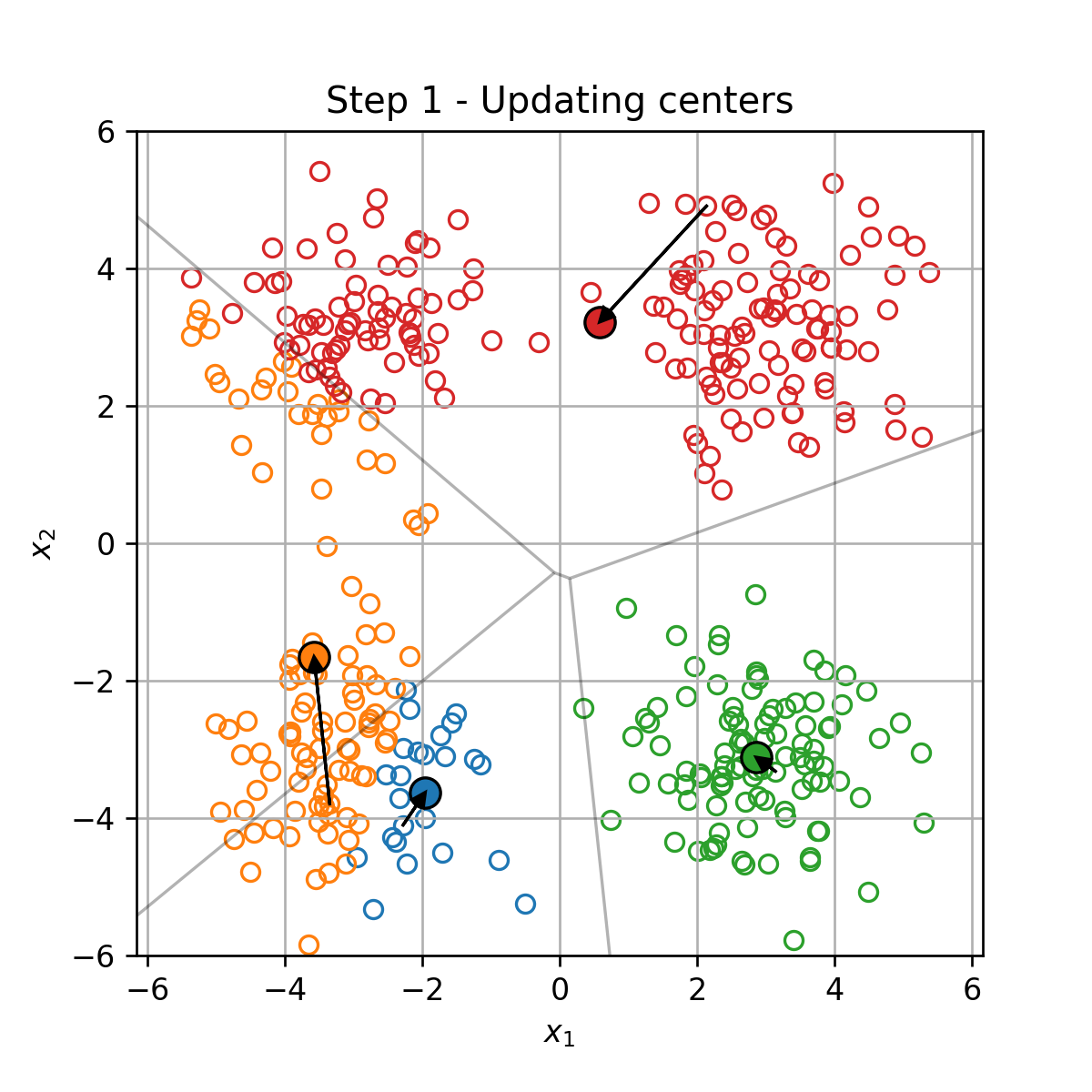
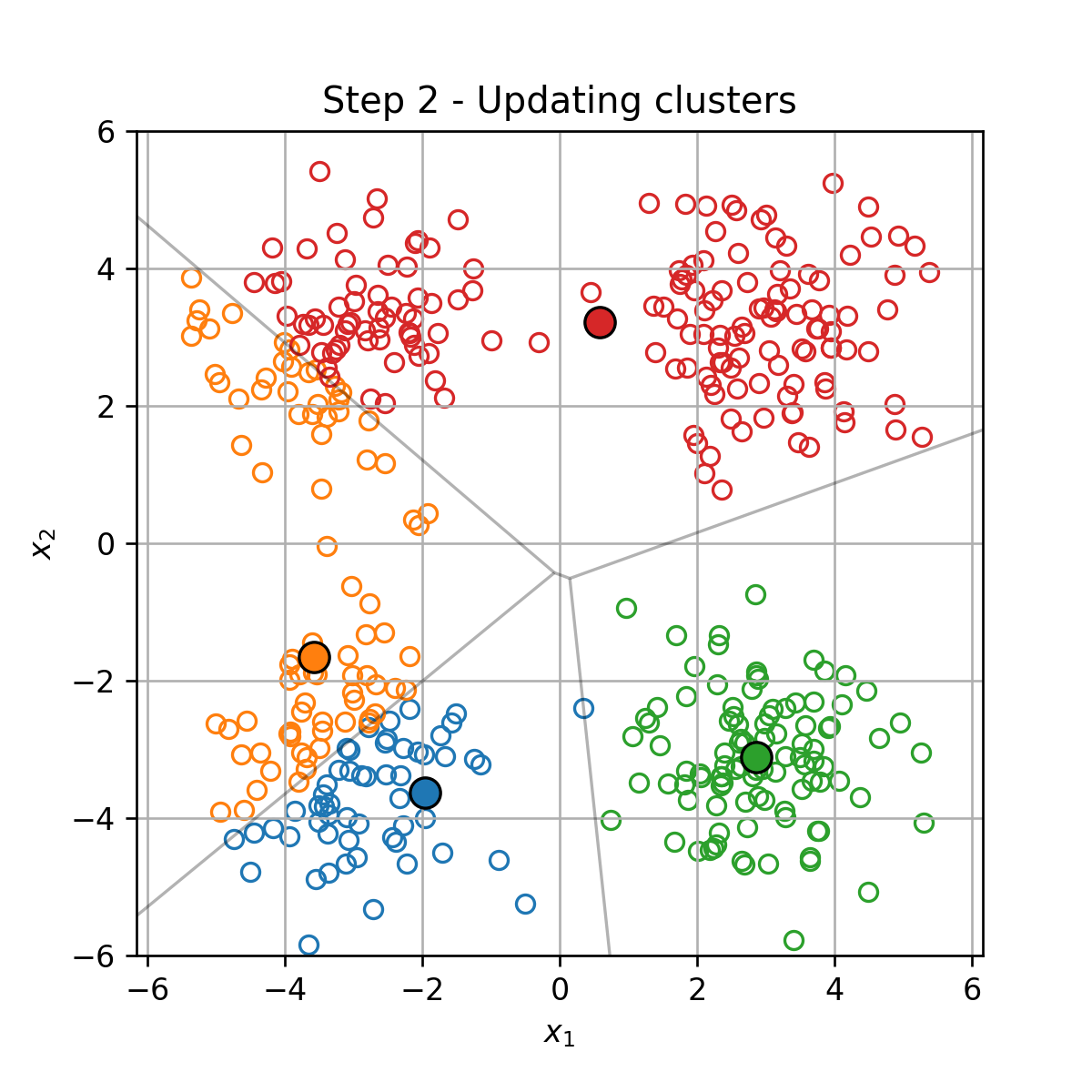
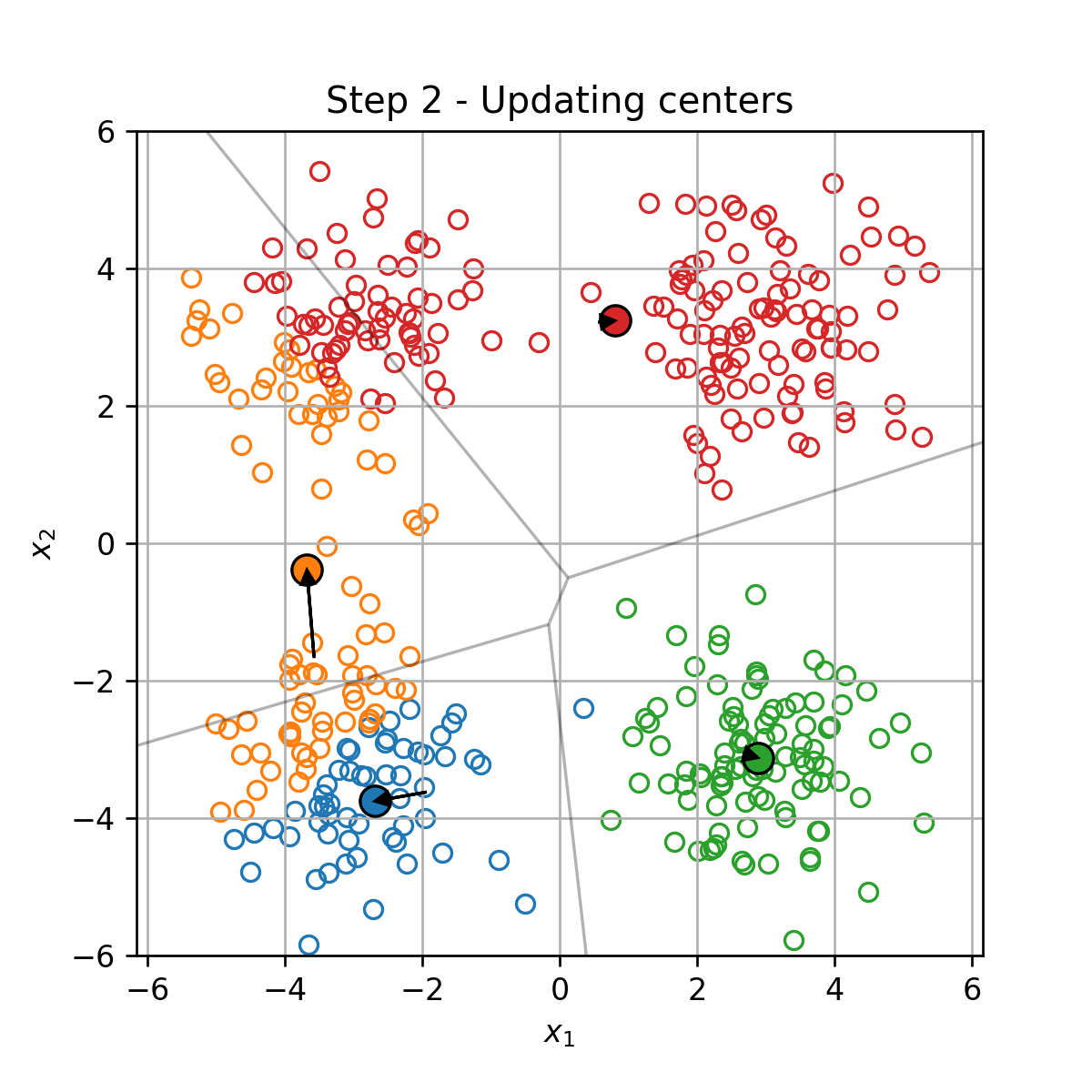
