הרצאה 7 - שיערוך פילוג בשיטות לא פרמטריות
דיסקרימינטיבי vs. גנרטיבי
הגישה הדיסקרימינטיבית
מדגם
הגישה הגנרטיבית
מדגם
הקשר לבעיות unsupervised learning
בקורס זה לא נעסוק כמעט בבעיות unsupervised learning.
בבעיות unsupervised learning המדגם מכיל סוג אחד של משתנים x \mathbf{x} x
ננסה ללמוד מהם התכונות שמאפיינות את הדגימות במדגם.
אחת הדרכים הטובות ביותר לעשות זאת היא על ידי שיערוך הפילוג שלהם.
שיערוך הפילוג
הבעיה של בניית מודל הסתברותי של משתנים אקראיים מתוך מדגם מכונה בעיית שיערוך (estimation) . את המודל ההסתברותי אנו נבטא בעזרת אחת מהפונקציות הבאות:
פונקציית ההסתברות (probablity mass function - PMF)
פונקציית צפיפות ההסתברות (probability density function - PDF)
פונקציית הפילוג המצרפית (cumulative distribution function CDF).
חיזוי (prediction) ושיערוך (estimation)
בבעיות חיזוי אנו מועניינים לחזות את ערכו של משתנה אקראי , לרוב על סמך משתנה / וקטור אקראי בודד (דגימה יחידה ).בבעיות שיערוך אנו מעוניינים לבנות מודל הסתברותי של משתנה / משתנים אקראיים לרוב על סמך הרבה דגימות .
דוגמא
נסתכל לדוגמא על המדגם של הונאות אשראי מהרצאה הקודמת:
נרצה לשערך את הפילוג של המשתנים על פי מדגם זה
דוגמא
לדוגמא היינו רוצים למצוא פונקציות אשר יתארו את הפילוג של הדגימות החוקיות ושל ההונאות:
שיערוך א-פרמטריות
בהרצאה הקרובה נעסוק בשיטות שיערוך אשר מכונות שיטות לא פרמטריות או א-פרמטריות, מהות השם תהיה ברורה יותר אחרי שנציג בהרצאה הבאה את הנושא של שיטות פרמטריות.
שיערוך ההסתברות של מאורע
דוגמא
נניח שיש בידינו את המדגם הבא של מדידות של זמני נסיעה (בדקות) מחיפה לתל אביב על כביש החוף:
D = { x ( i ) } = { 55 , 68 , 75 , 50 , 72 , 84 , 65 , 58 , 74 , 66 } \mathcal{D}=\{x^{(i)}\}=\{55, 68, 75, 50, 72, 84, 65, 58, 74, 66\} D = { x ( i ) } = { 5 5 , 6 8 , 7 5 , 5 0 , 7 2 , 8 4 , 6 5 , 5 8 , 7 4 , 6 6 } ברצונינו לשערך את ההסתברות של המאורע שנסיעה מסויימת תיקח פחות משעה, A = { x < 60 } A=\{x<60\} A = { x < 6 0 }
שיערוך ההסתברות של מאורע
דוגמא
D = { x ( i ) } = { 55 , 68 , 75 , 50 , 72 , 84 , 65 , 58 , 74 , 66 } \mathcal{D}=\{x^{(i)}\}=\{55, 68, 75, 50, 72, 84, 65, 58, 74, 66\} D = { x ( i ) } = { 5 5 , 6 8 , 7 5 , 5 0 , 7 2 , 8 4 , 6 5 , 5 8 , 7 4 , 6 6 } נשערך שהסתברות זו שווה למספר הפעמים היחסי שמאורע זה קרה במדגם הנתון:
Pr ( A ) ≈ p ^ A , D = 0.3 \text{Pr}(A)\approx\hat{p}_{A,\mathcal{D}}=0.3 Pr ( A ) ≈ p ^ A , D = 0 . 3
נשתמש בסימון "כובע" לציון גודל שאותו אנו חוזים / משערכים באופן אמפירי.
נציין את העובדה שמשערך תלוי במדגם שבו השתמשנו על ידי הוספת D \mathcal{D} D
מדידה אמפירית (empirical measure)
בהינתן מדגם מסויים D = { x ( i ) } i = 0 N \mathcal{D}=\{\boldsymbol{x}^{(i)}\}_{i=0}^N D = { x ( i ) } i = 0 N p ^ A , D \hat{p}_{A,\mathcal{D}} p ^ A , D P r ( A ) Pr\left(A\right) P r ( A )
p ^ A , D = 1 N ∑ i = 1 N I { x ( i ) ∈ A } \hat{p}_{A,\mathcal{D}}=\frac{1}{N}\sum_{i=1}^N I\{\boldsymbol{x}^{(i)}\in A\} p ^ A , D = N 1 i = 1 ∑ N I { x ( i ) ∈ A } נוכל כעת להשתמש בשיטה זו על מנת לנסות ולשערך את הפילוג של משתנים אקראיים.
משתנה אקראי דיסקרטי
דוגמא 1 - משתנה בינארי
x \text{x} x הטלנו את המטבע 10 פעמים וקיבלנו:
D = { x ( i ) } = { 0 , 0 , 0 , 0 , 1 , 0 , 0 , 1 , 0 , 0 } \mathcal{D}=\{x^{(i)}\}=\{0, 0, 0, 0, 1, 0, 0, 1, 0, 0\} D = { x ( i ) } = { 0 , 0 , 0 , 0 , 1 , 0 , 0 , 1 , 0 , 0 } מה ה PMF של x \text{x} x
משתנה אקראי דיסקרטי
דוגמא 1 - משתנה בינארי
D = { x ( i ) } = { 0 , 0 , 0 , 0 , 1 , 0 , 0 , 1 , 0 , 0 } \mathcal{D}=\{x^{(i)}\}=\{0, 0, 0, 0, 1, 0, 0, 1, 0, 0\} D = { x ( i ) } = { 0 , 0 , 0 , 0 , 1 , 0 , 0 , 1 , 0 , 0 } גם כאן נשערך את ההסתברויות של הערכים ש x \text{x} x
p x ( x ) ≈ p ^ x , D ( x ) = { 0.8 0 0.2 1 p_{\text{x}}(x)\approx\hat{p}_{\text{x},\mathcal{D}}(x)=
\begin{cases}
0.8 & 0 \\
0.2 & 1
\end{cases} p x ( x ) ≈ p ^ x , D ( x ) = { 0 . 8 0 . 2 0 1
זו למעשה מדידה אמפירית של המאורע ש { x = x } \{\text{x}=x\} { x = x }
משתנה אקראי דיסקרטי
דוגמא 2 - משתנה לא בינארי
x \text{x} x הטלנו את הקוביה 10 פעמים וקיבלנו:
D = { x ( i ) } = { 3 , 2 , 5 , 1 , 2 , 6 , 2 , 5 , 5 , 3 } \mathcal{D}=\{x^{(i)}\}=\{3, 2, 5, 1, 2, 6, 2, 5, 5, 3\} D = { x ( i ) } = { 3 , 2 , 5 , 1 , 2 , 6 , 2 , 5 , 5 , 3 } מה ה PMF של x \text{x} x
משתנה אקראי דיסקרטי
דוגמא 2 - משתנה לא בינארי
D = { x ( i ) } = { 3 , 2 , 5 , 1 , 2 , 6 , 2 , 5 , 5 , 3 } \mathcal{D}=\{x^{(i)}\}=\{3, 2, 5, 1, 2, 6, 2, 5, 5, 3\} D = { x ( i ) } = { 3 , 2 , 5 , 1 , 2 , 6 , 2 , 5 , 5 , 3 } בדיוק כמו קודם, נשערך את ההסתברות לקבל כל ערך לפי השכיחות שלו במדגם:
p x ( x ) ≈ p ^ x , D ( x ) = { 0.1 1 0.3 2 0.2 3 0 4 0.3 5 0.1 6 p_{\text{x}}(x)\approx\hat{p}_{\text{x},\mathcal{D}}(x)=
\begin{cases}
0.1 & 1 \\
0.3 & 2 \\
0.2 & 3 \\
0 & 4 \\
0.3 & 5 \\
0.1 & 6 \\
\end{cases} p x ( x ) ≈ p ^ x , D ( x ) = ⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ 0 . 1 0 . 3 0 . 2 0 0 . 3 0 . 1 1 2 3 4 5 6
ניסוח פורמאלי
בהינתן מדגם מסויים D = { x ( i ) } i = 0 N \mathcal{D}=\{\boldsymbol{x}^{(i)}\}_{i=0}^N D = { x ( i ) } i = 0 N
p ^ x , D ( x ) = 1 N ∑ i = 1 N I { x ( i ) = x } \hat{p}_{\mathbf{x},\mathcal{D}}(\boldsymbol{x})=\frac{1}{N}\sum_{i=1}^N I\{\boldsymbol{x}^{(i)}=\boldsymbol{x}\} p ^ x , D ( x ) = N 1 i = 1 ∑ N I { x ( i ) = x } שימו לב שמובטח לנו שנקבל פונקציית הסתברות חוקית (חיובית שהסכום עליה שווה ל1).
שיערוך הפילוג המצרפי
נזכור כי פונקציית הפילוג המצרפי (ה CDF) מוגדרת באופן הבא:
F x ( x ) = Pr ( { x j ≤ x j ∀ j } ) F_{\mathbf{x}}(\boldsymbol{x})=\text{Pr}\left(\{\text{x}_j\leq {x}_j\ \forall j\}\right) F x ( x ) = Pr ( { x j ≤ x j ∀ j } ) נוכל אם כן לשערך גודל זה על ידי שימוש במדידה האמפירית בעבור המאורע של A = { x j ≤ x j ∀ j } A=\{\text{x}_j\leq {x}_j \, \forall j\} A = { x j ≤ x j ∀ j }
F ^ x , D ( x ) = p ^ A , D = 1 N ∑ i = 1 N I { x j ≤ x j ∀ j } \hat{F}_{\mathbf{x},\mathcal{D}}(\boldsymbol{x})=\hat{p}_{A,\mathcal{D}}=\frac{1}{N}\sum_{i=1}^N I\{\text{x}_j\leq {x}_j \, \forall j\} F ^ x , D ( x ) = p ^ A , D = N 1 i = 1 ∑ N I { x j ≤ x j ∀ j } משערך זה נקרא empirical cumulative distribtuion function (ECDF).
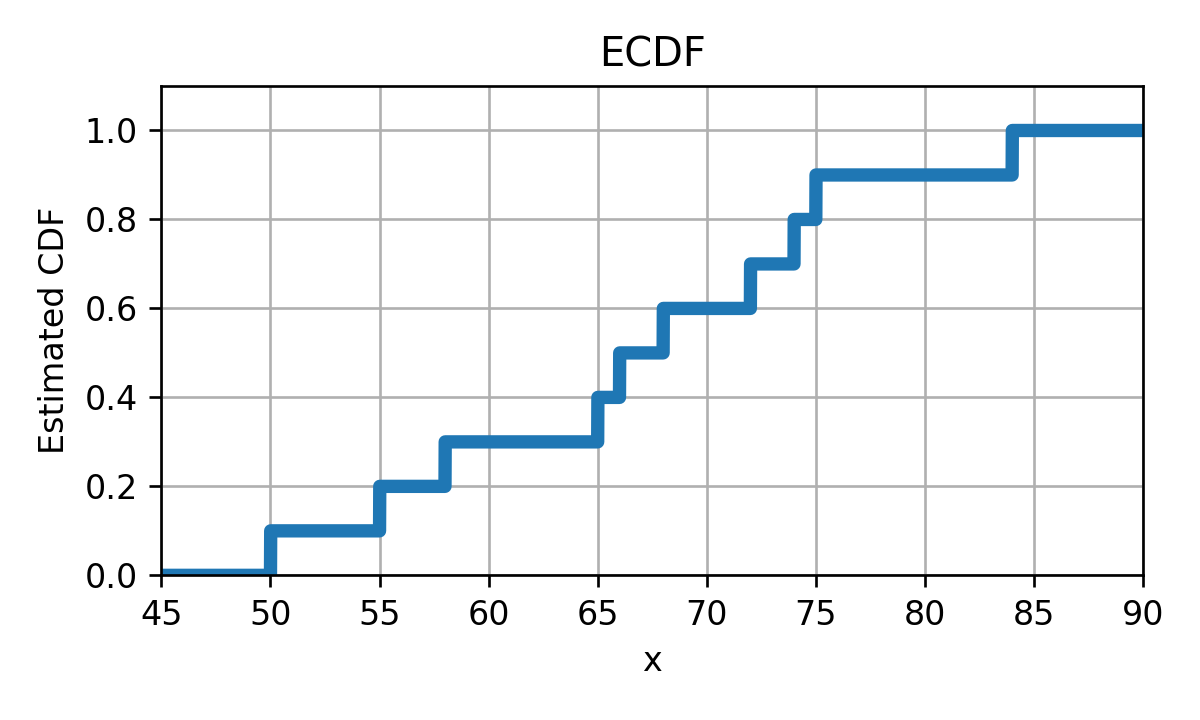
ECDF - דוגמא
נשערך את הפילוג המצרפי של זמני הנסיעה בכביש החוף
D = { x ( i ) } = { 55 , 68 , 75 , 50 , 72 , 84 , 65 , 58 , 74 , 66 } \mathcal{D}=\{x^{(i)}\}=\{55, 68, 75, 50, 72, 84, 65, 58, 74, 66\} D = { x ( i ) } = { 5 5 , 6 8 , 7 5 , 5 0 , 7 2 , 8 4 , 6 5 , 5 8 , 7 4 , 6 6 } F ^ x , D ( x ) = { 0 x < 50 0.1 50 ≤ x < 55 0.2 55 ≤ x < 58 0.3 58 ≤ x < 65 0.4 65 ≤ x < 66 0.5 66 ≤ x < 68 0.6 68 ≤ x < 72 0.7 72 ≤ x < 74 0.8 74 ≤ x < 75 0.9 75 ≤ x < 84 1 84 ≤ x \hat{F}_{\mathbf{x},\mathcal{D}}(\boldsymbol{x})=
\begin{cases}
0 & x<50 \\
0.1 & 50\leq x<55 \\
0.2 & 55\leq x<58 \\
0.3 & 58\leq x<65 \\
0.4 & 65\leq x<66 \\
0.5 & 66\leq x<68 \\
0.6 & 68\leq x<72 \\
0.7 & 72\leq x<74 \\
0.8 & 74\leq x<75 \\
0.9 & 75\leq x<84 \\
1 & 84\leq x \\
\end{cases} F ^ x , D ( x ) = ⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 x < 5 0 5 0 ≤ x < 5 5 5 5 ≤ x < 5 8 5 8 ≤ x < 6 5 6 5 ≤ x < 6 6 6 6 ≤ x < 6 8 6 8 ≤ x < 7 2 7 2 ≤ x < 7 4 7 4 ≤ x < 7 5 7 5 ≤ x < 8 4 8 4 ≤ x
ECDF - דוגמא
זוהי למעשה פונקציה קבועה למקוטעין אשר נראית כך:
בעיה : איך נראה ה PDF?
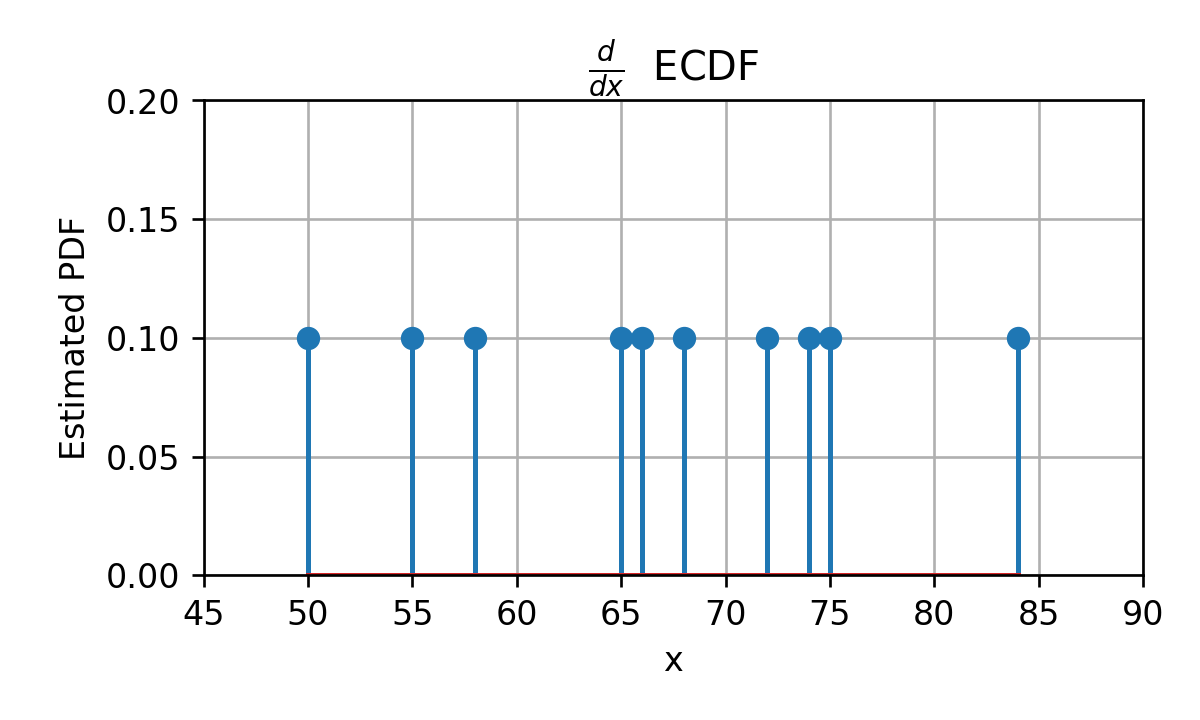
ECDF - דוגמא
ככה:
פונקציה כזו היא לא מאד שימושית.
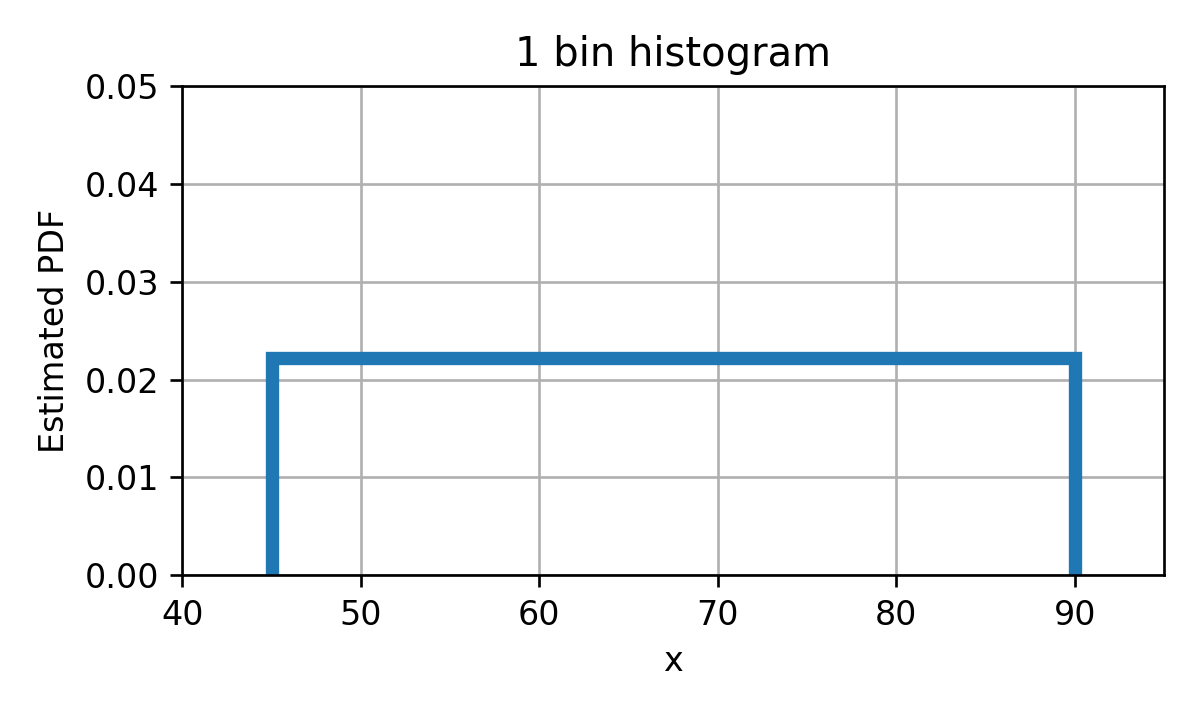
היסטוגרמה
נסיון לשערך PDF על ידי קוונטיזציה של משתנה רציף.
נחלק את טווח הערכים למספר סופי של חלקים המכוונים bins (תאים).
נשתמש במדידה אמפירת על מנת לשערך את ההסתברות להימצא בכל תא.
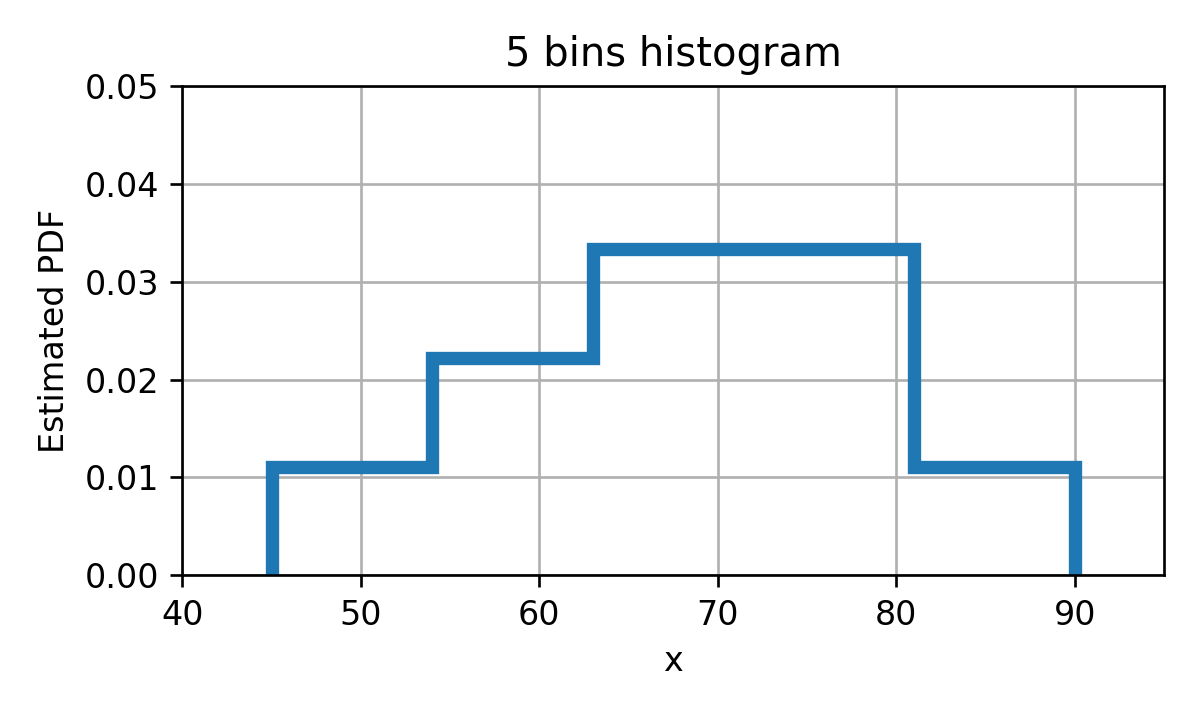
היסטוגרמה - דוגמא
D = { x ( i ) } = { 55 , 68 , 75 , 50 , 72 , 84 , 65 , 58 , 74 , 66 } \mathcal{D}=\{x^{(i)}\}=\{55, 68, 75, 50, 72, 84, 65, 58, 74, 66\} D = { x ( i ) } = { 5 5 , 6 8 , 7 5 , 5 0 , 7 2 , 8 4 , 6 5 , 5 8 , 7 4 , 6 6 } נחלק את התחום ל 5 קטעים:
[ 45 , 54 ) , [ 54 , 63 ) , [ 63 , 72 ) , [ 72 , 81 ) , [ 81 , 90 ] [45,54),[54,63),[63,72),[72,81),[81,90] [ 4 5 , 5 4 ) , [ 5 4 , 6 3 ) , [ 6 3 , 7 2 ) , [ 7 2 , 8 1 ) , [ 8 1 , 9 0 ] ההסתברות להיות בכל bin הינה:
p ^ { 45 ≤ x < 54 } , D = 0.1 p ^ { 54 ≤ x < 63 } , D = 0.2 p ^ { 63 ≤ x < 72 } , D = 0.3 p ^ { 72 ≤ x < 81 } , D = 0.3 p ^ { 81 ≤ x ≤ 90 } , D = 0.1 \begin{aligned}
\hat{p}_{\{45\leq\text{x}<54\},\mathcal{D}}&=0.1\\
\hat{p}_{\{54\leq\text{x}<63\},\mathcal{D}}&=0.2\\
\hat{p}_{\{63\leq\text{x}<72\},\mathcal{D}}&=0.3\\
\hat{p}_{\{72\leq\text{x}<81\},\mathcal{D}}&=0.3\\
\hat{p}_{\{81\leq\text{x}\leq90\},\mathcal{D}}&=0.1\\
\end{aligned} p ^ { 4 5 ≤ x < 5 4 } , D p ^ { 5 4 ≤ x < 6 3 } , D p ^ { 6 3 ≤ x < 7 2 } , D p ^ { 7 2 ≤ x < 8 1 } , D p ^ { 8 1 ≤ x ≤ 9 0 } , D = 0 . 1 = 0 . 2 = 0 . 3 = 0 . 3 = 0 . 1 יש לבחור את ה bins כך שיכסו את התחום ולא יחפפו.
היסטוגרמה
בכדי להפוך את ההסתברויות לצפיפות הסתברות נרצה "למרוח" את ההסתברות שקיבלנו באופן אחיד על פני ה bin.
p ^ x , D ( x ) = { 1 size of bin 1 p ^ { x in bin 1 } , D x in bin 1 ⋮ 1 size of bin B p ^ { x in bin B } , D x in bin B \hat{p}_{\text{x},\mathcal{D}}(x)
=\begin{cases}
\frac{1}{\text{size of bin }1}\hat{p}_{\{\text{x in bin }1\},\mathcal{D}}&\text{x in bin }1\\
\vdots\\
\frac{1}{\text{size of bin }B}\hat{p}_{\{\text{x in bin }B\},\mathcal{D}}&\text{x in bin }B
\end{cases} p ^ x , D ( x ) = ⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ size of bin 1 1 p ^ { x in bin 1 } , D ⋮ size of bin B 1 p ^ { x in bin B } , D x in bin 1 x in bin B
היסטוגרמה - דוגמא
p ^ { 45 ≤ x < 54 } , D = 0.1 p ^ { 54 ≤ x < 63 } , D = 0.2 p ^ { 63 ≤ x < 72 } , D = 0.3 p ^ { 72 ≤ x < 81 } , D = 0.3 p ^ { 81 ≤ x ≤ 90 } , D = 0.1 \begin{aligned}
\hat{p}_{\{45\leq\text{x}<54\},\mathcal{D}}&=0.1\\
\hat{p}_{\{54\leq\text{x}<63\},\mathcal{D}}&=0.2\\
\hat{p}_{\{63\leq\text{x}<72\},\mathcal{D}}&=0.3\\
\hat{p}_{\{72\leq\text{x}<81\},\mathcal{D}}&=0.3\\
\hat{p}_{\{81\leq\text{x}\leq90\},\mathcal{D}}&=0.1\\
\end{aligned} p ^ { 4 5 ≤ x < 5 4 } , D p ^ { 5 4 ≤ x < 6 3 } , D p ^ { 6 3 ≤ x < 7 2 } , D p ^ { 7 2 ≤ x < 8 1 } , D p ^ { 8 1 ≤ x ≤ 9 0 } , D = 0 . 1 = 0 . 2 = 0 . 3 = 0 . 3 = 0 . 1
היסטוגרמה - ניסוח פורמאלי
בהינתן מדגם מסויים D = { x ( i ) } i = 0 N \mathcal{D}=\{\boldsymbol{x}^{(i)}\}_{i=0}^N D = { x ( i ) } i = 0 N
מחלקים את תחום הערכים ש x \mathbf{x} x
לכל bin משערכים את ההסתברות של המאורע שבו x \mathbf{x} x
הערך של פונקציית הצפיפות בכל תא תהיה ההסתברות המשוערכת להיות בתא חלקי גודל התא.
לבחירת ה bins יש השפעה גדולה על איכות השיערוך שנקבל. ננסה להבין את השיקולים בבחירת ה bins.
היסטוגרמה - המקרה הסקלרי
B B B l b l_b l b r b r_b r b b b b
p ^ x , D ( x ) = { 1 N ( r 1 − l 1 ) ∑ i = 1 N I { l 1 ≤ x ( i ) < r 1 } l 1 ≤ x < r 1 ⋮ 1 N ( r B − l B ) ∑ i = 1 N I { l B ≤ x ( i ) < r B } l B ≤ x < r B \hat{p}_{\text{x},\mathcal{D}}(x)=
\begin{cases}
\frac{1}{N(r_1-l_1)}\sum_{i=1}^N I\{l_1\leq x^{(i)}<r_1\}&l_1\leq x<r_1\\
\vdots\\
\frac{1}{N(r_B-l_B)}\sum_{i=1}^N I\{l_B\leq x^{(i)}<r_B\}&l_B\leq x<r_B\\
\end{cases} p ^ x , D ( x ) = ⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ N ( r 1 − l 1 ) 1 ∑ i = 1 N I { l 1 ≤ x ( i ) < r 1 } ⋮ N ( r B − l B ) 1 ∑ i = 1 N I { l B ≤ x ( i ) < r B } l 1 ≤ x < r 1 l B ≤ x < r B
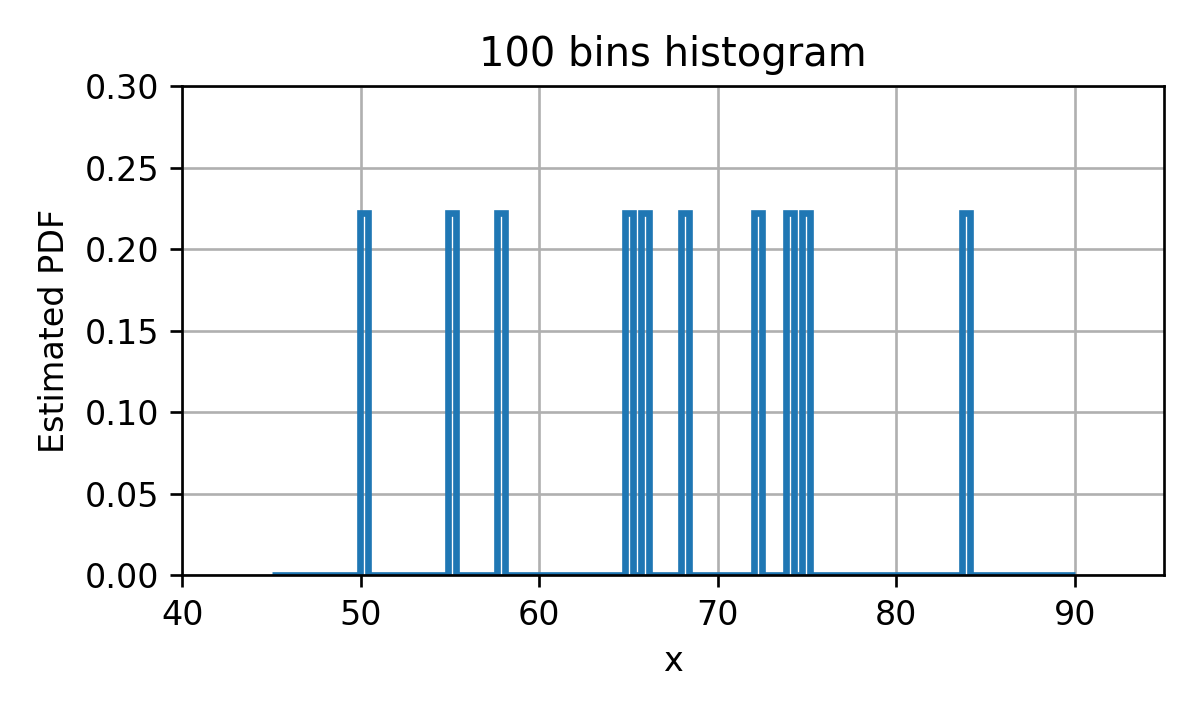
Overfitting ו underfitting של היסטוגרמה
דוגמא - שני מקרים קיצוניים
Overfitting ו underfitting של היסטוגרמה
מספר תאים קטן
Underfitting: יכולת מוגבלת לקרב את ה PDF האמיתי.
מספר תאים גדול
Overfitting: ההיסטוגרמה תתאר בצורה טובה את הדגימות אך לא את הפילוג האמיתי.
בחירת התאים
מקובל לחלק ל k k k
מכיוון שה k k k
ישנם מספר כללי אצבע אשר במרבית המקרים יתנו תוצאה לא רעה.
הכלל הנפוץ ביותר הינו לבחור את k k k k = ⌈ N ⌉ k=\left\lceil\sqrt{N}\right\rceil k = ⌈ N ⌉
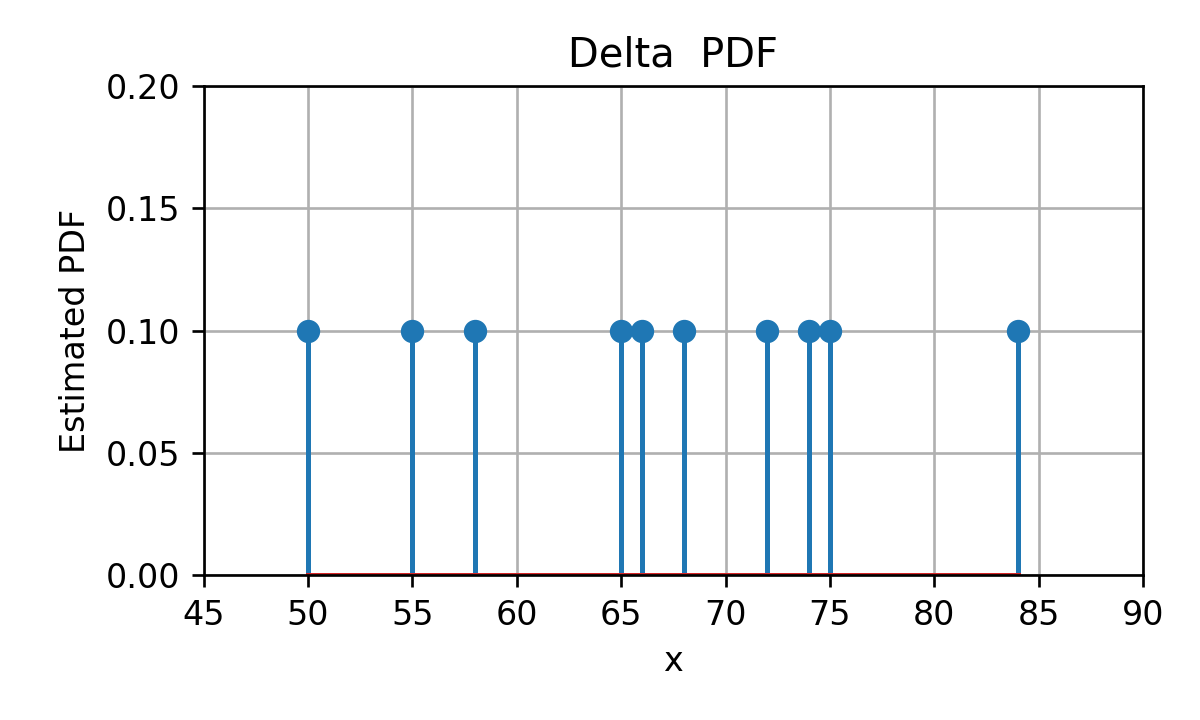
Kernel Density Estimation (KDE)
נתחיל מ PDF שבו אנו ממקמים פונקציית דלתא בגובה 1 N \frac{1}{N} N 1
לדוגמא, בעבור זמני הנסיעה בכביש החוף נקבל:
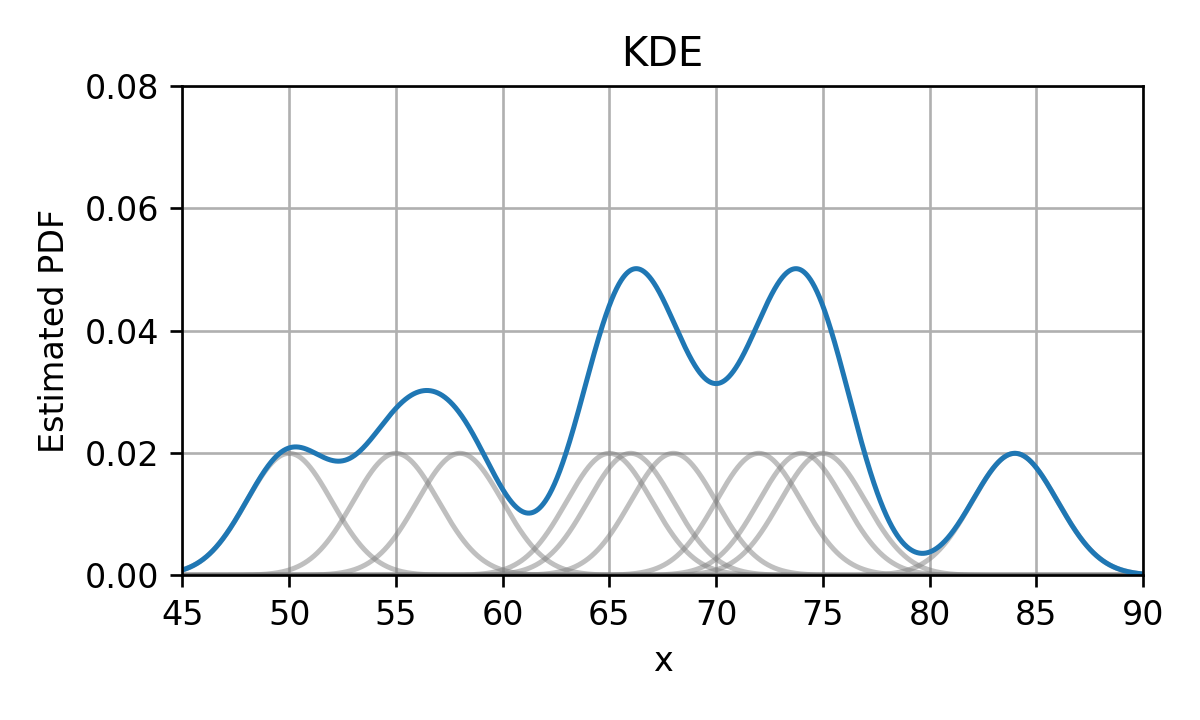
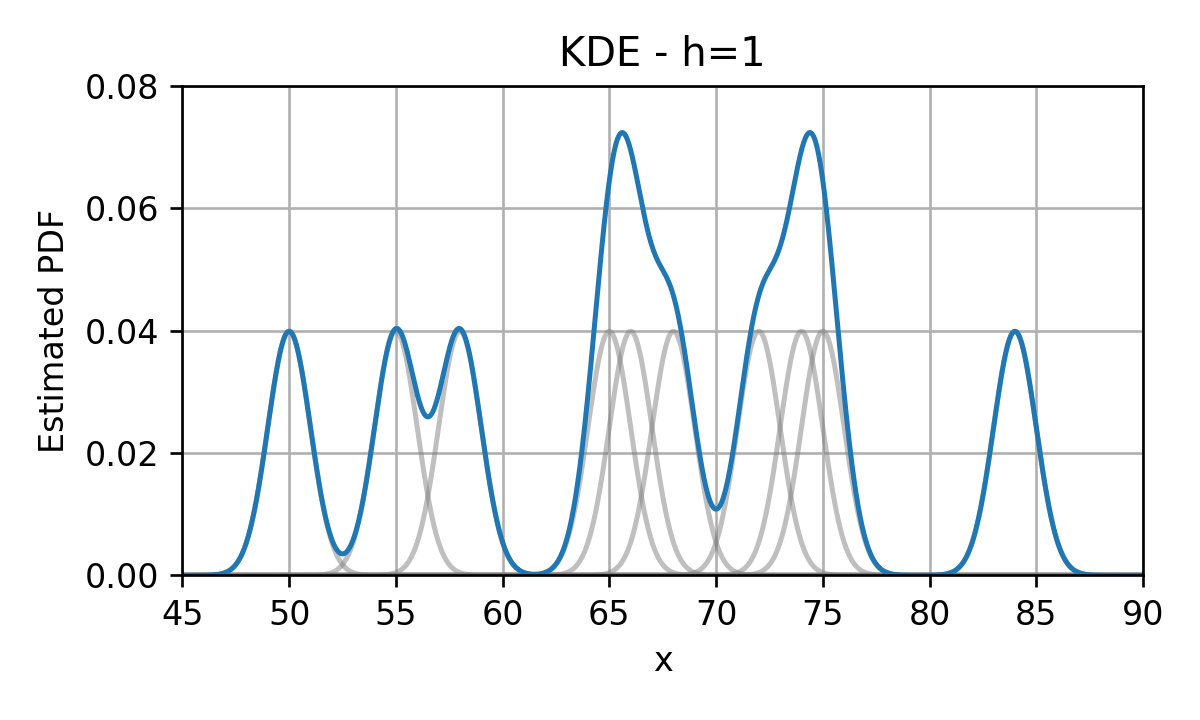
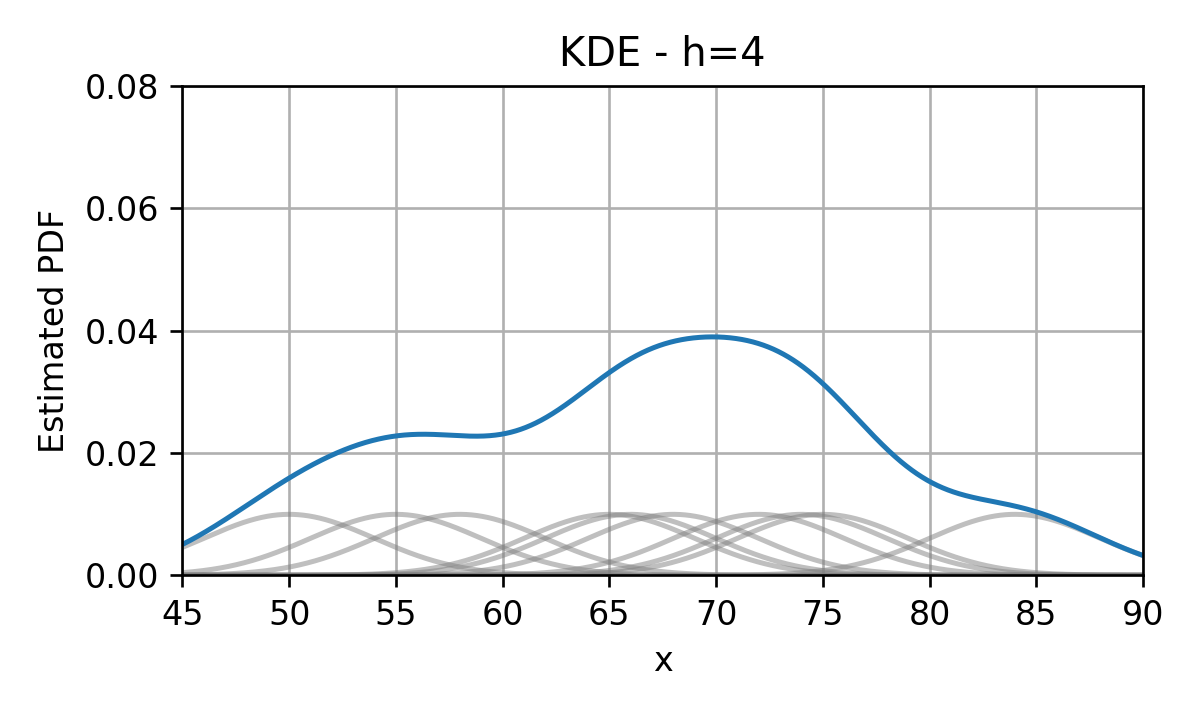
Kernel Density Estimation (KDE)
נחליף כל דלתא בפונקציית גרעין בעלת רוחב גדול מ-0.
לדוגמא גאוסיאנים:
Kernel Density Estimation (KDE)
נסכום את כל פונקציות הגרעין לקבלת ה PDF המשוערך:
Kernel Density Estimation (KDE)
פונקציות הגרעין (kernel) מכונות גם Parzen window .ומקובל לסמנם ב ϕ ( x ) \phi(\boldsymbol{x}) ϕ ( x )
אם כן, משערך ה KDE נתון על ידי:
p ^ x , ϕ , D ( x ) = 1 N ∑ i = 1 N ϕ ( x − x ( i ) ) \hat{p}_{\mathbf{x},\phi,\mathcal{D}}(\boldsymbol{x})=\frac{1}{N}\sum_{i=1}^N \phi(\boldsymbol{x}-\boldsymbol{x}^{(i)}) p ^ x , ϕ , D ( x ) = N 1 i = 1 ∑ N ϕ ( x − x ( i ) ) הערה : תנאי מספיק והכרחי בכדי שנקבל PDF חוקי, הינו שפונקציית הגרעיון תהיה בעצמה PDF חוקי.
בהקשר של עיבוד אותות : למעשה אנו מבצעים קונבולוציה בין פונקציית הדלתאות לבין פונקציית הגרעין. נרצה שהגרעין ישמש כמעיין low pass filter.
הוספת פרמטר רוחב
מקובל להוסיף פרמטר h h h
ϕ h ( x ) = 1 h D ϕ ( x h ) \phi_h(\boldsymbol{x})=\frac{1}{h^D}\phi\left(\frac{\boldsymbol{x}}{h}\right) ϕ h ( x ) = h D 1 ϕ ( h x ) בתוספת פרמטר זה המשערך יהיה:
p ^ x , ϕ , h , D ( x ) = 1 N h D ∑ i = 1 N ϕ ( x − x ( i ) h ) \hat{p}_{\mathbf{x},\phi,h,\mathcal{D}}(\boldsymbol{x})=\frac{1}{Nh^D}\sum_{i=1}^N \phi\left(\frac{\boldsymbol{x}-\boldsymbol{x}^{(i)}}{h}\right) p ^ x , ϕ , h , D ( x ) = N h D 1 i = 1 ∑ N ϕ ( h x − x ( i ) )
פונקציות גרעין נפוצות
שתי הבחירות הנפוצות ביותר לפונקציית הגרעין הינן:
חלון מרובע:
ϕ h ( x ) = 1 h D I { ∣ x j ∣ ≤ h 2 ∀ j } \phi_h(\boldsymbol{x})=\frac{1}{h^D}I\{|x_j|\leq \tfrac{h}{2}\quad\forall j\} ϕ h ( x ) = h D 1 I { ∣ x j ∣ ≤ 2 h ∀ j }
כלל אצבע עבור חלון ריבועי: נבחר את גודל החלון אדפטיבית כך שיכלול N \sqrt{N} N
גאוסיאן:
ϕ σ ( x ) = 1 2 π σ D exp ( − ∥ x ∥ 2 2 2 σ 2 ) \phi_{\sigma}\left(x\right)=\frac{1}{\sqrt{2\pi}\sigma^D}\exp\left(-\frac{\lVert x\rVert_2^2}{2\sigma^2}\right) ϕ σ ( x ) = 2 π σ D 1 exp ( − 2 σ 2 ∥ x ∥ 2 2 )
כלל אצבע לבחירת רוחב הגרעין במקרה הגאוסי הסקלרי:
σ = ( 4 ⋅ std ( x ) 5 3 N ) 1 5 ≈ 1.06 std ( x ) N − 1 5 \sigma=\left(\frac{4\cdot\text{std}(\text{x})^5}{3N}\right)^\frac{1}{5}\approx1.06\ \text{std}(\text{x})N^{-\tfrac{1}{5}} σ = ( 3 N 4 ⋅ std ( x ) 5 ) 5 1 ≈ 1 . 0 6 std ( x ) N − 5 1
שיערוך של פילוגים מעורבים
נניח שאנו רוצים לשערך את הפילוג המשותף של x \text{x} x y \text{y} y x \text{x} x y \text{y} y
במקרים כאלה נוח לפרק את פונקציית הפילוג המשותף באופן הבא:
p x , y ( x , y ) = p x ∣ y ( x ∣ y ) p y ( y ) p_{\mathbf{x},\text{y}}(\boldsymbol{x},y)
=p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|y)p_{\text{y}}(y) p x , y ( x , y ) = p x ∣ y ( x ∣ y ) p y ( y ) ולהפריד את בעיית השיערוך לשני חלקים:
השיערוך של p y ( y ) p_{\text{y}}(y) p y ( y )
השיערוך של p x ∣ y ( x ∣ y ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|y) p x ∣ y ( x ∣ y ) y \text{y} y
שיערוך של פילוגים מעורבים - דוגמא
נחזור לדוגמא של הונאות האשראי:
שיערוך של פילוגים מעורבים - דוגמא
נתחיל בשיערוך של y \text{y} y
y \text{y} y מתוך ה 200 עסקאות ישנם 160 עסקאות חוקיות ו 40 עסקאות שחשודות כהונאה. לכן:
p ^ y , D ( y ) = { 160 200 0 40 200 1 = { 0.8 0 0.2 1 \hat{p}_{\text{y},\mathcal{D}}(y)
=\begin{cases}
\frac{160}{200} & 0 \\
\frac{40}{200} & 1
\end{cases}
=\begin{cases}
0.8 & 0 \\
0.2 & 1
\end{cases} p ^ y , D ( y ) = { 2 0 0 1 6 0 2 0 0 4 0 0 1 = { 0 . 8 0 . 2 0 1
שיערוך של פילוגים מעורבים - דוגמא
נמשיך לשיערוך של p x ∣ y ( x ∣ y ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|y) p x ∣ y ( x ∣ y )
נשערך בנפרד את p x ∣ y ( x ∣ 0 ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|0) p x ∣ y ( x ∣ 0 ) p x ∣ y ( x ∣ 1 ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|1) p x ∣ y ( x ∣ 1 )
נתחיל מ p x ∣ y ( x ∣ 0 ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|0) p x ∣ y ( x ∣ 0 ) y = 0 \text{y}=0 y = 0
שיערוך של פילוגים מעורבים - דוגמא
נשתמש ב KDE על מנת לשערך את p x ∣ y ( x ∣ 0 ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|0) p x ∣ y ( x ∣ 0 )
שיערוך של פילוגים מעורבים - דוגמא
באופן דומה נשערך גם את p x ∣ y ( x ∣ 1 ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|1) p x ∣ y ( x ∣ 1 )
שיערוך של פילוגים מעורבים - דוגמא
p ^ y , D ( y ) = { 0.8 0 0.2 1 \hat{p}_{\text{y},\mathcal{D}}(y)
=\begin{cases}
0.8 & 0 \\
0.2 & 1
\end{cases} p ^ y , D ( y ) = { 0 . 8 0 . 2 0 1 שלושת הפילוגים ששיערכנו מרכיבים את הפילוג המשותף על פי:
p x , y ( x , y ) = p x ∣ y ( x ∣ y ) p y ( y ) p_{\mathbf{x},\text{y}}(\boldsymbol{x},y)
=p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|y)p_{\text{y}}(y) p x , y ( x , y ) = p x ∣ y ( x ∣ y ) p y ( y )
שימוש בפילוג המשוערך לפתרון בעיות supervised learning
הגישה הגנרטיבית
מדגם
עשינו את השלב הראשון, נעשה כעת את השלב השני.
חזאים אופטימאליים של פונקציות מחיר מוכרות - תזכורת
MSE : התוחלת המותנית:
h ∗ ( x ) = E [ y ∣ x ] h^*(\boldsymbol{x})=\mathbb{E}[y|x] h ∗ ( x ) = E [ y ∣ x ]
MAE : החציון של הפילוג המותנה:
h ∗ ( x ) = y median s.t. F y ∣ x ( y median ∣ x ) = 0.5 h^*(\boldsymbol{x})=y_{\text{median}}\qquad
\text{s.t.}\ F_{\text{y}|\mathbf{x}}(y_{\text{median}}|\boldsymbol{x})=0.5 h ∗ ( x ) = y median s.t. F y ∣ x ( y median ∣ x ) = 0 . 5 (כאשר F y ∣ x F_{\text{y}|\mathbf{x}} F y ∣ x y \text{y} y x \mathbf{x} x
Misclassification rate : הערך הכי סביר (ה mode):
h ∗ ( x ) = arg max y p y ∣ x ( y ∣ x ) h^*(\boldsymbol{x})=\underset{y}{\arg\max}\ p_{\text{y}|\mathbf{x}}(y|\boldsymbol{x}) h ∗ ( x ) = y arg max p y ∣ x ( y ∣ x )
דוגמא
בעבור הפילוג שמצאנו נחפש את החזאי אשר ממזער את ה misclassification rate.
h ( x ) = arg max y p y ∣ x ( y ∣ x ) h(\boldsymbol{x})=\underset{y}{\arg\max}\ p_{\text{y}|\mathbf{x}}(y|\boldsymbol{x}) h ( x ) = y arg max p y ∣ x ( y ∣ x ) במקרה הבנארי חזאי זה שווה ל:
h ( x ) = { 1 p y ∣ x ( 1 ∣ x ) > p y ∣ x ( 0 ∣ x ) 0 else h(\boldsymbol{x})=
\begin{cases}
1 & p_{\text{y}|\mathbf{x}}(1|\boldsymbol{x}) > p_{\text{y}|\mathbf{x}}(0|\boldsymbol{x}) \\
0 & \text{else}
\end{cases} h ( x ) = { 1 0 p y ∣ x ( 1 ∣ x ) > p y ∣ x ( 0 ∣ x ) else את p y ∣ x ( y ∣ x ) p_{\text{y}|\mathbf{x}}(y|\boldsymbol{x}) p y ∣ x ( y ∣ x )
p y ∣ x ( y ∣ x ) = p x , y ( x , y ) p x ( x ) = p x ∣ y ( x ∣ y ) p y ( y ) p x ( x ) p_{\text{y}|\mathbf{x}}(y|\boldsymbol{x})
=\frac{p_{\mathbf{x},\text{y}}(\boldsymbol{x},y)}
{p_{\mathbf{x}}(\boldsymbol{x})}
=\frac{p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|y)p_{\text{y}}(y)}
{p_{\mathbf{x}}(\boldsymbol{x})} p y ∣ x ( y ∣ x ) = p x ( x ) p x , y ( x , y ) = p x ( x ) p x ∣ y ( x ∣ y ) p y ( y )
דוגמא
אם כן, בכדי לבדוק האם עסקה מסויימת הינה הונאה או לא, עלינו לבדוק האם:
p y ∣ x ( 1 ∣ x ) > p y ∣ x ( 0 ∣ x ) ⇔ p x ∣ y ( x ∣ 1 ) p y ( 1 ) p x ( x ) > p x ∣ y ( x ∣ 0 ) p y ( 0 ) p x ( x ) ⇔ p x ∣ y ( x ∣ 1 ) p y ( 1 ) > p x ∣ y ( x ∣ 0 ) p y ( 0 ) \begin{aligned}
p_{\text{y}|\mathbf{x}}(1|\boldsymbol{x}) &> p_{\text{y}|\mathbf{x}}(0|\boldsymbol{x}) \\
\Leftrightarrow \frac{p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|1)p_{\text{y}}(1)}{p_{\mathbf{x}}(\boldsymbol{x})} &>
\frac{p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|0)p_{\text{y}}(0)}{p_{\mathbf{x}}(\boldsymbol{x})}\\
\Leftrightarrow p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|1)p_{\text{y}}(1) &>
p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|0)p_{\text{y}}(0)\\
\end{aligned} p y ∣ x ( 1 ∣ x ) ⇔ p x ( x ) p x ∣ y ( x ∣ 1 ) p y ( 1 ) ⇔ p x ∣ y ( x ∣ 1 ) p y ( 1 ) > p y ∣ x ( 0 ∣ x ) > p x ( x ) p x ∣ y ( x ∣ 0 ) p y ( 0 ) > p x ∣ y ( x ∣ 0 ) p y ( 0 )
דוגמא
p x ∣ y ( x ∣ 1 ) p y ( 1 ) > p x ∣ y ( x ∣ 0 ) p y ( 0 ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|1)p_{\text{y}}(1) >
p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|0)p_{\text{y}}(0) p x ∣ y ( x ∣ 1 ) p y ( 1 ) > p x ∣ y ( x ∣ 0 ) p y ( 0 ) נציב את פונקציות הפילוג ששיערכנו קודם לכן ונקבל את החזאי הבא:
ה misclassification rate של חזאי זה על ה test set הינו 0.12.
ה bias וה variance של משערך
המשערכים תלויים בצורה חזקה במדגם שאיתו אנו עובדים.
נסתכל על האקראיות של השיערוך הנובעת מהאקראיות של המדגם.
נשתמש בסימון E D \mathbb{E}_{\mathcal{D}} E D
נגדיר bias ו variance של משערך
ה bias וה variance של משערך
Bias
בעבור שיערוך של גודל כל שהוא z z z z ^ D \hat{z}_{\mathcal{D}} z ^ D
Bias ( z ^ ) = E D [ z ^ D ] − z \text{Bias}\left(\hat{z}\right)=\mathbb{E}_{\mathcal{D}}\left[\hat{z}_{\mathcal{D}}\right]-z Bias ( z ^ ) = E D [ z ^ D ] − z כאשר ההטיה שווה ל-0, אנו אומרים שהמשערך אינו מוטה (Unbiased ).
Variance
ה variance (שונות) של המשערך יהיה:
Var ( z ^ ) = E D [ ( z ^ D − E D [ z ^ D ] ) 2 ] = E D [ z ^ D 2 ] − E D [ z ^ D ] 2 \text{Var}\left(\hat{z}\right)
=\mathbb{E}_{\mathcal{D}}\left[\left(\hat{z}_{\mathcal{D}}-\mathbb{E}_{\mathcal{D}}\left[\hat{z}_{\mathcal{D}}\right]\right)^2\right]
=\mathbb{E}_{\mathcal{D}}\left[\hat{z}_{\mathcal{D}}^2\right]-\mathbb{E}_{\mathcal{D}}\left[\hat{z}_{\mathcal{D}}\right]^2 Var ( z ^ ) = E D [ ( z ^ D − E D [ z ^ D ] ) 2 ] = E D [ z ^ D 2 ] − E D [ z ^ D ] 2
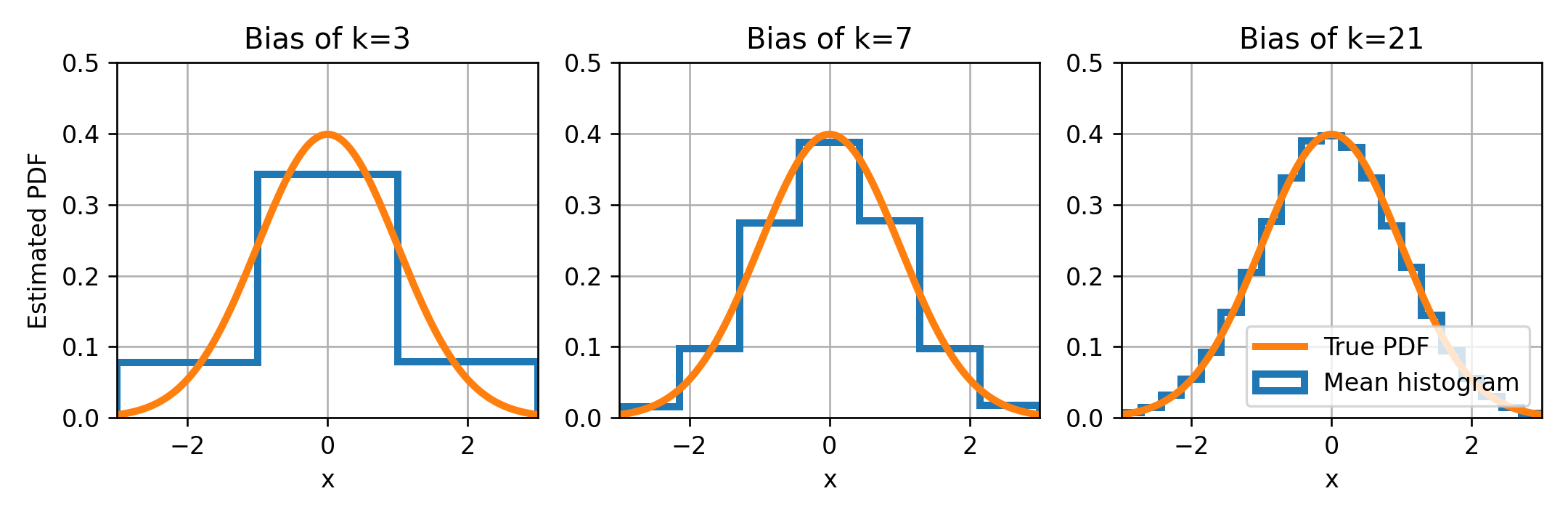
מספר ה bins במונחים של bias ו variance
ננסה לשערך את ה PDF של משתנה אקראי נורמאלי בעזרת היסטוגרמות בעלות 3, 7 ו 21 bins.
ה bias
נשרטט את ההיסטוגרמה הממוצעת לצד ה PDF האמיתי.
ה bias הוא ההפרש בין ההיסטוגרמה הממוצעת ל PDF האמיתי. ה bias קטן ככל שמספר ה bins גדל.
מספר ה bins במונחים של bias ו variance
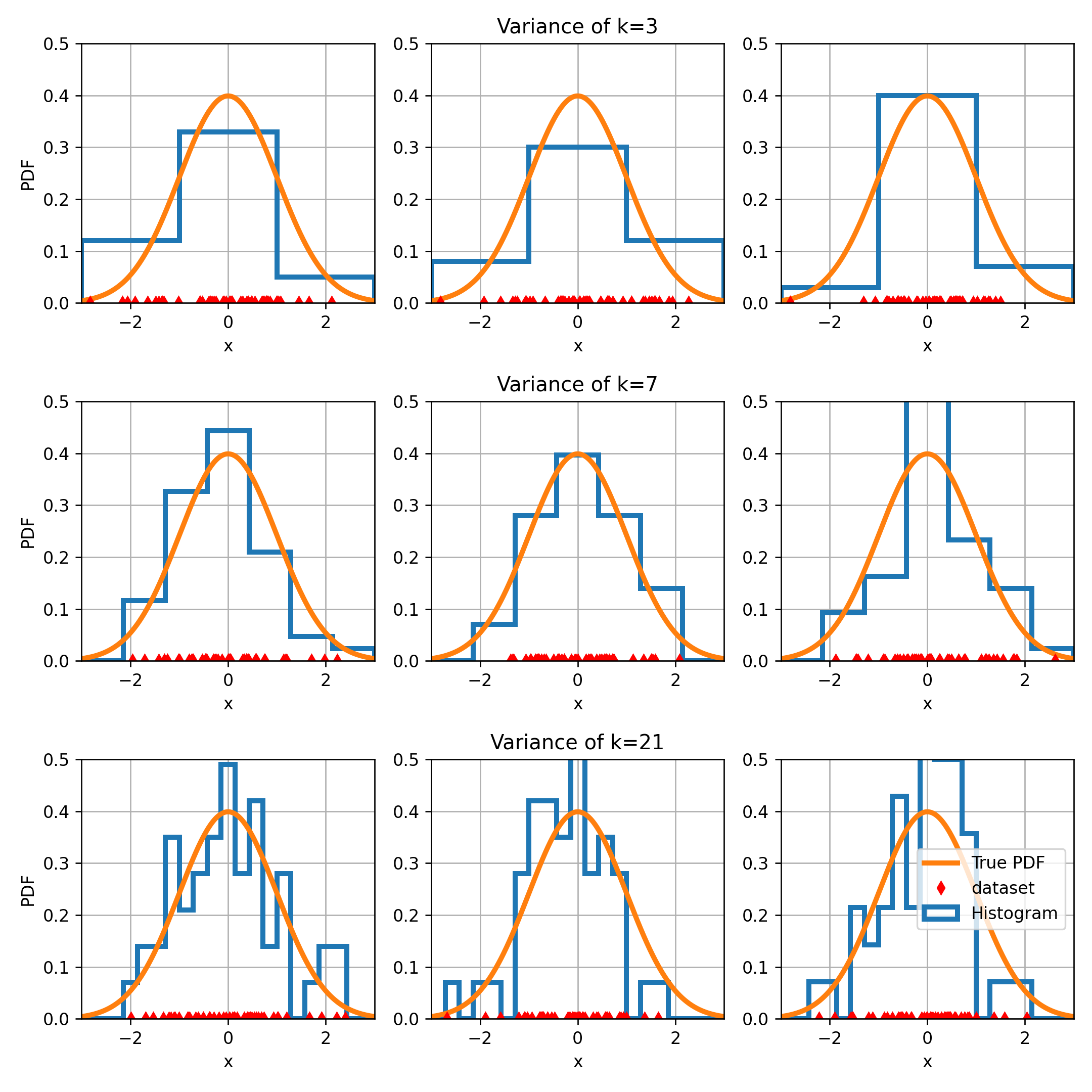
מספר ה bins במונחים של bias ו variance
ה variance
בכל שורה בגרף הקודם מגרילים שלושה מדגמים ומחשבים להם את ההיסטוגרמה.
אנו מצפים שבעבור מקרים שבהם ה variance נמוך השינויים יהיו קטנים ובעבור variance גבוה השינויים יהיו גדולים.
ה variance גדל ככל שאנו מגדילים את כמות ה bins.
בדומה לחזאים בגישה הדיסקרימינטיבית, גם בהיסטוגרמה ישנו bias-variance tradeoff.