הרצאה 6 - SVM ושיטות גרעין
מה נלמד היום
סיווג לינארי
בפרק זה נעסוק בבעיית סיווג בינארי. לשם הנוחות נסמן את שתי המחלקות ב . בפרט נעסוק בסוג מסויים של מסווגים מהצורה:
עם ן כל שהם. מסווגים אלו מכוונים מסווגים לינאריים. מסווגים מסוג זה מתקבלים לדוגמא בעבור LDA או linear logistic regression. מסווגים אלו מחלקים את המרחב לשני חלקים אשר נמצאים משני צידיו של על-מישור (hyperplane) המוגדר על ידי המשוואה המכונה מישור ההפרדה.
על-מישור הוא הרחבה של מושג המישור למימדים שונים מ2. במרחב ממימד על המישור יהיה ממימד . לדוגמא, במימד אחד על-המישור הוא נקודה, בדו מימד על-המישור הוא קו ובתלת מימד על-המישור הוא מישור דו מימדי. לשם הפשטות, בקורס זה נשתמש בשם מישור גם כדי להתייחס לעל-מישורים.
שימו לב: חושב לא להתבלבל בין המשוואה לבין המשוואה אשר מגדירה משוואה לינארית במרחב של ו . שני הצורות האלה אומנם קרובות אך הם לא אותה משוואה וגם האיבר החופשי, שבשניהם מסומן לרוב ב הוא לא אותו .
פרידות לינארית (linear separability)
בהרצאה זו אנו נתייחס לשני מקרים, הראשון בו קיים מישור מפריד אשר מסווג את המדגם בצורה מושלמת (בלי טעויות סיווג) ושני בו לא ניתן למצוא מישור כזה. על מדגמים מהסוג הראשון נאמר שהם פרידים לינארית. להלן דוגמאות לשני סוגי המדגמים:
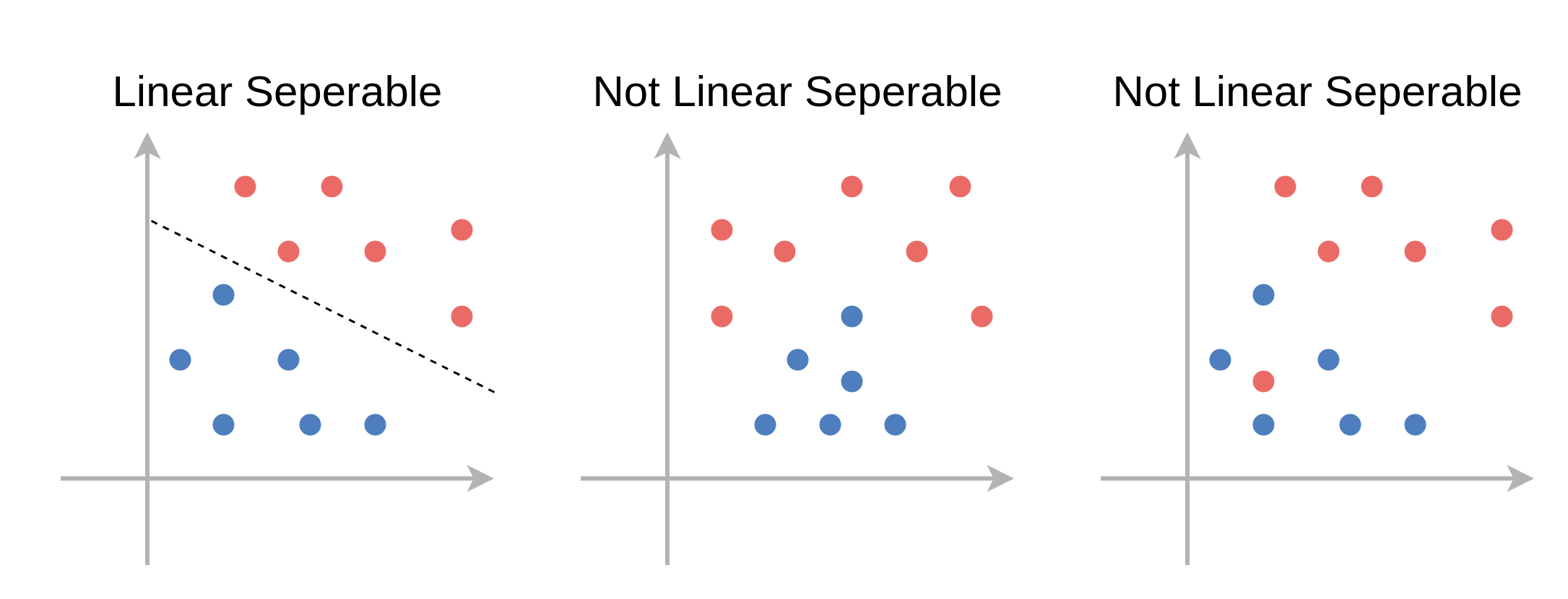
חשוב לציין שחלוקה זו לשני סוגי המדגמים רלוונטית רק לדיון התיאורטי, שכן לרוב לא נוכל לדעת מראש אם מדגם הוא פריד לינארית או לא.
