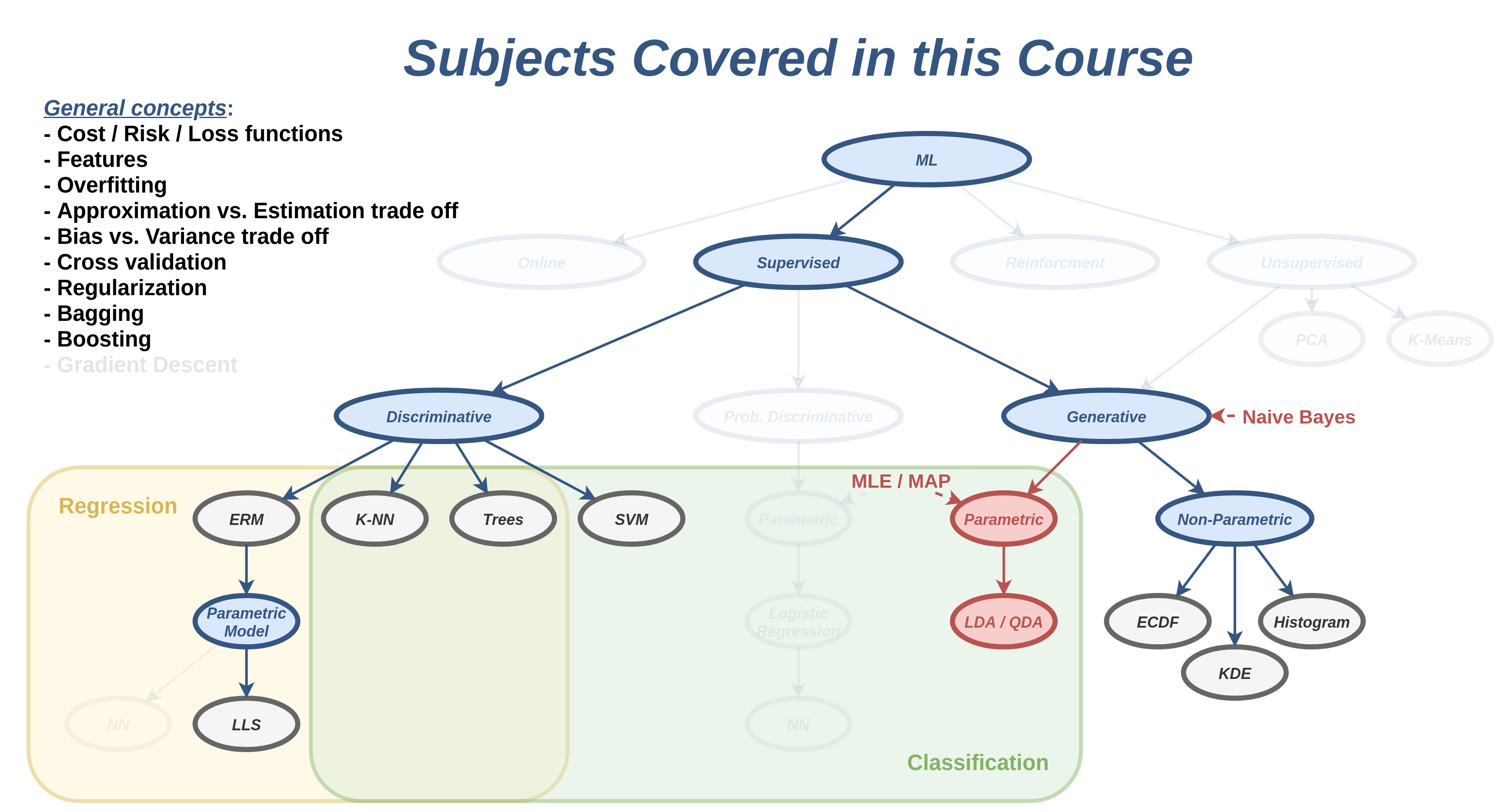
במרבית המקרים בשלב בניית המודל כמות המשאבים שיעמדו לרשותינו (זמן ריצה, כוח חישוב זיכרון וכו') תהיה מאד גדולה. לדוגמא יש כיום הרבה מודלים אשר מאומנים בחוות שרתים על מחשבים מאד חזקים, לרוב עם חומרה יעודית, במשך כמה ימים. מצד שני, בזמן החיזוי אנו לנרצה במקרים רבים לבצע את החישוב על פלטפורמה יחסית חלשה ולקבל תוצאות מאד מהירות. לדוגמא מערכת להתראה על סכנות בכביש צריכה לבצע חיזוי עבור תמונות שמצולמות בקצב של מספר תמונות בשניה ולרוץ על מערכת פשוטה יחסית שיושבת בתוך האוטו.
