הרצאה 10 - Neural Networks
מה נלמד היום

רשת נוירונים מלאכותית כמודל פרמטרי
במקומות רבים בתחום של מערכות לומדות נרצה למצוא פונקציה שתבצע פעולה מסויימת או תתאר תופעה מסויימת. בקורס זה ניסינו למצוא פונקציות שיבצעו פעולות חיזוי או שיתארו פילוגים של משתנים אקראיים, כמו כן ראינו כי דרך נוחה לעשות זאת היא על ידי שימוש במודל פרמטרי ומציאת הפרמטרים האופטימאלייים של המודל.
עד כה בעיקר עבדנו עם מודלים שהם לינאריים בפרמטרים של המודל. באופן תיאורטי יכול הייצוג של מודלים שכאלה היא בלתי מוגבלת שכן אנו יודעים לדוגמא נוכל לקרב הרבה מאד פונקציות עם פולינום מסדר מספיק גבוהה. הבעיה היא שבמרבית המקרים העבודה עם פולינומים מסדרים גבוהים היא לא מאד פרקטית. אחת הבעיות של פולינומים היא העובדה שכמות הפרמטרית היא מסדר גודל של האורך של וקטור הכניסה בחזקת סדר הפולינום: , כאשר הוא מאד גדול כמות הפרמטרים גדלה בקצב מאד מהיר עם סדר הפולינום. לדוגמא, בעבור תמונה יחסית קטנה של 100x100 פיקסלים למודל פרמטרי שהוא פולינום מסדר שלישי יהיו טריליון פרמטרים, שזה מספר לא ריאלי.
נשאלת אם כן השאלה האם ישנם מודלים מתאימים יותר.
נוירון ביולוגי
בשנים האחרונות מודלים פרמטריים המכונים רשתות נוירונים מלאכותיות (Artificial Neural Networks - ANNs) הוכיחו את עצמם כמודלים פרמטריים מאד יעילים לפתרון מגוון רחב של בעיות. הההשראה לצורה שבה המודלים הפרמטריים בנויים מגיעה מרשתות עצביות ביולוגיות כגון המוח ורשת העצבים. בצורה מאד פשטנית ניתן לתאר את האופן בו תא עצב (נוירון) ביולוגי פועל כך:
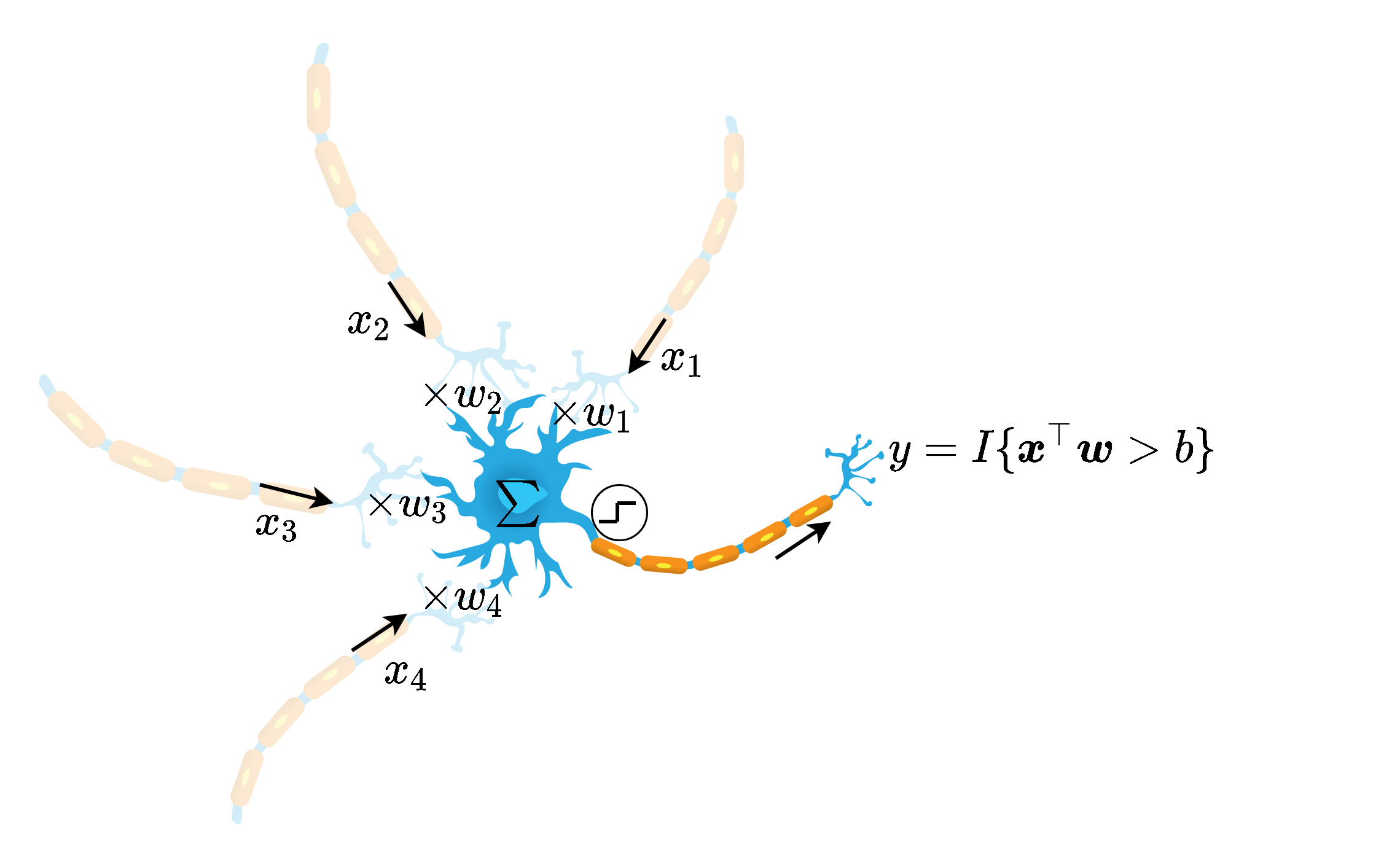
לנוירון האופייני ישנו איזור של "קולטנים" (Dendrites) אשר משמשים כקלט של הנוירון, ומעין זרוע אשר יכולה להתחבר ל"קולטנים" של ניורונים אחרים (אשר חיבורים הנקראים Axons) והיא משמשת לפלט של ההנוירון. הקלט והפלט של הנוירונים הוא פולסים חשמליים אשר הנוירונים יכולים לקבל ולשלוח אחד לשני. כל נוירון מסתכל על סך כל הפולסים שהוא מקבל מהנוירונים האחרים. כאשר סך כל הפולסים עובר ערך סף מסויים, הוא "יורה" פולס משלו למוצא של הנוירון.
התיאור הזה הוא מאד מופשט ומפספס הרבה מהמורכבויות של אופן פעולת הנוירונים אך הוא ההשראה למודל של רשתות נוירונים מלאכותיות. באופן סכימתי ניתן למדל את פעולת הנוירון באופן הבא:
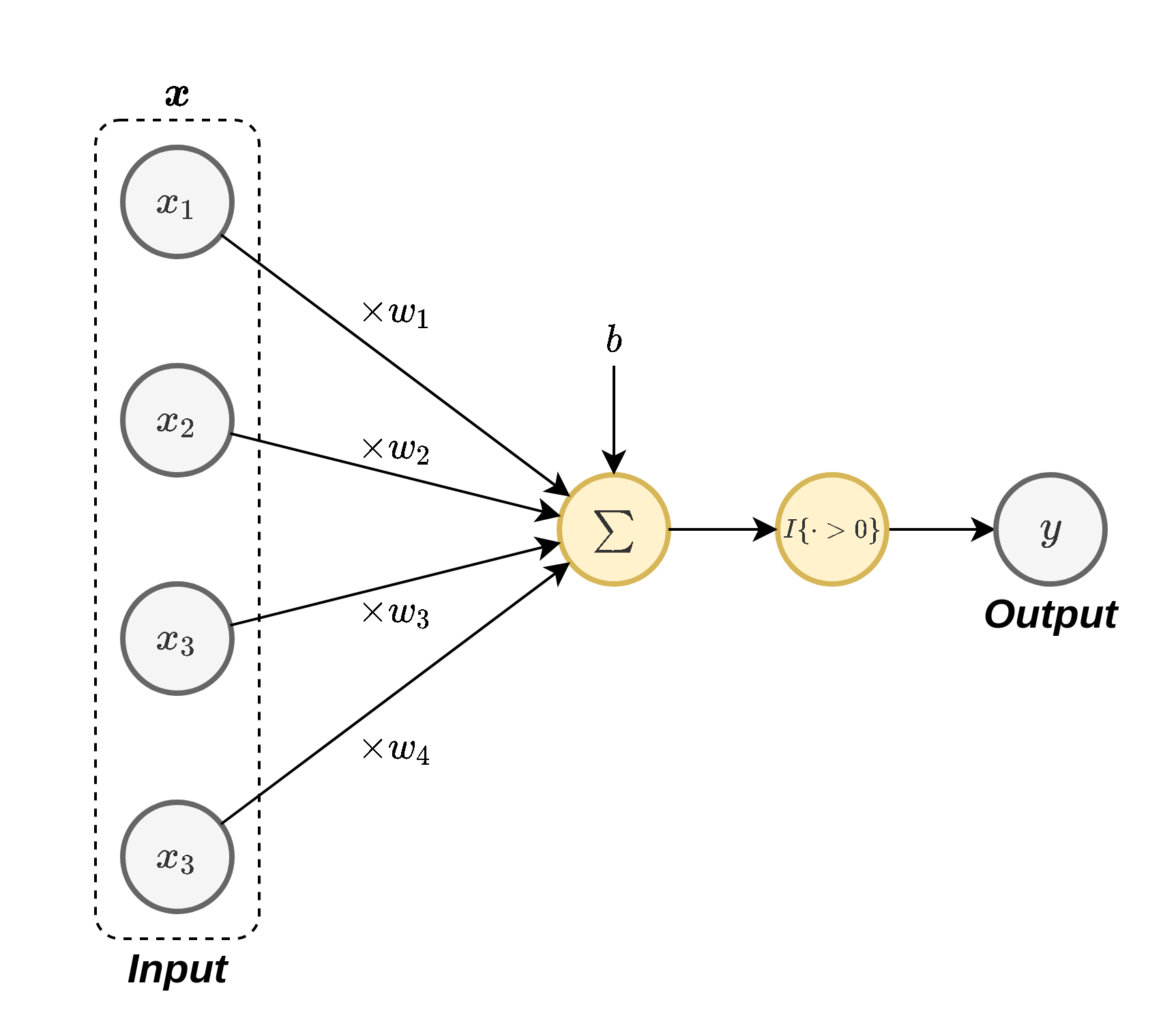
בשלב הראשון מחשבים קומבינציה לינארית של הכניסות עם משקלים כל שהם ובתוספת היסט ובשלב השני מעבירים את הקומבינציה הלינארית דרך פונקציית מדרגה אשר מוציאה 1 אם הקומבינציה הלינארית חיובית ו0 אחרת.
נוירונים ברשת נוירונים מלאכותית
המודל של הנוירון הביולוגי עומד בבסיס של המודל של רשתות נוירונים מלאכותיות אך עם תיקון קטן. לצורך של בניה ולימוד של מודל פרמטרי פונקציית המדרגה היא בפועל מאד בעייתית. זאת בעיקר משום שהיא מוסגלת להוציא רק ערכים בינאריים ובגלל העובדה שהנגזרת שלה היא 0 בכל מקום, מה שלא יאפשר לנו ללמוד את הפרמטרים של המודל שנבנה בעזרת gradient descent. לשם כך נחליף את פונקציית המדרגה בפונקציה אחרת כלשהיא . פונקציה זו מכונה פונקציית ההפעלה (activation function). בחירות נפוצות של פונקציית ההפעלה כוללות את
- הפונקציה הלוגיסטית (סיגמואיד):
- טנגנס היפרבולי:
- פונקציית ה ReLU (Rectified Linear Unit): אשר מוגדרת (זוהי פונקציית ההפעלה הנפוצה ביותר כיום).
פונקציות נוספות אשר נמצאות כיום בשימוש, כוללות כל מיני וריאציות שונות שנעשו על פונקציית ה ReLU.
באופן סכימתי נסמן נוירון בודד באופן הבא:
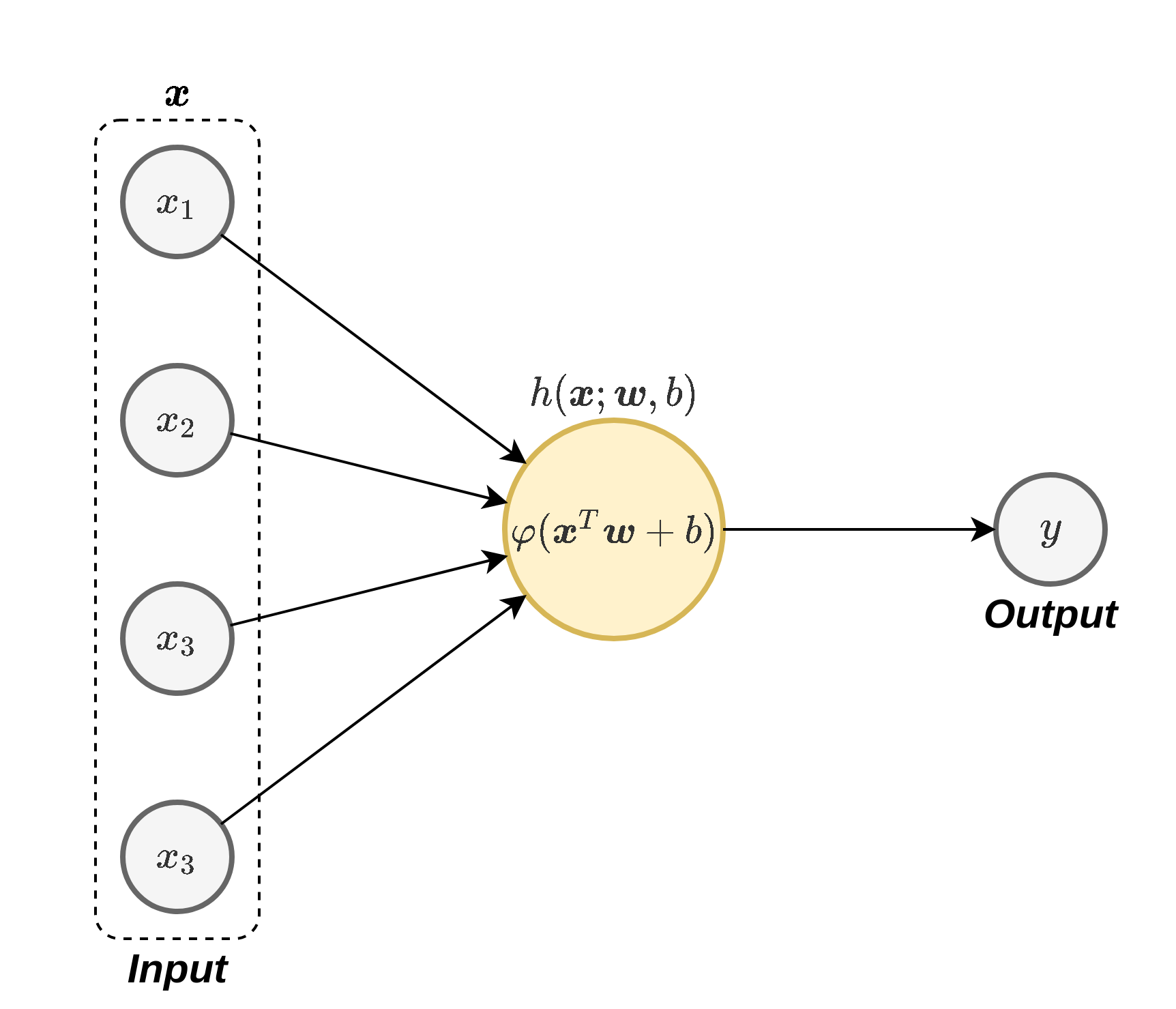
כאשר סימנו את הפונקציה שאותה מבצע הנוירון ב עם פרמטרים ו . נרצה כעת להשתמש במודל של הנוירון בודד כדי לבנות רשת המורכבת ממספר נוירונים אשר בעזרתה נוכל למדל פונקציות מורכבות.
רשת נוירונים
בדומה למקרה הביולוגי, לנוירון בודד אין הרבה שימוש, אך כאשר משלבים מספר רב של נוירונים ניתן לייצג בעזרתם פונקציות מאד מורכבות. בדומה לרשתות הביולוגיות אנו נחבר את הנוירונים כך שהמוצאים של הניורונים ישמשו ככניסות של נוירונים אחרים כפי שמתואר בשרטוט הבא:
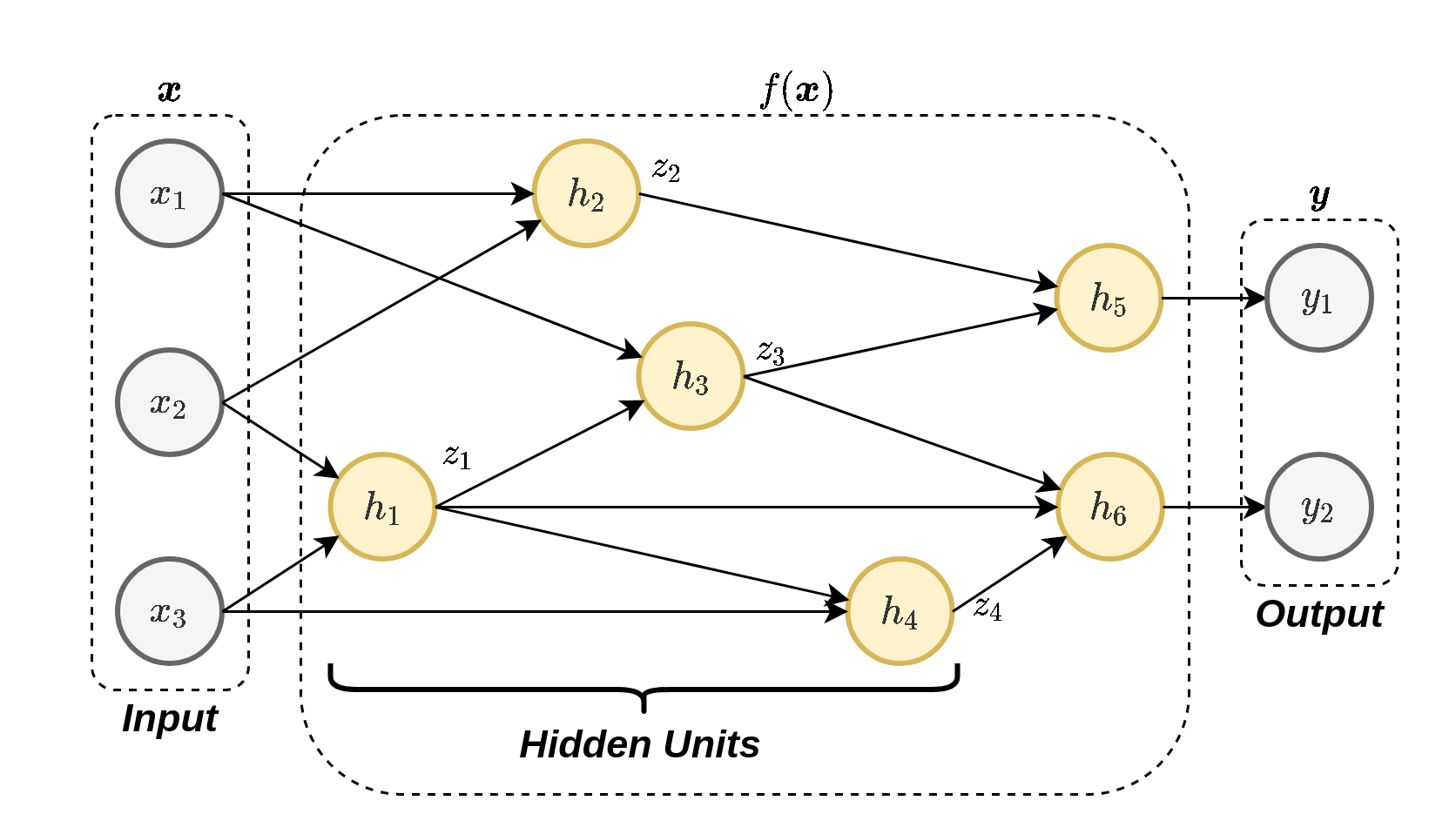
על ידי בניית רשת שכזו ניתן לקבל מודל פרמטרי בעלי יכולת לקרב מגוון מאד רחב של פונקציות. הפרמטרים של המודל יהיו אוסף כל הפרמטרים של כל הנוירונים ברשת. לרוב הנוירונים אשר מרכיבים את הרשת יהיו מצורה שהצגנו קודם:
אך באופן כללי ניתן גם לבחור לבנות את הרשת מפונקציות אחרות. בקורס זה, אלא אם נאמר אחרת, אנו נניח כי כי הנוירונים הם מהצורה שהופיעה לעיל. לשם הנוחות, אנו נסמן לרוב (בדומה לשאר הקורס) ב את הוקטור אשר מכיל את כל הפרמטרים של המודל:
הארכיטקטורה של הרשת
המבנה של הרשת כולל את מספר הנוירונים שהיא מכילה ואת הדרך שבה הם מחוברים אחד לשני נקרא הארכיטקטורה של הרשת. בחירת הארכיטקטורה של הרשת היא קריטית מאד לטיב הביצועים שנקבל ולשימושים שונים מתאימות ארכיטקטורות שונות. חלק גדול מאד מהמחקר שנעשה כיום בתחום הוא סביב הנושא של חיפוש ארכיטקטורות אשר מניבות תוצאות טובות יותר לשימושים ספציפיים. התהליך של מציאת הארכיטקטורה שמתאימה לבעיה דורש לא מעט ניסיון, אינטואיציה, והרבה ניסוי וטעיה כנגד ה validation set. לרוב הדרך הטובה ביותר לבחור ארכיטקטורה היא למצוא בעיה דומה לבעיה שאותה ברצונכם לפתור והשתמש בארכיטקטורה שעבדה טוב במקרה זה (לרפרנס).
נגדיר שני מושגים אשר קשורים לארכיטקטורה של הרשת:
- יחידות נסתרות (hidden units): הנוירונים אשר אינם מחוברים למוצא הרשת (אינם נמצאים בסוף הרשת).
- רשת עמוקה (deep network): רשת אשר מכילה מסלולים מהכניסה למוצא, אשר עוברים דרך יותר מיחידה נסתרת אחת.
לדוגמא, ברשת בשרטוט מעל הנוירונים עד הם יחידות ניסתרות והרשת נחשבת לרשת עמוקה משום שהמסלול שעובר דרך , ו עובד דרך שתי יחידות נסתרות.
Feed-forward vs. Recurrent
אנו מבדילים בין שני סוגי ארכיטקטורות:
- רשת הזנה קדמית (feed-forward network): ארכיטקטורות אשר אינן מכילות מסלולים מעגליים. ברשתות אלו ניתן להגדיר את הכיוון בו זורם המידע מהכניסה ליציאה ואת הסדר של הנוירונים ברשת. רוב הרשתות אשר נמצאות בשימוש בכיום הם מסוג זה.
- רשתות נשנות (recurrent neural network - RNN): בקורס זה לא נעסוק ברשתות מסוג זה, נציין רק שאלו ארכיטקטורות אשר כן מכילות מסלולים מעגליים. רשתות אלו יכילו לרוב גם רכיבי זיכרון (בדומה ל registers במעגלים חשמליים) והם יתאימו למקרים בהם מאד ארוך, כמו לדוגמא במקרה של אות אודיו ארוך.
על החשיבות של פונקציות ההפעלה
ללא פונקציות ההפעלה, הנוירונים פשוט יחשבו קומבינציות לינאריות של הקלט שהם מקבלים. מכיוון שכל הרכבה של פונקציות לינאריות עדיין נשארת פונקציה לינארית, אנו נקבל שהרשת תמיד תוכל לייצג רק פונקציות לינאריות, ללא תלות בארכיטקטורה שאותה נבחר. לכן חוסר הלינאריות של פונקציות ההפעלה הוא למעשה מה שמאפשר בפועל לרשתות הנוירונים לייצג מגוון עשיר של פונקציות.
המוצא של הרשת
Regression + ERM
כאשר נשתמש ברשת לפתרון של בעיות רגרסיה בשיטת ERM, אנו נרצה שהרשת תמדל את החזאי אשר אמור להוציא סקלר אשר מקבל ערכים רציפים, לרוב בתחום לא מוגבל. במקרה זה אנו נרצה שהמוצא של הרשת יתנקז לנוירון בודד ללא פונקציית אקטיבציה (על מנת שלא להגביל את המוצא של הרשת).
בעיות סיווג בגישה הדיסקרימינטיבית הסתברותית
לסיווג בינארי, בגישה הדיסקרימינטיבית ההסתברותית, אנו נרצה למדל את . לכן, אנו נרצה שהרשת תוציא ערך סקלרי רציף בתחום בין 0 ל-1. לכן גם פה אנו נרצה שהמוצא של הרשת יתנקז לנוירון בודד עם פונקציית הפעלה אשר מוציאה ערכים בתחום כדוגמאת הפונקציה הלוגיסטית. (ניתן לחילופין לחשב על המודל כעל רשת ללא פוקציית הפעלה במוצא אשר מפעילים על המוצא של הרשת את הפונקציה לוגיסטית על מנת לקבל הסתברות חוקית).
בסיווג לא בינארי של מחלקות, בגישה הדטרמיניסטית ההסתברותית, אנו נרצה למדל את כל ההסתברויות של . לכן אנו נרצה שהרשת תוציא וקטור באורך שעליו נפעיל את פונקציית ה softmax, על מנת לקבל וקטור הסתברות חוקי.
מציאת הפרמטרים של המודל
כתלות בבעיה אותה אנו מנסים לפתור, והשיטה שבה אנו משתמשים, אנו נרשום את בעיית האופטימיזציה שאותה אנו רוצים לפתור. בהקשר של השיטות הרלוונטיות בקורס זה:
- ב ERM אנו ננסה למזער את ה risk האמפירי.
- בגישה הדיסקרימינטיבית ההסתברותית נשתמש ב MLE או MAP.
בדומה למקרה של logistic regression גם כאן לרוב לא נוכל לפתור את בעיית האופטימיזציה על ידי גזירה והשוואה ל-0 ובמקום זה נחפש פתרון על ידי שימוש ב gradient descent. בשביל לחשב את הגרדיאנט לפי הפרמטרים אנו נעזר בשיטה שנקראת back-propagation, אותה נציג בהמשך ההרצאה הזו.
עבור רשת את מואצה נסמן בתור .
רגרסיה: לדוגמה, פונקציית ההפסד של least squares היא
סיווג בינארי: במקרה של רגרסיה לוגיסטית ניתן להשתמש בפונקציה מהרצאה 9:
עם פונקציית הסיגמואיד .
במקרה של סיווג רב מחלקתי , ניתן להשתמש בפונקציית softmax ופונקציית ההפסד מהרצאה 9.
MultiLayer Perceptron (MLP)
נתמקד כעת בארכיטקטורה מאד נפוצה אשר נקראת MultiLayer Perceptron (MLP). בארכיטקטורה זו הנוירונים מסודרים בשתי שכבות (layers) או יותר, המכונות Fully Connected (FC) layers. בהן כל נוירון מוזן מכל הנוירונים שבשכבה שלפניו. לדוגמא:
מה שמגדיר את הארכיטקטורה במקרה של MLP הוא מספר השכבות וכמות הנוירונים בכל שכבה. כמות הנוירונים בכל שכבה מכונה לרוב הרוחב של השכבה. בדוגמה הזו, יש ברשת 3 שכבות ברוחב 2, 3 ו 2.
רישום מטריצי
בשרטוט מעל סימנו את הנוירון ה בשכבה ה ב ואת המוצא שלו ב . בנוסף, סימנו את הוקטור המכיל את כל המוצאים בשיכבה ה ב . נסמן גם את הפרמטרים של הנוירון ה ב ו . הפונקציה שאותה מבצע כל נוירון הינה:
כדי לרשום את הפעולה שמבצעת כל שיכבה בצורה מטריצית נגדיר את המטריצה אשר מאגדת את כל הוקטורים באותה שכבה:
ונגדיר באופן דומה את הוקטור אשר מאגד את כל הפרמטרים באותה שכבה:
נוכל כעת לרשום את הפעולה שמבצעת כל השכבה כולה באופן הבא:
כאשר פונקציית ההפעלה פועלת על וקטור איבר-איבר.
עבור MLP כללי עם שכבות ניתן לכתוב
כאשר
שימו לב, יכולה להיות תלויה בשכבה.
ניתן לכתוב זאת בצורה רקורסיבית
כאשר פעולת האקטיבציה מתבצעת איבר-איבר ו-.
הערה לגבי נגזרות וקטוריות
זכרו כי עבור פונקציה סקלרית
תהי פונקציה וקטורית של וקטור , , .
אזי
ובמקרה הפשוט בו מתקיים כי
מקור השם
השם Perceprton מתייחס לאלגוריתם / שיטה ישנה אשר אינה נלמדת בקורס זה. ה Perceptron היה אחד הנסיונות הראשונים למדל נוירון ולהשתמש בו לפתרון בעיות במערכות לומדות אך ההצלחה שלו הייתה מאד מוגבלת. למרות שהשם MLP עשוי לרמוז אחרת, אין באמת קשר בין אלגוריתם / מודל ה Perceptron לארכיטקטורת ה MLP שתיארנו כאן. (אם אתם רוצים להשתכנע תוכלו לשמוע פה את Geoffrey Hinton, שנתן לארכיטקטורה זו את שמה, אומר זאת בעצמו).
יכולת היצוג של MLP - "משפט הקירוב האוניברסלי"
המשפט הבא מובא ללא הוכחה והוא מתייחס ליכולת של MLP עם שיכבה ניסתרת אחת לקרב כל פונקציה חסומה ורציפה:
בהינתן:
- כל פונקציית הפעלה רציפה שאינה פולינומיאלית (או כזו חסומה ואינטגרבילית).
- וכל פונקציה רציפה על קוביית היחידה .
אזי:
ניתן למצוא פונקציה מהצורה (MLP עם שיכבה נסתרת אחת):
כך ש:
הערה: משפט זה לא מגביל את הרוחב של השכבה הנסתרת וכמובן שככל שהפונקציה מורכבת יותר כך נצטרך לרוב שכבה רחבה יותר. משפט זה הוא בעיקר יעיל כדי להבין את יכולת הייצוג החזקה של רשתות ניורונים, והוא לא מאד שימושי ליישומים פרקטיים.
Back-Propagation
באופן כללי אנו צריכים לחשב את הנגזרות של פונקציית ההפסד ביחס לכל פרמטרי הרשת (משקולות ואיברי הטיה), כלומר
כאשר הם המשקולות של השכבה ה-. שימו לב כי
כאשר הנגזרת המאתגרת היחידה לחישוב היא הראשונה.
כפי שציינו קודם, לרוב אנו נמצא את הפרמטרים של המודל בעזרת gradient descent. כדי להקל על החישוב של הנגזרות של ה objective לפי הפרמטרים אנו נשתמש בשיטה הנקראת back-propagation אשר מחשבת את הגרדיאנטים על ידי שימוש בכלל השרשרת.
כלל השרשרת מפרק את הנגזרת של הרכבה של פונקציות למכפלה של הנזגרות של הפונקציות. במקרה של משתנה יחיד היא נראית כך:
במקרה של מספר משתנים הוא נראה כך:
אנו נראה שעל מנת לחשב את הנגזרות לפי הפרמטרים של הנוירונים ברשת אנו נצטרך לבצע 2 שלבים:
- Forward pass: העברה של הדגימות במדגם דרך הרשת ושמירה של כל ערכי הביניים (המוצאים של כל הנוירונים).
- Backward pass: חישוב של הנגזרות של הנוירונים מהמוצא של הרשת לכיוון הכניסה.
על מנת להסביר את השיטה נסתכל על 2 דוגמאות.
דוגמא פשוטה
נרצה לחשב את עבור פרמטר כלשהו. למשל, עבור פונקציית ההפסד הריבועית כאשר הוא הערך האמיתי
ובאופן דומה עובר שאר פונקציות ההפסד. כך, עלינו להתמקד בנגזרת זאת.
נתחיל ראשית במקרה סקלרי פשוט שבו יש 4 פונקציות פרמטריות שמורכבות אחת אחרי השניה:

נרשום את הנגזרת של לפי . על פי כלל השרשרת נוכל לרשום את הנגזרת באופן הבא:
נוכל לפרק גם את הנגזרת של לפי כלל השרשרת:
לכן:
כדי לחשב את הביטוי שקיבלנו עלינו לבצע את שני השלבים הבאים:
- לחשב את כל ה לאורך הרשת (forward pass).
- לחשב את כל הנגזרות מהמוצא של הרשת ועד לנקודה בה נמצא הפרמטר שלפיו רוצים לגזור (backward-pass).
דוגמא מעט יותר מורכבת
נסתכל על הרשת הבאה:
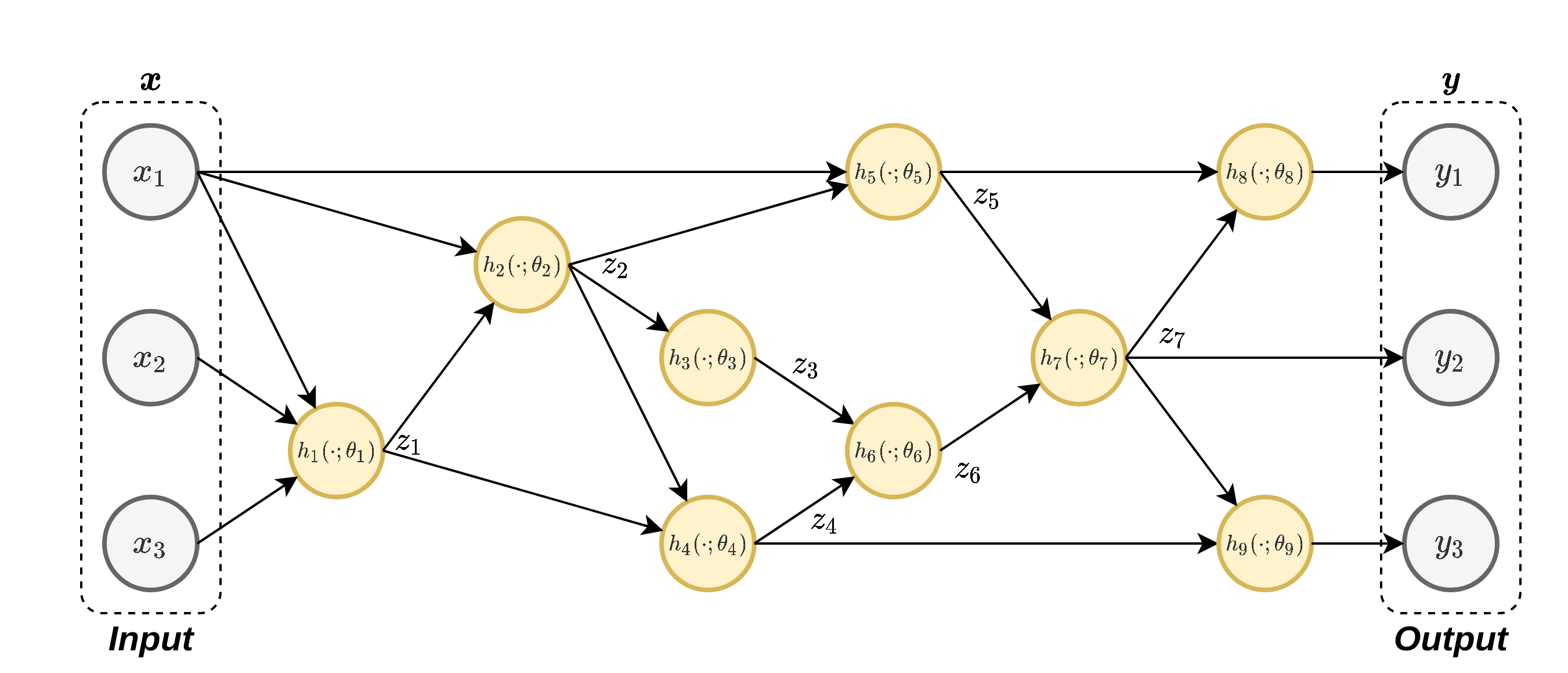
נחשב לדוגמא את הנגזרת של לפי .
נפרק על פי כלל השרשרת את הנגזרת של בדומה למה שחישבנו קודם:
- נריץ את ה forward-pass בשביל לחשב את ערכי ה .
- נריץ את ה backward-pass בו נחשב את הנגזרות מהמוצא של הרשת עד לנגזרת של .