הרצאה 9 - גישה דיסקרימינטיבית הסתברותית
דוגמא לבעיה בגישה הגנרטיבית פרמטרית
נסתכל שוב על הבעיה של חיזוי עסקאות שחשודות כהונאות:
התאמה של מודל QDA
py(0)=N∣I0∣=0.81
py(1)=N∣I1∣=0.19
μ0=∣I0∣1i∈I0∑x(i)=[55.1,54.6]⊤
μ1=∣I1∣1i∈I1∑x(i)=[54.4,55.2]⊤
Σ0=∣I0∣1i∑(x(i)−μy(i))(x(i)−μy(i))T=[350.9−42.9−42.9336]
Σ1=∣I1∣1i∑(x(i)−μy(i))(x(i)−μy(i))T=[817.9730.5730.5741.7]
התאמה של מודל QDA
שגיאת החיזוי (miscalssification rate) על ה test set הינה 0.08.
התוצאה סבירה, אך ניתן לראות שגאוסיאן לא מאד מתאים לפילוג של ההונאות.
הבעיה של הגישה הגנרטיבית פרמטרית
- היינו רוצים מודל אשר יכול לייצג בנפרד את שני האיזורים.
- לצערנו המבחר של המודלים בהם אנו יכולים לא גדול.
- המגבלה הזו נובעת מהצורך שהמודל ייצג פילוגים חוקיים.
הערה: במקרה זה ניתן להשתמש ב GMM + EM.
דוגמא למדגם שמתאים למודל של QDA
לצורך הדגמה נסתכל על גירסא של המדגם שבה יש רק איזור אחד של ההונאות:
מודל QDA
שגיאת החיזוי (miscalssification rate) על ה test set במקרה הזה הינה 0.
מודל LDA
רק לשם השוואה, נציג גם את התוצאה המתקבלת ממודל ה LDA:
הגישות שראינו עד כה
הגישה הדיסקרימינטיבית
מדגם
▼
חזאי בעל ביצועים טובים על המדגם
הגישה הגנרטיבית
מדגם
▼
הפילוג המשותף של x ו y על סמך המדגם
▼
חזאי אופטימלי בהינתן הפילוג המשותף
הגישה הדיסקרימינטיבית הסתברותית
ברוב פונקציות המחיר החזאי האופטימאלי יהיה תלוי רק בפילוג המותנה של y בהינתן x.
הגישה הדיסקרימינטיבית הסתברותית
מדגם
▼
הפילוג המותנה של y בהינתן x על סמך המדגם
▼
חזאי אופטימלי בהינתן הפילוג המותנה
ההתייחסות לגישה זו במקרות אחרים
- גישה זו מוכוונת ישירות למציאת החזאי ולא מנסה ללמוד את התכונות של המדגם לכן נחשבת לגישה דיסקרימינטיבית.
- השם גישה דיסקרימינטיבית הסתברותית לא מופיע במקרים אחרים.
- במרבית המקרים מציינים שיש שתי גישות דיסקרימינטיבית אך לא נותנים להם שמות שונים.
שימוש במודלים פרמטריים
- אנו נבחר מודל פרמטרי אשר יתאר את הפילוג המותנה, py∣x(y∣x).
- נשערך את פרמטרים של המודל בשיטות דומות לגישה הגנרטיבית (MLE ו MAP).
MLE על הפילוג המותנה
θ∗=θargmin −i=1∑Nlog(px,y(x(i),y(i);θ))=θargmin −i=1∑Nlog(py∣x(y(i)∣x(i);θ)px(x(i)))=θargmin −i=1∑Nlog(py∣x(y(i)∣x(i);θ))−i=1∑Nlog(px(x(i)))=θargmin −i=1∑Nlog(py∣x(y(i)∣x(i);θ))
- המשמעות היא ש אין צורך לדעת או לשערך את הפילוג של x.
- ניתן להגיע לאותה תוצאה גם עבור משערך MAP.
- שימו לב שהפילוג השולי של x אינו משפיע על הסיווג.
היתרון של הדיסקרימינטיבית הסתברותית
px,y(x,y) צריכה לקיים את התנאים הבאים:
- px,y(x,y;θ)≥0∀x,y,θ
- ∫∫px,y(x,y;θ)dxdy=1∀θ
עבור בעיות סיווג py∣x(y∣x) צריכה לקיים את התנאים הבאים:
- py∣x(y∣x;θ)≥0∀x,y,θ
- ∑y=1Cpy∣x(y∣x;θ)=1∀x,θ
האינטגרל על כל הערכים התחלף בסכום סופי של איברים.
נראה כעת כיצד ניתן לבנות מודלים המקיימים תנאים אלו.