דוגמא
נסתכל גם על דוגמא מספרית. נניח שאנו רוצים לחזות האם אדם מסויים שקיבל מכה בכתף פרק אותה על פי הסימפטומים שלו. לשם כך נסתכל על המדגם הבא
פריקה
כאב בכתף
נפיחות
סימנים כחולים
נימול ביד
נזלת
1
+
+
+
+
+
-
2
+
+
+
+
-
-
3
+
+
+
-
+
-
4
+
+
+
+
-
+
5
-
-
-
-
-
-
6
-
+
-
-
-
+
7
-
-
-
+
-
-
8
-
+
-
-
-
-
נסתכל על ניסיון לחזות את הסבירות שלאדם עם כל הסימפטומים יש פריקה בכתף.
שיערוך נאיבי - הנחת חוסר תלות בין המשתנים
נניח שאנו רוצים לשערך צפיפות הסתברות של משתנה D ממדי. שיטה מאד נאיבית (לא מתוחכמת) לפתור את הבעיה היא להתעלם מהקשר בין המשתנים השונים ולהניח שהם בלתי תלויים סטטיסטית. זאת אומרת ש:
תחת הנחה זו נוכל לשערך את הפילוג של כל אחד מה pxd(xd) בנפרד. החיסרון של שיטה זו הוא שהיא מגבילה מאד את הפילוגים שניתן ללמוד.
מסווג בייס נאיבי
נוכל להשתמש בשערוך הנאיבי לפתרון בעיות סיווג. לשם כך אנו נשתמש בהנחת החוסר תלות לשיערוך של px∣y(x∣y) ונניח כי ניתן לרשום את הפונקציית ההסתברות / צפיפות הסתברות המונתית באופן הבא:
זאת אומרת שבהינתן y הרכיבים של x בלתי תלויים סטטיסטית. אנו לא נרצה להניח חוסר תלות בין x ל y מיכוון שזוהי בדיוק התלות שאנו מחפשים על מנת לבנות עלפיה את החיזוי של y בהינתן x.
בעזרת הנחה זו נוכל לבנות חזאים אשר מבוססים על הפילוג של כל אחד מהמשתנים בנפרד. לדוגמא, אם נסתכל על החזאי אשר ממזער את ה misclassifcation rate:
y^=h(x)=yargmaxpy∣x(y∣x)
נוכל תחת הנחת החוסר תלות (ובעזרת חוק בייס) לרשום את החזאי כ:
שיטה זו לחיזוי בעזרת הנחת החוסר תלות מכונה סיווג בייס נאיבי (naïve Bayes classification).
דוגמא 1 - זיהוי פריקה של הכתף
נסתכל שוב על הדוגמא של הפריקה של הכתף. על מנת לבנות חזאי, נשערך את py(y) ואז נשתמש בהנחת החוסר תלות ונשערך בנפרד את ההסתברות המותנית של כל אחד מהרכיבים pxd∣y(xd∣y). (לשם הפשטות נשתמש ב1 ו0 במקום ה"+" וה"-" (בהתאמה) אשר מופיעים בטבלה):
מכיוון שתנאי זה מתקיים, החיזוי במקרה שבו מופיעים כל הסימפטומים יהיה שאכן ישנה פריקה של כתף.
דוגמא 2 - זיהוי הונאות אשראי
ננסה להשתמש בשיטה זו לבעיית חיזוי הונאות האשראי
שיטות פרמטריות
דרך נוספת לשיערוך פילוגים היא על ידי שימוש במודל פרמטרי. הדבר מאד דומה לשימוש שעשינו במודלים פרמטריים כאשר עסקנו בגישה הדטרמיניסטית. בשיטה זו אנו נגביל את הצורה של הפונקציה שאותה אנו רוצים לשערך (לרוב פונקציית צפיפות ההסתברות) למשפחה מומצמת של פונקציות על ידי שימוש במודל פרמטרי. גם כאן אנו נסמן את וקטור הפרמטרים של המודל ב θ.
חשוב לשים לב שבניגוד לשימוש במודלים פרמטרים בגישה הדטרמיניסטית, שם לא הייתה שום מגבלה על המודל הפרמטרי, כאן המודל חייב לייצר פילוג חוקי עבור כל בחירה של פרמטרים (במקרה של PDF זה אומר פונקציה חיובית שאינטרגל עליה נותן 1). מגבלה זו הינה מגבלה קשה אשר מצמצמת מאד את המודלים הפרמטריים שאיתם ניתן לעבוד. מגבלה זו למשל מונעת מאיתנו מלהשתמש אפילו במודל לינארי פשוט. המודלים שאיתם נעבוד יהיו לרוב פונקציות פילוג ידועות כגון פילוג אחיד, נורמלי, אקפוננציאלי וכו'.
כדי למצוא את הפרמטרים של המודל נרצה גם כאן למצוא דרך לתת "ציון" לכל בחירה של פרמטרים ולחפש את הפרמטריים אשר מניבים את הציון הטוב ביותר. נציג כעת שתי דרכים שונות להתייחס לפרמטרים של המודל. שני דרכים אלו מגיעות משתי גישות הקיימות בתחום של תורת השיערוך. כל גישה מובילה לדרך מעט שונה לבחירה של הפרמטרים האופטימאליים.
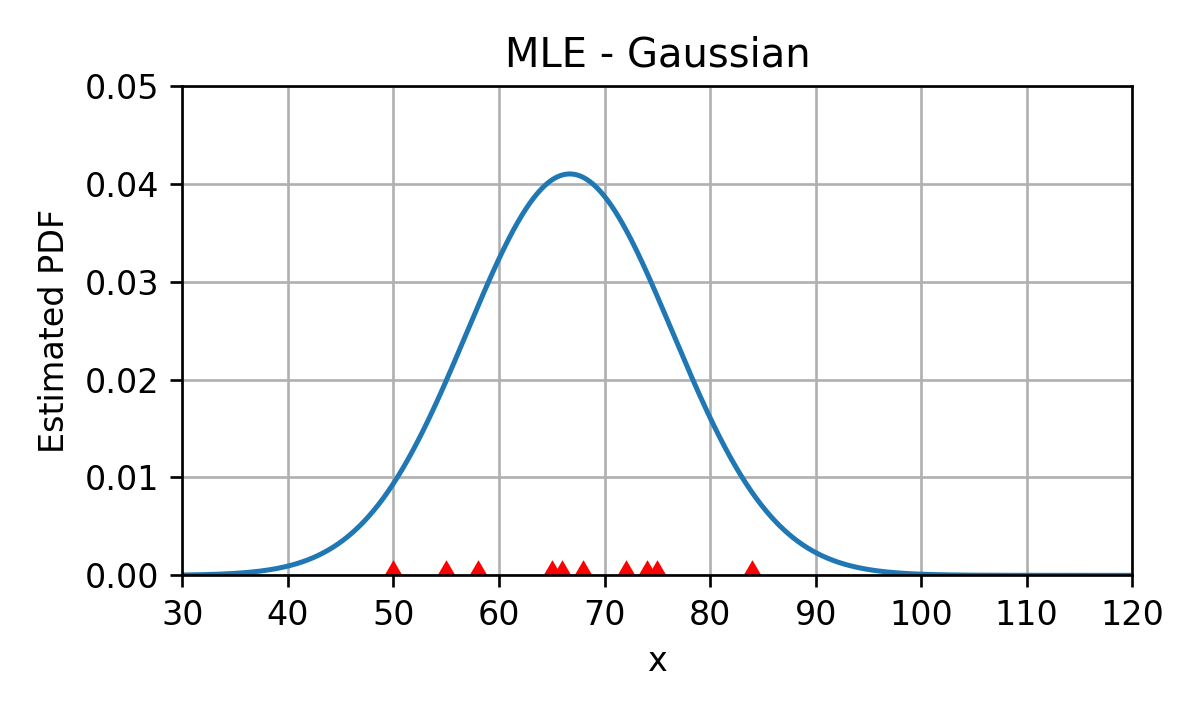
דוגמא: שיערוך הפילוג של זמן הנסיעה בכביש החוף
בהרצאה הקודמת הסתכלנו על שיערוך של הפילוג של זמן הנסיעה בכביש החוף מתוך הדגם הבא:
D={x(i)}={55,68,75,50,72,84,65,58,74,66}
משערך ה KDE (עם גרעין גאוסיאני עם הרוחב אשר נקבע על פי כלל האצבע) של הפילוג (לא דנו הסמסטר) הינו:
(הנקודות האדומות על ציר ה x מסמנות את המיקומים של הדגימות מהמדגם)
בהרצאה זו ננסה לשערך פרמטרים של פילוג נורמלי שיתאר בצורה טובה את הדגימות במדגם.
הגישה הלא-בייסיאנית (המכונה גם: קלאסית או תדירותית (Frequintist))
תחת גישה זו אנו נתייחס לפרמטרים בצורה פשוטה כאל מספרים שאותם יש לקבוע על מנת שהמודל יתאר בצורה טובה את המדגם הנתון. ההנחה היא כי יש ערך לא ידוע של הפרמטר שהוא ה"טוב" ביותר. את המודל הפרמטרי להסתברות / צפיפות הסתברות של משתנה אקראי x נסמן ב:
px(x;θ)
ונרצה לבחון עד כמה טוב מתאר מודל עם פרמטרים מסויימים את הפילוג של הדגימות במדגם. אחת הדרכים הנפוצות ביותר לעשות זאת הינה בעזרת פונקציית הסבירות.
משערך Maximum Likelyhood Estimator (MLE)
נסמן ב pD(D;θ) את ההסתברות לקבלת המדגם הנתון D={x(i)} על פי המודל שבידינו. גודל זה מכונה הסבירות (likelihood) של המדגם. אנו מעוניינים למצוא את הפרמטרים θ אשר מניבים את הסבירות הכי גבוהה. על מנת להדגיש את העובדה שהמדגם הוא למעשה גודל ידוע ואילו הגודל הלא ידוע, שאותו נרצה לבדוק, הינו θ, מקובל לסמן את פונקציית ה likelihood באופן הבא:
L(θ;D)≜pD(D;θ)
משערך ה MLE של θ הוא הערך אשר ממקסם את פונקציית ה likelihood:
θ^MLE=θargmaxL(θ;D)
מקובל לרשום בעיות אופטימיזציה כבעיות מינימיזציה, לכן במקרים רבים נרשום אותה כבעיה של מציאת הפרמטריים אשר ממזערים את המינוס של פונקציית הסבירות:
θ^MLE=θargmin−L(θ;D)
כאשר הדגימות במדגם הם i.i.d (בעלות פילוג זהה ובלתי תלויות, כפי שנניח תמיד שמתקיים בבעיות supervised learning) נוכל להסיק כי:
pD(D;θ)=i∏px(x(i);θ)
ולכן:
θ^MLE=θargmin−L(θ;D)=θargmin−i∏px(x(i);θ)
במקרים רבים נוכל להחליף את המכפלה על כל הדגימות בסכום, על ידי החלפת פונקציית ה likelihood ב log-likelihood (בזכות המונוטוניות העולה של פונקציית ה log מובטח לנו שנקבל את אותם פרמטרים אופטימאלים בשתי הבעיות):
הערה: בקורסים "עיבוד אותות אקראיים" ו-"הסקה סטטיסטית" מרחיבים הרבה בנושא תכונות משערך זה ואחרים.
דוגמא
נסתכל על הדוגמא של התאמת פילוג נורמלי לנסיעות בכביש החוף. הפרמטרים של מודל זה הינם התוחלת μ וסטיית התקן σ. נסמן את וקטור הפרמטרים ב θ=[μ,σ]⊤. המודל שלנו יהיה:
בגישה זו אנו נניח כי בדומה למדגם, גם הפרמטרים של המודל הם ריאליזציות (הגרלות) של משתנה אקראי בעל פילוג כל שהוא. גישה זו למעשה מניחה שיש בידינו מודל לפילוג המשותף של הפרמטרים והמדגם. לרוב הפילוג משותף יהיה נתון בצורה של:
pD,θ(D,θ)=pD∣θ(D∣θ)pθ(θ)
תחת ההנחה שבהינתן הפרמטרים הדגימות במדגם הם i.i.d, הפילוג המשותף יהיה:
pD,θ(D,θ)=pθ(θ)i∏px∣θ(x(i)∣θ)
תחת גישה זו עלינו לקבוע בנוסף לפילוג של הדגימות בהינתן הפרמטרים px∣θ(x∣θ) וגם את הפילוג השולי של הפרמטרים pθ(θ).
A Prioiri Distribution
הפילוג השולי של הפרמטרים pθ(θ), מכונה לרוב הפילוג הפריורי (prior distribution) או הא-פריורי (a priori distribution), זאת אומרת הפילוג של θ לפני שראינו את המדגם.
A Posteriori Distribution
פילוג חשוב נוסף שנרצה להתייחס אליו הוא הפילוג של הפרמטרים בהינתן המדגם p,θ∣D(θ∣D). פילוג זה מכונה הפילוג הפוסטריורי (posterior distribution) או א-פוסטריורי (a posteriori distribution) (או הפילוג בדיעבד), זאת אומרת, הפילוג אחרי שראינו את המדגם.
משערך Maximum A-posteriori Probaility (MAP)
הדרך הנפוצה ביותר לשערך את הפרמטרים θ היא למצוא את הערך אשר ממקסם את הפילוג הא-פוסטריורי (הערך הכי סביר של θ בהינתן המדגם pθ∣D(θ∣D)):
גם כאן נוכל להפוך את המכפלה לסכום על ידי מזעור מינוס הלוג של הפונקציה:
θ^MAP=θargmin−log(pθ(θ))−i∑log(px∣θ(x(i)∣θ))
ההבדל בין MLE ל MAP
ההבדל בין משערך ה MLE למשערך ה MAP הינו התוספת של האיבר −log(pθ(θ)). איבר זה, ששווה ללוג של הפילוג הא-פריורי, מוסיף למעשה את הידע שיש לנו לגבי איזה ערכים של θ יותר סבירים. ראינו תוספת שכזו כאשר דיברנו על רגולריזציה, שם הוספנו איבר לבעיית האופטימיזציה במטרה למשוך את הפתרון לאיזורים שהנחנו שהם יותר סבירים. לכן, ניתן למעשה לחשוב על בעיית ה MAP כעל בעיית MLE עם רגולריזציה. בתרגיל הבית אתם תראו את השקילות שבין בעיית MAP לבין לבעיית MLE עם רגולריזציה.
בגישה בייסיאנית בעיית השיערוך היא בעיית חיזוי
כפי שציינו, בגישה הבייסיאנית אנו מתייחסים גם למדגם וגם לפרמטרים בריאליזציות של משתנים אקראיים, בנוסף, אנו מניחים שאנו יודעים את הפילוג המשותף שלהם ואנו מנסים למצוא את הערך של הפרמטרים בהינתן המדגם. זוהי בדיוק בעיית חיזוי קלאסית של משתנה אקראי אחד בהינתן משתנה אקראי אחר על סמך הפילוג המשותף (חיזוי של הפרמטרים בהינתן המדגם).
במרבית המקרים המקרים פונקציית הצפיפות המשותפת יהיו מסובכות יכללו מכפלה של הרבה מאד איברים. לכן, חיזויים אחרים כגון התוחלת המותנית או החציון יהיו לרוב מסובכים מידי לחישוב.
דוגמא - הוספת prior
נחזור לדוגמא של התאמת מודל של פילוג נורמלי לפילוג של זמן הנסיעה בכביש החוף. לשם הפשטות בדוגמא זו נקבע את סטיית התקן של המודל ל σ=10 כך שיהיה לנו מודל פרמטרי בעל פרמטר יחיד μ:
px∣μ(x∣μ)=2πσ1exp(−2σ2(x−μ)2)
נניח כעת שיש לנו ידע קודם על פילוג הצפוי של μ. ידע כזה יכול לדוגמא להגיע מתוך סטטיסטיקה שאספנו על מהירויות הנסיעה בכבישים אחרים בארץ. הפילוג הצפוי של μ יהיה הפילוג הא-פריורי של פרמטר זה. נניח אם כן שהפילוג הא-פריורי של μ הוא גם פילוג נורמלי עם תוחלת μμ=60 וסטיית תקן של σμ=5:
pμ(μ)=2πσμ1exp(−2⋅σμ2(μ−μμ)2)
התיאור פה מעט מבלבל משום שאנו מניחים שגם הפילוג של זמן הנסיעה הוא נורמלי וגם הפילוג הא-פריורי של μ נורמלי. אלא שני פילוגים שונים שבמקרה נבחרו להיות בעלי אותו מבנה. ניתן לחשוב על התהליך של ייצור זמני הנסיעה באופן הבא. בתחילה באופן חד פעמי (לצורך העניין עם הבניה של כביש החוף) מוגרל הפרמטר μ מתוך הפילוג pμ אשר מאפיין את הנסיעות בכביש החוף. אחרי שפרמטר זה נקבע, עבור כל נסיעה מחדש מגרילים את זמן נסיעה מתוך px∣μ תוך שימוש בערך של μ אשר הגרלנו.
זו למעשה ממוצע ממושקל בין הערך הממוצע של x במדגם לבין μμ. עבור הדוגמא שלנו נקבל:
μ=64.8[min]
ערך זה מעט יותר קרוב ל60 משאר התוצאה שקיבלנו בשיערוך ה MLE. זאת משום ה prior ש"מושך" את הפרמטרים לאיזורים הסבירים יותר ולכן הוא מקרב אותו ל μμ=60.
שימוש בשיערוך פרמטרי לפתרון בעיות supervised learning
נראה עכשיו איך להשתמש בשערוך הצפיפות שתארנו צורך פתרון בעיות סיווג בלמידה מפוקחת. נציג שיטה אשר משתמשת במודל של פילוג נורמלי וב MLE לפתרון בעיות סיווג.
Quadric Discriminant Analysis (QDA)
בשיטה זו אנו נשתמש במודל של פילוג נורמלי וב MLE על מנת לשערך את הפילוג המותנה של x בהינתן y. אנו למעשה צריכים לשערך מודל נורמלי אחד עבור כל אחת מ C המחלקות של y יכול לקבל. זאת אומרת שאנו נרצה לשערך את הפרמטרים הבאים:
וקטור תוחלת μc עבור כל אחד מהמחלקות (c∈{1,2,…,C}).
בשביל למצוא את הערכים האופטימאלים של μ1 ו Σ1 מספיק להסתכל על האיבר הראשון. לכן ניתן למעשה לפרק את הבעיה ל C בעיות נפרדות שבהם משערכים בנפרד את הפרמטרים של כל מחלקה.
ניתן לפתור את הבעיה הזו על ידי גזירה והשוואה ל-0. הפיתוח עבור Σc הוא מעט מורכב ואנו לא נראה אותו בקורס זה ונקפוץ לפתרון. הפיתוח מודגם בקורס "עיבוד וניתוח מידע". נראה אבל את החישוב של μc
את בעיית האופטימיזציה הזו ניתן לפתור על ידי גזירה והשוואה ל-0. נסמן את ה objective ב f:
התנאי שקיבלנו xTCx+aTx+b>0 הוא ריבועי ב x ומכאן מקבל האלגוריתם את שמו.
Linear Discriminant Analysis (LDA)
LDA שונה מ QDA בשינוי קטן בהנחות על מודל. על מנת להקטין את כמות הפרמטרים של המודל LDA מניח שלפונקציות הפילוג של המחלקות השונות יש את אותה מטריצת הקווריאנס. זאת אומרת שיש Σ יחידה אשר משותפת לכולם.
שהפרמטרים של המודל יהיו כעת:
וקטור תוחלת μc עבור כל אחד מהמחלקות (c∈{1,2,…,C}).
מטריצת covariance אחת Σ אשר משותפת לפילוגים של כל המחלקות.
גם כאן ניתן למצוא את הפתרון של בעיית האופטימיזציה על ידי גזירה והשןןאה לאפס. במקרה זה בחיפוש אחר ה Σ האידאלי לא ניתן להתייחס רק לחלק מהמדגם משום מהטריצה משותפת לכל המחלקות. הפתרון המתקבל הינו: