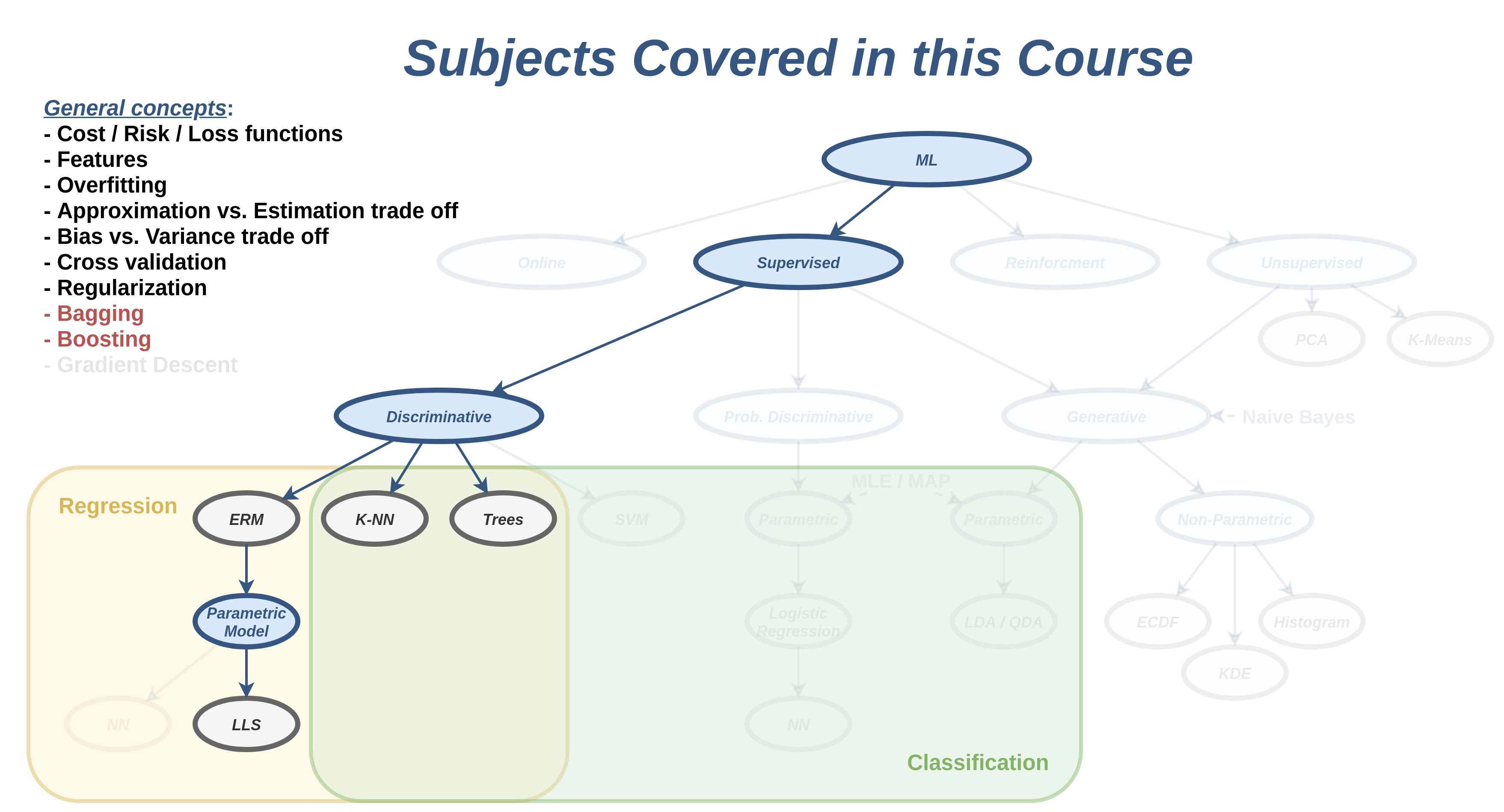
בהרצאה הזו נציג שתי שיטות אשר בעזרתן ניתן לשפר את הביצועים של אלגוריתמים קיימים על ידי שימוש בסט של חזאים. סט זה מכונה לרוב ensemble (מכלול).