סיווג בינארי
עבור התנאי השני יהיה:
py∣x(0∣x;θ)+py∣x(1∣x;θ)=1∀x,θ
דרך פשוטה לקיים תנאי זה הינה למצוא פונקציה f(x;θ) אשר מחזירה ערכים בין 0 ל 1 ולהגדיר את המודל באופן הבא:
py∣x(1∣x;θ)py∣x(0∣x;θ)=f(x;θ)=1−f(x;θ)
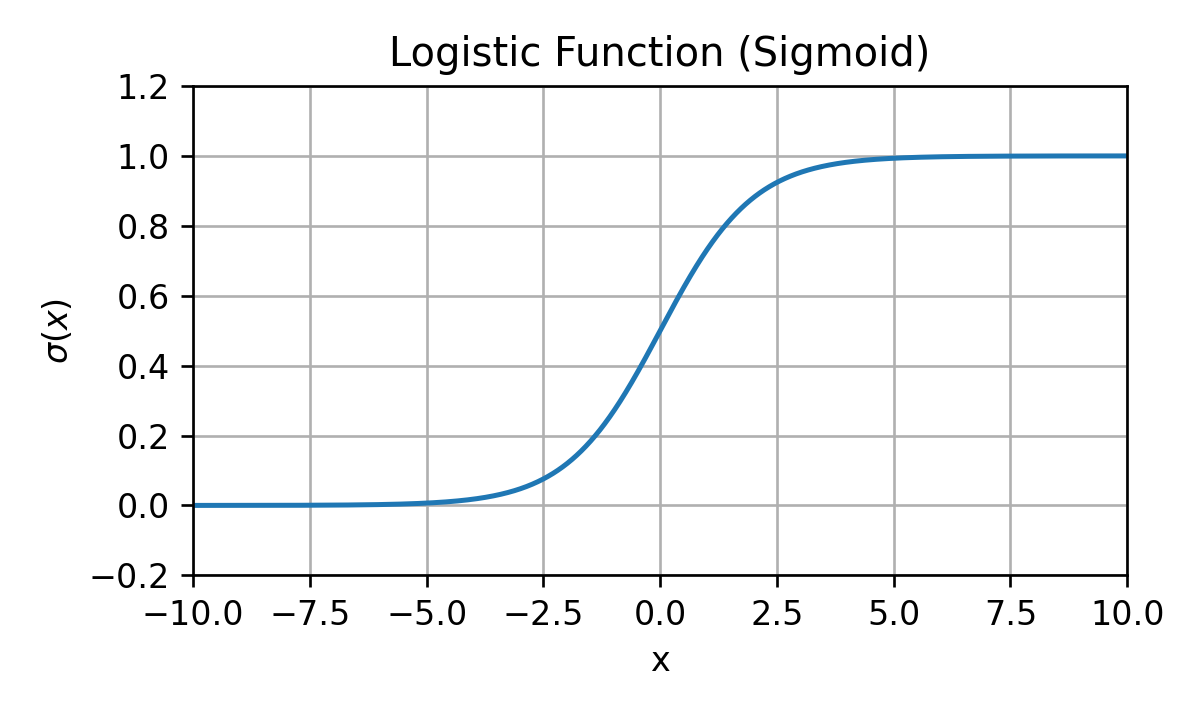
הפונקציה הלוגיסטית
σ(z)=1+e−z1
הערה: מקובל לכנות את הפונקציה הזו סיגמואיד (sigmoid).
הפונקציה הלוגיסטית
כל מודל פרמטרי מהצורה:
py∣x(1∣x;θ)py∣x(0∣x;θ)=σ(f(x;θ))=1−σ(f(x;θ))
יהיה מודל פרמטרי חוקי עבור f שמקבלת ערכים חיוביים ושליליים.
תכונות
- רציפה
- מונוטונית עולה
- 1−σ(z)=σ(−z)
- dzdlog(σ(z))=1−σ(z)
Binary Logistic Regression
ב Binary Logistic Regression (כלומר, y∈{0,1}) נשתמש במודל שהצגנו קודם:
py∣x(1∣x;θ)py∣x(0∣x;θ)=σ(f(x;θ))=1−σ(f(x;θ))
נמצא את הפרמטרים של המודל בעזרת MLE:
θ∗=θargmin −i=1∑Nlog(py∣x(y(i)∣x(i);θ))=θargmin −i=1∑NI{y(i)=1}log(σ(f(x(i);θ)))+I{y(i)=0}log(1−σ(f(x(i);θ)))=θargmin −i=1∑Ny(i)log(σ(f(x(i);θ)))+(1−y(i))log(1−σ(f(x(i);θ)))
Binary Logistic Regression
θ∗=θargmin −i=1∑Ny(i)log(σ(f(x(i);θ)))+(1−y(i))log(1−σ(f(x(i);θ)))
במרבית המקרים לא ניתן יהיה לפתור באופן אנליטי ונחפש את הפתרון בשיטות נומריות כגון אלגוריתם ה gradient descent עליו נרחיב בהמשך ההרצאה.