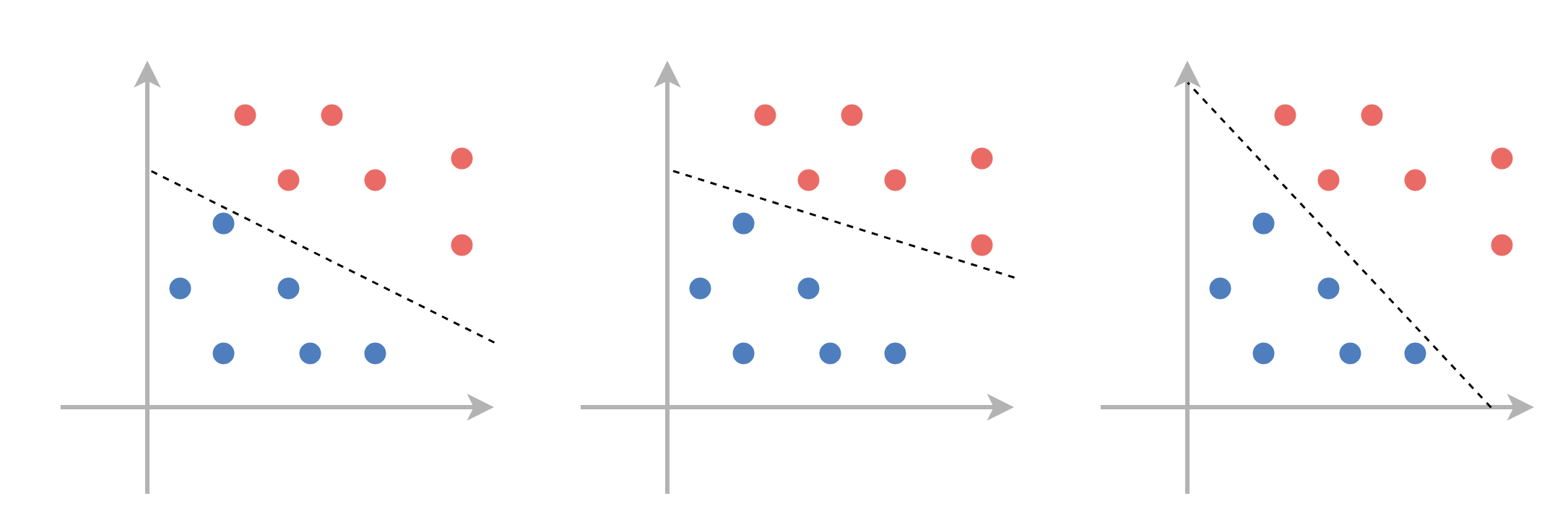
למדגם פריד לינארית יהיה תמיד יותר ממשטח הפרדה אחד אשר יכול לסווג בצורה מושלמת את המדגם. לא נוכיח זאת, אך נראה דוגמא לכך על המדגם הבא:
בחלקה הראשון של הרצאה זו נסתכל על המקרה של מדגם פריד לינארית ונציג את אלגוריתם ה hard SVM אשר מנסה לבחור בצורה חכמה את מישור ההפרדה הטוב ביותר. בחלקה השני של ההצראה נציג את אלגוריתם ה soft SVM אשר מרחיב את האלגוריתם גם למקרה שבו המדגם אינו פריד לינארית.
תזכורת - גאומטריה של המישור
לפני שנציג את אלגוריתם ה SVM נתעכב לרגע על המשוואת המישור כדי לקבל קצת אינטואיציה לגבי התפקיד של ו במשוואה זו.
נתחיל מלהסתכל על גרסא פשוטה יותר של משוואת המישור שבה אין איבר היסט (איבר חופשי) ו הוא וקטור יחידה . ספציפית, נסתכל על הפונקציה . משוואה זו מטילה נקודות במרחב על המישור המוגדר על ידי ומודד את המרחק של הטלה זו.
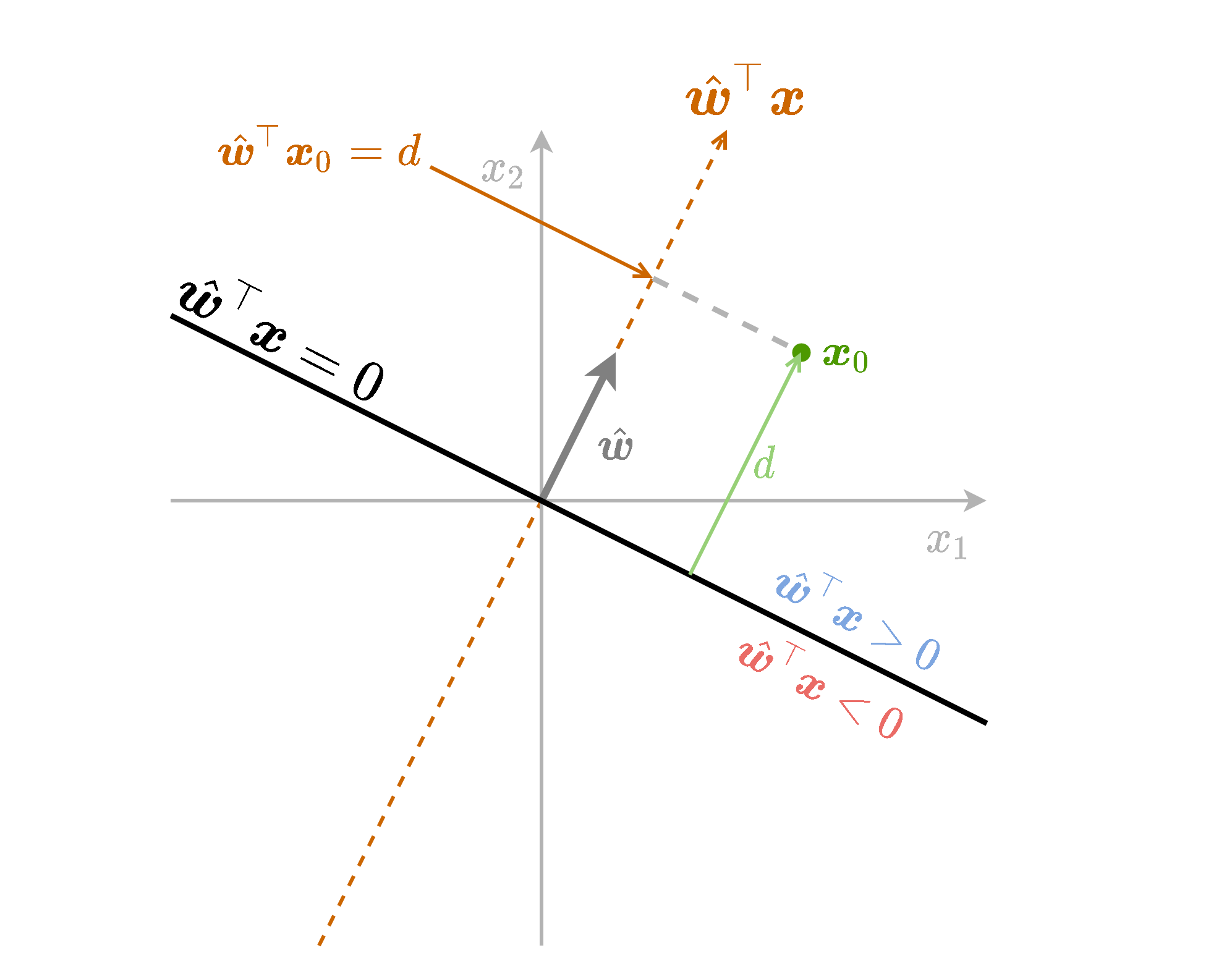
פונקציה זו למעשה מודדת את המרחק של הנקודה כל שהיא מהמישור של בתוספת של סימן אשר מציין את הצד של המישור בו נמצאת הנקודה. בחצי המרחב שעליו מצביע הוקטור הפונקציה חיובית והיא שלילית בחצי השני.
נשתמש בשם signed distance (מרחק מסומן) כדי להתייחס לשילוב של המרחק מהמישור בתוספת הסימן המתאים לצד של המישור.
כעת נחליף את הוקטור בוקטור כל שהוא (שאינו וקטור יחידה). נקבל את הפונקציה שזהה לפונקציה הקודמת רק מוכפלת ב (נורמת של . בחלק מהמקרים נשמיט את ה ונרשום רק ):
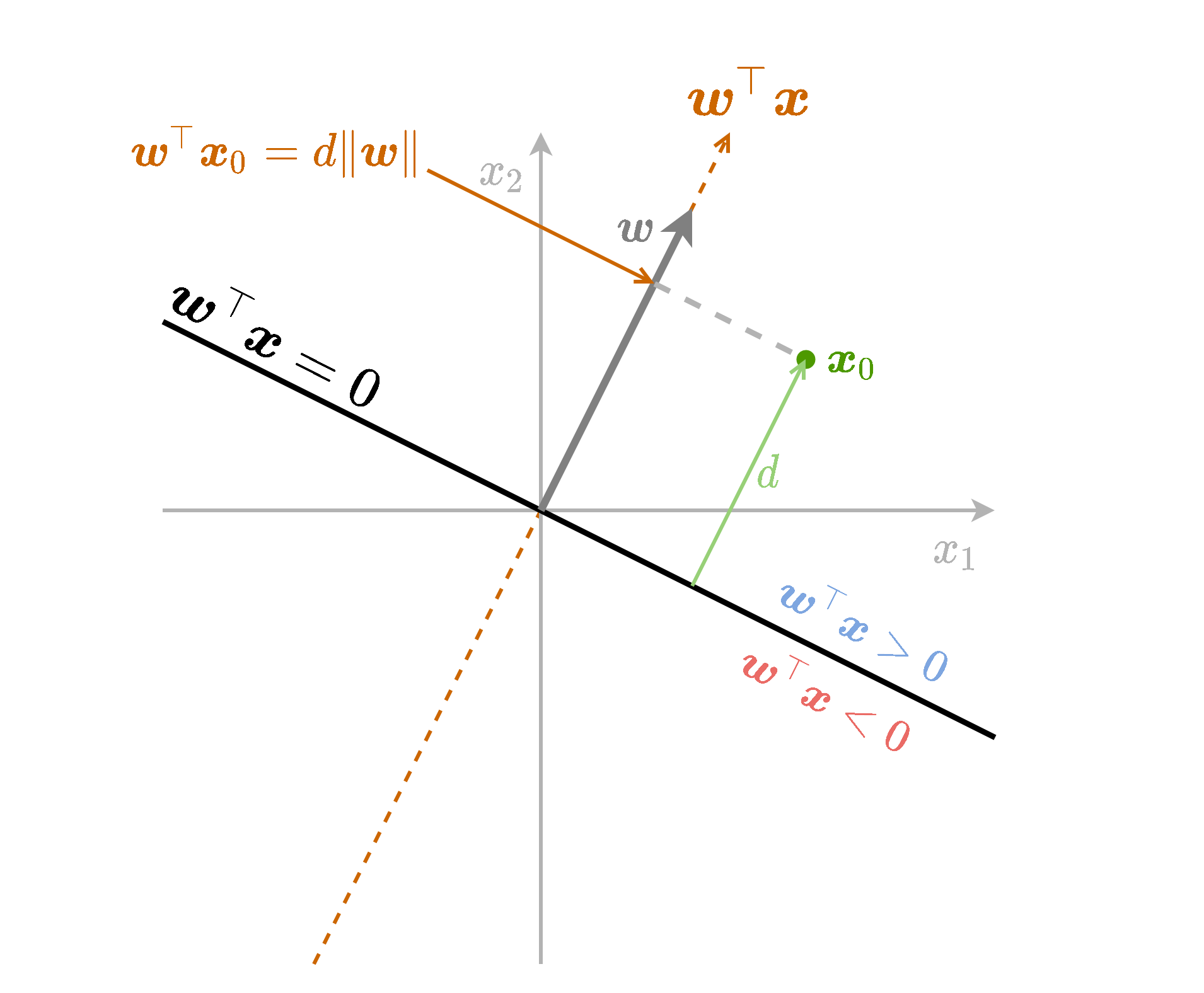
במקרה זה ה signed distance של נקודה כל שהיא מהמישור יהיה .
כאשר נוסיף לפונקציה גם איבר היסט נקבל את הפונקציה . ההוספה של הקבוע למעשה שקולה להזזה של נקודת ה-0 שממנה מודדים את ההטלה בכיוון ההפוך ל . המרחק שבו צריך להזיז את האפס לאורך הקו הינו .
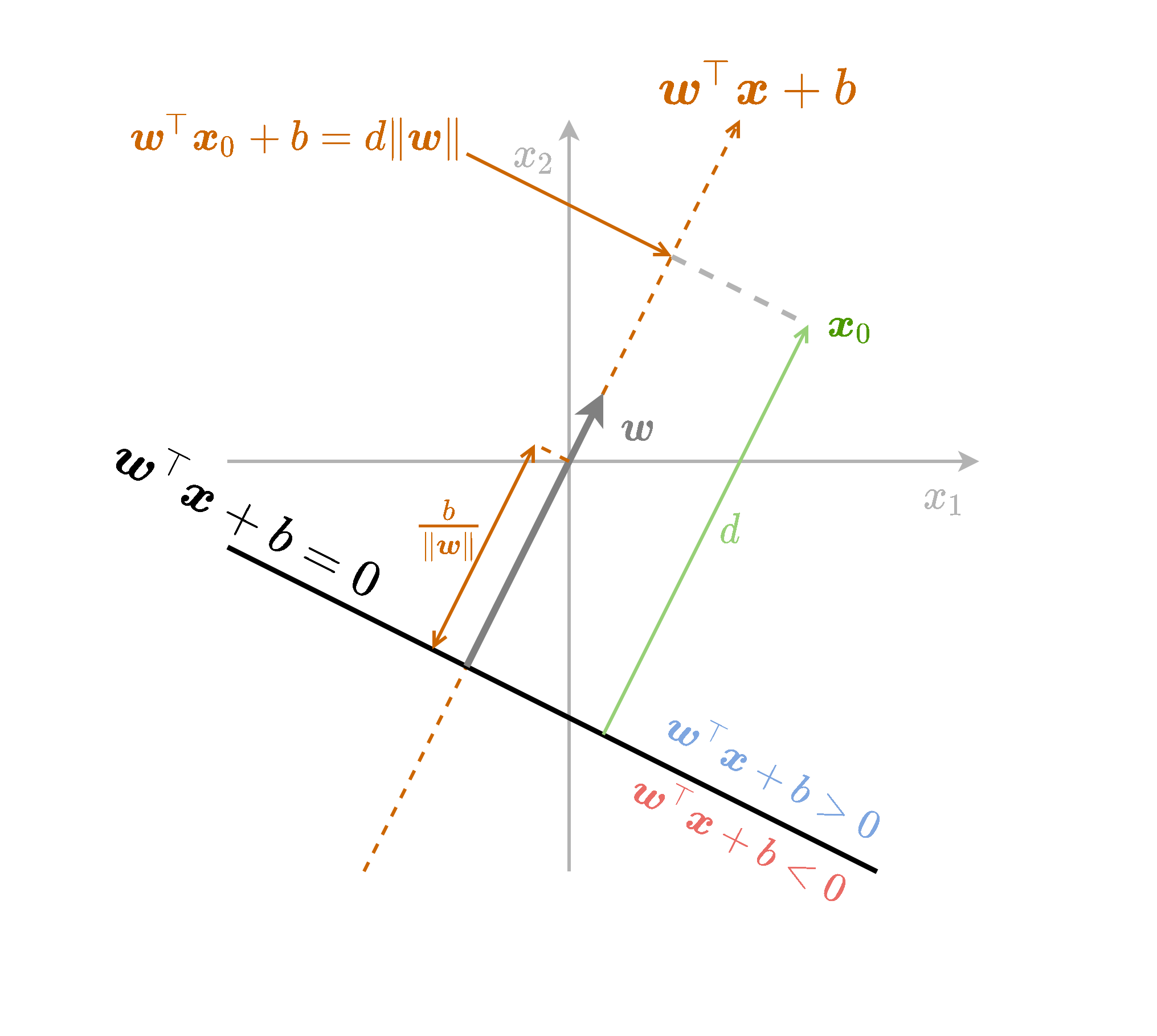
כאן ה signed distance של נקודה כל שהיא ממישור הינו:
נסכם את כל הנאמר לעיל בשרטוט הבא:
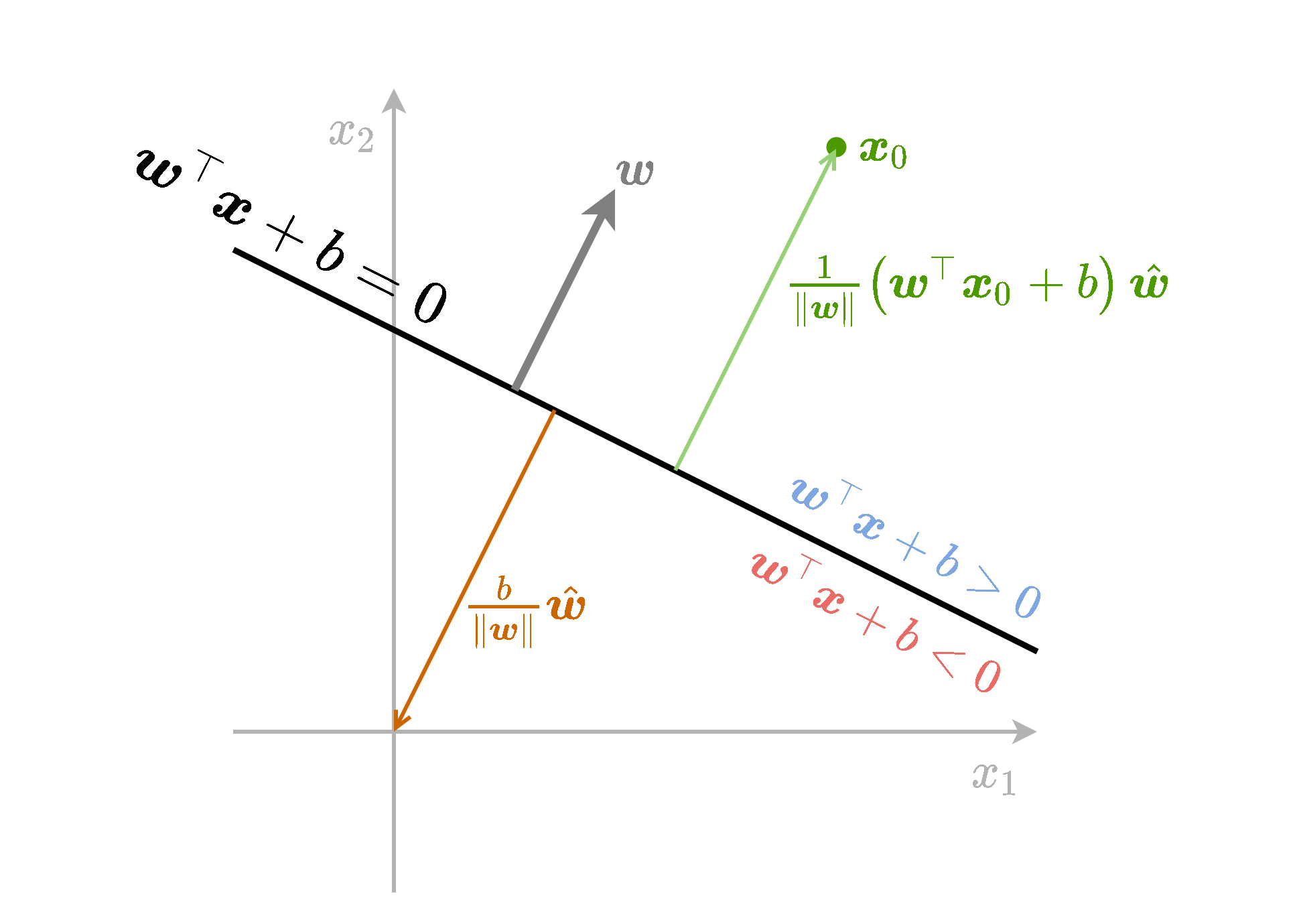
אינווריאנטיות לכפל בסקלר
תכונה נוספת של על-מישורים הינה שהם אינווריאנטים (לא משתנים) תחת כפל בסקלר. זאת אומרת שאם נכפיל את גם את וגם את בקבוע כל שהוא שונה מאפס לא נשנה את מיקומו של המישור במרחב, זאת משום ש:
המשמעות של אינווריאנטיות זו הינה שיש מספר דרכים להגדיר את אותו המסווג הלינארי. לעובדה זו תהיה משמעות כאשר ננסה לרשום את בעיית האופטימיזציה שנרצה לפתור על מנת למצוא את מישור ההפרדה הטוב ביותר.
Support Vector Machine (SVM)
SVM הוא אלגוריתם דיסקרימינטיבי לסיווג בינארי אשר מחפש מסווג לינארי אשר יסווג בצורה טובה את המדגם. לאגוריתם זה יש שני גרסאות hard SVM אשר מחפש מסווג לינארי טוב לסיווג מדגם שהוא פריד לינארית, ו soft SVM אשר מרחיב את האלגוריתם למקרה שבו המדגם לא פריד לינארית. נתחיל בלהציג את hard SVM.
Hard SVM
כפי שציינו קודם, במקרה שבו המדגם הינו פריד לינארית ישנו יותר ממישור הפרדה אחד אשר מסווג את המדגם באופן מושלם. נרצה למצוא מישור הפרדה אשר יכליל בצורה טובה גם לנקודות מחוץ למדגם. הנחה סבירה הינה שהפילוג הצפוי של הנקודות יתרכז באופן גס סביב הנקודת מהמדגם.
תחת היגיון זה hard SVM מנסה למצוא מישור הפרדה אשר יהיה רחוק ככל האפשר מהנקודות שבמדגם, או באופן יותר מדוייק, נרצה שהמרחק מהמישור לנקודה הקרובה אליו ביותר יהיה מקסימאלי. נגריר זאת באופן מתימטי.