תזכורת הטיה ושונות
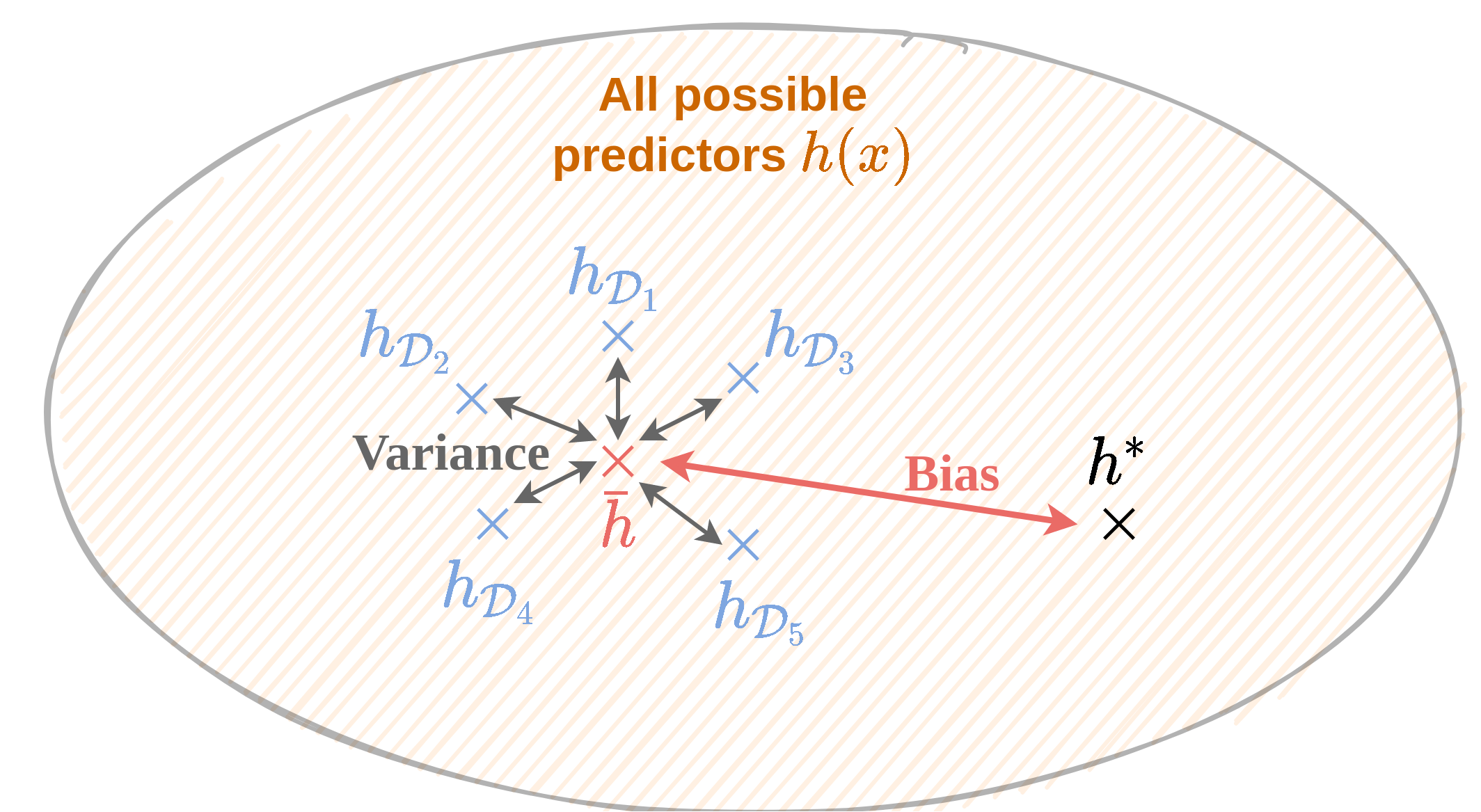
על מנת להבין מה שיטות אלו מנסות לעשות נזכיר שוב את המושגים של הטיה ושונות של חזאים. שני מושגים אלו כזכור מתייחסים לפילוג של שגיאת החיזוי על פני מדגמים שונים. נזכור כי כל מדגם D נבנה על ידי הגרלה של N דגימות בלתי תלויות מתוך פילוג כל שהוא ולכן נוכל להתייחס למדגם עצמו כאל משתנה אקראי.
נניח שאנו משתמשים באלגוריתם אשר בהינתן מדגם D מייצר חזאי hD(x).
הגדרנו בעבר את החיזוי הממוצע (על פני מדגמים) באופן הבא:
hˉ(x)=ED[h(x)]
ואת החזיזוי האופטימאלי ב h∗(x). ההטיה של החיזוי הוא ההפרש בין החיזוי הממוצע לחיזוי האופטימלי. השונות של החיזוי היא השונות של החיזוי כפונקציה של המדגם:
ED[(hD(x)−hˉ(x))2]
ראינו כי:
מודלים בעלי יכולת ייצוג נמוכה יסבלו לרוב מהתאמת חסר אשר יתבטא בהטיה גבוהה ושונות נמוכה (מדגמים שונים יניבו בערך את אותו המודל, אך המודל הזה יהיה רחוק מהחיזוי האופטימלי בגלל יכולת הייצוג המוגבלת).
מודלים בעלי יכולת ייצוג גבוהה יסבלו לרוב מהתאמת יתר אשר יתבטא בשונות מאד גבוהה והטיה נמוך (מדגמים שונים יניבו מודלים מאד שונים, אך החיזוי הממוצע על פני מודלים אלו יהיה לרוב קרוב לחיזוי האופטימלי).
כעת נוכל להסביר מה bagging ו boosting מנסים לעשות:
ב bagging ננסה לקחת מכלול של חזאים עם שונות גבוהה ולשלב ביניהם כדי ליצור חזאי עם שונות נמוכה יותר.
ב boosting ננסה לקחת מכלול של חזאים עם הטיה גבוהה ולשלב ביניהם כדי ליצור חזאי עם הטיה נמוכה יותר.
Bagging
כפי שציינו, ב Bagging נהיה מעוניינים לייצר מכלול (ensamble) של חזאים בעלי הטיה נמוכה אך שונות גבוהה ואז לשלב ביניהם על מנת להקטין את השונות. אחת הבחירות הנפוצות לחזאים שכאלה ב bagging היא עצי החלטה עמוקים (ללא pruning).
השם Bagging הוא הלחם של המילים bootstrapping ו aggregation, שהם שני שלבי השיטה שאותה נתאר כעת.
גישה נאיבית
אנו יודעים מהסתברות שבמקרים בהם יש באפשרותינו לחזור על מדידה אקראית מסויימת מספר פעמים, באופן בלתי תלוי, נוכל להקטין את השונות של המדידה על ידי לקיחת הממוצע של מספר מדידות.
תיאורטית אם היינו יכולים לייצר כמה מדגמים בלתי תלויים, היינו יכולים לבנות חזאי עבור כל אחד מהמדגמים ולמצע על החזאים האלה על מנת להקטין את השונות של השגיאת החיזוי. בפועל לרוב יהיה בידינו רק מדגם יחיד שאיתו נצטרך לעבוד.
ניתן אומנם לייצר מספר מדגמים שונים על ידי חלוקת המדגם הקיים למספר מדגמים קטנים יותר. הבעיה עם שיטה זו הינה שבמרבית המקרים העובדה שהמדגמים התמקבלים הם משמעותית קטנים מהמדגם המקורי תגדיל מאד את שונות החזאים שניצור ובפועל נקבל חזאי ממוצע בעל שונות גדולה יותר.
Bootstrapping
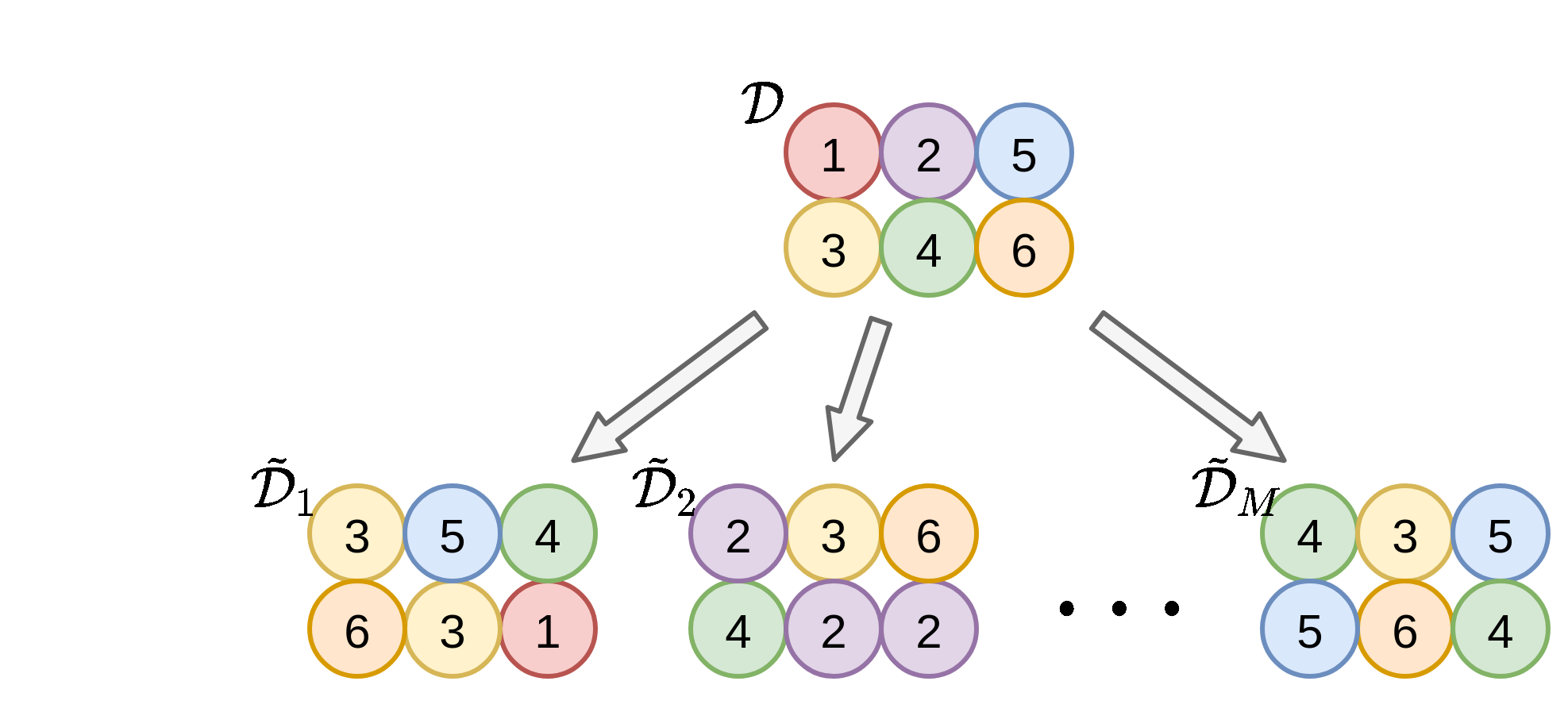
Bootstraping הינה אופציה חלופית לייצר מספר מדגמים מתוך מדגם הנתון אשר שומרת על גודל המדגם, אך מתפשרת על דרישת חוסר התלות בין המדגמים ובין הדגימות במדגם.
בשיטה זו אנו נייצר מדגמים חדשים על ידי דגימה מחדש של המדגם הנתון. זאת אומרת שבשביל לייצר מתוך מדגם נתון D בגודל N מדגם חדש D~ בגודל N~ אנו נגריל N~ פעמים ערכים מתוך D. הדגימה מתוך D הינה עם חזרות, זאת אומרת שניתן להגריל כל דגימה מתוך D מספר פעמים.
ניתן להראות שהסיכוי של דגימה כלשהיא מ D להופיע ב D~ הינה 1−(1−N1)N~. כאשר N~=N ו N→∞, סיכוי זה הולך ל 1−e−1≈63%. זאת אומרת שכאשר נייצר מדגם על ידי bootstrapping מתוך מדגם גדול, המדגם החדש יכיל בערך 63% מהדגימות המקוריות עם כפילויות.
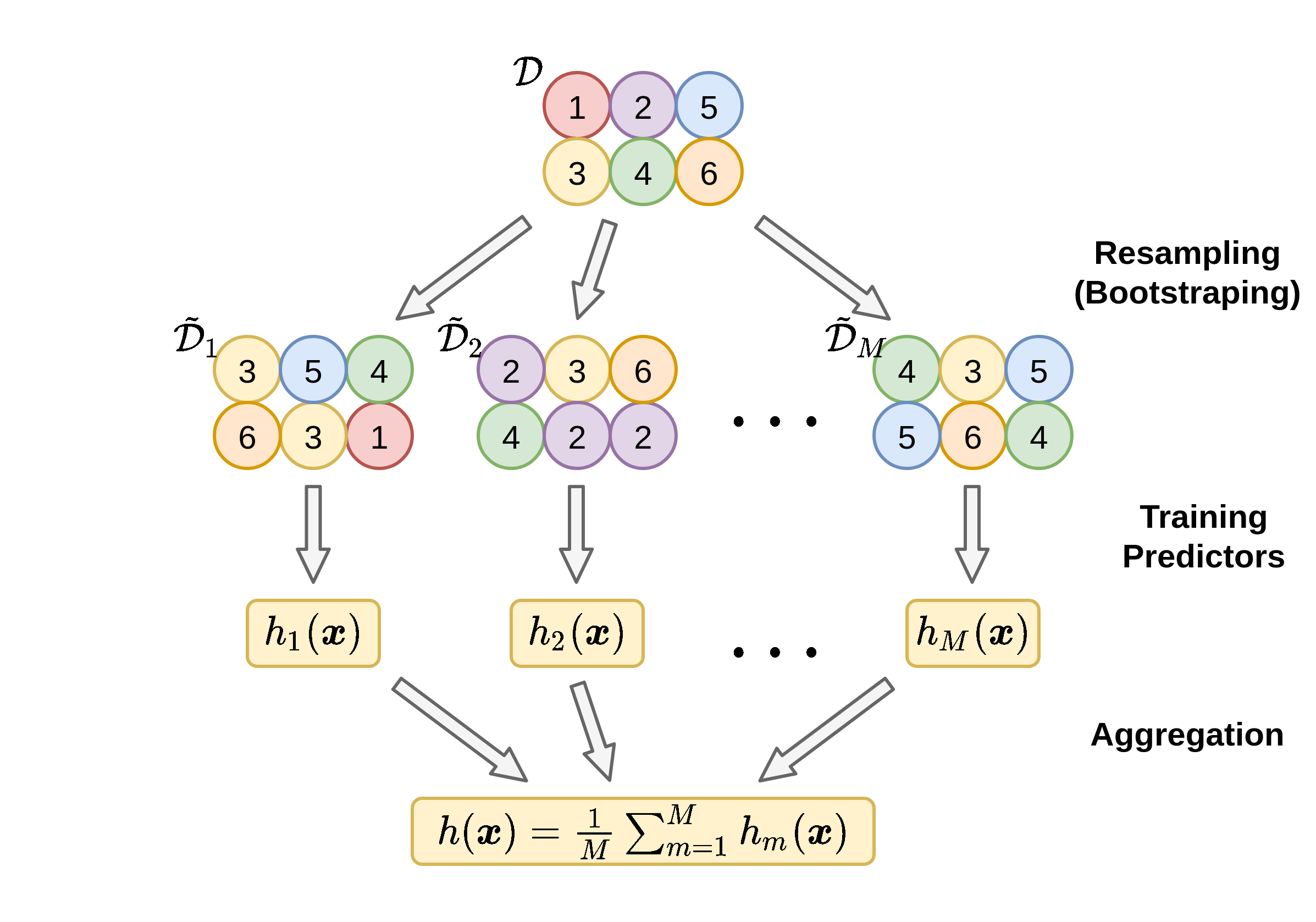
Aggregation: בניית החזאים ושילובם לחזאי יחיד
ב Bagging אנו נעשה שימוש ב bootstrapping על מנת לייצר M מדגמים חדשים {D~m}m=1M בגודל זהה למדגם המקורי, N~=N. מספר המדגמים M בהם נהוג להשתמש נע בין עשרות מדגמים לאלפים. עבור כל אחד מהמדגמים D~m נבנה חזאי h~m. לרוב נשתמש באותה השיטה על מנת לבנות את כל החזאים.
לאחר הבניה של M החזאים אנו נקבץ את כולם על מנת לקבל את החזאי הכולל בו נשתמש לחיזוי.
עבור בעיות רגרסיה: אנו נמצע את תוצאת החיזוי של כל החזאים:
h(x)=M1m=1∑Mh~m(x)
עבור בעיות סיווג: נבצע majority voting:
h(x)=majority({h~1(x),h~2(x),…,h~M(x)})
הערכת ביצועיים - Out Of Bag Error Estimation (לקריאה עצמית - לא למבחן)
אחד היתרונות של bagging הינו העובדה שניתן להעריך את ביצועי המודל ללא צורך ב test / validation set. הרעיון הינו להשתמש בעובדה שכל אחד מהמדגמים החדשים מכיל רק חלק מהדגימות וניתן להשתמש בשאר הדגימות כדי להעריך את הביצועים שלהם.
עבור כל אחד מהמדגמים D~M נזהה את הדגימות שלא נכללו במדגם זה. דגימות אלו מוכנות out-of-bag samples. כפי שציינו קודם, עבור N גדול, בערך 37% מהדגימות יהיו out-of-bag samples. כדי להעריך את ביצועי המודל נעבור על כל הדגימות במדגם ונעריך את השגיאה על דגימה זו תוך שימוש רק בחזאים שעבורם דגימה זו הינה out-of-bag samples, זאת אומרת, כל החזאים שלא ראו את הדגימה הזו בשלב האימון. ככל שמספר החזאים יהיה גדול יותר כך שיערוך זה של השגיאה יהיה טוב יותר.
Random Forest (לקריאה עצמית - לא למבחן)
שיטה מאד נפוצה ויעילה לפתרון בעיות ב supervised learning נקראת random forest. שיטה זו היא למעשה שימוש בעצי החלטה בשילוב עם bagging בתוספת של שינוי אחד קטן. ב random forest כדי להגדיל את האקראיות ואת השוני בין העצים (מלבד העובדה שהם פועלים על מדגמים שונים) אנו נכניס אקראיות נוספת לתהליך הבניה של העץ.
אנו נעשה זאת על ידי בחירה מראש של קבוע שלם (hyperparameter) b אשר קטן מהמימד (מספר השדות / איברים) של x. בכל בחירה של node אנו נגריל באקראי b שדות מתוך כלל השדות של x ונגביל את הבחירה של כלל ההחלטה רק לשדות אלו. הגבלה זו אמורה להכניס הרבה מאד אקראיות לתהליך הבניה של העץ. שאר האלגוריתם של בניית העצים וה bagging לא משתנים.
מדוע השיטה עובדת?
הפחתה בהתאמת יתר
דיוק גבוה
חסינות בפני נתונים בעייתיים (כגון נתונים חסרים, outliers)
קיימות הבטחות תיאורטיות (לא נדון)
AdaBoost
בניגוד ל bagging, ב boosting ננסה להשתמש במכלול של חזאים בעלי הטיה גבוהה אך שונות נמוכה כדי ליצור חזאי כולל בעל הטיה נמוכה מבלי להגדיל באופן משמעותי את השונות. נתמקד בבעיות סיווג בינארי, ובדומה לדיון על SVM, גם כאן אנו נניח כי התווית בבעיה הם y=±1.
בקורס זה נציג את אחת משיטות ה boosting הפופולריות ביותר אשר נקראת AdaBoost (adaptive-boosting). בהינתן אוסף של חזאים h~(x) בעלי הטיה גובהה, שיטה זו מנסה לבנות חזאי מהצורה של:
h(x)=sign(m=1∑Mαmh~m(x))
כך ש h(x) יהיה בעל הטיה נמוכה. בפועל זאת אומרת שאנו מעוניינים לקחת מכלול של מסווגים שעושים התאמת חסר ולשלבם כדי לקבל מסווג אשר שמתאים בצורה טובה יותר לבעיה. בחירה פופולרית של מסווגים כאלה הינה עצי החלטה בעומק 1 המכונים stumps (עצים עם פיצול יחיד).
החידוש ש AdaBoost הכניס לעומת שיטת ה boosting שהייתה קיימת לפניו, הינה העובדה ש αm תלוי ב m, זאת אומרת לכל h~ יש את המקדם שלו. מכאן מגיע ה adaptive בשם של האלגוריתם.
בעיית ה boosting המקורית (לקריאה עצמאית - לא למבחן)
במקור boosting פותח כמענה לשאלה תיאורתית שהתייחסה ליכולת לבנות מסווג "טוב" בהינתן אוסף של מסווגים "גרועים". על מנת לרשום זאת באופן יותר פורמלי נגדיר את המושגים של לומד חזק ולומד (weak / strong learner). עבור בעיית סיווג בינארית:
אנו נאמר שאלגוריתם מסויים הוא לומד חזק אם לכל ϵ,δ>0 האלגוריתם מסוגל, בהינתן מדגם גדול מספיק, ללמוד פונקציית חיזוי שמקיימת Pr(h(x)=y)<ϵ, בהסתברות גדולה מ 1−δ.
אנו נאמר שאלגוריתם מסויים הוא לומד חלש אם לכל δ>0 קיים γ>0 כך שהאלגוריתם מסוגל, בהינתן מדגם גדול מספיק, ללמוד פונקציית חיזוי שמקיימת Pr(h(x)=y)<21−γ, בהסתברות גדולה מ 1−δ.
במילים פשוטות יותר, לומד חזק הינו אלגוריתם אשר עבור מדגם מספיק גדול ייצר חזאי מדוייק כרצונינו ולומד חלש הינו אלגוריתם אשר מסוגל לייצר חזאי שהוא קצת יותר טוב מניחוש אקראי (הטלת מטבע).
בעזרת boosting הצליחו להוכיח את הטענה שניתן להפוך כל לומד חלש ללומד חזק על ידי בניית קומבינציה לינארית של מסווגים אשר נוצרו בעזרת הלומד החלש.
החסם על ה misclassification rate
לפני שנציג את הבעיית האופטימיזציה שאותה AdaBoost מנסה לפתור, נראה תחילה שעבור חזאי מהצורה של
h(x)=sign(m=1∑Mαmh~m(x))
ותוויות של y=±1, adht, שגיאת 0-1 האמפירית חסום מלמעלה על ידי:
את השוויון האחרון ניתן להראות על ידי הפרדה לשני מקרים על פי הסימן של yz. כאשר נציב את המבנה של h(x) לתוך הנוסחא של שגיאת 0-1 האמפירית ונשתמש באי השיוון הנ"ל על כל איבר בסכום נקבל כי:
תגרום כנראה להקטנת שגיאת 0-1 האמפירית ובכך להקטנת ההטיה. יתרה מזאת, אנו נראה בהמשך כי תחת תנאים מסויימים מתקיים שכאשר M→∞ החסם ידעך ל-0 וכך גם שגיאת 0-1 האמפירית.
הדרך שבה AdaBoost מנסה לפתור את בעיית האופטימיזציה הינה בצורה חמדנית. בשיטה זו אנו נגדיל את M בהדרגה כאשר בכל פעם נחפש את ה αm וה h~m האופטימלים. נראה כעת כיצד כיצד ניתן למצוא את αm ו h~m האופטימליים בכל שלב.
נסתכל על המצב בו כבר מצאנו את כל ה αm וה h~m עד ל M−1, וכעת אנו רוצים למצוא את αM ו h~M. אנו רוצים אם כן לפתור את בעיית האופטימיזציה הבאה:
בבעיית האופטימיזציה הזו αM יכול לקבל כל ערך בעוד שאת h~M עלינו לבחור מתוך מאגר מסווגים נתון. הדרך לפתור את בעיית האופטימיזציה הזו היא על ידי השלבים הבאים:
רישום מחדש של בעיית האופטימיזציה בצורה יותר פשוטה.
מציאת αM כפונקציה של h~M על ידי גזירה והשוואה ל-0.
הצבה של αM בחזרה לבעיית האופטימיזציה על מנת לקבל ביטוי פשוט שאותו יש למזער כתלות ב h~M.
נציג כעת את הפתרון של בעיה זו, כאשר הפיתוח המלא של הפתרון מופיע בסוף ההרצאה. כדי לרשום את הפתרון בצורה פשוטה נגדיר את הגדלים הבאים ונסביר מה הם מייצגים:
נתחיל מהאיבר wi(M−1) שהוא למעשה גרסא "מנורמלת" של w~i(M−1) כך שסכימה על כל איבריו לפי i תיתן 1. ניתן למעשה להסתכל על איבר זה כעל איבר מישקול אשר נותן מישקל שונה לכל דגימה במדגם כך שסכום כל המשקלים יהיה 1. נמשיך לפונקציה ε שהיא למעשה דומה מאד לביטוי של שגיאת 0-1 האמפירית של h~ עד כדי המשקלים wi אשר נותנים חשיבות יתרה לחלק מהדגימות במדגם על פני דגימות אחרות. פונקציה זו היא למעשה שגיאת 0-1 אמפירית ממושקלת.
h~M ו αM האופטימליים בכל שלב יהיו נתונים על ידי:
נסתכל על המשקל ללא הנרמול של הדגימה ה i. משקל זה שווה ל w~i(M)=exp(−y(i)∑m=1Mαmh~m(x(i))). משקל זה מציין למעשה עד כמה טוב האלגוריתם מסווג את הדגימה ה i. כאשר הסיווג הוא נכון ו ∑m=1Mαmh~m(x(i)) באותו סימן של y(i) משקל זה יהיה קטן מ 1 (e עם חזקה שלילית) וכאשר הסיווג הוא שגוי המשקל יהיה גדול מ 1. הגודל בערך מוחלט של ∑m=1Mαmh~m(x(i)) קובע עד כמה המשקל יהיה גדול או קטן מ 1. גודל זה במובן מסויים מציין את הודאות של המסווג בחיזוי.
מכאן שתפקיד המשקלים הוא לדאוג שהאלגוריתם יבחר בכל צעד את החזאי אשר ישפר את הסיווג בעיקר על הדגימות שעליהן החזאי הנוכחי טועה.
תנאי עצירה
באופן כללי בחלק גדול מהמקרים AdaBoost ילך ויקטין את שגיאת החיזוי על המדגם ככל שנגדיל את M עד שהוא יגיע לסיווג מושלם. אך תכונה מפתיעה של AdaBoost (ואלגוריתמי boosting באופן כללי) הינה שהם ממשיכים לשפר את יכולת ההכללה שלהם אם ממשיכים להריץ את האלגוריתם גם אחרי שהוא הגיע לסיווג מושלם. בנוסף אלגוריתמים אלו לרוב יגדילו את כמות התאמת היתר שהחזאי עושה בקצב מאד איטי (אם בכלל). זאת אומרת שלרוב נרצה להריץ את האלגוריתם מספר רב של צעדים ולבדוק במהלך הריצה את הביצועים שלו על validation set. נעצור את האלגוריתם כאשר האלגוריתם יפסיק להשתפר או כאשר יגיע למספר צעדים מקסימאלי שנקבע מראש.
קצב ההתכנסות של החסם
ראינו קודם כי שגיאת 0-1 האמפירית (הלא ממושקלת) של החזאי על המדגם חסומה על ידי ה הביטוי:
מכיוון שמדובר בבעיית סיווג בינארית עם תוויות ±1 הביטוי y(i)hM(x(i)) יכול לקבל רק אחד משני ערכים, 1 כאשר y(i)=hM(x(i)) ו −1 אחרת. נפצל אם כך את הסכום לשני המקרים על ידי הוספה של פונקציות אינדיקטור:
כעת נשים לב שמכיוון שמדובר בבעיית סיווג בינארית עם תוויות ±1 הביטוי y(i)h(x(i)) יכול לקבל רק אחד משני ערכים, 1 כאשר y(i)=h(x(i)) ו −1 אחרת. נפצל אם כך את הסכום לשני המקרים על ידי הוספה של פונקציות אידיקציה:
הגודל ∑i=1Nw~i(M−1) הוא קבוע מבחינת בעיית האופטימיזציה ולכן נוכל לחלק את התוצאה שקיבלנו בגודל זה מבלי לשנות את בעיית האופטימיזציה. נקבל לאחר פעולה זו את ה objective הבא:
כפונקציה של ε ה objective הוא ε(1−ε). זהו פולינום הפוך שמקבל את ערכו המקסימאלי ב ε=21 ומתאפס ב ε=0,1. נניח לרגע ש ε הוא בתחום של [0,0.5], מיד נצדיק הנחה זו. במקרה זה הערך המינימאלי של ה objective יהיה כאשר ε יהיה מיניאלי. זאת אומרת ש:
נסביר מדוע ניתן להניח ש ε הוא בתחום של [0,0.5]. באופן כללי ε הוא ממוצע ממושקל של פונקציות אינדיקטורים שמקבלים 0 או 1 ולכן הוא יכול לקבל ערכים בתחום [0,1]. כדי לפשט את הבעיה נוכל להניח שאנו דואגים מראש לטפל במסווגים שבהם שגיאת 0-1 האמפירית הממושקלת קטנה מחצי על ידי היפוך הסימן של מוצא החזאי. הסיבה לעשות זאת הינה שהמקרים שבהם שגיאת 0-1 האמפירית הממושקלת גדולה מחצי הם מקרים שבהם החזאי מבצע יותר טעויות מחיזויים נכונים (באופן ממושקל). במקרים כאלה ההפוך של החזאי יגרום להם לעשות פחות טעויות מחיזויים נכונים ויהפוך את ה miscalssification rate הממושקל שלהם ל 1−ε שיהיה קטן מחצי.
(באופן כללי לא חייבים לבצע את ההיפוך ובמקום זאת צריך למזער את ∣0.5−ε∣ והמשקול αM ידאג להפוך את הסימן של המוצא של החזאי כאשר זה הכרחי במקום לעשות זאת באופן ידני)