הרצאה 7 - שיערוך פילוג בשיטות לא פרמטריות
מה נלמד היום
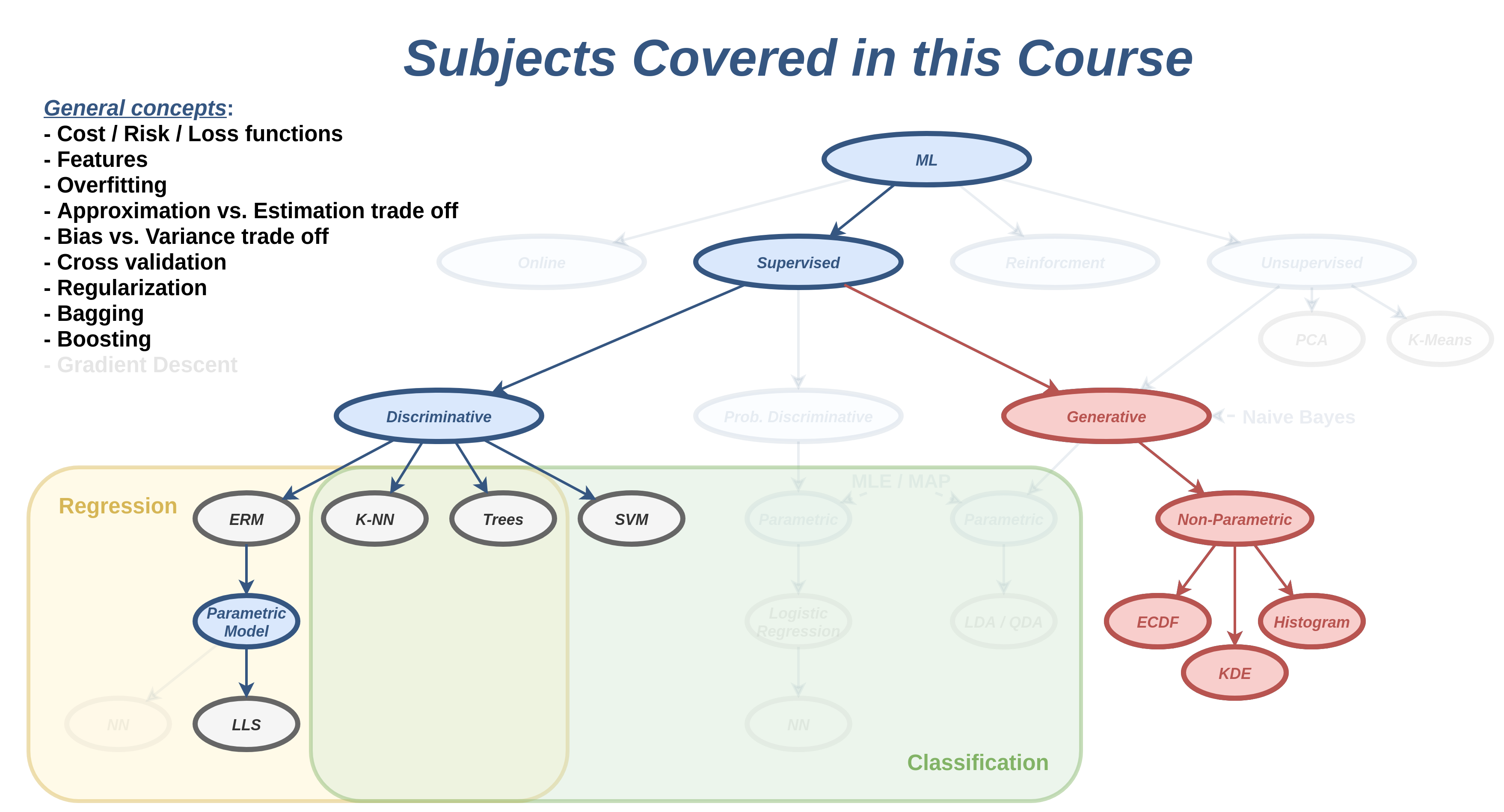
הגישה הגנרטיבית
דיסקרימינטיבי vs. גנרטיבי
עד כה, עסקנו בשיטות לפתרון בעיות supervised learning אשר פעלו תחת הגישה הדיסקרימינטיבית שבה ניסינו באופן ישיר למצוא חזאי אשר יתאים למדגם. בשלושת השבועות הקרובים אנו נכיר גישה אחרת לפתרון בעיות supervised learning אשר נקראת הגישה הגנרטיבית.
כפי שציינו בעבר, ההבדל העיקרי בין בעיות חיזוי קלאסיות לבעיות supervised learning היא העובדה שאין בידינו את הפילוג של המשתנים האקראיים ובמקום זה יש בידינו מדגם מייצג שלהם. בגישה הגינרטיבית ננסה לגשר על פער זה על ידי שימוש במדגם לצורך שיערוך הפילוג של המשתנים האקראיים. בהינתן הפילוג המשוערך אנו נקבל בעיית חיזוי קלאסית אשר לרוב ניתן לפתרון בצורה פשוטה.
ננסה לתאר את ההבדל בין הגישה הדיסקרימינטיבית לגנרטיבית בעזרת השרטוט הבא:
הגישה הדיסקרימינטיבית
מדגם
▼
חזאי בעל ביצועים טובים על המדגם
הגישה הגנרטיבית
מדגם
▼
פילוג על סמך המדגם
▼
חזאי אופטימאלי בהינתן הפילוג
הגישה הגנרטיבית מקבלת את שמה מהעובדה שהיא מנסה ללמוד את החוקיות אשר יצרה (generate) את הדגימות, בעוד שהשיטה הדיסקרימינטיבית רק מנסה להתאים לכל מדידה תווית מתאימה (discriminate).
הקשר לבעיות unsupervised learning
בקורס זה לא נעסוק כמעט בבעיות unsupervised learning אך כן ננצל ההזדמנות זו בכדי לתאר בקצרה את הקשר של שיטות גנרטיביות לבעיות מסוג זה. בבעיות unsupervised learning המדגם לא מכיל שני סוגי משתנים ו , אלא רק סוג בודד. לדוגמא אוסף של תמונות פנים, או אוסף של הקלטות דיבור של אדם מסויים. בבעיות מסוג זה, ננסה לרוב ללמוד מהם התכונות שמאפיינות את הדגימות במדגם. אחת הדרכים הטובות ביותר לתאר את המאפיינים של הדגימות היא על ידי שיערוך של הפילוג שלהם ואכן שיטות גנרטיביות דומות שאלו שנלמד בפרק זה משמשות גם בבעיות unsupervised learning.
שיערוך הפילוג
הבעיה של בניית מודל הסתברותי של משתנים אקראיים מתוך מדגם מכונה בעיית שיערוך (estimation). את המודל ההסתברותי אנו נבטא בעזרת אחת מהפונקציות הבאות:
- פונקציית ההסתברות (probablity mass function - PMF)
- פונקציית צפיפות ההסתברות (probability density function - PDF)
- פונקציית הפילוג המצרפית (cumulative distribution function CDF).
חיזוי ושיערוך
בעיות חיזוי (prediction) ובעיות שיערוך (estimation) קרובים מאד באופי, ובמקרים רבים מבלבלים בין השתיים. ננסה לחדד את ההבדלים בניהם:
- בבעיות חיזוי אנו מועניינים לחזות את ערכו של משתנה אקראי, לרוב על סמך משתנה / וקטור אקראי בודד (דגימה יחידה).
- בבעיות שיערוך אנו מעוניינים לבנות מודל הסתברותי של משתנה / משתנים אקראיים לרוב על סמך הרבה דגימות.
דוגמא לבעיית שיערוך
נסתכל לדוגמא על המדגם של הונאות אשראי מהרצאה הקודמת:
![]()
היינו מעוניינים לבנות על סמך מדגם זה את הפילוג של המשתנים האקראיים. לדוגמא היינו רוצים למצוא פונקציות כדוגמאת אלה אשר יתארו את הפילוג של הדגימות החוקיות ושל ההונאות:
![]()
בשלושת ההרצאות הקרובות אנו נעסוק בשאלה של כיצד לשערך פילוגים מסוגים אלו מתוך המדגם, וכיצד ניתם לבנות על סמך שיערוכים אלו את פונקציית החיזוי.
שיערוך של פונקציות פילוג בשיטות א-פרמטריות
בהרצאה הקרובה נעסוק בשיטות שיערוך אשר מכונות שיטות לא פרמטריות או א-פרמטריות, מהות השם תהיה ברורה יותר אחרי שנציג בהרצאה הבאה את הנושא של שיטות פרמטריות.
שיערוך ההסתברות של מאורע
נתחיל בבעיה פשוטה. ננסה לשערך את ההסתברות להתרחשות של מאורע מסויים על סמך מדגם.
דוגמא
נניח שיש בידינו את המדגם הבא של מדידות של זמני נסיעה (בדקות) מחיפה לתל אביב על כביש החוף:
ברצונינו לשערך את ההסתברות של המאורע שנסיעה מסויימת תיקח פחות משעה, . המשערך הטבעי ביותר לבעיה זו הינו משערך אשר שווה למספר הפעמים היחסי שמאורע זה קרה במדגם הנתון. בדוגמא זו יש 3 מתוך 10 נסיעות שבהן זמן הנסיעה היה קצר משעה, לכן נשערך שההסתברות של מאורע זה הינה:
בדומה לסימון בבעיות חיזוי, נשתמש בסימון "כובע" לציון גודל שאותו אנו חוזים / משערכים באופן אמפירי (על סמך מדגם). בנוסף אנו נקפיד לציין את העובדה שמשערך תלוי במדגם שבו השתמשנו על ידי הוספת מתחת למשערך.
שיטת שיערוך זו מכונה מדידה אמפירית (empirical measure) או משערך הצבה. נרשום את המשערך בצורה פורמלית.
מדידה אמפירית / משערך הצבה (empirical measure)
בהינתן מדגם מסויים , המדידה האמפירית, , הינה שיערוך של הההסתברות, , והיא מחושבת באופן הבא:
נוכל כעת להשתמש בשיטה זו על מנת לנסות ולשערך את הפילוג של משתנים אקראיים.
שיערוך פונקציית ההסתברות של משתנה אקראי דיסקרטי
שיערוך פונקציית ההסתברות (ה PMF) של משתנים אקראיים דיסקרטיים הוא לרוב משימה פשוטה. נסתכל על שתי דוגמאות:
דוגמא 1 - משתנה בינארי
יש בידינו מטבע לא הוגן (כזה שההסתברות שיפול על עץ או על פלי היא לא חצי-חצי). נסמן את תוצאת ההטלה של המטבע ב כך ש 1 מציין עץ ו 0 מציין פלי. בכדי לקבוע את ה PMF של הטלנו את המטבע 10 פעמים וקיבלנו:
גם פה הפתרון הטבעי הוא לשערך את הסתברות לקבל כל ערך של על פי השכיחות של אותו ערך במדגם. זאת אומרת כיוון שמתוך ה10 דגימות יש 2 פעמים את הערך 1 ו8 פעמים את הערך 0 נשערך את ה PMF להיות:
למעשה אנו משתמשים כאן במדידה אמפירית של המאורע ש לשיערוך של כל אחד מהערכים.
דוגמא 2 - משתנה לא בינארי
את אותו השיערוך נוכל כמובן לבצע גם על משתנים דיסקטיים אשר יכולים לקבל מספר כל שהוא של ערכים. דגומא נסתכל על בעיה דומה עם קוביה לא הוגנת שב 10 הטלות שלה התקבלו הדגימות הבאות:
גם כאן נשערך את ההסתברות לקבל כל ערך לפי השכיחות שלו במדגם:
ניסוח פורמאלי
בהינתן מדגם מסויים , נוכל לשערך את ה PMF של משתנה / וקטור אקראי דיסקרטי באופן הבא:
שימו לב שמובטח לנו שנקבל פונקציית הסתברות חוקית (חיובית שהסכום עליה שווה ל1).
שיערוך פונקציית הפילוג המצרפי של משתנה אקראי
ECDF (Empirical Cumulative Distribution Function)
נזכור כי פונקציית הפילוג המצרפי (ה CDF) מוגדרת באופן הבא:
נוכל אם כן לשערך גודל זה על ידי שימוש במדידה האמפירית בעבור המאורע של באופן הבא:
משערך זה נקרא empirical cumulative distribtuion function (ECDF).
דוגמא
נשערך את פונקציית הפילוג המצרפי של המדגם של 10 זמני הנסיעה בכביש החוף
משערך ה ECDF של יהיה במקרה זה:
זוהי למעשה פונקציה קבועה למקוטעין אשר נראית כך:
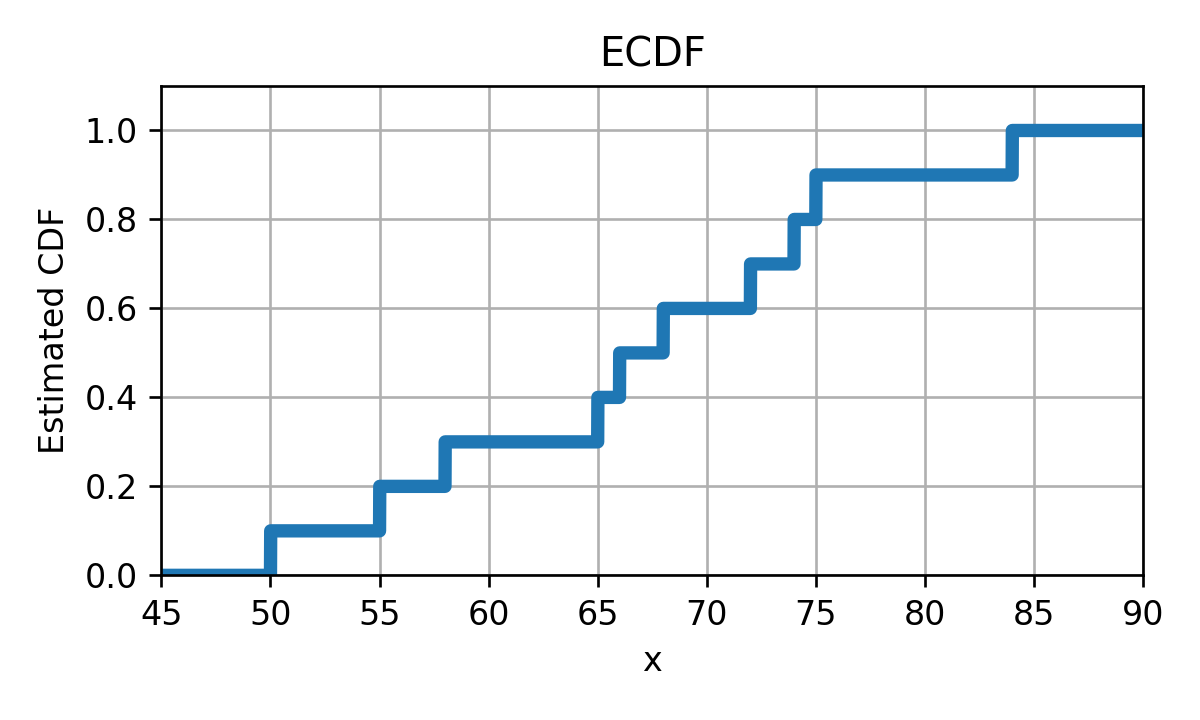
הבעיה עם ECDF
הבעיה העיקרית עם משערך ה ECDF הינה שהוא מייצר פונקציה שהיא קבועה למקוטעין, כאשר בעבור משתנים רציפים היינו מצפים לפונקציה רציפה אשר עולה בהדרגה מ 0 ל 1. אחד הבעיות העיקריות עם העובדה שהפונקציה אינה רציפה הינה פונקציית ה PDF המתקבלת מתוך נסיון לגזור את ה ECDF. פונקציית ה PDF שנקבל תהיה מורכבת מאוסף של פונקציות דלתא:
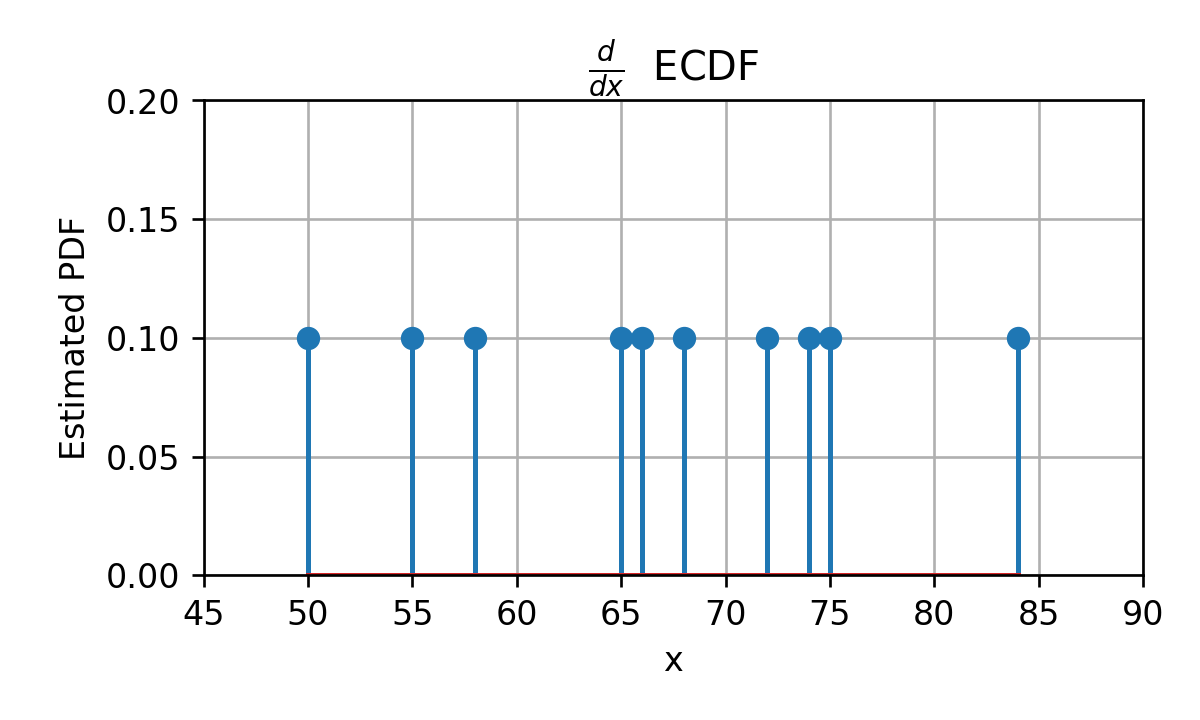
ופונקציה כזו היא לא מאד שימושית.
היסטוגרמה
היסטוגרמה היא מעיין נסיון לשערך פילוג של משתנה רציף על ידי כך שנעשה לו קוונטיזציה. בשיטה זו נחלק את טווח הערכים שמשתנה אקראי יכול לקבל למספר סופי של חלקים המכוונים bins (תאים). אחרי חלוקה זו נשתמש במדידה אמפירת על מנת לשערך את ההסתברות להימצא בכל תא.
דוגמא
לדוגמא בעבור המקרה של של זמני הנסיעה, נוכל לחלק את התחום ל 5 קטעים:
הבחירה של ה bins נעשתה כך שהם יכסו את כל התחום ולא תהיה בניהם חפיפה (כולל בקצוות ה bin). באופן כללי ניתן לבחור את ה bins בכל צורה שהיא כל עוד הם מקיימים את אותם שני תנאים של כיסוי מלא וחוסר חפיפה.
נחשב את ההסתברות להיות בכל bin בעזרת המדידה האמפירית:
בכדי להפוך את ההסתברויות של המאורעות האלה לצפיפות הסתברות נרצה "למרוח" את ההסתברות שקיבלנו להיות ב bin מסויים באופן אחיד על פני ה bin. זאת אומרת שצפיפות ההסתברות בכל נקודה ב bin תהיה ההסתברות להימצא ב bin חלקי גודל ה bin. נקבל אם כן את פונקציית צפיפות הפילוג הבאה:
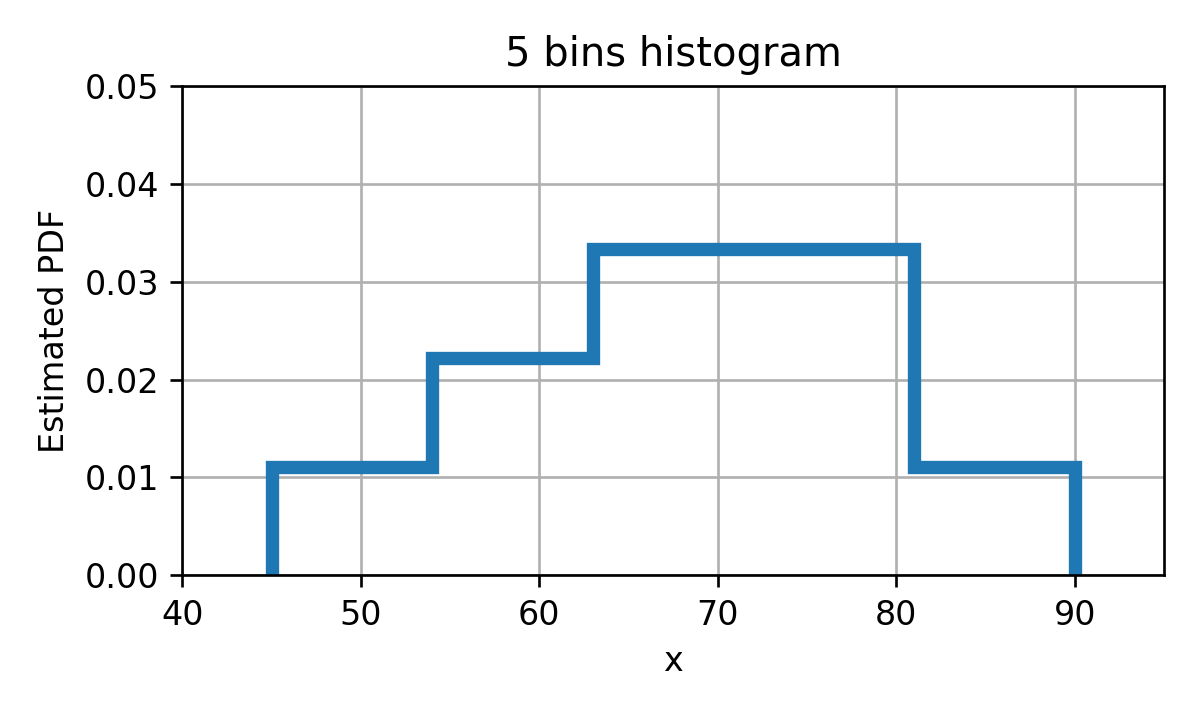
ניסוח פורמאלי
בהינתן מדגם מסויים , ההיסטוגרמה הינה שיערוך של ה PDF של משתנה / וקטור אקראי והיא מחושבת באופן הבא:
- מחלקים את תחום הערכים ש יכול לקבל ל bins (תאים) לא חופפים אשר מכסים את כל התחום.
- לכל bin משערכים את ההסתברות של המאורע שבו יהיה בתוך התא.
- הערך של פונקציית הצפיפות בכל תא תהיה ההסתברות המשוערכת להיות בתא חלקי גודל התא.
נרשום זאת בעבור המקרה של משתנה אקראי סקלרי. נסמן ב את מספר התאים וב ו את הגבול השמאלי והימני בהתאמה של התא ה . ההסטוגרמה תהיה נתונה על ידי:
לבחירת ה bins יש השפעה גדולה על איכות השיערוך שנקבל. ננסה להבין את השיקולים בבחירת ה bins.
Overfitting ו underfitting של היסטוגרמה
דוגמא
נסתכל על שני מקרים קיצוניים. בעבור בחירה של bin יחיד אשר מכסה את כל התחום, נקבל את ההיסטוגרמה הבאה:
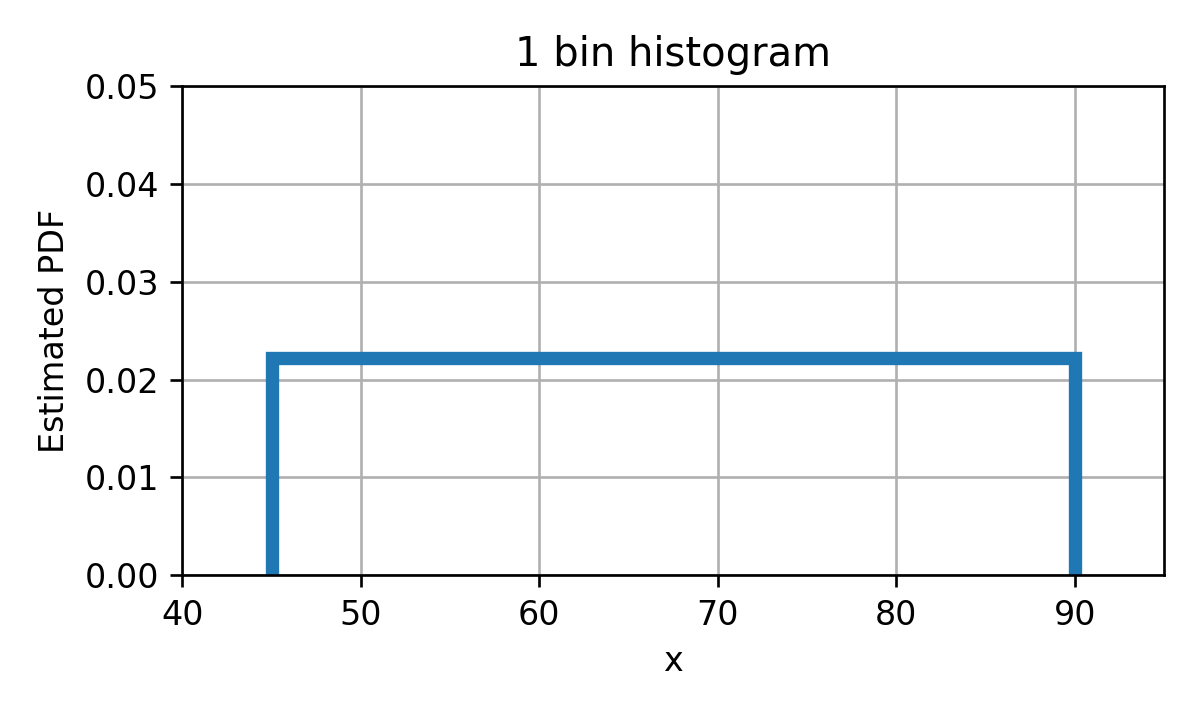
בעבור חלוקה של התחום ל 100 bins בעלי גודל אחיד, נקבל את ההיסטוגרמה הבאה:
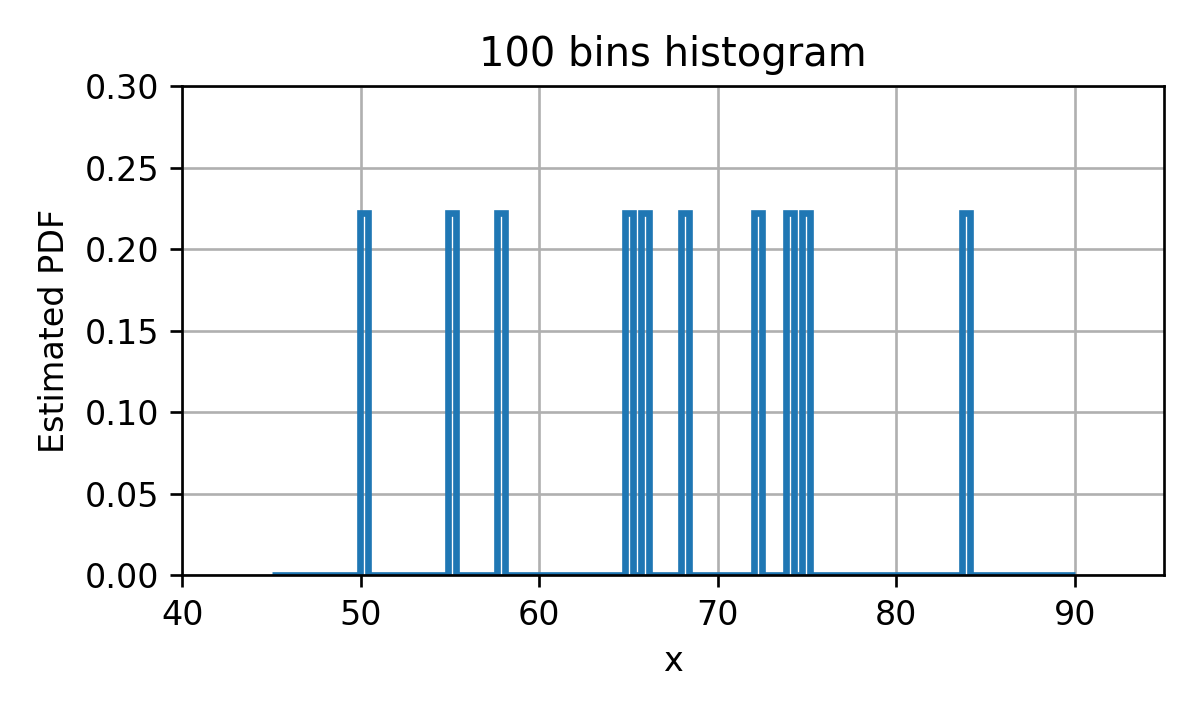
כאשר מספר התאים מאד קטן היכולת שלנו לקרב את ה PDF האמיתי תהיה מאד מוגבלת ולכן נקבל PDF משוערך שמאד שונה מה PDF האמיתי. זהו למעשה מקרה קלאסי של underfitting שבו אנו משתמשים במודל מוגבל אשר יכול ללמוד רק מאפיינים מאד גסים של המדגם וניתן לשפר את התוצאה על ידי שימוש במודל בעל יכול ביטוי גדולה יותר.
מצד שני כאשר מספר ה bin מאד גדול ההיסטוגרמה תתאר בצורה טובה את הפילוג של הדגימות הספציפיות שבמדגם אך כנראה שפילוג זה לא יתאר בצורה טובה את הפילוג של מדגם אקראי אחר, או לחילופין את הפילוג האמיתי של המשתנה האקראי. זהו מקרה קלאסי של overfitting.
גם כאן החלוקה האופטימלית ל bins, שתייצר את פונקציית ההיסטוגרמה הקרובה ביותר ל PDF האמתי, תהיה לרוב איזו שהיא נקודת ביניים בין חלוקה למספר גדול של bins אשר תיצור overfitting לבין חלוקה למספר קטן של bins אשר תייצר underfitting.
הערה: בפסקה האחרונה ציינו את פונקציית ההיסטוגרמה הקרובה ביותר ל PDF האמיתי, כאשר למעשה לא הגדרנו מדד למרחק בין פונקציות צפיפות. מסתבר שזהו נושא חשוב ויש הרבה דרכים לעשות זאת, אך בקורס זה לא נספיק לעסוק בו ונסתפק בהערכה איכותית של השיערוך ולא בהערכה כמותית.
בחירת התאים
בחירה מקובלת של החלוקה לתאים הינה החלוקה של התחום ל תאים אחידים בגודלם. נשאר אם כן לבחור את . מכיוון שה האופטימאלי ישתנה מבעיה לבעיה, נאלץ לרוב לבחור אותו בעזרת ניסוי וטעיה. אך אם זאת, ישנם מספר כללי אצבע אשר במרבית המקרים יתנו תוצאה לא רעה. הכלל הנפוץ ביותר הינו לבחירה של הינה שורש מספר הדגימות במדגם (מעוגל כלפי מעלה):
Kernel Density Estimation (KDE)
נציג כעת שיטה נוספת מאד פופולרית לשיערוך פונקציית pdf מתוך מדגם המכונה kernel density estimation (KDE). בכדי להבין איך השיטה פועלת נתחיל מ PDF שבו אנו ממקמים פונקציית דלתא בגובה בכל נקודה אשר מופיעה במדגם. לדוגמא, בעבור 10 הדגימות של זמני הנסיעה בכביש החוף נקבל:
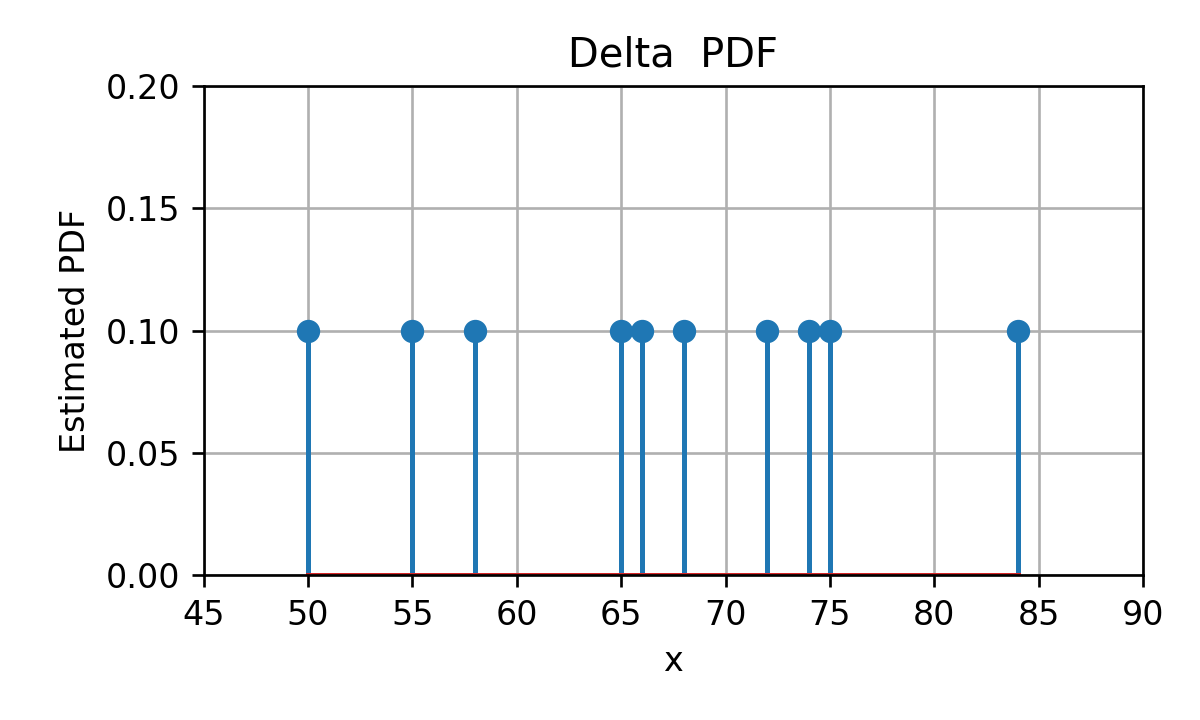
ראינו קודם כי שיטה אחת שבה PDF שכזה מתקבל הינה מתוך נסיון לגזור את פונקציית ה ECDF.
בכדי להפוך את הפילוג הזה ליותר סימפטי ננסה "למרוח" את פונקציות הדלתא על ידי החלפתם בפונקציות בעלות רוחב גדול מ-0 (בניגוד לרוחב 0 של פונקציות הדלתא). לדוגמא, בחירה נפוצה להחלפה שכזו היא החלפה של כל פונקציית דלתא בגאוסיאן:

הפונקציות שבהם אנו מחליפים את פונקציות הדלתא מכונות פונקציות גרעין (kernel) או Parzen window ומקובל לסמנם ב . לאחר ההחלפה של הדלתאות בפונקציות הגרעין, נסכום את כל פונקציות הגרעין שקיבלנו לקבלת ה PDF המשוערך:
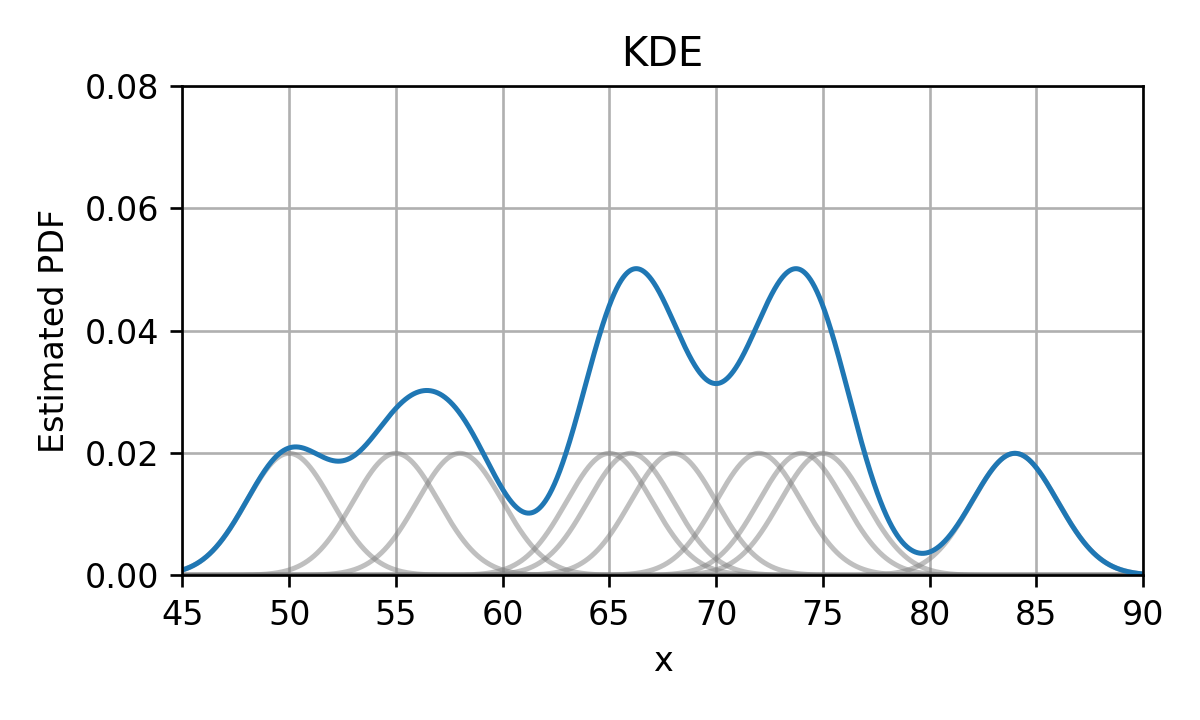
אם כן, משערך ה KDE נתון על ידי:
הערה למי שלקח קורסים בעיבוד אותות: למעשה אנו מבצעים קונבולוציה בין פונקציית הדלתאות לבין פונקציית גרעין כל שהיא. לרוב אנו נרצה שהגרעין ישמש כמעיין low pass filter שמטרתו להחליק את פונקציית הדלתאות.
הערה: תנאי מספיק והכרחי בכדי שנקבל PDF חוקי, הינו שפונקציית הגרעיון תהיה בעצמה PDF חוקי. זאת אומרת שהיא חייבת להיות חיוביות ושהאינטרגל עליה יהיה שווה ל 1.
הוספת פרמטר רוחב
מקובל להוסיף לפונקציות הגרעין פרמטר אשר שולט ברוחב שלה באופן הבא:
החלוקה ב היא על מנת לשמור על הנרמול של הפונקציה. כאשר הוא המימד של .
בתוספת פרמטר זה המשערך יהיה:
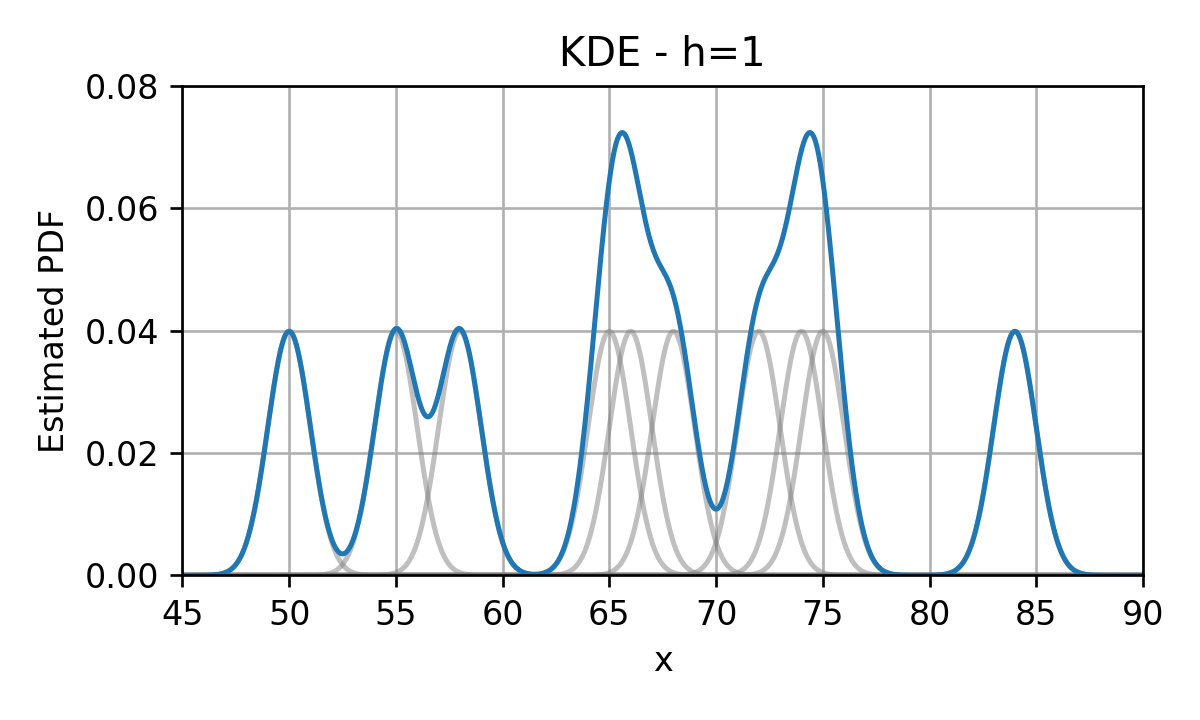
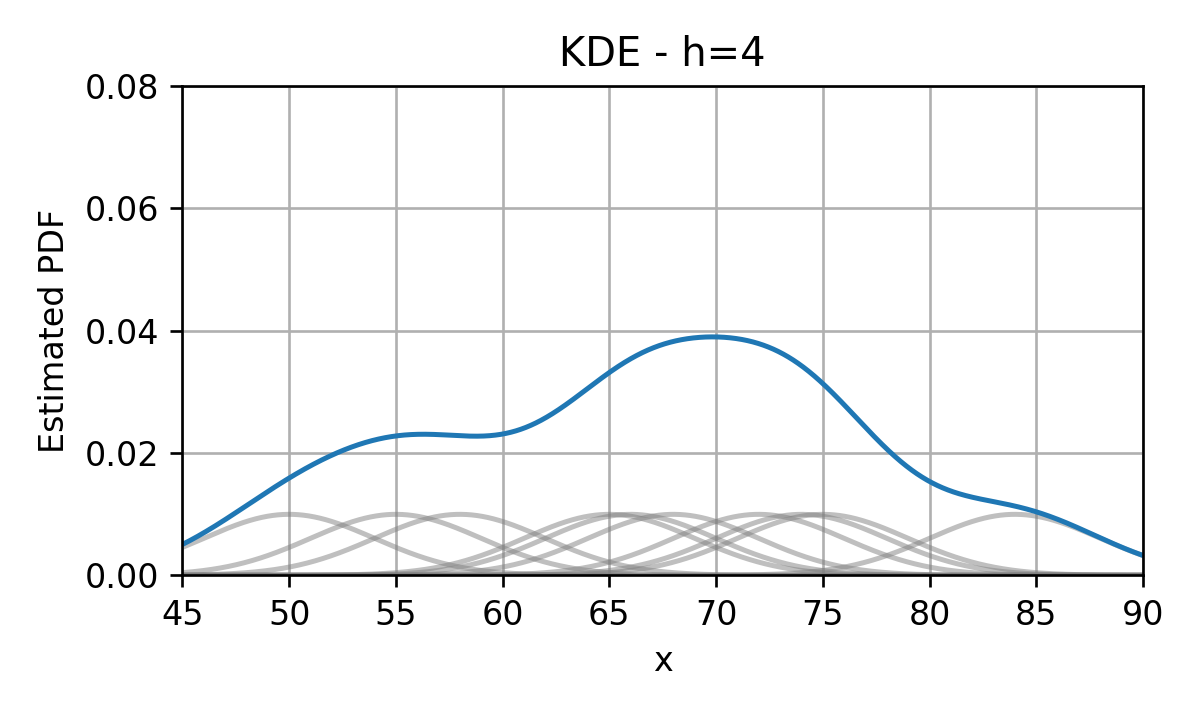
בדומה לבחירה של מספר התאים בהיסטוגרמה גם כאן רוחב הגרעין ישלוט במידת ה overfitting. בעבור גדול נקבל underfitting ובעבור קטן נקבל overfitting.
פונקציות גרעין נפוצות
שתי הבחירות הנפוצות ביותר לפונקציית הגרעין הינן:
-
חלון מרובע:
כלל אצבע עבור חלון ריבועי הוא לבחור בצורה אדפטיבית את גודל החלון כך שיכלול מספר נתון () של דגימות מסביב לנקודה הנחקרת. בחירה סבירה הינה , בדומה למה שעשינו בהיסטוגרמות.
-
גאוסיאן:
כלל אצבע לבחירת רוחב הגרעין במקרה הגאוסי הסקלרי הינו , כאשר הינה הסטיית תקן של (אשר לרוב תהיה משוערכת גם היא מתוך המדגם)
שיערוך של פילוגים מעורבים
במקרים רבים אנו נרצה לשערך פילוגים אשר מערבים משתנים רציפים ומשתנים בדידים. נניח לדוגמא שאנו רוצים לשערך את הפילוג המשותף של ו כאשר הוא משתנה רציף ו הוא משתנה בדיד. במקרים כאלה נוח לפרק את פונקציית הפילוג המשותף באופן הבא:
ואז להפריד את בעיית השיערוך לשני חלקים:
- השיערוך של - שיערוך זה יהיה לרוב פשוט שכן שיערוך זה לא תלוי כלל בערכו של , ו הוא משתנה אקראי דיסקרטי שאותו קל יותר לשערך.
- השיערוך של - כאן יהיה לרוב נוח לפצל את השיערוך למספר שיערוכים שונים בעבור כל ערך אפשרי של . זאת אומרת , , וכו'. הדרך לעשות זאת היא על ידי פיצול של המדגם על פי הערכים של ושיערוך הפילוג של בנפרד על כל חלק של המדגם.
הצורך לשערך פילוגים משותפים מופיע לדוגמא בבעיות סיווג שבהם התוויות הם דיסקרטיות והמדידות הם רציפות.
דוגמא
נחזור לדוגמא של הונאות האשראי:
![]()
נתחיל אם כן בשיערוך של הפילוג של התוויות. כפי שציינו, מכיוון ש בדיד נוכל לשערך בפשטות את ה PMF שלו על פי השכיחות של כל אחד מהערכים 0 ו 1 במדגם. מכיוון שמתוך ה 200 עסקאות שיש במדגם (ב train set) ישנם 160 עסקאות חוקיות () ו 40 עסקאות שחשודות כהונאה () השיערוך של ה PMF של יהיה:
נמשיך לשיערוך של . נשערך בנפרד את ואת .
נתחיל מ . בשביל לשערך פילוג זה נסתכל רק על הדגימות השייכות של :
![]()
נשתמש ב KDE על מנת לשערך את פונקציית הפילוג של מדגם זה:
![]()
באופן דומה נשערך גם את :
![]()
שלושת הפילוגים ששיערכנו, , ו , מרכיבים למעשה את הפילוג המשותף המלא של ו . זאת מכיוון שבעבור כל צמד ערכים של ו נוכל לחשב את הפילוג המשותף שלהם על פי:
שימוש בפילוג המשוערך לפתרון בעיות supervised learning
נחזור כעת לסיבה שבגללה אנו רוצים לנסות לשערך את פונקציית הפילוג של משתנים אקראיים. כפי שציינו קודם, בכדי לפתור בעיות supervised learning בגישה הגנרטיבית נרצה לשערך את פונקציית הפילוג על מנת שנוכל לבנות על פיה את פונקציית החיזוי. נזכיר כי בעבור פונקציות המחיר הנפוצות אנו כבר יודעים מהו החזאי האופטימאלי בהינתן הפילוג:
-
MSE: התוחלת המותנית:
-
MAE: החציון של הפילוג המותנה:
(כאשר היא פונקציית הפילוג המצרפי של בהינתן ).
-
Misclassification rate: הערך הכי סביר (ה mode):
לכן במקרים אלו כל שעלינו לעשות זה להציב את הפילוג שמצאנו לביטוי לחזאי האופטימאלי.
דוגמא
בעבור הפילוג שמצאנו על פי המדגם של הונאות האשראי נחפש את החזאי אשר ממזער את ה misclassification rate. אנו יודעים כי חזאי זה נתון על ידי:
במקרה הבינארי חזאי זה שווה ל:
את נוכל לחשב מתוך הפילוג המשותף באופן הבא:
(זהו למעשה חוק בייס). אם כן, בכדי לבדוק האם עסקה מסויימת הינה הונאה או לא, עלינו לבדוק האם:
אם נציב את פונקציות הפילוג ששיערכנו קודם לכן ונקבל את החזאי הבא:
![]()
ה misclassification rate של חזאי זה על ה test set הינו 0.12.
ה bias וה variance של משערך
בדומה לחזאים שבנינו בגישה הגנריטיבית, גם המשערכים שתיארנו כאן תלויים בצורה חזקה במדגם שאיתו אנו עובדים. לכן, בדומה לאנליזה שעשינו כאשר דיברנו על ה bias-variance tradeoff, גם כאן נוכל להסתכל על האקראיות של השיערוך הנובעת מהאקראיות של המדגם.
נשתמש שוב בסימון בכדי לסמן תוחלת על פני הפילוג של המדגם. בעזרת תוחלת זו נגדיר את המושגים של ה bias וה variance של משערך מסויים:
Bias
בעבור שיערוך של גודל כל שהוא בעזרת משערך , ה bias (היסט) של השיערוך מוגדר כ:
כאשר ההטיה שווה ל-0, אנו אומרים שהמשערך אינו מוטה (Unbiased).
Variance
ה variance (שונות) של המשערך יהיה:
אנו נהיה מעוניינים כמובן במשערך שגם ה bias וגם ה variance שלו קטנים.
מלבד במקרים מאד מנוונים לרוב לא נוכל באמת לחשב את הגדלים האלה. השימוש העיקרי שלנו בהם יהיה בכדי לנסות ולהבין כיצד שינוי מסויים בשיטת ישפיע על איכות השיערוך מתוך ההבנה של האם הוא מקטין או מגדיל את הגדלים האלה.
דוגמא: אנליזה של מספר ה bins במונחים של bias ו variance
כפי שציינו קודם בעבור היסטוגרמה עם נמוך אנו נקבל תופעה של underfitting ובעבור גדול נקבל overfitting. נראה איך זה מתקשר ל bias וה variance של המשערך.
לצורך הדוגמא ננסה לשערך את ה PDF של משתנה אקראי עם פילוג נורמאלי (גאוסי). נעשה זאת בעזרת היסטוגרמות בעלות 3, 7 ו 21 bins. נתחיל בבחינה של ה bias של ההיסטוגרמות, לשם כך נשרטט את ההיסטוגרמה הממוצעת לצד ה PDF האמיתי. בדוגמאות מסוג זה, בהם אנו מייצרים את המדגם בצורה מלאכותית, ניתן לחשב בקירוב את ההיסטוגרמה הממוצעת על ידי מיצוע על מספר גדול של מדגמים או לחילופין (ספציפית במקרה הזה) ניתן לקחת מדגם מאד גדול (לא לכל משערך זה יהיה נכון).
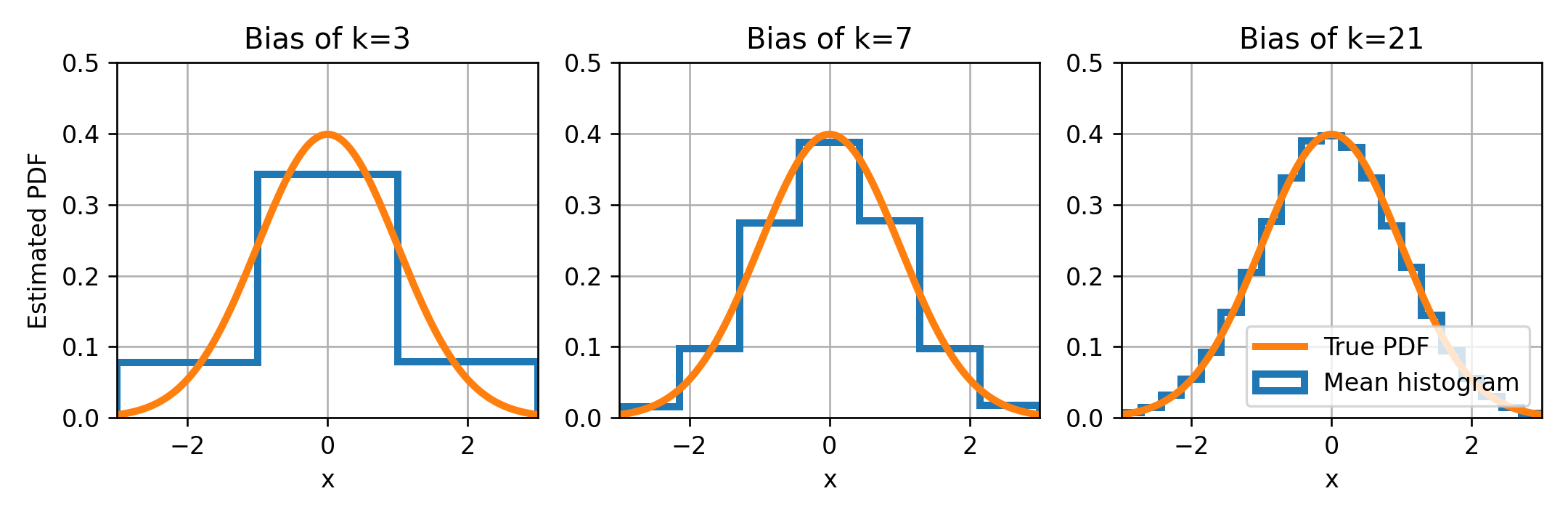
ה bias בגרפים אלו הוא ההפרש בין ההיסטוגרמה הממוצעת ל PDF האמיתי (ההפרש בין הקו הכחול לכתום). ניתן לראות שככל שמספר ה bins גדל כך ההיסטוגרמה הממוצעת מתקרבת ל PDF האמיתי, ניתן אם כך להסיק שבעבור מקרה זה, ה bias של ההיסטוגרמה קטן ככל שמספר ה bins גדל.
נבחן כעת את ה variance של ההיסטוגרמה בעבור כל אחת מהבחירות של כמות ה bins. לשם כך נקח כמה מדגמים שונים ונחשב את ההיסטוגרמה של כל אחד מהם. נסתכל עד כמה משתנה ההיסטוגרמה בין מדגם למדגם. אנו מצפים שבעבור מקרים שבהם ה variance נמוך השינויים יהיו קטנים ובעבור variance גבוה השינויים יהיו גדולים.
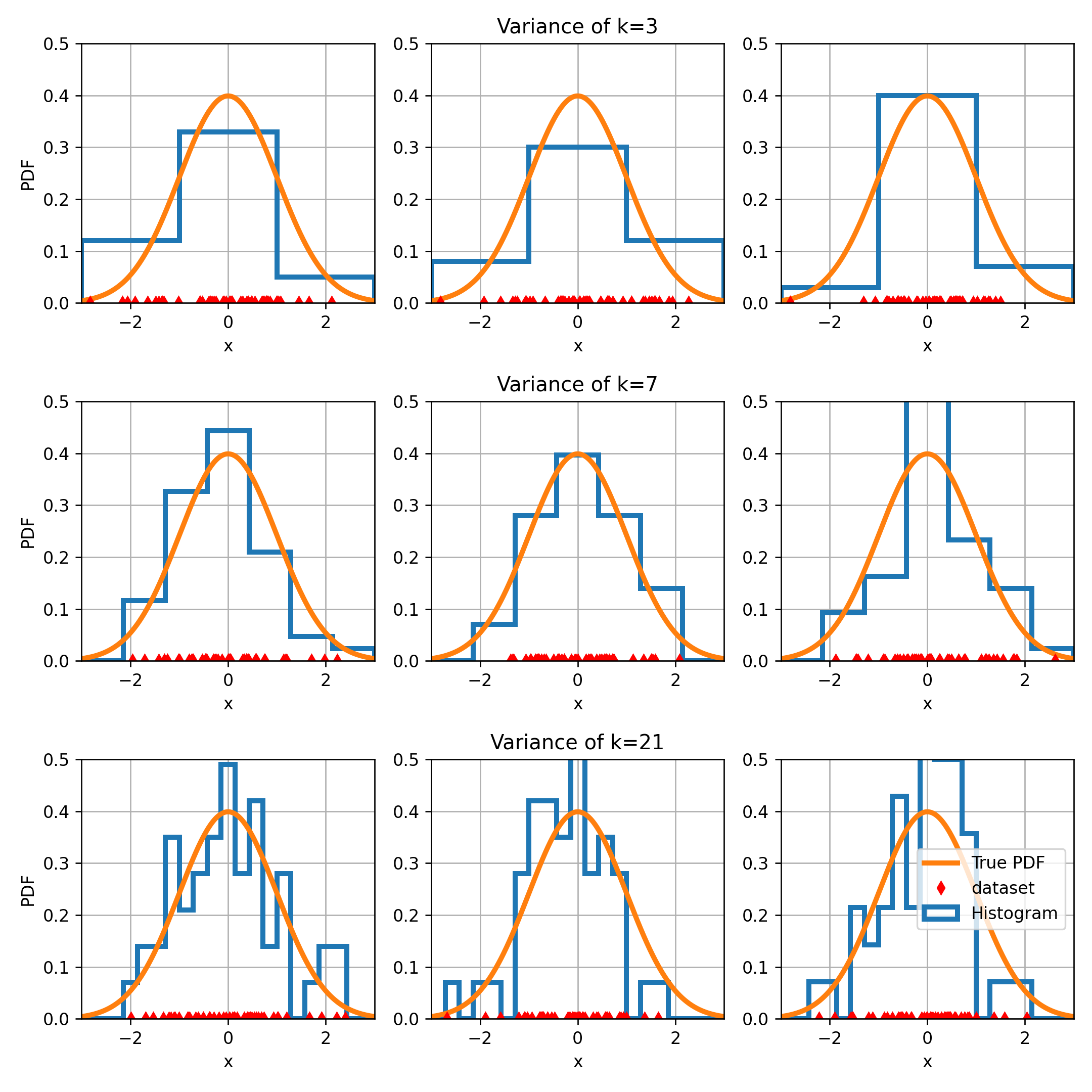
בכל שורה בגרף הזה אנו מגרילים שלושה מדגמים שונים (הנקודות האדומות בתחתית של כל גרף) ומחשבים להם את ההיסטוגרמה. ניתן לראות כי בעבור שלושה bins (השורה הראשונה) אנו מקבלים בערך את אותה התוצאה בעבור כל שלושת המדגמים. מנגד ניתן לראות כי בעבור 21 bins ישנם הבדלים מאד גדולים בין התוצאות המתקבלות בעבור כל אחד מהמדגמים. המשמעות אם כן הינה שבמקרה זה ה variance של ההיסטוגרמה גדל ככל שאנו מגדילים את כמות ה bins.
ראינו עם כן, שבדומה לחזאים שבנינו בגישה הדיסקרימינטיבית, גם בהיסטוגרמה ישנו bias-variance tradeoff וגם כאן אנו נחפש את נקודת האופטימום שמוצאת איזון בין השניים.