נסתכל על המכפלה בין המרחקים המסומנים של הנקודות לתוויות שלהם: . כדי לקבל סיווג מושלם נרצה שכל המכפלות האלה יהיו חיוביות. ב Hard SVM, בנוסף לניסיון לגרום לכל המכפלות להיות חיוביות, ננסה למקסם את המינימום של מכפלות אלו. דרישה זו תנסה להרחיק כמה שאפשר את הנקודות מהמישור.
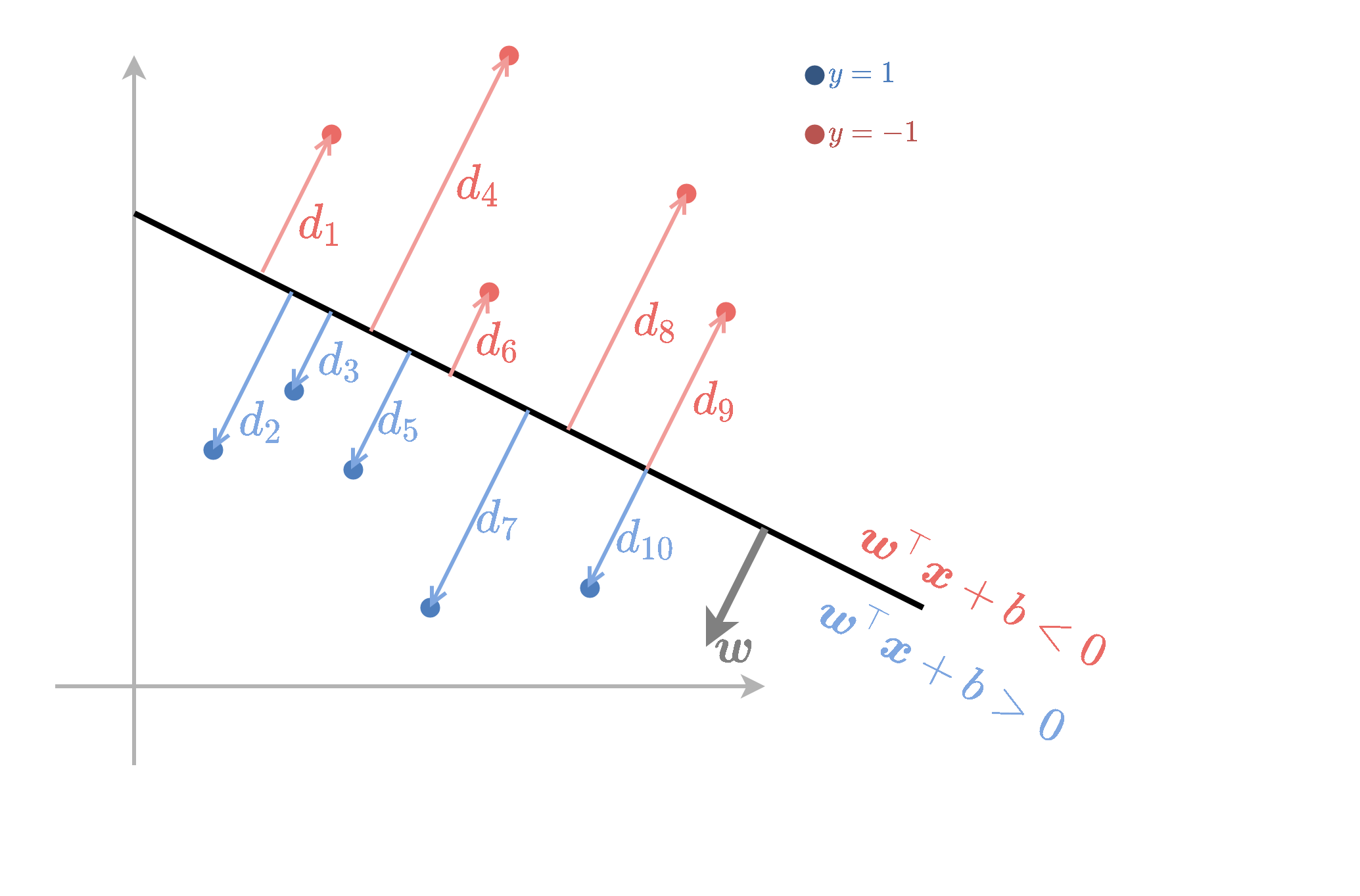
בעיית האופטימיזציה שנרצה לפתור אם כן הינה:
באופן כללי ניתן לנסות לפתור בעיה זו באופן ישיר על ידי אלגוריתם כמו gradient descent. בפועל העובדה שבבעיה מופיע על כל המדגם מאד מקשה לממש פתרון שיתכנס בזמן סביר. למזלנו ניתן לפשט את הבעיה ולמצוא בעיה שקולה, שאותה נכנה הבעיה הפרימאלית, שאותה שניתן יהיה לפתור באופן יעיל בשיטות נומריות אחרות.
הפיתוח של הבעיה הפרימאלית
כפי שציינו קודם המשוואת המישור היא אינווריאנטית לכפל בקבוע. זאת אומרת שבבעיית האופטימיזציה נוכל לבחור באופן שרירותי קבוע כפלי להכפיל בו את ו מבלי לפגוע במרחב של המסווגים שמתוכם אנו מחפשים את הפתרון. בפרט נוכל להוסיף דרישה ש:
אם נוסיף את האילץ הזה לבעיית האופטימיזציה נקבל:
נוכל לפשט אף יותר את בעיית האופטימיזציה על ידי כך שנחליף את האילוץ של באילוץ:
מכיוון שבעיית האופטימיזציה מנסה להקטין את הגודל של מובטח שלפחות עבור אחת מהדגימות במדגם האילוץ יתקיים בשיוון (אחרת אז ניתן להקטין עוד את ו ובכך להקטין את ה objective), דבר אשר יגרור שיתקיים ש . אם כן, בעיית האופטימיזציה הבאה שקולה לבעיה שמימנה התחלנו:
הבעיה החדשה שקיבלנו נקראת הבעיה הפרימאלית ויש לה צורה מאד מיוחדת המוכנה quadratic programming problem והיה ניתנת לפתרון בשיטות נומריות מאד יעילות אותם לא נכסה בקורס זה. ניתן כעת פרשנות אינטואיטיבית לבעיה הפרימאלית.
פרשנות
האילוץ בבעיית האופטימיזציה שקיבלנו דורשת שבעבור ו כל שהם כל הנקודות במדגם יהיו מסווגות בצורה נכונה ועליהם להימצא מחוץ לתחום של:
תחום זה אשר נמצא בין שני המישורים:
ו
נקרא השוליים (margin) של המסווג ותפקידו להרחיק את הנקדות של המדגם ממישור ההפרדה.
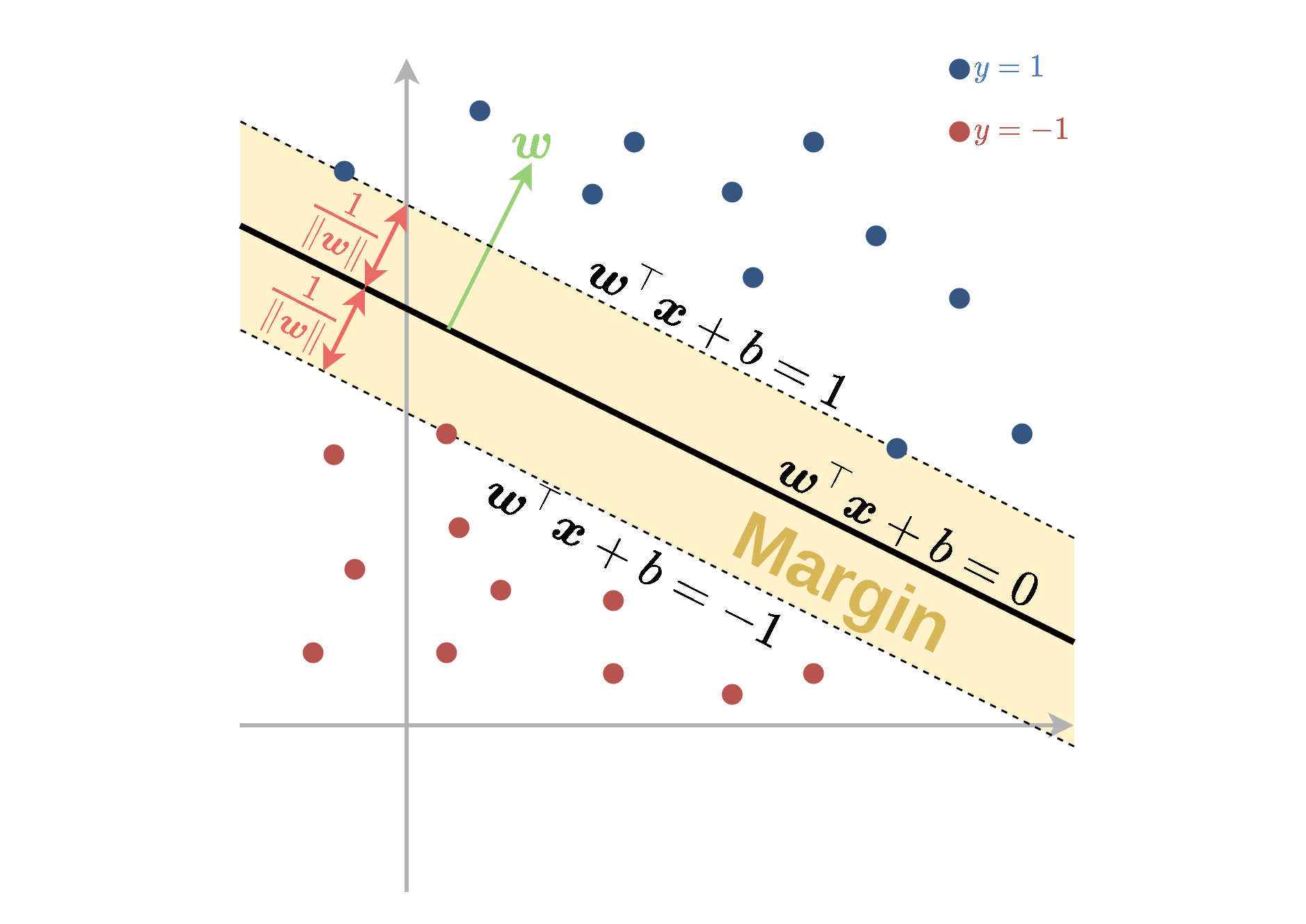
המרחק בין מישור ההפרדה לשפה של ה margin שווה ל והרוחב הכולל של ה margin הינו . בעיית האופטימיזציה, שמנסה למזער את , תחת האילוץ תתכנס לפרמטרים של המסווג בעל ה margin הגדול ביותר אשר מקיים תנאי זה.
Support Vectors
משום ש SVM מנסה להרחיק את הנקדות הקרובות ביותר למישור נקבל שלרוב רק חלק קטן מאד של הנקודות ישפיעו על הבחירה של מישור ההפרדה. לדוגמא, נקודות שכנראה לא ישפיעו על מישור ההפרדה הם כאלה שנמצאות רחוק מהאיזור של התפר בין שני המחלקות. בפועל הנקודות היחידות אשר ישפיעו על התוצאה של בעיית האופטימיזציה הן הנקודות שבסופו של דבר ישבו על השפה של ה margin. נקודות אלו מקיימות והן מכוונות support vectors. שהסרה או הזזה אינפיטסימאלית של נקודות שאינם support vectors לא תשפיע על הפתרון של בעיית האופטימיזציה.
הבעיה הדואלית
נציג כעת דרך שקולה נוספת לרישום של בעיית האופטימיזציה אשר מכונה הבעיה הדואלית. בעיה זו לפעמים נוחה יותר לשימוש והיא גם תשרת אותנו בהמשך כאשר נציג את שיטת הגרעין. המעבר מהבעיה הפרימאלית נעשה על ידי שיטה המכונה תנאי Karush-Kuhn-Tucker אשר גם אותה לא נציג בקורס זה. נציג אבל את בעיית האופטימיזציה עצמה. הסבר מפורט יותר על אופטימיזציה של בעיות קמורות בהקשר של SVM והמעבר לבעיה הדואלית ניתן למצוא בנספח בנושא באתר המודל של הקרוס.
בבעיה זו נגדיר משתני עזר נוספים . בעזרת משתנים אלו ניתן לרשום את הבעיה הדואלית באופן הבא:
מתוך המשתנים ניתן לשחזר את אופן הבא:
ישנו קשר בין הערכים של לנקודות שהם support vectors. בפרט, בעבור נקודות שאינם support vectors יתקיים ש . (בנוסף, במרבית המקרים, אם כי לא תמיד, בעבור נקודות שהם כן support vectors יתקיים ש ).
נסכם זאת בטבלה הבאה:
| . | . | . |
|---|---|---|
| נקודות רחוקות מה margin | ||
| נקודות על ה margin (שהם support vectors) |
על מנת לחשב את הפרמטר של המישור נוכל לבחור נקודה מסויימת שבעבור ה . נקודה כזו בהכרח תהיה support vectors ולכן היא תקיים , מתוך משוואה זו ניתן לחלץ את .
Soft SVM
Soft SVM מתייחס למקרה שבו המדגם אינו פריד לינארית. במקרה זה עדיין מגדירים את השוליים בצורה דומה אך מאפשרים לנקודות המדגם להיכנס לתוך השוליים ואף לחצות אותם לצד הלא נכון של מישור ההפרדה. על כל חריגה כזו משלמים קנס בפונקציית המטרה שאותו מנסים למזער. את החריגה של הדגימה ה נסמן ב . לנקודות שהם בצד הנכון של המישור ומחוץ ל margin יהיה 0.
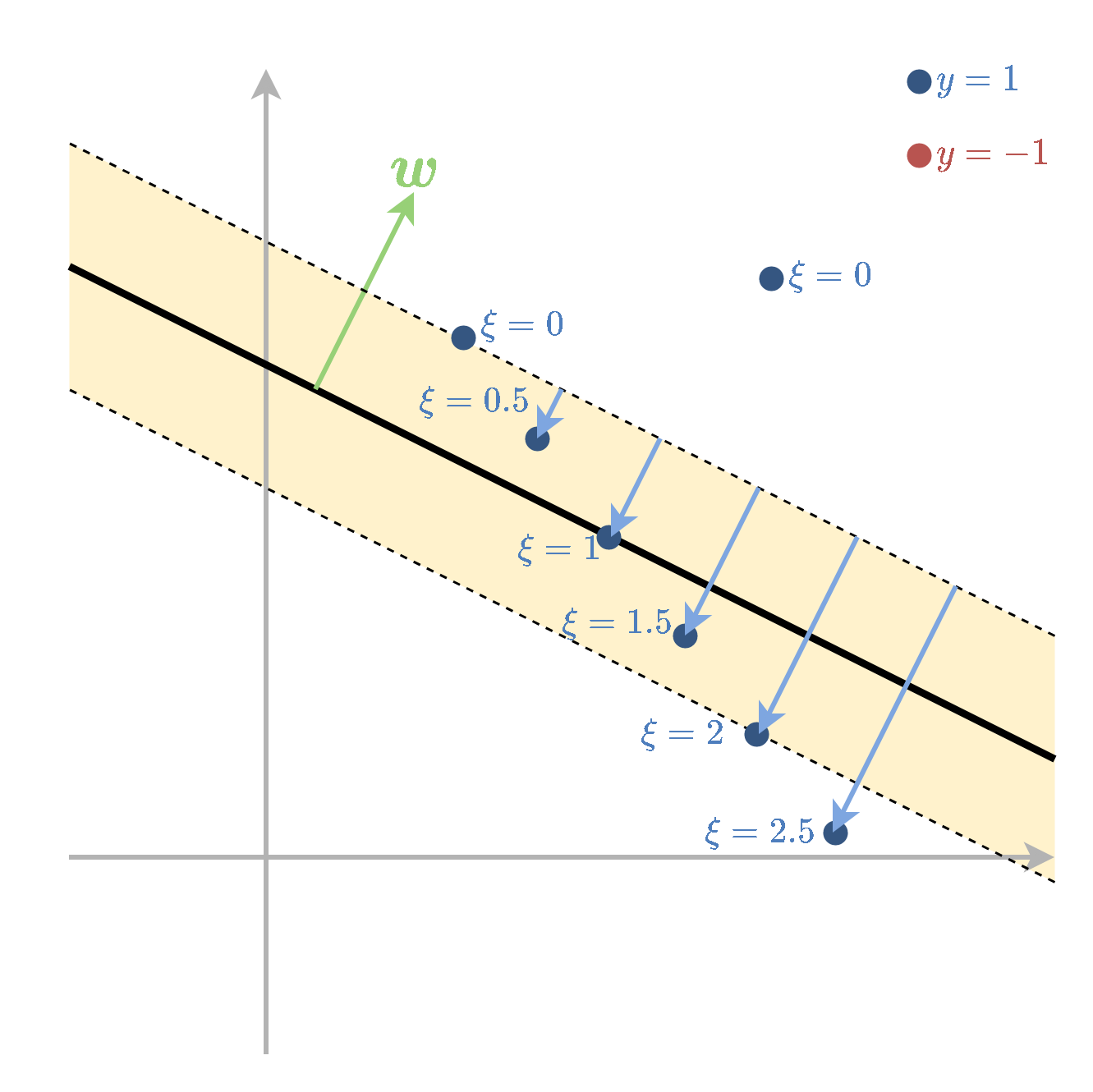
המשתנים נקראים slack variables ובעיית האופטימיזציה הפרימאלית תהיה
כאשר הוא היפר-פרמטר אשר קובע את גודל הקנס בפונקציית המחיר על כל חריגה.
הבעיה הדואלית הינה:
ה support vectors מוגדרים להיות הנקודות שמקיימות
תכונות:
| . | . | . |
|---|---|---|
| נקודות שמסווגות נכון ורחוקות מה margin | ||
| נקודות על ה margin (שהם support vectors) | ||
| נקודות שחורגות מה margin (גם support vectors) |
כאשר המקרה האחרון כולל נקודות המסווגות נכון ולא נכון.
פונקציות גרעין
מאפיינים: תזכורת
נוכל תמיד להחליף את וקטור המשתנים שעליו פועל האלגוריתם בוקטור חדש , כאשר היא פונקציה אשר נבחרה מראש ונקראת פונקציית המאפיינים שכן היא מחלצת מאפיינים רלוונטים מתוך שבהם נשתמש. אם הממד של מספיק גבוה, ניתן תמיד להגיע להפרדה לינארית במרחב הרב-ממדי (דורש הוכחה).
פונקציות גרעין
במקרים רבים החישוב של יכול להיות מסובך אך קיימת דרך לחשב בצורה יעילה את הפונקציה אשר נקראת פונקציית גרעין. יתרה מזאת, ייתכנו מצבים שבהם וקטור המאפיינים הוא אינסופי ועדיין פונקציית הגרעין היא פשוטה לחישוב.
ישנם קריטריונים תחתם פונקציה מסויימת היא פונקציית גרעין בעבור וקטור מאפיינים מסויים. בקורס זה לא נכנס לתאים אלו. נציג שתי פונקציות גרעין נפוצות:
- גרעין גאוסי: כאשר פרמטר שיש לקבוע.
- גרעין פולינומיאלי: כאשר פרמטר שיש לקבוע.
פונקציית המאפיינים שמתאימות לגרעינים אלו הם מסורבלות לכתיבה ולא נציג אותם כאן.
Kernel Trick in SVM
הרעיון ב kernel trick הינו לעשות שימוש בפונקציית הגרעין על מנת להשתמש ב SVM עם מאפיינים מבלי לחשב את באופן ישיר. בעבור פונקציית מאפיינים עם פונקציית גרעין הבעיה הדואלית של SVM הינה:
בעיית אופטימיזציה זו מגדירה את המשתנים בלי צורך לחשב את באופן מפורש בשום שלב.
הפרמטר נתון על ידי:
כדי לחשב את באופן מפורש יש לחשב את , אך ניתן להמנע מכך עם מציבים את הנוסחא ל ישירות לתוך המסווג:
כדי להמנע מהחישוב של גם במסווג נשתמש בעובדה ש:
כך שגם בשלב החיזוי ניתן להשתמש בפונקציית הגרעין בלי לחשב את באופן מפורש.