הרצאה 5 - Bagging and Boosting
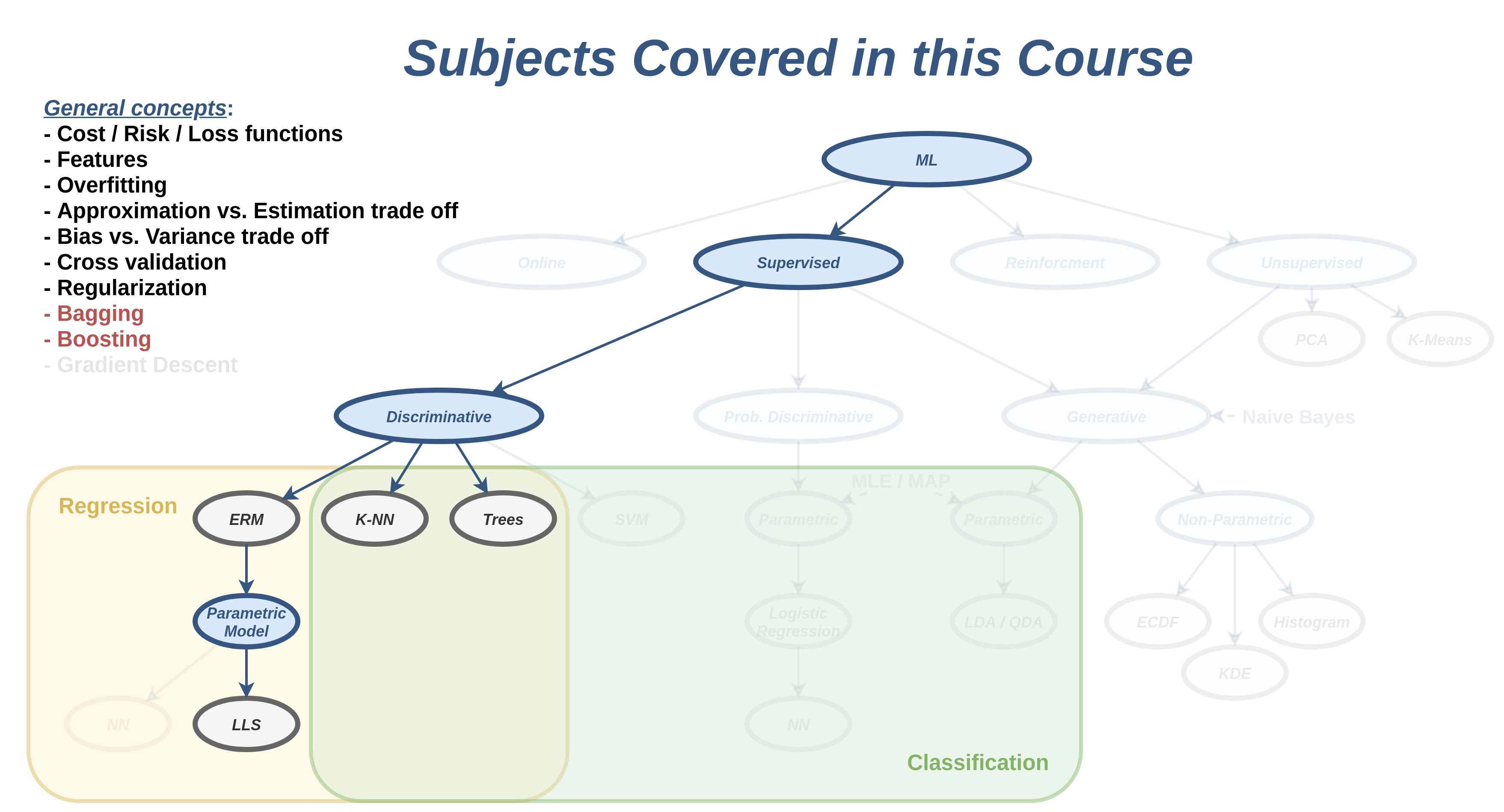
Ensemble Methods
בהרצאה הזו נציג שתי שיטות אשר בעזרתן ניתן לשפר את הביצועים של אלגוריתמים קיימים על ידי שימוש בסט של חזאים. סט זה מכונה לרוב ensemble (מכלול).
תזכורת הטיה ושונות
- מתייחסים לפילוג של שגיאת החיזוי על פני מדגמים שונים.
- נתייחס למדגם כאל משתנה אקראי.
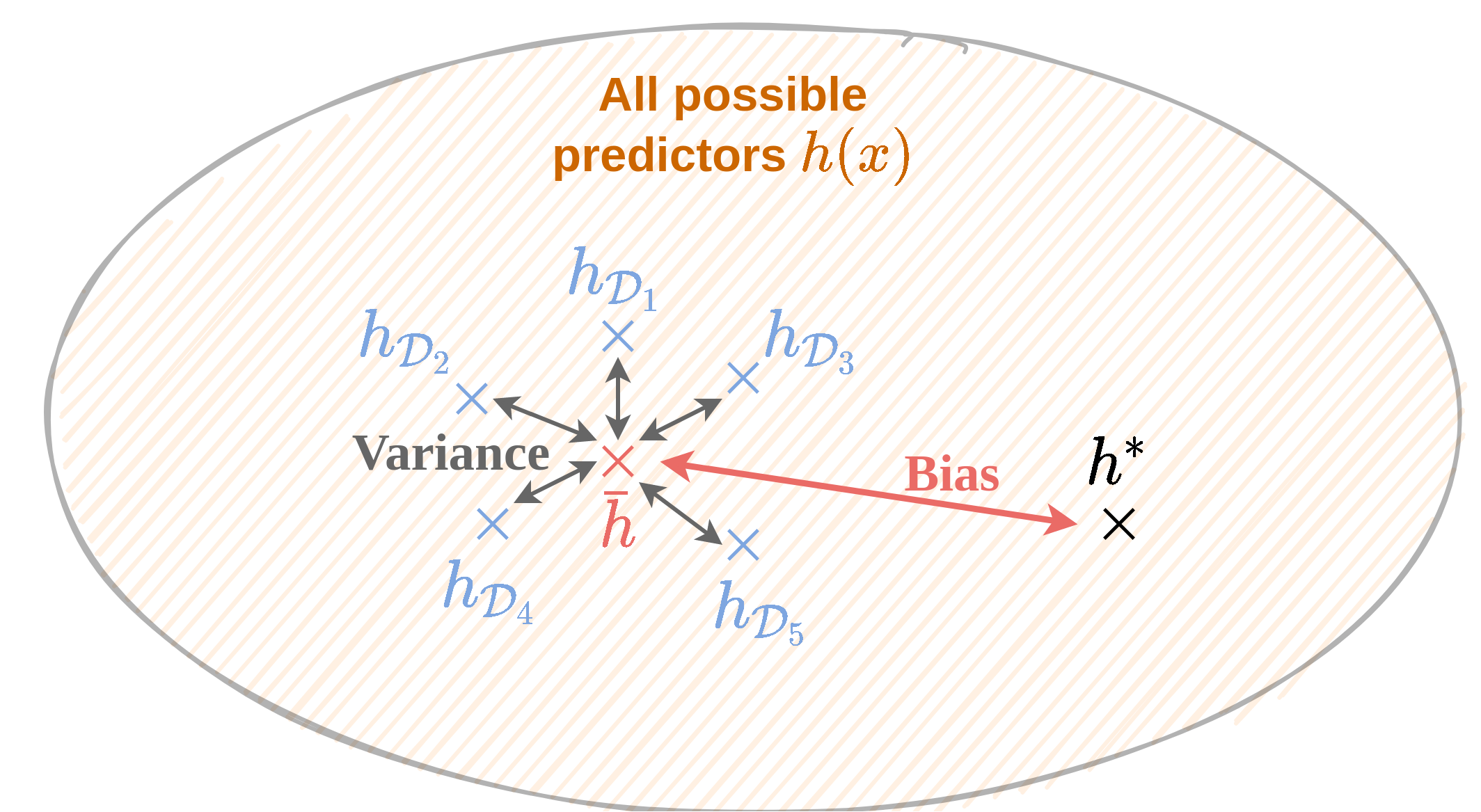
תזכורת הטיה ושונות
- החיזוי הממוצע: hˉ(x)=ED[h(x)]
- החיזוי האופטימלי h∗(x).