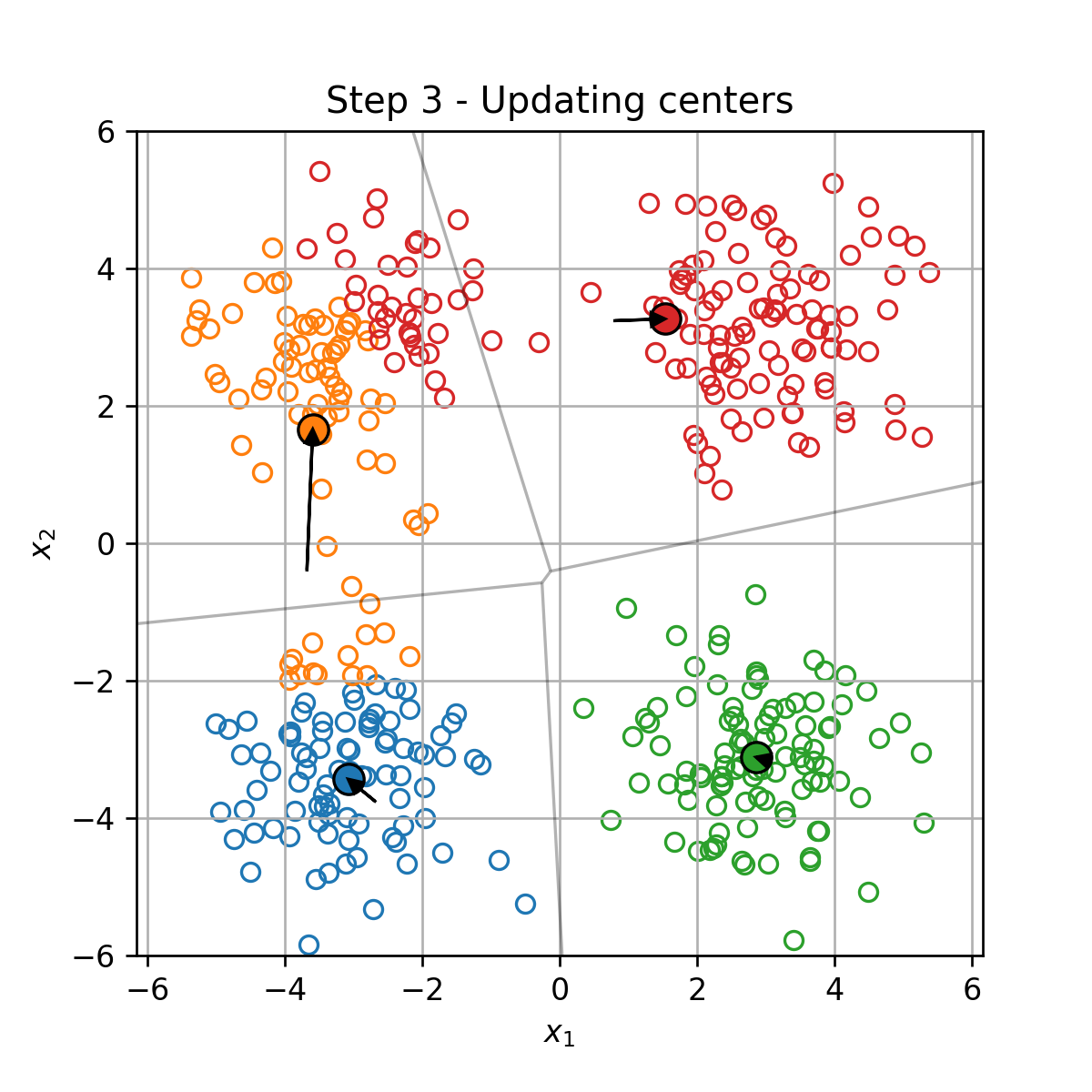
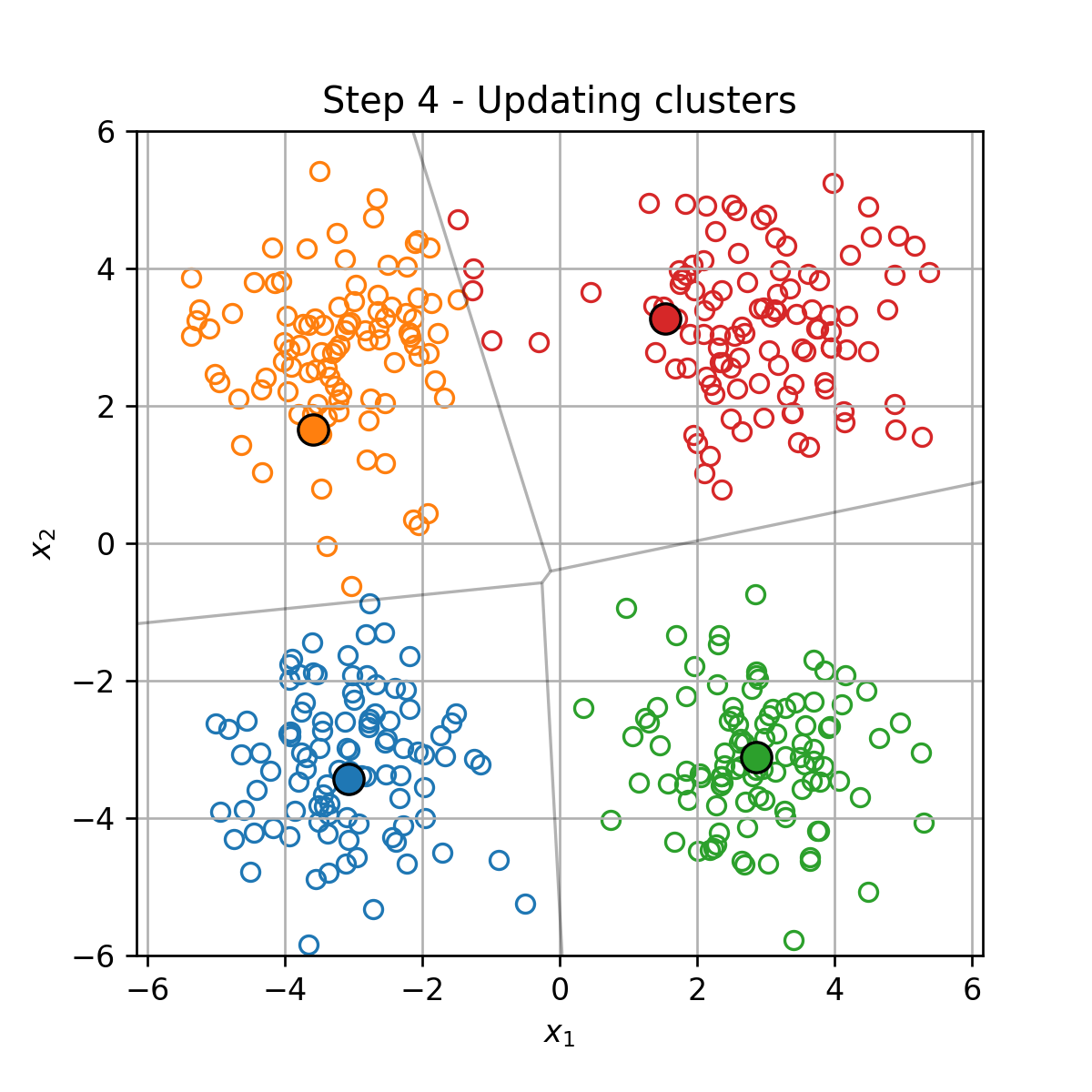
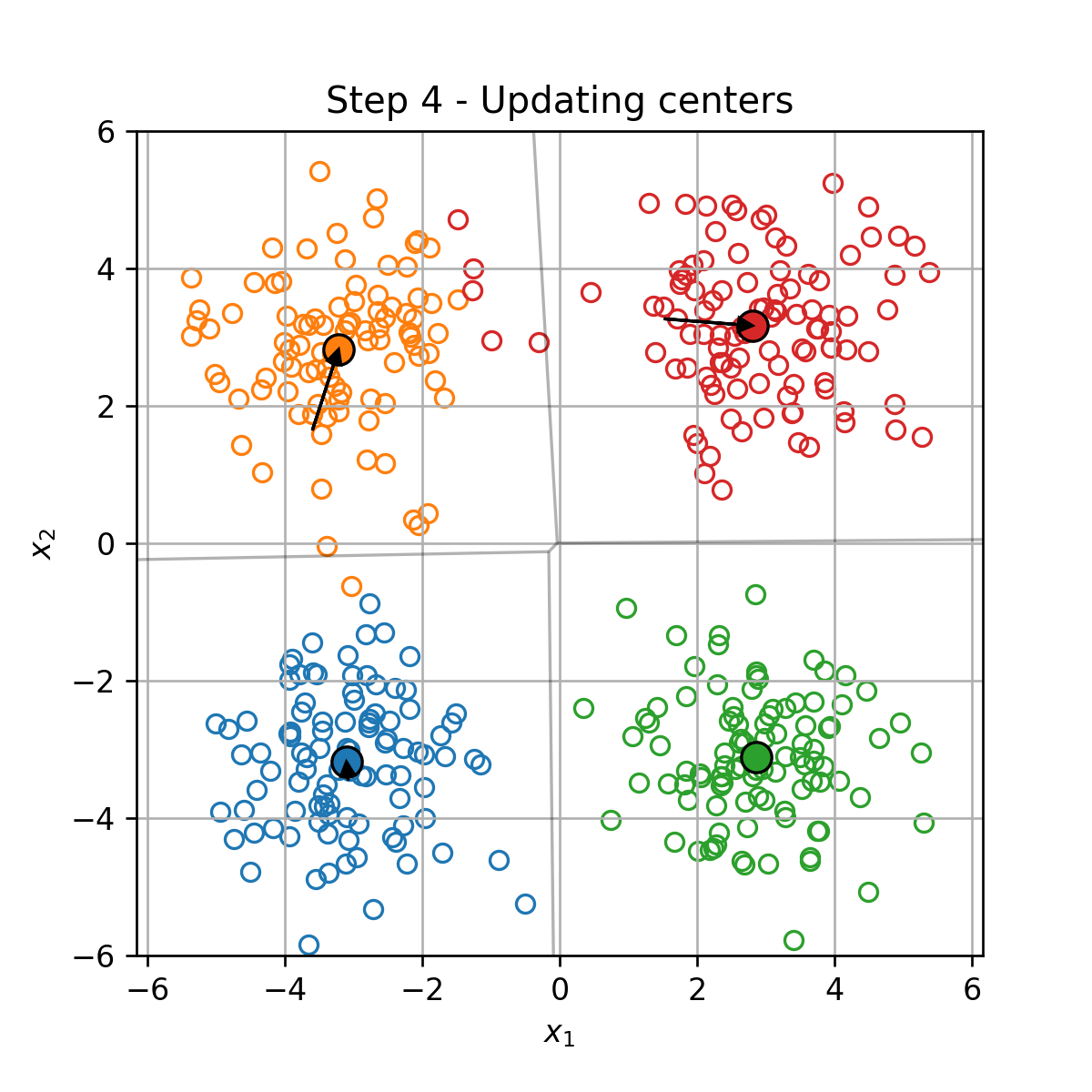
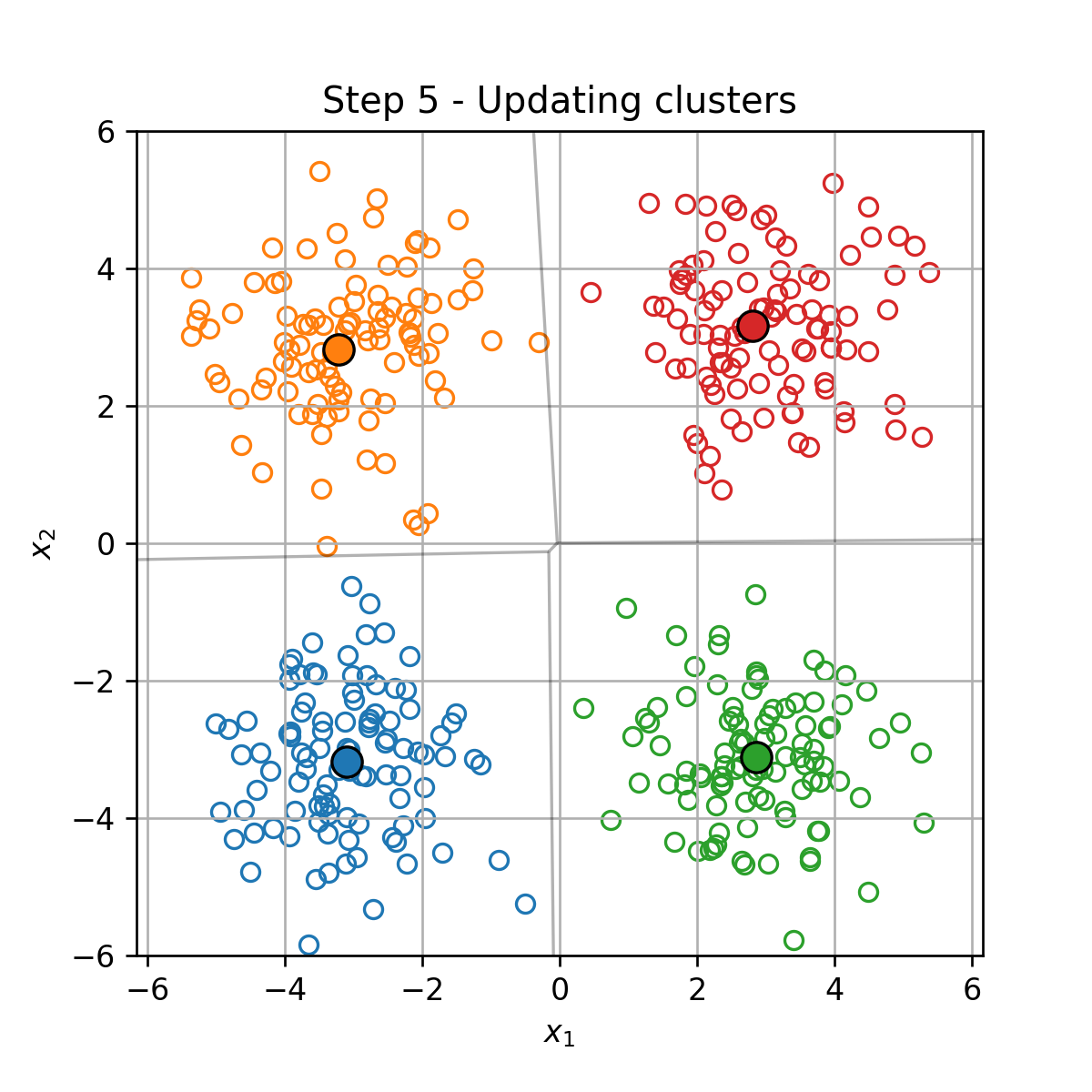
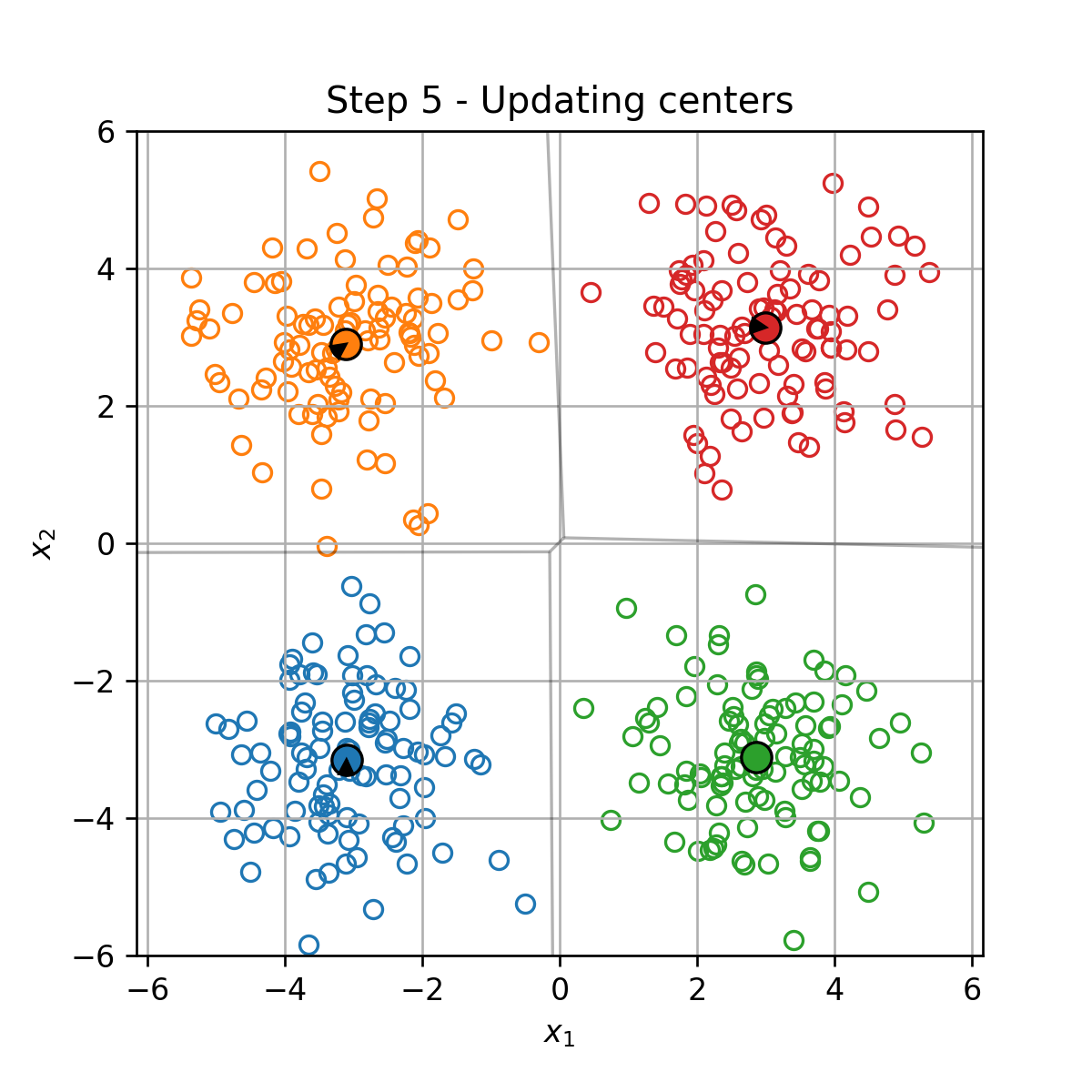
K-Means
K-Means הוא אלגוריתם אשכול אשר מנסה לחלק את הדגימות במדגם ל K קבוצות על סמך המרחק בין הדגימות.
סימונים
K - מספר האשכולות (גודל אשר נקבע מראש).
Ik - אוסף האינדקסים של האשכול ה-k. לדוגמא: I5={3,6,9,13}
∣Ik∣ - גודל האשכול ה-k (מספר הפרטים בקבוצה)
{Ik}k=1K - חלוקה מסויימת לאשכולות
בעיית האופטימיזציה
בהינתן מדגם D={x(i)}i=1N, K-Means מנסה למצוא את החלוקה לאשכולות אשר תמזער את המרחק הריבועי הממוצע בין כל דגימה לכל שאר הדגימות שאיתו באותו האשכול. זאת אומרת, K-means מנסה לפתור את בעיית האופטימיזציה הבאה: