הרצאה 6 - SVM ושיטות גרעין
על-מישור (hyperplane)
- הרחבה של מושג המישור למימדים שונים מ2.
- במרחב ממימד D, על-המישור יהיה ממימד D−1.
- בקורס זה נשתמש בשם מישור גם כדי להתייחס לעל-מישורים.
- לא להתבלבל בין w⊤x+b=0 לבין ax+b=y.
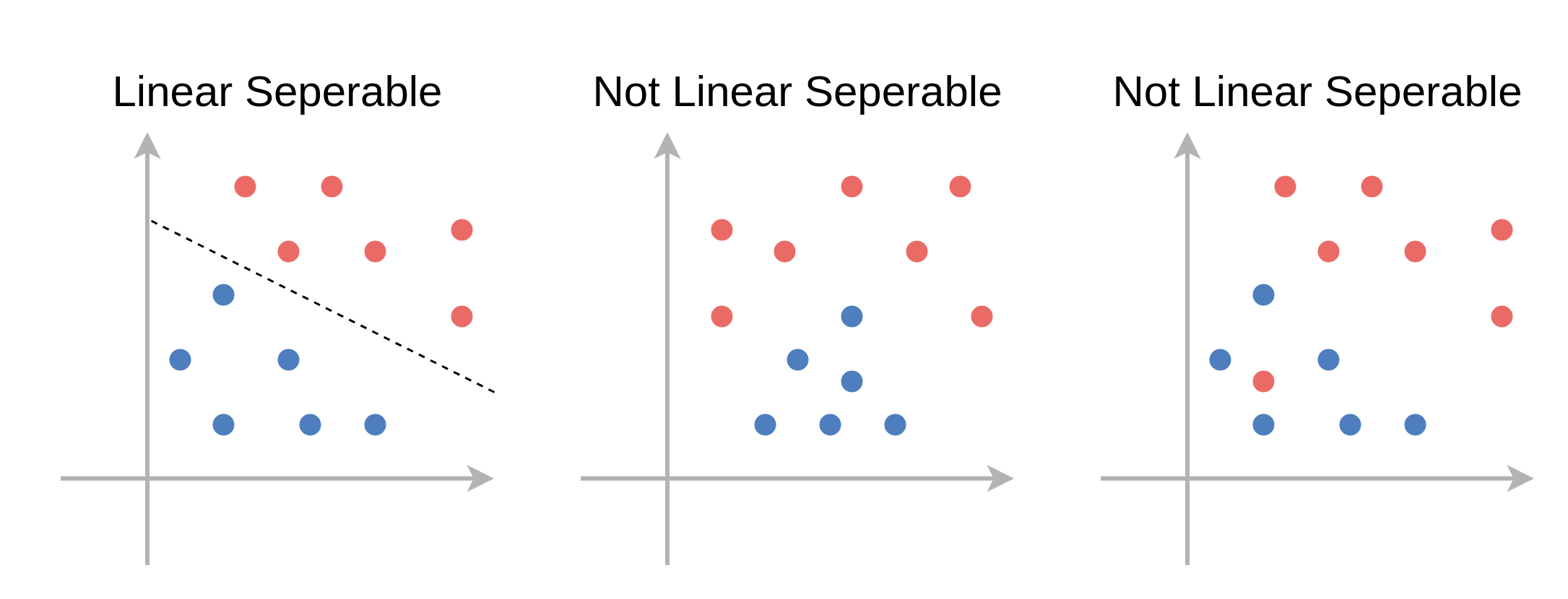
פרידות לינארית (linear separability)
במקרה שבו קיים מישור מפריד אשר מסווג את המדגם בצורה מושלמת (בלי טעויות סיווג) נאמר שהמדגם פריד לינארית.
- לרוב לא נוכל לדעת מראש האם מדגם הוא פריד לינארית או לא.
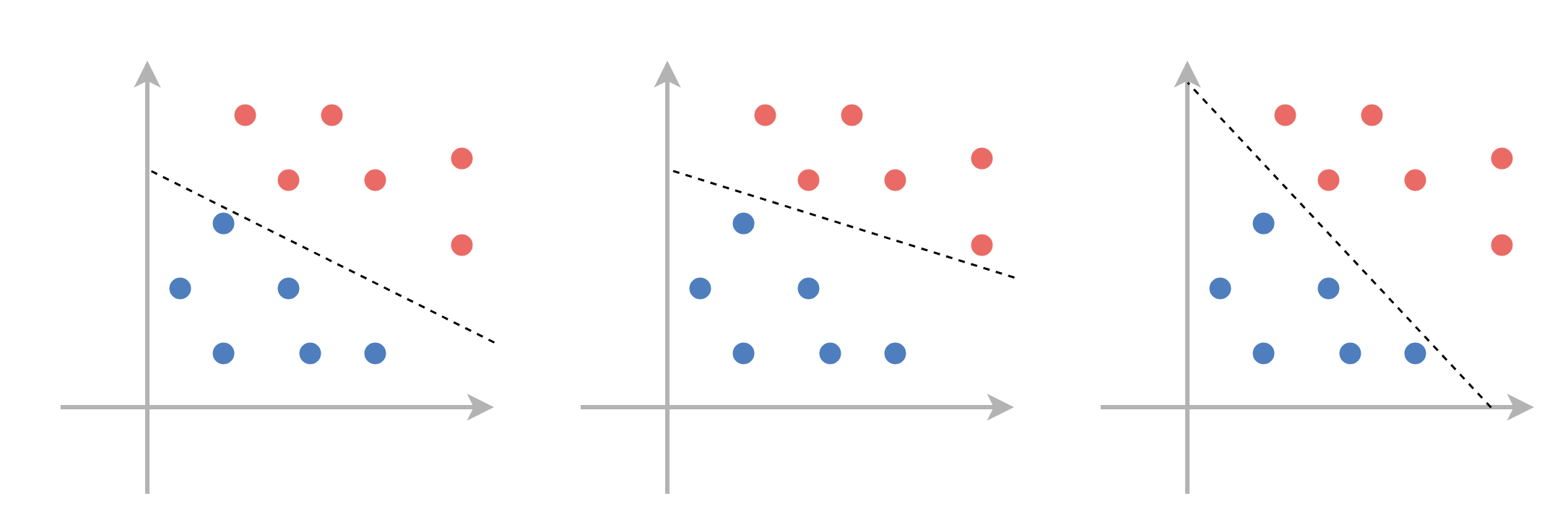
פרידות לינארית (linear separability)
למדגם פריד לינארית יהיה תמיד יותר ממשטח הפרדה אחד:
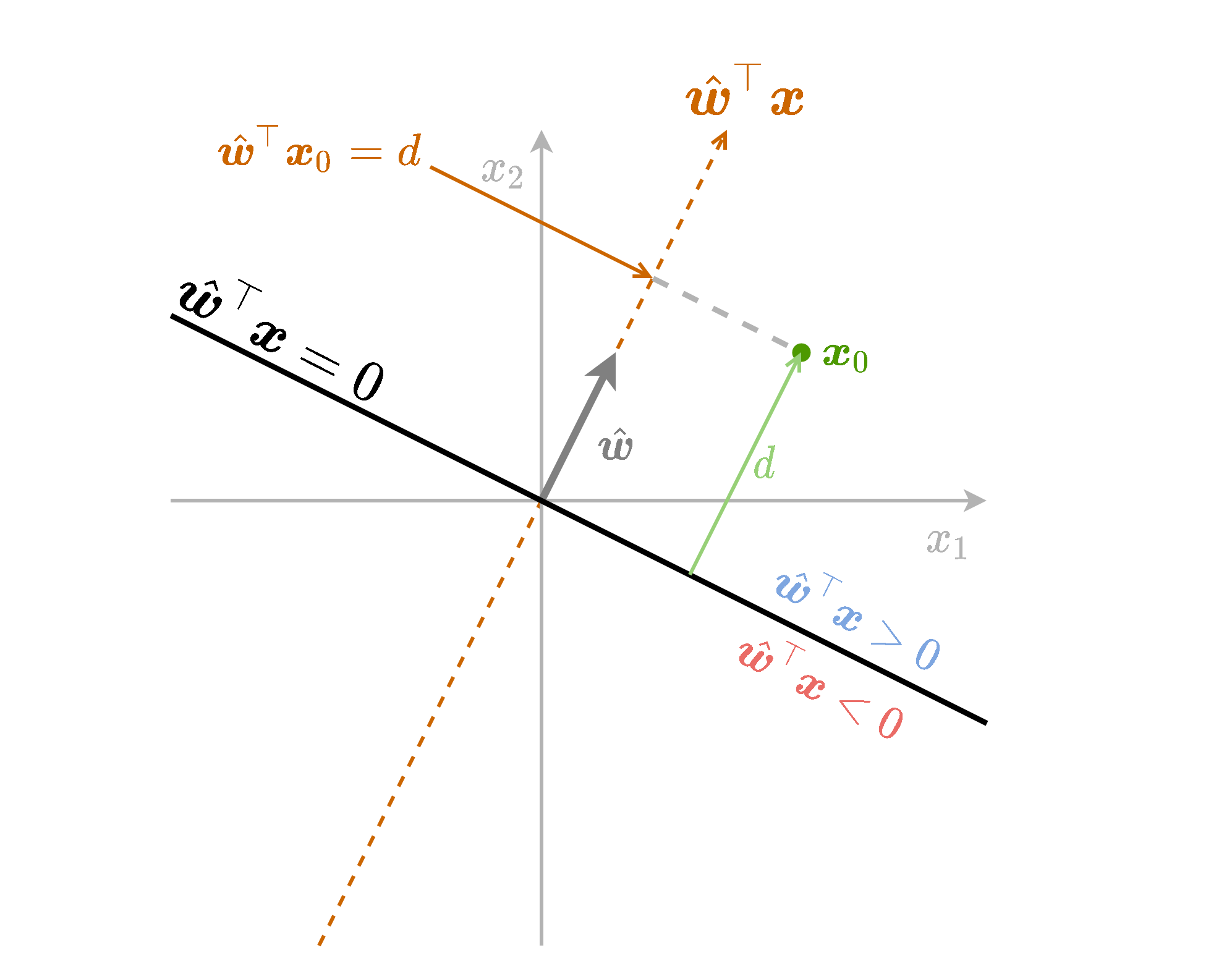
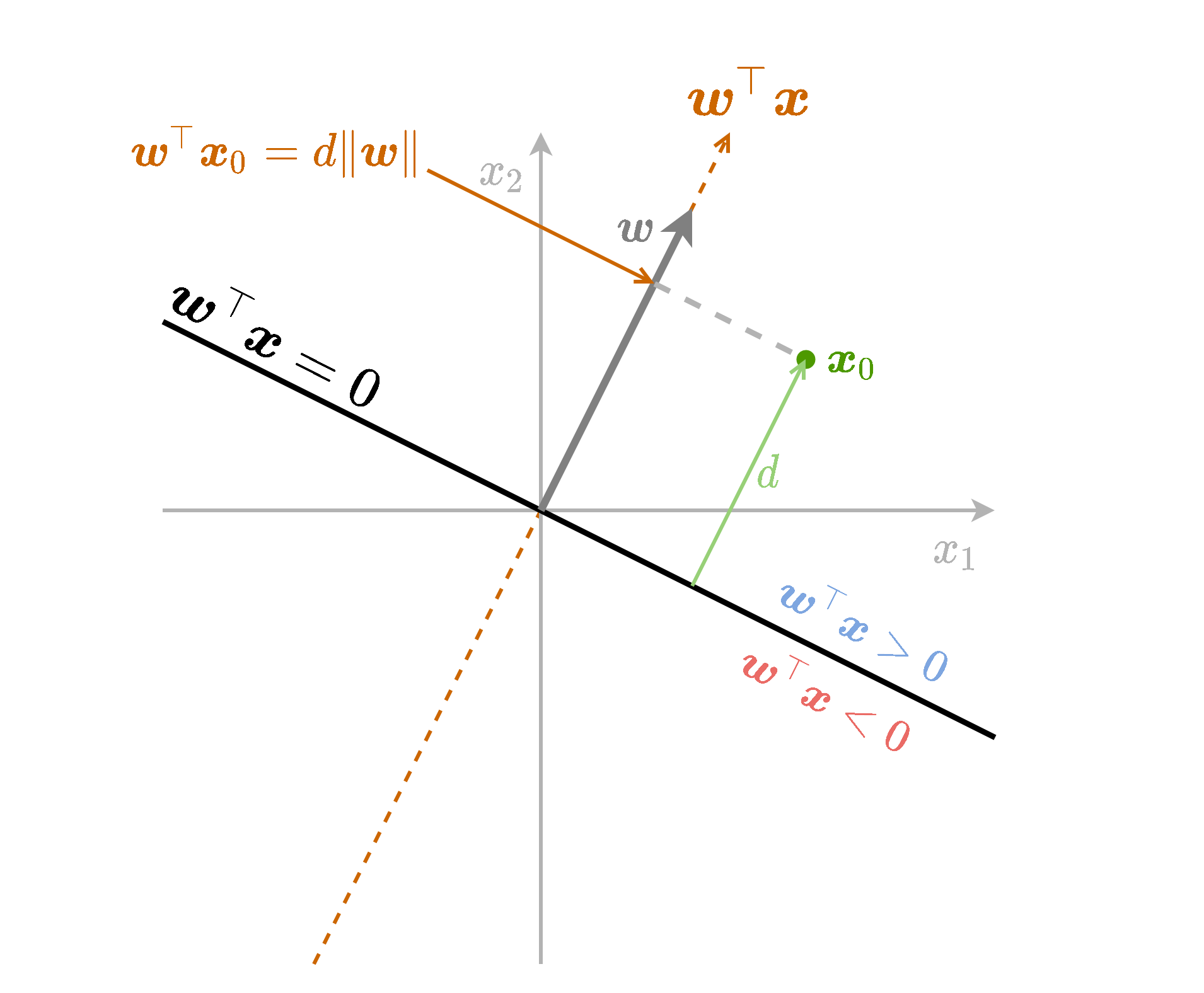
תזכורת - גאומטריה של המישור
נסתכל על הפונקציה f(x)=w^⊤x. משוואה זו מטילה נקודות במרחב על המישור המוגדר על ידי w^ (וקטור יחידה בכיוון של w), ומודדת את האורך של הטלה זו.
תזכורת - גאומטריה של המישור
- מודדת את המרחק מהמישור w^⊤x בתוספת של סימן אשר מציין את הצד של המישור.
- נשתמש בשם signed distance (מרחק מסומן) כדי להתייחס לשילוב של המרחק מהמישור בתוספת הסימן.
תזכורת - גאומטריה של המישור
נחליף את הוקטור w^ בוקטור w. נקבל פונקציה זהה המוכפלת ב ∥w∥2.
ה signed distance יהיה d=∥w∥1w⊤x0.
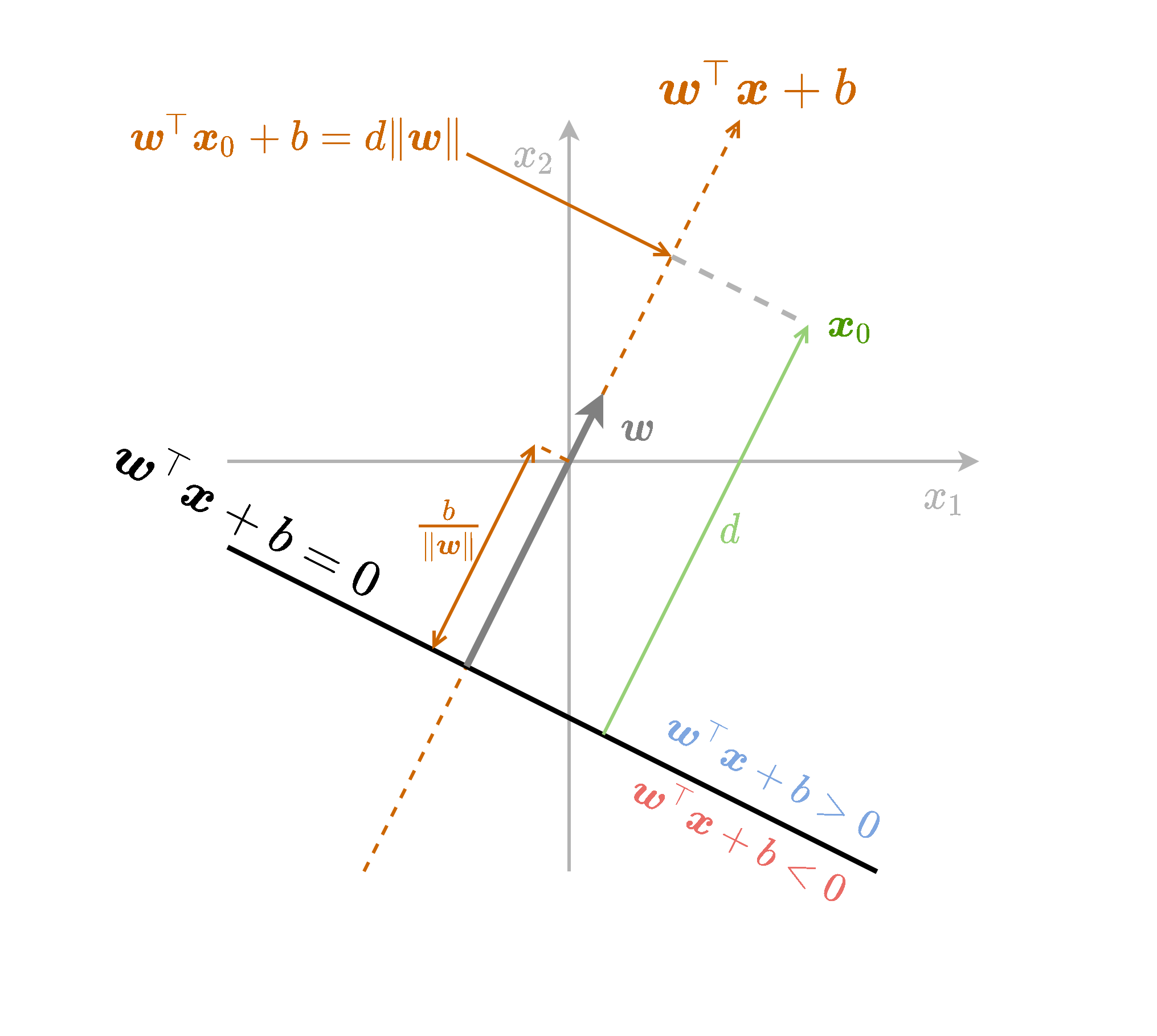
תזכורת - גאומטריה של המישור
נוסיף לפונקציה גם איבר היסט b. ההוספה של הקבוע שקולה להזזה של נקודת ה-0.
ה signed distance יהיה d=∥w∥1(w⊤x0+b)
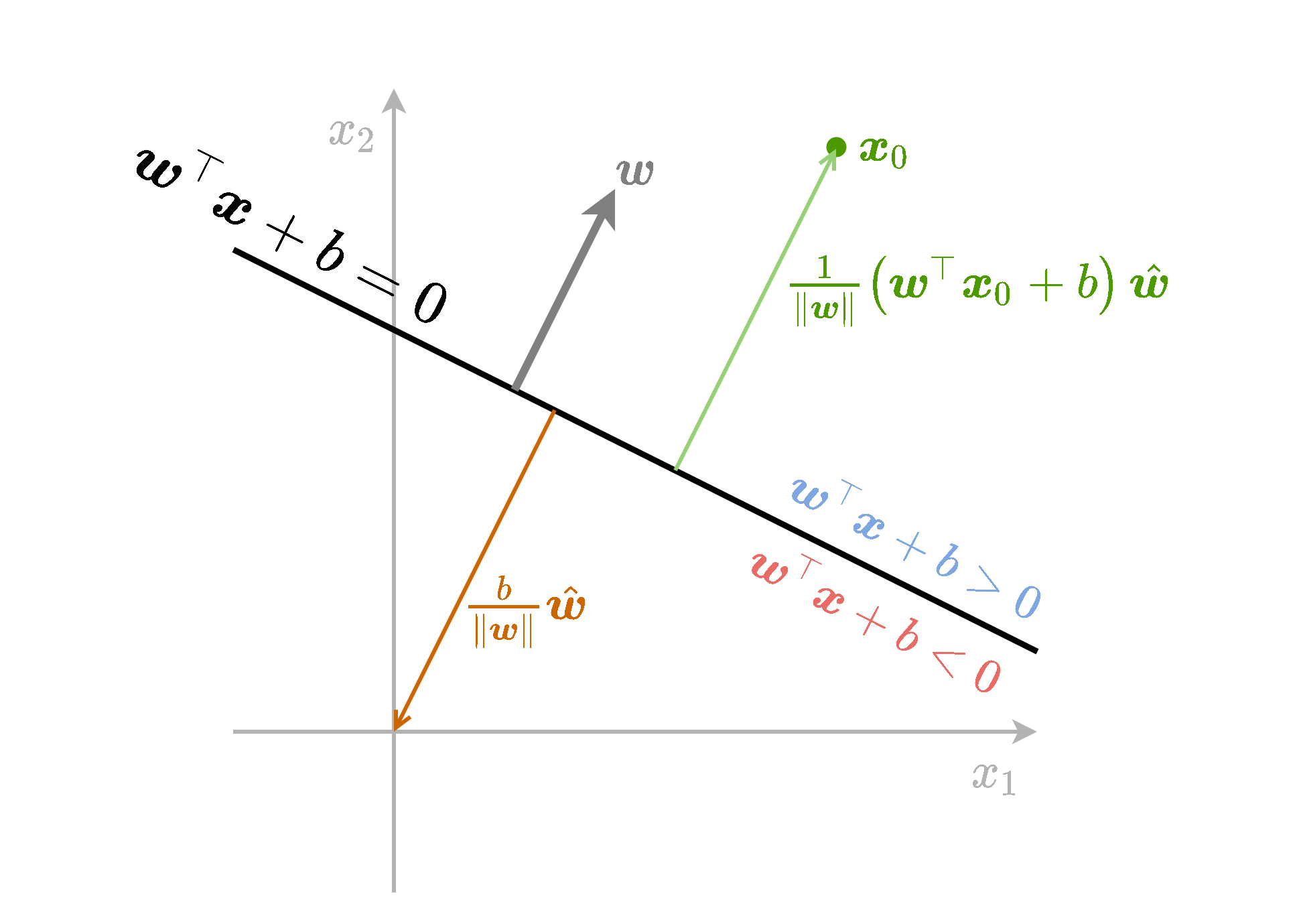
תזכורת - גאומטריה של המישור
נסכם את כל הנאמר לעיל בשרטוט הבא:
אינווריאנטיות לכפל בסקלר
אם נכפיל את גם את w וגם את b בקבוע כל שהוא α שונה מאפס לא נשנה את מיקומו של המישור במרחב, זאת משום ש:
(αw)⊤x+(αb)⇔w⊤x+b=0=0
המשמעות הינה שיש מספר דרכים להגדיר את אותו מסווג לינארי.
Support Vector Machine (SVM)
- אלגוריתם דיסקרימינטיבי לסיווג בינארי (מחפש מסווג טוב על המדגם).
- Hard SVM מחפש מסווג לינארי למדגם שהוא פריד לינארית.
- Soft SVM מרחיב את האלגוריתם למקרה שבו המדגם לא פריד לינארית.
Hard SVM
- Hard SVM מנסה למצוא מישור הפרדה אשר יהיה רחוק ככל האפשר מהנקודות שבמדגם.
- או: נרצה שהמרחק מהמישור לנקודה הקרובה אליו ביותר יהיה מקסימאלי.
שאלה: למה זה רעיון טוב אינטואיטיבית?
Hard SVM
נסתכל על המכפלה בין המרחקים המסומנים של הנקודות לתוויות שלהם ∥w∥1(w⊤x(i)+b)y(i).
- כדי לקבל סיווג מושלם נרצה שכל המכפלות יהיו חיוביות.
- בנוסף ננסה למקסם את המינימום של מכפלות אלו.
Hard SVM
בעיית האופטימיזציה שנרצה לפתור אם כן הינה:
w∗,b∗=w,bargmaximin{∥w∥1(w⊤x(i)+b)y(i)}
- ניתן לנסות לפתור באופן ישיר על ידי gradient descent.
- בפועל העובדה שבבעיה מופיע min על כל המדגם מאד מקשה.
- ניתן לפשט את הבעיה ולמצוא בעיה שקולה, שאותה נכנה הבעיה הפרימאלית.
- את הבעיה הפרימאלית יהיה ניתן לפתור באופן יעיל בשיטות נומריות אחרות.
הפיתוח של הבעיה הפרימאלית
- נוכל לבחור באופן שרירותי קבוע כפלי להכפיל בו את w ו-b.
- בפרט נוכל להוסיף דרישה ש:
imin{(w⊤x(i)+b)y(i)}=1
הפיתוח של הבעיה הפרימאלית
אם נוסיף את האילוץ הזה לבעיית האופטימיזציה נקבל:
w∗,b∗=w,bargmaxs.t.=w,bargmaxs.t.=w,bargmaxs.t.=w,bargmins.t.imin{∥w∥1(w⊤x(i)+b)y(i)}imin{(w⊤x(i)+b)y(i)}=1∥w∥1imin{(w⊤x(i)+b)y(i)}imin{(w⊤x(i)+b)y(i)}=1∥w∥1imin{(w⊤x(i)+b)y(i)}=121∥w∥2imin{(w⊤x(i)+b)y(i)}=1
הפיתוח של הבעיה הפרימאלית
נוכל גם להחליף את האילוץ של imin{(w⊤x(i)+b)y(i)}=1 באילוץ:
(w⊤x(i)+b)y(i)≥1∀i
מובטח שלפחות עבור אחת מהנקודות האילוץ יתקיים בשיוויון: אם זה לא המצב, תמיד נוכל לכפול את w ו-b בקבוע חיובי קטן מספיק כך שהשיוויון יתקיים, וגם נשתפר בפתרון בעיית האופטימיזציה (שמנסה להקטין את ∣∣w∣∣).
הפיתוח של הבעיה הפרימאלית
קיבלנו את בעיית האופטימיזציה השקולה הבאה, היא הבעיה הפרימאלית:
w∗,b∗=w,bargmins.t.21∥w∥2(w⊤x(i)+b)y(i)≥1∀i
שימו לב למספר הגדול של האילוצים!
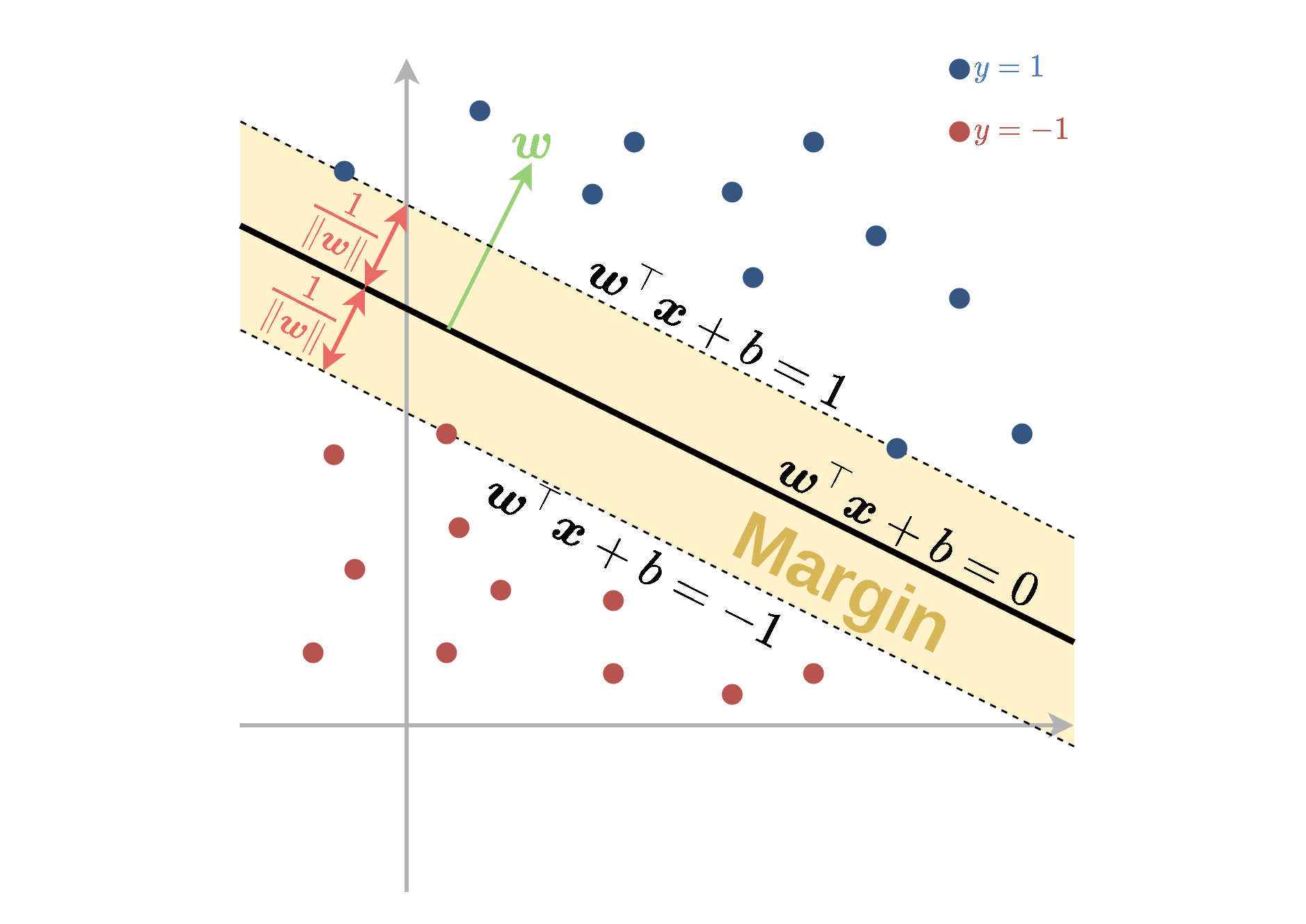
פרשנות
האילוץ דורש שהנקודות מהמדגם יהיו מחוץ לתחום:
1>w⊤x+b>−1
אשר נקרא השוליים (margin).
פרשנות
- המרחק בין מישור ההפרדה לשפה של ה margin שווה ל ∥w∥1.
- בעיית האופטימיזציה מנסה למזער את ∥w∥ ותתכנס למסווג בעל ה margin הגדול ביותר.
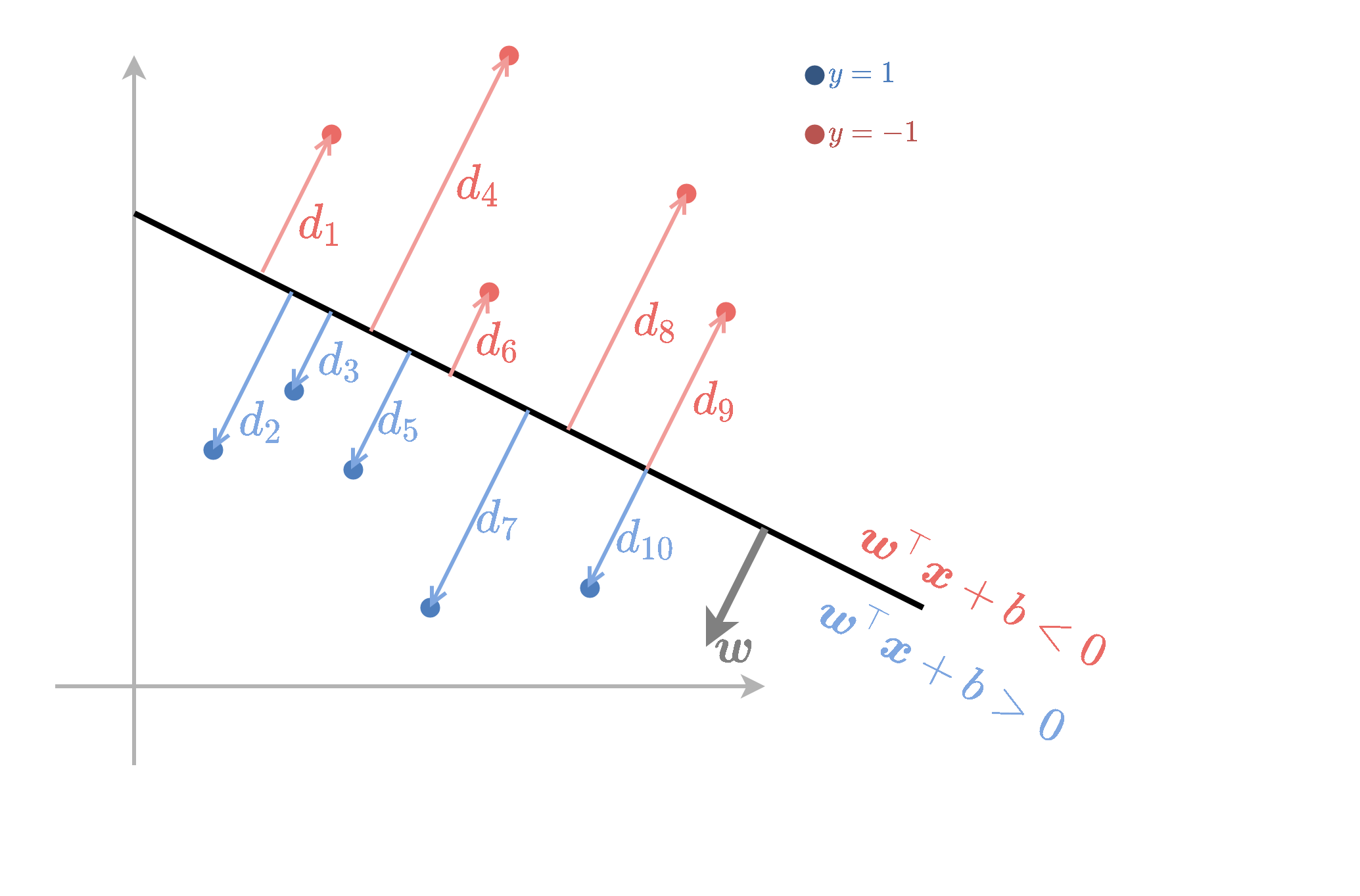
Support Vectors
- ה support vectors הן הנקודות שיושבות על ה-margin והן מקיימות y(i)(w⊤x(i)+b)=1.
- רק נקודות אלו ישפיעו על הפתרון של בעיית האופטימיזציה.
הבעיה הדואלית
דרך שקולה נוספת לרישום של בעיית האופטימיזציה (ללא הוכחה):
נגדיר N משתני עזר נוספים {αi}i=1N בעזרתם ניתן לרשום את הבעיה הדואלית באופן הבא:
{αi}∗={αi}argmaxs.t.[i∑αi−21i,j∑y(i)y(j)αiαjx(i)⊤x(j)]αi≥0∀ii∑αiy(i)=0
יש מספר גדול של משתנים, אך מעט אילוצים.
במודל ניתן למצוא נספח עם הסבר מפורט על אופטימיזציה קמורה בהקשר של SVM.
הבעיה הדואלית
{αi}∗={αi}argmaxs.t.[i∑αi−21i,j∑y(i)y(j)αiαjx(i)⊤x(j)]αi≥0∀ii∑αiy(i)=0
שימו לב שהתלות במאפיינים רק דרך מכפלות פנימיות.
מתוך המשתנים {αi}i=1N ניתן לשחזר את w אופן הבא:
w=i∑αiy(i)x(i)
רק נקודות המדגם שעבורן α חיובי תורמות לסכום.
הערה (הרחבה למתעניינים): המשתנים α הם כופלי לגרנז' מהבעיה הפרימאלית.
הקשר בין αi ו support vectors.
| . |
. |
. |
| נקודות רחוקות מה margin |
y(i)(w⊤x(i)+b)>1 |
αi=0 |
| נקודות על ה margin (שהם support vectors) |
y(i)(w⊤x(i)+b)=1 |
αi≥0 |
חישוב b
- נבחר נקודה מסויימת שעבורה αi>0.
- נקודה כזו בהכרח תהיה support vector ותקיים y(i)(w⊤x(i)+b)=1.
- מתוך משוואה זו ניתן לחלץ את b.
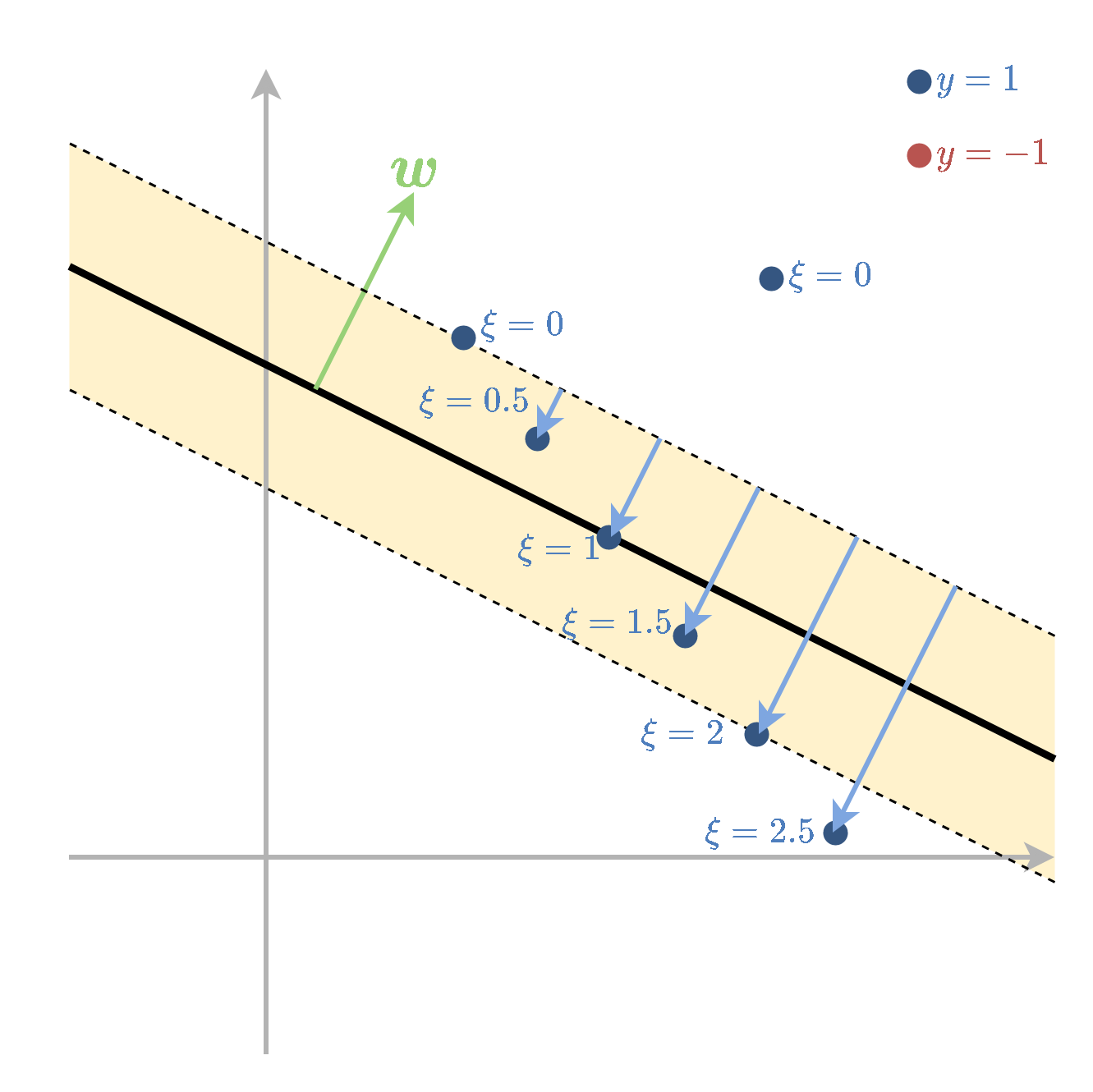
Soft SVM
- מתייחס למקרה שבו המדגם אינו פריד לינארית.
- מאפשרים לנקודות המדגם להיכנס לתוך השוליים ואף לחצות אותם.
- על כל חריגה כזו משלמים קנס בפונקציית המטרה.
Soft SVM
- את החריגה של הדגימה ה i נסמן ב ∥w∥1ξi.
- המשתנים ξi נקראים slack variables.
Soft SVM
ובעיית האופטימיזציה הפרימאלית תהיה
w∗,b∗,{ξi}∗=w,b,{ξi}argmins.t.[21∥w∥2+Ci=1∑Nξi]y(i)(w⊤x(i)+b)≥1−ξi∀iξi≥0∀i
כאשר C הוא היפר-פרמטר אשר קובע את גודל הקנס בפונקציית המחיר על כל חריגה. בבעיה הפרימאלית לא היה היפר-פרמטר.
שאלה: מה ההשפעה של ערכים שונים של המשתנים ξi?
Soft SVM
הבעיה הדואלית הינה
{αi}∗={αi}argmaxs.t.[i∑αi−21i,j∑y(i)y(j)αiαjx(i)⊤x(j)]0≤αi≤C∀ii∑αiy(i)=0
Soft SVM
עבור ה support vectors מתקיים: y(i)(w⊤x(i)+b)=1−ξi
תכונות:
| . |
. |
. |
| נקודות שמסווגות נכון ורחוקות מה margin |
y(i)(w⊤x(i)+b)>1 |
αi=0 |
| נקודות על ה margin (שהם support vectors) |
y(i)(w⊤x(i)+b)=1 |
0≤αi≤C |
| נקודות שחורגות מה margin (גם support vectors) |
y(i)(w⊤x(i)+b)=1−ξi |
αi=C |
כאשר המקרה האחרון כולל נקודות המסווגות נכון ולא נכון.
מאפיינים: תזכורת
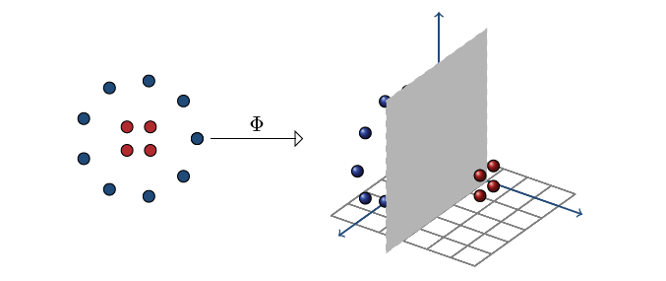
סיווג לינארי מוגבל, ולכן נרצה להרחיב לסיווג לא לינארי.
מאפיינים: דוגמה
נשים לב שהמסווג האופטימלי הוא ריבועי במרחב המקורי.
נשתמש בפונקציית המאפיינים
Φ(x)=(x1,x2,x1x2,x12,x22,1)
ונקבל w⊤Φ(x) שהוא לינארי ב-w.
האיור מתוך, Mohri et-al, Foundation of Machine Learning
פונקציות גרעין
- במקרים רבים החישוב של Φ(x) יכול להיות מסובך אך קיימת דרך לחשב בצורה יעילה את הפונקציה K(x1,x2)=Φ(x1)⊤Φ(x2).
- הפונקציה K נקראת פונקציית גרעין.
- יתרה מזאת, ייתכנו מצבים שבהם וקטור המאפיינים הוא אינסופי אך פונקציית הגרעין היא פשוטה לחישוב.
נציג שתי פונקציות גרעין נפוצות:
- גרעין גאוסי: K(x1,x2)=exp(−2σ2∥x1−x2∥22) כאשר σ פרמטר שיש לקבוע.
- גרעין פולינומיאלי: K(x1,x2)=(1+x1⊤x2)p כאשר p≥1 פרמטר שיש לקבוע.
Kernel Trick in SVM
הרעיון ב kernel trick הינו לעשות שימוש בפונקציית הגרעין על מנת להשתמש ב SVM עם מאפיינים מבלי לחשב את Φ באופן ישיר.
עבור פונקציית מאפיינים Φ עם פונקציית גרעין K הבעיה הדואלית של SVM הינה:
{αi}∗={αi}argmaxs.t.i∑αi−21i,j∑y(i)y(j)αiαjK(x(i),x(j))αi≥0∀ii∑αiy(i)=0
Kernel Trick in SVM
{αi}∗={αi}argmaxs.t.i∑αi−21i,j∑y(i)y(j)αiαjK(x(i),x(j))αi≥0∀ii∑αiy(i)=0
שאלה: מה הקשר לבעיה הדואלית בשקף 25?
בעיית אופטימיזציה זו מגדירה את המשתנים {αi} בלי צורך לחשב את Φ באופן מפורש בשום שלב.
Kernel Trick in SVM
באופן כללי, הפרמטר w נתון על ידי:
w=i∑αiy(i)Φ(x(i))
אשר מצריך חישוב של Φ. ניתן להימנע מכך על ידי הצבה של w כמו שהוא ישירות לחזאי.
h(x)=sign(w⊤Φ(x)+b)=sign(i∑αiy(i)Φ(x(i))⊤Φ(x)+b)=sign(i∑αiy(i)K(x(i),x)+b)
בדרך זו אנו יכולים לאמן להשתמש בחזאי אשר אומן בעבור וקטור מאפיינים Φ מבלי לחשב בשום שלב את Φ באופן מפורש.
סיכום: תכונות מסווג SVM
במקרה הפריד לינארית:
- איטואיטיבי וקל להבנה - ייצוג פשוט של הפתרון
- מבטיח ביצועי הכללה טובים בזכות השוליים הרחבים (לא הראינו) - סוג של רגולריזציה
- יעיל חישובית
במקרה הלא פריד לינארית:
- מתווסף היפר-פרמטר שיש לכוון
- הבנה אינטואיטיבית פחותה
- מעבר פשוט ונוח למסווגים לא לינאריים ע"י שיטות גרעין