- ההטיה היא ההפרש בין החיזוי הממוצע לחיזוי האופטימלי.
- השונות היא ED[(hD(x)−hˉ(x))2]
תזכורת הטיה ושונות
- מודלים בעלי יכולת ייצוג נמוכה יסבלו לרוב מהתאמת חסר אשר יתבטא בהטיה גבוהה ושונות נמוכה
- מודלים בעלי יכולת ייצוג גבוהה יסבלו לרוב מהתאמת יתר אשר יתבטא בשונות מאד גבוהה והטיה נמוכה
Bagging ו Boosting
כעת נוכל להסביר מה bagging ו boosting מנסים לעשות:
- ב bagging ננסה לקחת מכלול של חזאים עם שונות גבוהה ולשלב ביניהם כדי ליצור חזאי עם שונות נמוכה יותר.
- ב boosting ננסה לקחת מכלול של חזאים עם הטיה גבוהה ולשלב ביניהם כדי ליצור חזאי עם הטיה נמוכה יותר.
שאלה: דוגמאות לכל אחד מהמקרים
Bagging
נהיה מעוניינים לייצר מכלול (ensemble) של חזאים בעלי הטיה נמוכה אך שונות גבוהה ואז לשלב ביניהם על מנת להקטין את השונות.
אחת הבחירות הנפוצות לחזאים שכאלה ב bagging היא עצי החלטה עמוקים (ללא pruning).
השם Bagging הוא הלחם של המילים bootstrapping ו aggregation, שהם שני שלבי השיטה.
גישה נאיבית
- לו יכלנו לייצר כמה מדגמים בלתי תלויים, היינו יכולים לבנות חזאי עבור כל מדגם ולמצע על החזאים על מנת להקטין את השונות של השגיאת החיזוי.
- בפועל לרוב יהיה בידינו רק מדגם יחיד שאיתו נצטרך לעבוד.
- ניתן לייצר מספר מדגמים על ידי חלוקת המדגם הקיים, אך לרוב העובדה שהמדגמים הם משמעותית קטנים מהמדגם המקורי תגדיל את השונות.
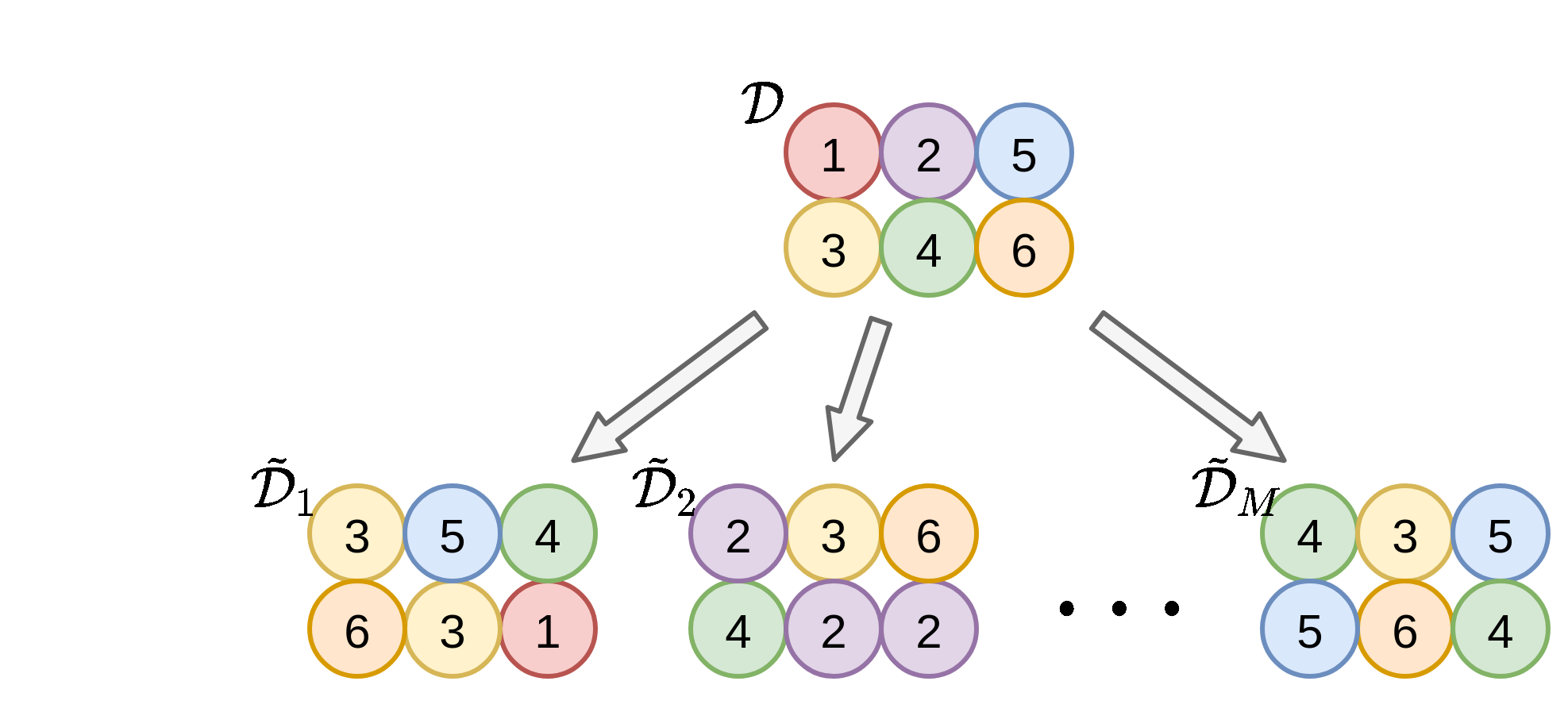
Bootstrapping
אופציה חלופית אשר שומרת על גודל המדגם, אך מתפשרת על דרישת חוסר התלות בין המדגמים ובין הדגימות.
Bootstrapping
בשיטה זו אנו נייצר מדגמים חדשים על ידי דגימה מחדש של המדגם הנתון. הדגימה הינה עם חזרות.
שאלה: מהי דגימה עם חזרות ודגימה ללא חזרות? מה ניתן לומר על התלות בין הדגימות המתקבלות?
Bootstrapping
- הסיכוי של דגימה כלשהיא להופיע ב D~ הינה 1−(1−N1)N~.
- כאשר N~=N ו N→∞, סיכוי זה הולך ל 1−e−1≈63%.
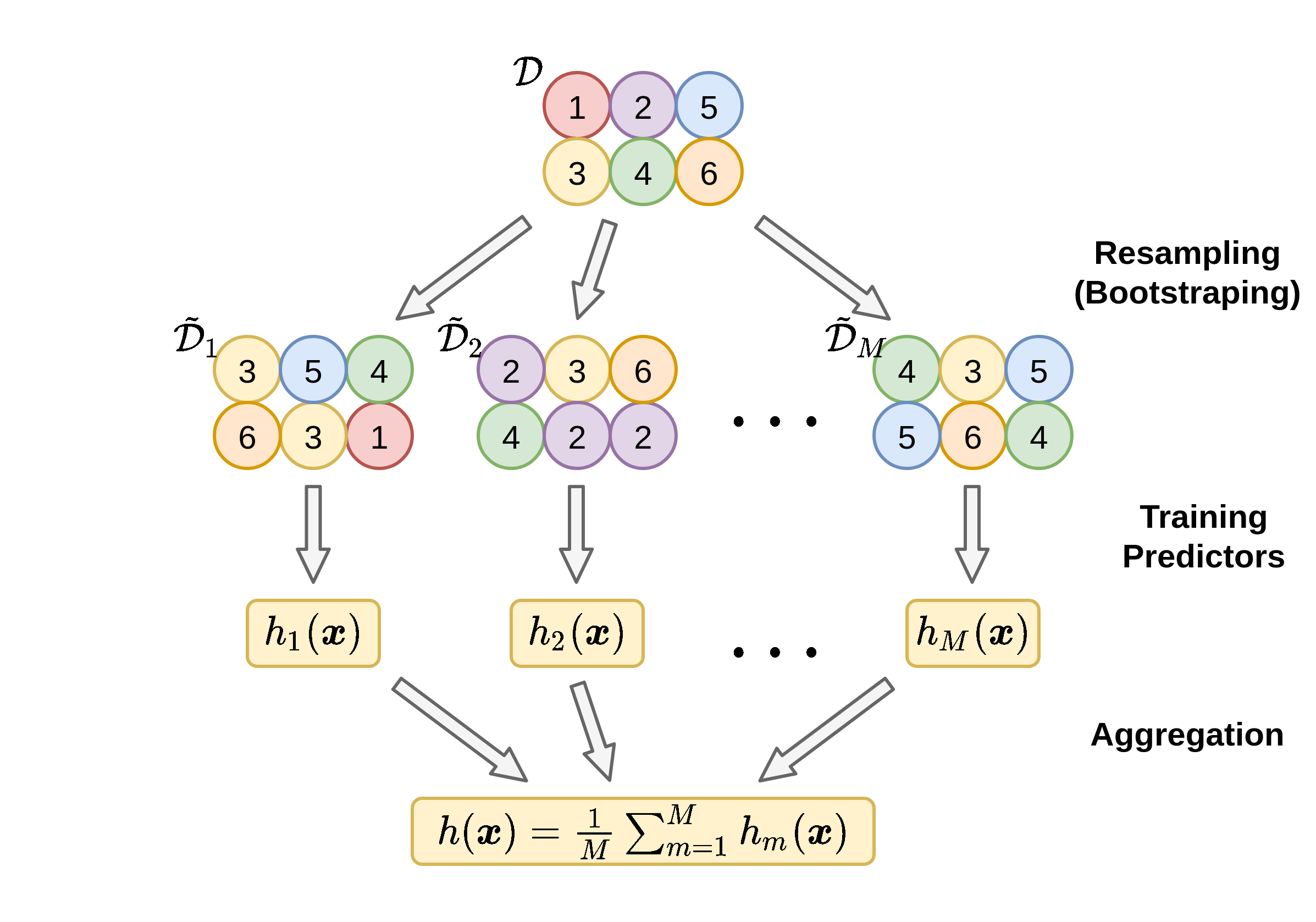
Aggregation: שילוב חזאים לחזאי יחיד
- נייצר M מדגמים חדשים בגודל זהה למדגם המקורי N~=N.
- עבור כל אחד מהמדגמים D~m נבנה חזאי h~m.
- נקבץ את כל החזאים על מנת לקבל את החזאי הכולל.
Aggregation: שילוב חזאים לחזאי יחיד
- עבור בעיות רגרסיה: נמצע את תוצאת החיזוי של כל החזאים:
h(x)=M1m=1∑Mh~m(x)
- עבור בעיות סיווג: נבצע majority voting:
h(x)=majority({h~1(x),h~2(x),…,h~M(x)})
Aggregation: שילוב חזאים לחזאי יחיד
- מספר המדגמים M נע בין עשרות מדגמים לאלפים.
- לרוב נשתמש באותה השיטה על מנת לבנות את כל החזאים.
- כל מסווג יכול להיות עץ החלטה מלא!
Out Of Bag Error Estimation (לקריאה עצמית - לא למבחן)
- ניתן להעריך את ביצועי המודל ללא צורך ב test / validation set.
- הרעיון הינו להשתמש בעובדה שכל אחד מהמדגמים מכיל רק חלק מהדגימות.
Random Forest (לקריאה עצמית - לא למבחן)
- שילוב של עצי החלטה עם bagging + תוספת.
- תוספת - בחירה אקראית של תת-קבוצות של רכיבים בפיצולים בצומת - מקטין את הקורלציה בין העצים השונים.
-
שיטה מאד יעילה ונפוצה.
Random Forest (לקריאה עצמית - לא למבחן)
מדוע השיטה עובדת?
- הפחתה בהתאמת יתר
- דיוק גבוה
- חסינות בפני נתונים בעייתים (כגון נתונים חסרים, ouliers)
- קיימות הבטחות תאורטיות (לא נדון)
- מה החסרון לעומת עצי החלטה?
Boosting
- ננסה להשתמש במכלול של חזאים בעלי הטיה גבוהה אך שונות נמוכה כדי ליצור חזאי כולל בעל שונות נמוכה.
- נתמקד בבעיות סיווג בינארי.
- התוויות בבעיה הן (מטעמי סימטריה) y=±1.
בעיית ה boosting המקורית
(לקריאה עצמאית - לא למבחן)
- מהו לומד חזק?
- מהו לומד חלש?
- האם כל לומד הוא בעצם גם לומד חזק?
הרחבה ברשימות
AdaBoost (adaptive-boosting)
בהינתן אוסף של חזאים "חלשים" h~(x) בעלי הטיה גבוהה, שיטה זו מנסה לבנות חזאי מהצורה
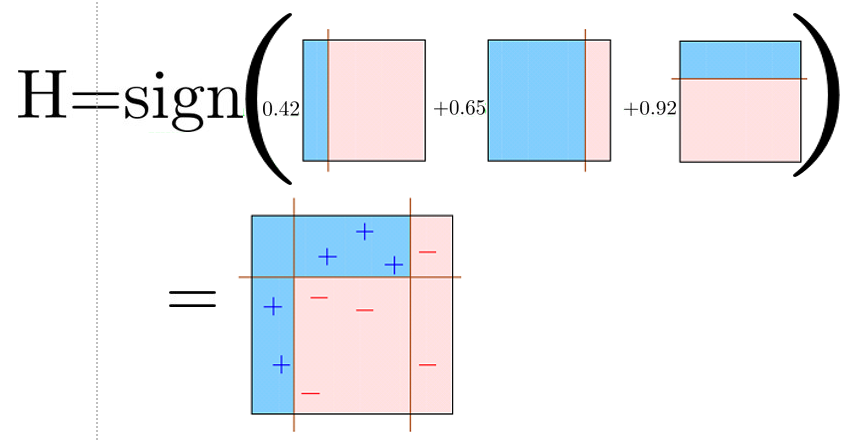
h(x)=sign(m=1∑Mαmh~m(x))
כך ש h(x) יהיה בעל הטיה נמוכה.
- בחירה פופולרית של מסווגים כאלה הינה עצי החלטה בעומק 1 המכונים stumps (עצים עם פיצול יחיד).
החסם על ה misclassification rate
נראה שעבור חזאי מהצורה של
h(x)=sign(m=1∑Mαmh~m(x))
שגיאת 0-1 האמפירית חסומה מלמעלה על ידי:
N1i=1∑Nexp(−m=1∑Mαmy(i)h~m(x(i)))
החסם על ה misclassification rate
נתחיל בעובדה שעבור y=±1 וערך כל שהוא z מתקיים ש:
I{sign(z)=y}=I{sign(yz)=1}≤exp(−yz)
ונשתמש באי השיוון הנ"ל על כל איבר בסכום בנוסחא לשגיאה האמפירית ונקבל כי:
N1i∑I{h(x(i))=y(i)}=N1i∑I{sign(m=1∑Mαmh~m(x(i)))=y(i)}≤N1i=1∑Nexp(−m=1∑My(i)αmh~m(x(i)))
בעיית האופטימיזציה של AdaBoost
על פי החסם שהצגנו לעיל נוכל להניח כי מזעור של בעיית האופטימיזציה הבאה:
{αm,h~m}m=1MargminN1i=1∑Nexp(−m=1∑Mαmy(i)h~m(x(i)))
תגרום כנראה להקטנת השגיאה האמפירית ובכך להקטנת ההטיה.
- אנו נראה בהמשך כי תחת תנאים מסויימים כאשר M→∞ החסם ידעך ל-0.
בעיית האופטימיזציה של AdaBoost
{αm,h~m}m=1MargminN1i=1∑Nexp(−m=1∑Mαmy(i)h~m(x(i)))
- AdaBoost מנסה לפתור את בעיית האופטימיזציה בצורה חמדנית.
- אנו נגדיל את M בהדרגה כאשר בכל פעם נחפש את ה αm וה h~m האופטימלים.
בעיית האופטימיזציה של AdaBoost
{αm,h~m}m=1MargminN1i=1∑Nexp(−m=1∑Mαmy(i)h~m(x(i)))
נסתכל על המצב בו כבר מצאנו את כל ה αm וה h~m עד ל M−1, וכעת אנו רוצים למצוא את αM ו h~M:
αM,h~M=α,h~argminN1i=1∑Nexp(−m=1∑M−1αmy(i)h~m(x(i))−αy(i)h~(x(i)))
- αM יכול לקבל כל ערך.
- את h~M עלינו לבחור מתוך מאגר מסווגים נתון.
בעיית האופטימיזציה של AdaBoost
αM,h~M=α,h~argminN1i=1∑Nexp(−m=1∑M−1αmy(i)h~m(x(i))−αy(i)h~(x(i)))
הדרך לפתור את בעיית האופטימיזציה:
- רישום מחדש של בעיית האופטימיזציה בצורה יותר פשוטה.
- מציאת αM כפונקציה של h~M על ידי גזירה והשוואה ל-0.
- הצבה של αM בחזרה לבעיית האופטימיזציה על מנת לקבל ביטוי פשוט שאותו יש למזער כתלות ב h~M.
נציג כעת את הפתרון של בעיה זו, כאשר הפיתוח המלא של הפתרון מופיע בסוף ההרצאה.
בעיית האופטימיזציה של AdaBoost
αM,h~M=α,h~argminN1i=1∑Nexp(−m=1∑M−1αmy(i)h~m(x(i))−αy(i)h~(x(i)))
נגדיר את הגדלים הבאים:
w~i(M−1)wi(M−1)ε(h~,{wi})=exp(−m=1∑M−1αmy(i)h~m(x(i)))=∑j=1Nw~j(M−1)w~i(M−1)משקלגבוהלדגימותקשות=i=1∑NwiI{y(i)=h~(x(i))}
בעיית האופטימיזציה של AdaBoost
h~M ו αM האופטימאליים בכל שלב יהיו נתונים על ידי:
h~M=h~argmin ε(h~,{wi(M−1)})=h~argmin i=1∑Nwi(M−1)I{y(i)=h~(x(i))}
ו
αM=21ln(εM1−εM)
כאשר סימנו:
εM=ε(h~M,{wi(M−1)})
כאשר h~M הינו מסווג טוב לדגימות קשות. הוכחה מלאה ברשימות.
בעיית האופטימיזציה של AdaBoost
אם כן, בכל שלב עלינו לבצע את הפעולות הבאות:
- חישוב המשקלים {wi(M−1)}.
- מציאת החזאי h~ אשר ממזער את שגיאת 0-1 האמפירית הממושקלת.
- חישוב המקדם αM.
בפועל ניתן לחשב את המשקלים של ה צעד ה M כבר בסוף הצעד ה M−1. בנוסף ניתן להשתמש בעובדה ש:
w~i(M)=w~i(M−1)exp(−αMy(i)h~M(x(i)))
כדי להימנע מלחשב את הסכום על m ולקצר את החישוב.
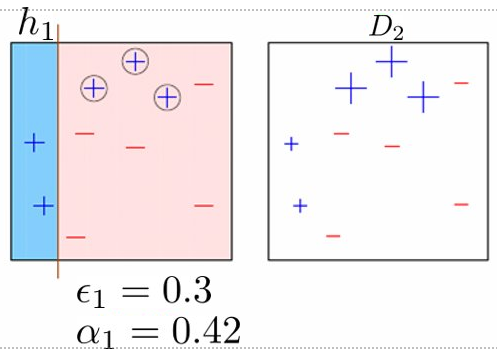
האלגוריתם של AdaBoost
נאתחל את המשקולות wi(0)=N1.
-
נבחר את המסווג אשר ממזער את:
h~M=h~argmin i=1∑Nwi(M−1)I{y(i)=h~(x(i))}
-
נחשב את המקדם αM של המסווג:
εMαM=i=1∑Nwi(M−1)I{y(i)=h~M(x(i))}=21ln(εM1−εM)
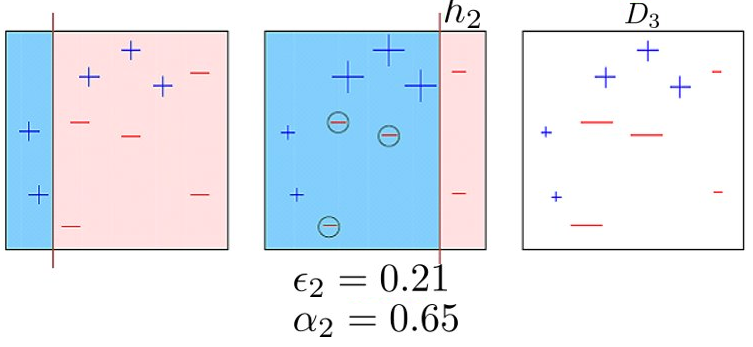
האלגוריתם של AdaBoost
-
נעדכן את וקטור המשקלים:
w~i(M)wi(M)=wi(M−1)exp(−αMy(i)h~M(x(i)))=∑j=1Nw~j(M)w~i(M)
המשמעות של המשקלים
המשקל ללא הנרמול של הדגימה ה i שווה ל:
w~i(M)=exp(−y(i)m=1∑Mαmh~m(x(i)))
- משקל זה מציין עד כמה טוב האלגוריתם מסווג את הדגימה ה i.
- דגימות שלא מסווגות נכון יהיו בעלות משקל גדול.
- התפקיד של המשקלים הוא לדאוג שהאלגוריתם יבחר בכל צעד את החזאי אשר ישפר את הסיווג בעיקר על הדגימות שעליהן החזאי הנוכחי טועה.
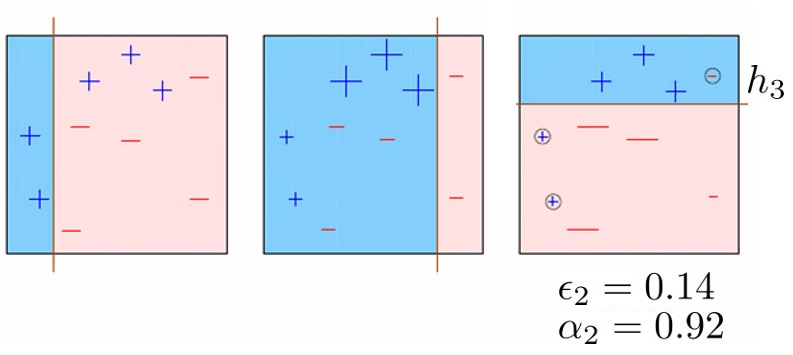
תנאי עצירה
- בחלק גדול מהמקרים AdaBoost ילך ויקטין את שגיאת החיזוי על המדגם עד שהוא יגיע לסיווג מושלם.
- AdaBoost ממשיך לשפר את יכולת ההכללה שלהו גם אחרי שהוא הגיע לסיווג מושלם.
- כמות התאמת היתר גדלה בקצב מאד איטי (אם בכלל).
- נרצה להריץ את האלגוריתם מספר רב של צעדים ולבדוק את הביצועים על validation set.
קצב ההתכנסות של החסם
ראינו קודם כי שגיאת 0-1 האמפירית (הלא ממושקלת) של החזאי על המדגם חסומה על ידי הביטוי:
N1i∑I{h(x(i))=y(i)}≤N1i=1∑Nexp(−m=1∑My(i)αmh~m(x(i)))
נראה כעת כי תחת תנאים מסויימים מובטח כי חסם זה ידעך ל-0 ככל שנגדיל את M.
טענה (הוכחה מלאה ברשימות)
נסמן את שגיאת 0-1 האמפירית הממושקלת בצעד ה m ב εm=21−γm. נטען כי מתקיים הקשר הבא:
N1i=1∑Nexp(−m=1∑My(i)αmh~m(x(i)))≤exp(−2m=1∑Mγm2)
מכאן שבמידה וקיים γ אשר מקיים γm≥γ>0 אזי מתקיים ש:
N1i∑I{h(x(i))=y(i)}≤N1i=1∑Nexp(−m=1∑My(i)αmh~m(x(i)))≤exp(−2Mγ2)
זאת אומרת, שקיים חסם לשגיאת 0-1 האמפירית אשר דועך באופן מעריכי עם M.
יתרונות
- הקטנת ההטיה
- מימוש פשוט ויעיל
- ניתן לשימוש עם מגוון מסווגים בסיסיים
חסרונות
- התאמת יתר ורגישות לרעש (התמקדות בדוגמאות קשות)
- קשה למימוש מקבילי
- רגישות לבחירה של מסווגי בסיס
- פרשנות מורכבת (למשל, ביחס לעצי החלטה)
הרחבות
- רבות ומגוונות. בחלקו משלבות רגולריזציה, אפשרות לעיבוד מקבילי, שילוב עם bagging ועוד