הערה: בגישה הגנרטיבית שתארנו גם לא ניתן בד"כ לחשב אנליטית את פתרון הסבירות המרבית. במקרה הגאוסי זה ניתן כמו שראינו.
Binary Logistic Regression
py∣x(1∣x;θ)py∣x(0∣x;θ)=σ(f(x;θ))=1−σ(f(x;θ))
עבור misclassification rate החזאי האופטימאלי יהיה:
h(x)=yargmax py∣x(y∣x;θ)={10σ(f(x;θ))>0.5else={10f(x;θ)>0else
סיווג לא בינארי
ניתן להרחיב את השיטה לבניית מודלים באמצעות פונקציית ה softmax.
פונקציית ה Softmax
לוקחים וקטור z באורך C ומייצרים ממנו וקטור אשר יכול לייצג פילוג דיסקרטי חוקי.
softmax(z)=∑c=1Cezc1[ez1,ez2,…,ezC]⊤
או פונקציה עם טווח רב-ממדי:
softmax(z)i=∑c=1Cezcezi
פונקציית ה Softmax
softmax(z)i=∑c=1Cezcezi
תכונות
- softmax(z+a)i=softmax(z)i ∀i.
- ∂zj∂log(softmax(z))i=δi,j−softmax(z)j
הפונקציה הלוגיסטית כמקרה פרטי
עבור וקטור באורך 2: z=[a,b], נקבל:
softmax(z)1softmax(z)2=ea+ebea=1+eb−a1=σ(a−b)=ea+ebeb=1−σ(a−b)
(Non-Binary) Logistic Regression
עבור C פונקציות פרמטריות כלשהן, fc(x;θc), ניתן לבנות מודל פרמטרי חוקי באופן הבא:
py∣x(y∣x;θ)=∑c=1Cefc(x;θc)efy(x;θy)
לשם נוחות נסמן:
- θ=[θ1⊤,θ2⊤,…,θC⊤]⊤.
- f(x;θ)=[f1(x;θ1),f2(x;θ2),…,fC(x;θC)]⊤
נוכל לרשום את המודל הפרמטרי באופן הבא:
py∣x(y∣x;θ)=softmax(f(x;θ))y
(Non-Binary) Logistic Regression
py∣x(y∣x;θ)=softmax(f(x;θ))y
משערך ה MLE של מודל זה יהיה נתון על ידי:
θ∗=θargmin −i=1∑Nlog(py∣x(y(i)∣x(i);θ))=θargmin −i=1∑Nlog(softmax(f(x(i);θ))y(i))
היתירות בייצוג של מודל ה logistic regression
- במקרה הבינארי לא היינו צריכים להגדיר 2 פונקציות פרמטריות.
- במקרה הכללי מספיק להגדיר C−1 פונקציות פרמטריות.
- הסתברות של C−1 מחלקות תקבע באופן מוחלט את המחלקה האחרונה כך שהיא תשלים את ההסתברות ל-1.
- כל שינוי מהצורה של fc(x;θc)→fc(x;θc)+g(x) לא ישנה את הפילוג המותנה
במקרים מסויימים נרצה לבטל יתירות זו. ניתן לעשות זאת על ידי קיבוע של f1(x;θ1)=0
Linear Logistic Regression
המקרה שבו הפונקציות הפרמטריות הם לינאריות:
fc(x;θc)=θc⊤x
אפשר כמובן להוסיף סף ע"י תוספת קבוע לאגף ימין.
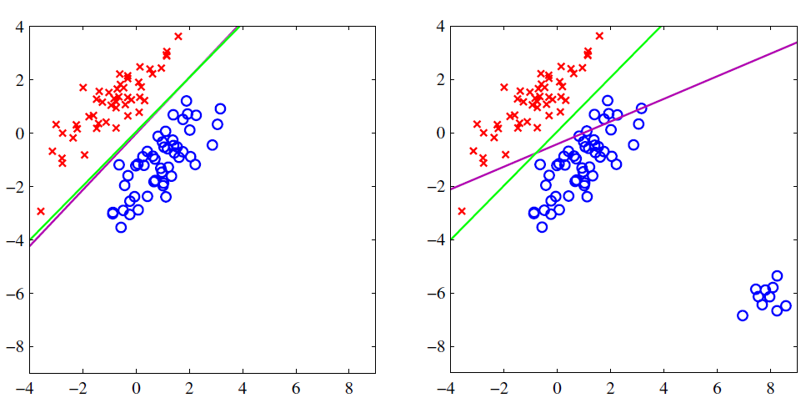
Linear Logistic Regression
ירוק - סיווג בינארי לוגיסטי.
סגול - קריטריון אחר.
האיור מתוך, C.M. Bishop, Pattern Recognition and Machine Learning
Linear Logistic Regression
סיווג לוגיסטי לשלוש מחלקות.
האיור מתוך, C.M. Bishop, Pattern Recognition and Machine Learning
Gradient descent (שיטת הגרדיאנט)
האלגוריתם מנסה למצוא מינימום מקומי על ידי התקדמות בצעדים קטנים בכיוון שבו הפונקציה יורדת הכי מהר.
Gradient descent (שיטת הגרדיאנט)
- אלגוריתם חמדן (greedy): מנסה בכל איטרציה לשפר את מצבו לעומת המצב הנוכחי
- יתכנס למינימום מקומי.
- הדרישה היחידה הינה היכולת לחשב את הנגזרת של פונקציית המטרה.
Gradient descent (שיטת הגרדיאנט)
עבור בעיית המינמיזציה:
θargming(θ)
את הפרמטר η יש לקבוע מראש, והוא יקבע את גודל הצעדים שהאלגוריתם יעשה.
תנאי עצירה
θ(t+1)=θ(t)−η∇θg(θ(t))
- מספר צעדי עדכון שנקבע מראש: t>max-iter.
- הנורמה של הגרדיאנט קטנה מערך סף: ∥∇θg(θ)∥2<ϵ
- השיפור בפונקציית המטרה קטן מערך סף: g(θ(t−1))−g(θ(t))<ϵ
- שימוש בעצירה מוקדמת על מנת להתמודד עם התאמת יתר (נרחיב על כך בהרצאה הבאה)
הבעיות של האלגוריתם
- התכנסות למינימום מקומי ותלות באיתחול
- לא ניתן לקבוע בוודאות האם האלגוריתם התכנס
- בעיית הבחירה של גודל הצעד
שתי הבעיות הראשונות מונעות הגעה לאופטימום אך עדיין לא מפריעות לאלגוריתם להניב תוצאות טובות.
הבעיה של בחירת גודל צעד עלולה למנוע מהאלגוריתם להניב תוצאות רלוונטיות תוך מספר סביר של צעדים.
בעיית הבחירה של גודל הצעד
- כאשר יהיו בבעיה כיוונים שונים בהם ישנו הבדל גדול בקצב השינוי של הפונקציה לרוב לא יהיה גודל צעד אשר יגרום לפונקציה להתכנס במספר סביר של צעדים. ראו למשל איור בשקפים הקודמים.
- gradient descent בצורתו הפשוטה אינו מאד שימושי.
- למזלנו ישנם מספר שיפורים שניתן לעשות על מנת להתמודד עם בעיה זו.
- לצערנו בקורס זה לא נספיק לכסות שיפורים אלו.
- האלגוריתם נידון בהרחבה בקורס "אופטימזציה" ובקורס "למידה עמוקה".
דוגמא: Linear Logistic Regression
נחזור לבעיה של חיזוי עסקאות החשודות כהונאות אשראי.
דוגמא: Linear Logistic Regression
נשתמש במודל של linear logistic regression:
py∣x(y∣x;θ)={σ(x⊤θ)1−σ(x⊤θ)y=1y=0
נמצא את הפרמטרים של המודל בעזרת MLE:
θ∗=θargmin −i=1∑Ny(i)log(σ(x(i)⊤θ))+(1−y(i))log(1−σ(x(i)⊤θ))
כלל העדכון של האלגוריתם יהיה:
θ(t+1)=θ(t)+ηi=1∑N(y(i)(1−σ(x(i)⊤θ))−(1−y(i))σ(x(i)⊤θ))x(i)
נזכור כי עבור בעיה זו, פונקציית המחיר קמורה.
בחירת η
נריץ את האלגוריתם מספר קטן של צעדים עבור ערכי η שונים:
בחירת η
- η=30 ו η=100 מתאימים למקרה של η גדול מידי.
- נבחר את η=10.
- שימו לב כי האלגוריתם אינו מתכנס לגודל צעד גדול, אפילו שפונקציית המחיר קמורה!
דוגמא: Linear Logistic Regression
נריץ את האלגוריתם עם η=10 ונקבל את החזאי הבא:
דוגמא: Linear Logistic Regression
נקבל misclassification rate של 0.02 על ה test set:
שימוש במודל מסדר גבוה יותר
נוכל להשתמש בכל מודל שנרצה.
נחליף את f(x;θ) בפולינום מסדר שני ונקבל:
שימוש במודל מסדר גבוה יותר
נקבל misclassification rate של 0 על ה test set: