הרצאה 2 - רגרסיה לינארית
מה נלמד היום

Supervised learing (למידה מונחית)
בהרצאה הקודמת הכרנו באופן כללי את סוגי הבעיות בהם עוסק התחום של מערכות לומדות והתחלנו לדבר על בעיות מסוג supervised learning (למידה מונחית). בעיות אלו הם הבסיסיות ביותר בתחום והבנה טובה של בעיות אלו היא הבסיס להבנה של כל שאר הבעיות במערכות לומדות. אנו נעסוק בבעיות מסוג זה לאורך רוב רובו של הסימסטר.
על מנת להבין ולהגדיר מה הם בעיות supervised learning עלינו ראשית לחזור על הנושא של בעיות חיזוי.
בעיית החיזוי
בתרגול 2 מופיעה תזכורת מורחבת יותר של התחום, אך לצורך הרצאה זו נסתפק בתיאור הקצר המופיע פה. בבעיית החיזוי אנו מנסים לחזות את ערכו של משתנה אקראי לא ידוע, לרוב על סמך משתנים אקראיים ידועים. בעיות חיזוי הם מאד נפוצות ומופיעות במגוון רחב של תחומים בהנדסה ומדע. בהנדסת חשמל בעיות אלו מופיעות בתחומים כגון עיבוד אותות, תקשורת ספרתית ובקרה. יתרה מזאת, בעיות חיזוי מלוות אותנו כמעט בכל פעולה יום יומית, לדוגמא:
כאשר אנחנו מתלבטים האם לקחת איתנו מטריה ביציאה מהבית, אנו למעשה מנסים לבצע חיזוי של האם ירד גשם או לא על סמך פרטי מידע שיש בידינו, כגון התחזית ששמענו, כמות העננים בשמים, צבע העננים וכו'.
ביום יום אנחנו אולי לא מנסים לפתור את בעיות החיזוי באופן מתמטי, אך אנו כן מחזיקים בראש איזה שהוא מודל של הקשרים הסטטיסטים בין המשתנים השונים, ואנו מנסים לבצע את החיזוי על סמך אותו מודל באופן איכותי.
הקשר ל supervised learning
בבעיות חיזוי קלאסיות, אנו מניחים שהפילוג של כל המשתנים האקראיים ידוע, וכי האתגר הוא מציאת החזאי האופטימאלי על סמך הפילוג. לעומת זאת, בבעיות supervised learning (ובבעיות במערכות לומדות באופן כללי) אנו מניחים כי הפילוג אינו ידוע ובמקומו נתון לנו מדגם של דגימות מתוך אותו פילוג. את החזאי נאלץ כעת לבנות על סמך המדגם במקום על סמך הפילוג. במהלך הקורס אנו נדון נכיר שיטות שונות לבנות חזאים באופן זה ונדון בבעיות הקיימות בשיטות אלו.
סימונים ושמות
בקורס זה אנו נשתמש בסימונים והשמות הבאים:
- Labels (תויות / תגיות): (או במקרה הוקטורי ) - יהיה המשתנה / הוקטור האקראי שאותו אנו מנסים לחזות. בקורס זה ה labels, , יהיו כמעט תמיד סקלריים.
- Observations \ measurements (תצפיות או מדידות): (או במקרה הוקטורי ) - יהיה הוקטור האקראי אשר מכיל את המשתנים שלפיהם נרצה לבצע את החיזוי. במקרים מסויימים החיזוי יהיה על פי משתנה יחיד ואז יהיה סקלר.
- - תוצאת חיזוי כל שהיא.
- מרחב החזאים \ השערות . במרחב זה נמצאים כל החזאים האפשריים.
- - פונקציית החיזוי. נשים לב כי .
- אנו נשתדל להשתמש ב לסימון האורך של הוקטור
The dataset (המדגם)
כפי שציינו, את הבניה של החזאי אנו נעשה על פי מדגם מתוך הפילוג הלא ידוע. לרוב המדגם יהיה מורכב מזוגות של ו אשר יוצרו מתוך דגימות בלתי תלויות:
נשתדל להשתמש תמיד ב לסימון מספר הדגימות שבמדגם.
הנחת ה i.i.d
במערכות לומדות אנו תמיד נניח כי הדגימות במדגם נוצרו כולם מאותו הפילוג באופן בלתי תלוי אחת בשניה. זאת אומרת שזוג המשתנים הינו בלתי תלוי סטטיסטית בזוג המשתנים כאשר .
מהו החזאי האופטימאלי
באופן כללי, כל פונקציה אשר ממפה מהמרחב של למרחב של היא פונקציית חיזוי חוקית. נשאלת אם כן השאלה מהי פונקציית החיזוי המוצלחת ביותר? באופן כללי היינו מעוניינים למצוא חזאי אשר לעולם לא טועה.בפועל, מכיוון ש הינו משתנה אקראי לא נוכל אף פעם לחזותו במדוייק (מלבד במקרים מיוחדים בהם נקבע באופן חד ערכי על ידי ).
מיכוון שבעבור כל חיזוי שנבחר אנו מצפים לשגיאה כל שהיא, אנו צריכים להגדיר דרך להשוות בין הטעויות שאותם מבצעים החזאים שונים. אנו צריכים להחליט לדוגמא איך נבחר בין חזאי שעושה כל הזמן שגיאות בינוניות לבין חזאי אשר רוב הזמן עושה שגיאות ממש קטנות אך פעם בכמה זמן עושה שגיאה מאד גדולה. הנושא הראשון שנעסוק בו בהרצאה יהיה הדרך שבה נרצה להשוות בין הביצועים של חזאים שונים.
Regression vs. Classification
מוקבל לחלק את הבעיות ב supervised learning לשני תתי תחומים:
- בעיות regression (רגרסיה) - בעיות בהם הוא משתנה רציף.
- בעיות classification (סיווג) - בעיות בהם הוא משתנה בדיד אשר יכול לקבל ערכים מתוך סט ערכים סופי (ולרוב קטן).
דוגמאות:
- רגרסיה: חיזוי זמן נסיעה בכביש החוף, חיזוי מרחקים לאובייקטים בתמונה, חיזוי מחירים של דירות וכו'.
- סיווג: חיזוי של המחלה בה חולה אדם מסויים על פי הסימפטומים שלו, חיזוי של האם דואר מסויים הוא spam או לא, חיזוי של האם עסקת אשראי מסויימים היא לגיטימית או הונאה וכו'/
(בעיקרון יכולים להיות גם בעיות בהם בדיד ולא סופי. בבעיות מסוג זה לרוב פשוט מניחים ש רציף והופכים את הבעיה לבעיית רגרסיה ולבסוף מעגלים את התוצאה).
כפי שנראה בהמשך הקורס, אבחנה זו חשובה מכיוון שהאופי של ישפיע על הדרך שבה ננסה לפתור את הבעיה.
בעיית רגרסיה לדוגמא
נסתכל על בעיית החיזוי של זמן הנסיעה בכביש החוף על סמך מספר המכוניות בכביש:
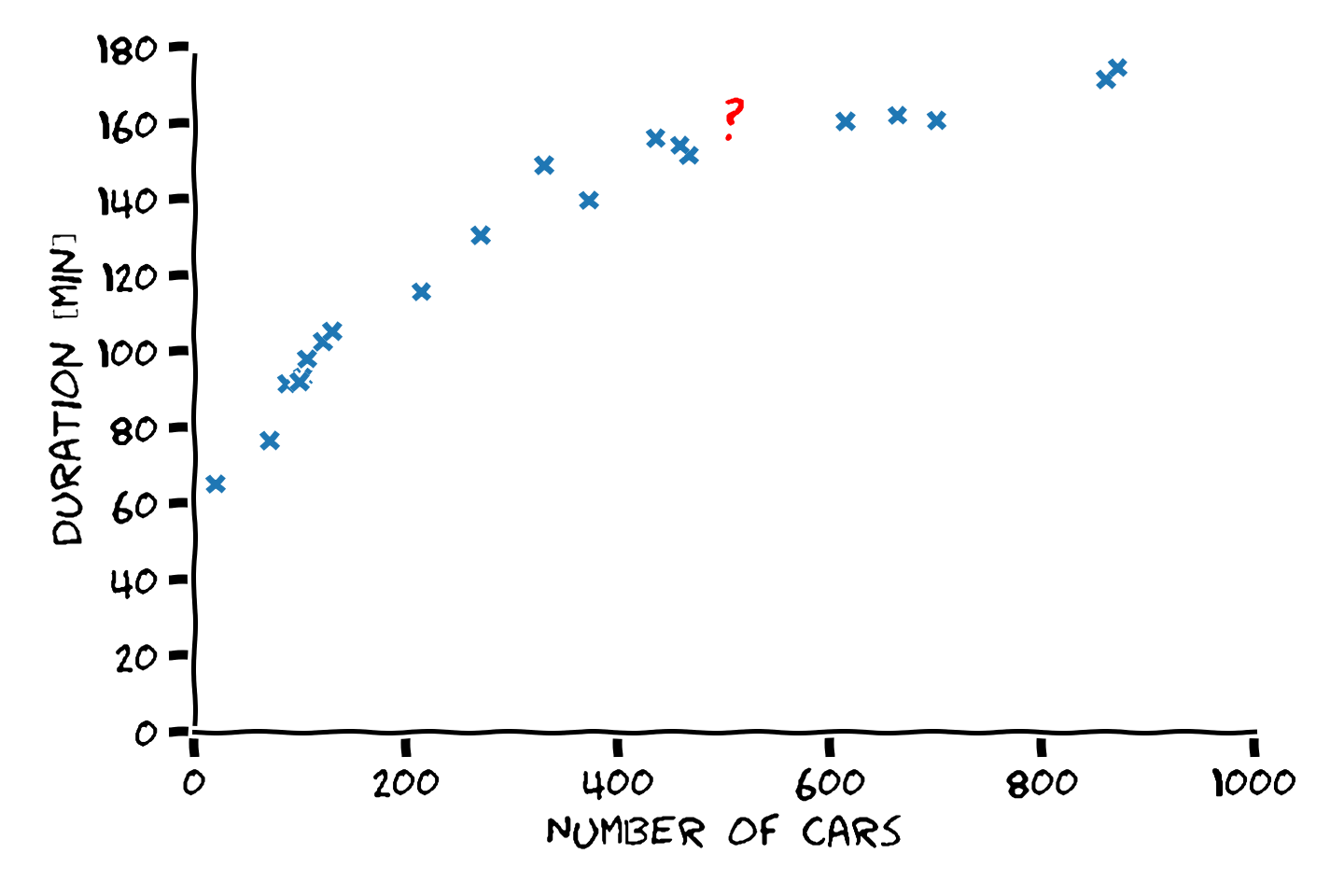
ננסח את הבעיה בצורה פורמאלית:
- Labels - - המשתנה האקראי של זמן הנסיעה.
- Meassurments - - המשתנה האקראי של מספר המכוניות על הכביש.
- - פונקציית החיזוי אשר מקבלת את מספר המכוניות על הכביש ומוציאה חיזוי של זמן הנסיעה.
- - מדגם הנתון של הזוגות של (מספר מכוניות, זמן נסיעה).
המטרה שלנו הינה להשתמש ב על מנת למצוא חזאי אשר יהיה כמה שיותר מוצלח תחת קריטריון שאותו נצטרך להגדיר.
השלבים הכלליים לפתרון הבעיה
הרעיון מאחורי כמעט כל השיטות במערכות לומדות הוא זהה:
- נגדיר קריטריון מתמטי אשר מודד עד כמה מודל מסויים מצליח לבצע את המשימה
- נבחר משפחה רחבה של מודלים בתקווה שלפחות אחד מהם יהיה מוצלח מספיק.
- נחפש מבין כל המודלים במשפחה את המודל המוצלח ביותר.
The cost function (פונקציית המחיר)
נתחיל מהשלב הראשון של הגדרת הקריטריון של שלפיו נרצה לבחור את החזאי שלנו. הדרך המקובלת לעשות זאת הינה על ידי הגדרת פונקציית מחיר.
פונקציית המחיר היא פונקציה אשר מעניקה לכל חזאי ציון. לרוב נהוג להגדיר את הפונקציה כך שככל שהציון נמוך יותר החזאי טוב יותר. אנו נגדיר את החזאי האופטימאלי כחזאי בעל הציון הנמוך ביותר מבין כל החזאים האפשריים. נסמן את החזאי האופטימאלי ב :
ישנם דרכים רבות להגדיר את פונקציית המחיר, ואין דרך "נכונה" לעשות זאת. באופן כללי, הבחירה של פונקציית המחיר צריכה להתאים לבעיה שאותה רוצים לפתור בעזרת החזאי. באופן כללי פונקציית המחיר אמורה לשקף את המחיר אותו "נשלם" על שימוש בחזאי נתון כל שהוא, בפועל, במרבית המקרים משתמשים באחת מכמה פונקציות מחיר נפוצות.
נציג את אחת הדרכים הפופולריות להגדיר פונקציית מחיר, אשר עושה זאת על ידי שימוש בפונקציה הנקראת פונקציית הפסד (loss function).
Risk and loss functions (פונקציות סיכון והפסד)
פונקציית הסיכון הינה מקרה פרטי של פונקציית המחיר והיא מוגדרת באופן הבא:
בעוד שפונקציית המחיר מנסה לתת ציון ליכולת החיזוי הכללית של החזאי, פונקציית ההפסד נותנת ציון לחיזוי בודד מסויים. שבהינתן חזאי ודגימה אקראית עם ו מסויימים, ההפסד המשוייך לדגימה זו יהיה:
את פונקציית המחיר הכוללת ניתן כעת להגדיר כתוחלת של פונקציית ה loss על פני הפילוג של ו
במקרים כאלה, מוקבל לכנות את פונקציית המחיר, פונקציית הrisk (סיכון), ולסמנה באות :
פונקציות loss נפוצות
-
פונקציית loss נפוצה לבעיות classification היא פונקציית ה Zero-One loss אשר מוגדרת באופן הבא:
לפונקציית ה risk אשר משתמשת ב loss הזה קוראים: misclassification rate.
-
פונקציית loss נפוצה לבעיות regression היא פונקציית ה loss אשר מוגדרת באופן הבא:
לפונקציית ה risk אשר משתמשת ב loss הזה קוראים: mean squared errors (MSE).
- במקרים רבים נהוג להשתמש דווקא בשורש של ה MSE בכדי שפונקציית המחיר תחזיר ערכים באותם יחידות כמו . במקרה זה קוראים לפונקציית המחיר root mean squared errors (RMSE). התוספת של השורש לא משנה את בעיית האופטימיזציה (משום שהיא פונקציה מונוטונית עולה) ולכן הוא לא משפיע על החזאי המתקבל.
-
פונקציית loss נפוצה נוספת לבעיות regression היא פונקציית ה loss אשר מוגדרת באופן הבא:
לפונקציית ה risk אשר משתמשת ב loss הזה קוראים: mean absolute errors (MAE).
בעיה: הפילוג של המשתנים האקראיים לא ידוע
הבעיה עם האופן שבו הגדרנו את פונקציית הסיכון הינה העובדה שהיא מוגדרת על ידי תוחלת על פני הפילוג של המשתנים האקראיים בבעיה שהוא כאמור לא ידוע. בעיה זו קיימת לא רק בפונקציות מחיר מסוג סיכון אלא גם בסוגים שונים של פונקציות מחיר אשר כמעט תמיד תלויות בפילוג של המשתנים האקראיים בבעיה.
שיערוך אמפירי של פונקציית המחיר / סיכון
בכדי לנסות ולהתמודד עם בעיה זו נוכל במקום לנסות ולחשב את ערכה של פונקציית המחיר באופן אנליטי, לנסות ולשערך את ערכה של פונקציית הסיכון על סמך אוסף של דוגמאות מתוך הפילוג (מדגם). שיעוך על סמך דוגמאות מכונה שיערוך אמפירי.
Empirical risk (סיכון אמפירי)
הסיכון האמפירי מוגדר על ידי החלפת התוחלת בפונקציית הסיכון בגרסא האמפירית שלה. אנו נשתמש בסימון על מנת לסמן את תחולת האמפירית המבוססת על המדגם נתון .
ניתן להראות כי כאשר מספר הדגימות הולך לאין סוף התוחלת האמפירית מתכנסת לתוחלת האמיתית במובן הסתברותי.
הסיכון האמפירי המקבל מהחלפה זו הינו:
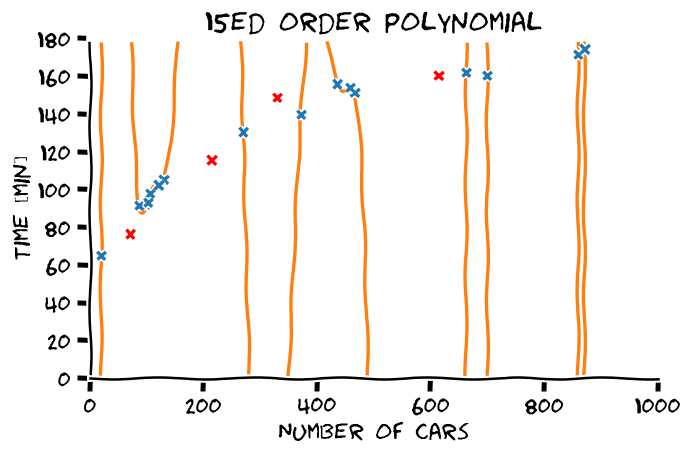
התאמת יתר
השימוש בגרסא האמפירית של פונקציית המחיר היא במקרים רבים בעייתית והיא גורמת בין היתר לתופעה המוכנה overfitting (התאמת יתר). בשלב זה אנו נתעלם מבעיה זו ואנו נעסוק בה בהרחבה בהרצאה הבאה.
גישות לפתרון בעיות supervised learning
לפני שנעבור לשלב הבניה של החזאי אנו נציג שתי גישות שונות לבהם ניתן לגשת לבעיה. באופן כללי ניתן לחלק את השיטות לפתרון בעיות supervised learning לשתי הגישות הבאות:
גישה גנרטיבית (generative) - בגישה זו אנו ננסה להשתמש במדגם על מנת לנסות וללמוד את הפילוג הלא ידוע. שיטה זו נקראת גנרטיבית משום שהיא לומדת את הפילוג שמתוכו נוצרו (generated) הדגימות.
גישה דיסקרימינטיבית (discriminative) - בשיטה זו ננסה לבנות חזאי אופטימאלי על סמך הגרסא האמפירית של פונקציית המחיר בתקווה שהוא יקבל ציון טוב גם בגרסא הלא אמפירית של פונקציית המחיר (זאת אומרת, שהוא ידע להכליל בצורה טובה).
לכל אחד מהגישות יש את היתרונות והחסרונות שלה. במהלך הקורס נכיר אלגוריתמים משני הגישות ונעמוד על ההבדלים בניהם.
Empirical risk minimization (ERM)
בעבור מקרים בהם פונקציית המחיר מוגדרת כפונקציית סיכון, הגישה הדיסקרימינטיבית הבסיסית ביותר הינה לנסות לחפש באופן ישיר חזאי אשר ממזער את הסיכון האמפירי. הגישה הזו מכונה ERM (Empirical Rik Minimization) והיא מוגדרת על ידי בעיית האופטימיזציה הבאה:
שימו לב כי הוספנו את הכיתוב מתחת לחזאי האופטימאלי של בעיית האופטימיזציה זו. עשינו זאת משתי סיבות:
- על מנת להדגיש את התלות של החזאי במדגם (לכל מדגם יהיה חזאי אופטימאלי אחר).
- בכדי להבדיל את החזאי המתקבל משיטת ה ERM מהחזאי האופטימאלי של הבעיה המקורית אשר באופן עקרוני יהיה שונה.
מודלים פרמטריים
לרוב אנו נרצה להגביל את החזאי שלנו למשפחה מצומצמת של פונקציות. לרוב אנו נרצה לעשות זאת על ידי בחירה של משפחה של פונקציות אשר מוגדרות על ידי מודל פרמטרי. ישנם שני סיבות עיקריות לכך:
- כפי שנראה בהרצאה הבאה הגבלה זו חשובה בכדי לשפר את יכול ההכללה של החזאי ולסייע בהקטנת בעיית הoverfitting.
- יותר פרקטי לנסות לחפש פרמטרים של מודל מאשר חיפוש כללי של פונקציה במרחב הפונקציות.
מודל פרמטרי מגדיר את המבנה הכללי של הפונקציות במשפחה עד כדי מספר סופי של פרמטרים אשר חופשיים להשתנות. את הפרמטרים של המודל נסמן בעזרת הוקטור . אנו נשתמש ב בכדי לתאר חזאי מהמשפחה הפרמטרית עם פרמטרים . אין כל מגבלה על הצורה הכללית שלהמודל הפרמטרי, המודל הפרמטרי יכול להיות לדוגמא:
דוגמאות נוספות למודלים פרמטריים:
- פונקציות לינאריות:
- פולינומים:
- טור פוריה סופי:
- רשתות נוירונים
מודל פרמטרי למעשה ממפה כל פונקציה מהמשפחה הפרמטרית לוקטור. היתרון בעבודה עם וקטורים הינו שיש לנו סט עשיר של כלים בהם אנו יכולים להשתמש. לדוגמא, מכיוון שניתן לגזור לפי וקטורים, נוכל להשתמש ב gradient decent על מנת לחפש את המודל האופטימאלי במרחב המודלים. מיכוון שכל וקטור כעת מגדיר מודל מסויים (ולהיפך) ניתן לרשום את בעיית האופטימיזציה של מציאת המודל האופטימאלי כבעיית אופטימיזציה על וקטור הפרמטרים (במקום על ):
או במקרה של ERM:
מודל לינארי
המודל הפרמטרי הפשוט ביותר הינו המודל הלינארי. המודל הלינארי הוא בעל המבנה הבא::
דרך נוחה יותר לכתוב את המודל הזה היא בצורה וקטורית:
איבר היסט (bias)
ניתן להוסיף למודל גם איבר bias על מנת לקבל מודל מהצורה הבאה:
לשם הנוחות בכדי לשמור על הכתיב הוקטורי של המודל נפריד לרוב את איבר ה bias משאר הפרמטרים. לרוב נסמן אותו בעזרת או :
אנו נראה מיד דרך נוחה יותר להוספת איבר ההיסט בעזרת שינוי של הוקטור כך שהביטוי יכיל גם את איבר ההיסט.
Linear Least Squares (LLS)
מקרה מיוחד של בעיית ERM עם מודל לינארי, הוא המקרה שבו משתמשים בפונקציית MSE (פונקציית risk עם loss ריבועי ()):
השימוש במודלים לינאריים וב MSE נפוץ מאד ולכן בעיית ה LLS מופיעה בתחומים רבים. בעיית האופטימיזציה המקבלת בעבור LLS הינה:
כתיב מטריצי
את בעיה זו ניתן לרשום גם בצורה קומפקטית על ידי הגדרת הוקטור והמטריצה הבאים:
-
נדגיר את וקטור התגיות כוקטור של כל התגיות במדגם:
-
נגדיר את המטריצת המדידות כמטריצה של כל ה -ים במדגם:
בעזרת הגדרות אלו ניתן לרשום את בעיית האופטימיזציה של LLS באופן הבא:
(ניתן להראות זאת על ידי רישום הורמה כסכום ושימוש בעובדה ש )
פתרון סגור
מה שמיוחד בבעיית האופטימיזציה של LLS הינה העובדה שניתן להגיע לפתרון סגור לפרמטרים האופטימאלייים על ידי גזירה והשוואה ל-0. הפתרון המתקבל הינו: (את החישוב עצמו אתם תראו בתרגול 3)
פתרון זה נכון רק כאשר המטריצה הפיכה. בתרגול אנו נדון במשמעות של תנאי זה.
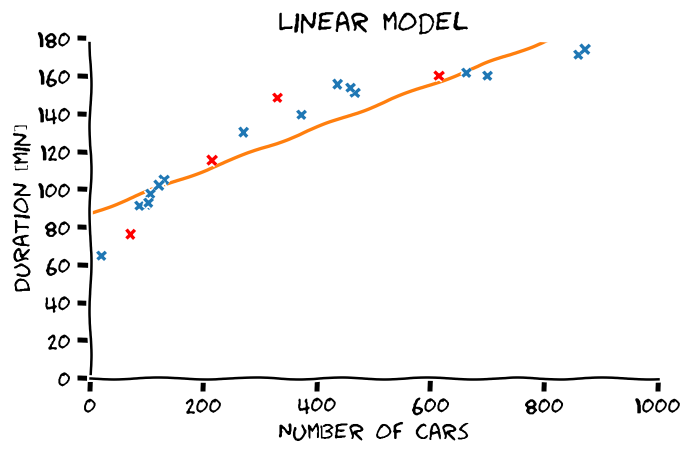
דוגמא
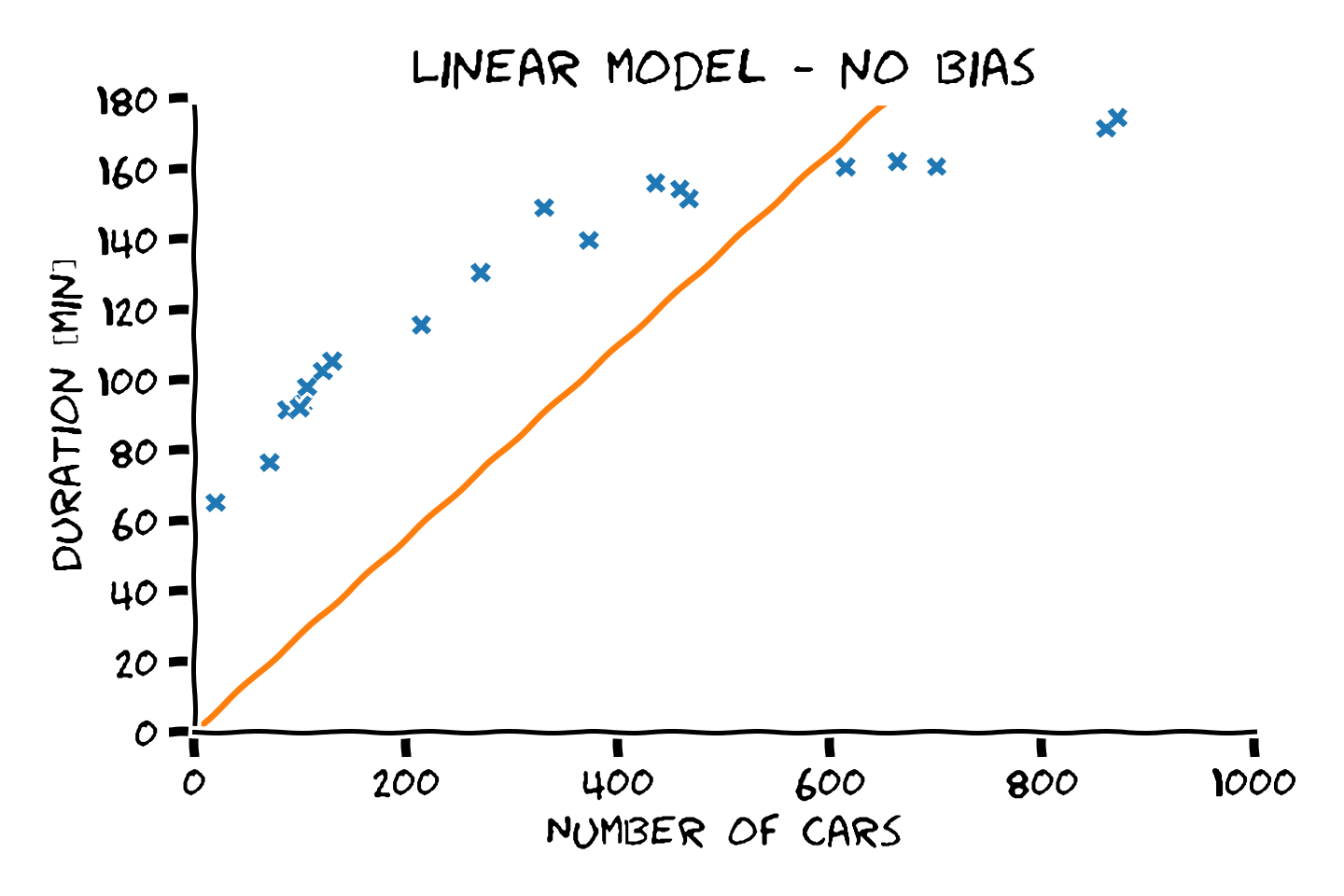
נשתמש במודל לינארי ובפתרון של בעיית ה LLS בכדי למצוא חזאי לבעיית שיערוך זמן הנסיעה. נתחיל במודל ללא היסט:
את הפרמטר האופטימאלי נוכל לחשב על ידי הצבה של הנקודות במדגם לתוך:
כאשר . התוצאה המקבלת הינה
הוספת איבר היסט
בכדי להוסיף איבר היסט, עלינו להשתמש במודל מהצורה של:
הבעיה אם צורה זו הינה, שהפתרון הסגור שמצאו מתייחס למקרה שבו אין איבר היסט, לשם ככך ננסה לנסח מחדש את הבעיה כך שיתקבל מודל ללא איבר היסט.
עיבוד מקדים
נשים לב לעובדה שבבואנו לבצע משימת חיזוי אנו לא חייבים להשתמש בנתונים בצורת הגולמית ומותר לנו לבצע עיבוד מקדים של הנתונים לפני שאנו מזינים אותם לחזאי. נניח לדוגמא שאנו מעריכים שיהיה נוח יותר לבצע את החיזוי של זמן הנסיעה על פי הריבוע של כמות המכוניות על הכביש. במקרה שכזה נוכל פשוט להעלות המספר המכוניות בריבוע לפני שאנו מזינים אותם לחזאי. העיבוד המקדים יכול למעשה לפעול על כל וקטור המדידות , לעבד אותו ולייצר ממנו וקטור חדש. אנו נסמן ב את הפונקציה אשר מקבלת את המידע הגולמי מייצרת ממנו את :
פעולת החיזוי במקרים אלו תהיה:
את קלט החדש מקובל לכנות וקטור המאפיינים (features). השימוש במאפיינים מאפשר לנו מספרים דברים:
- הרחבת מודלים פשוטים, כגון המודל הלינארי למודלים מורכבים יותר (כפי שנראה כאן ובתרגול).
-
שינוי האופן בו מיוצג המידע כך שיהיה לחזאי קל יותר לבצע את בעיית החיזוי. לדוגמא:
- החלפת היחידות שבהם השתמשו לתיאור מדידה מסויימת
- הפיכת תמונת פנים לוקטור של מאפיינים של פנים כגון: המרחק בין העיניים, גוון העור, עד כמה הפנים אליפטיות וכו'
- ניקוי רעשים להקלטות audio.
- לקראת סוף הקורס נראה גם כיצד ניתן להשתמש במאפיינים על מנת להתמודד עם בעיית ה overfitting בעזרת שיטה המוכנה הורדת מימד.
במקרים רבים נרצה להתייחס לפונקציה אשר מייצרת איבר ספציפי ב , לשם כך נוח להתייחס לפונקציה כוקטור של פונקציות אשר מייצרות כל אחת איבר אחד בוקטור :
סימון מתמטי מקובל בו נשתמש הינו הסימון הבא:
כאן מוצגת כוקטור של פונקציות, כאשר הפעלה וקטור שכזה על מייצרת את הוקטור של הפלטים של הפונקציות
דוגמא: הוספה של איבר ההיסט בעזרת מאפיינים
על ידי שילוב של מודל לינארי עם מאפיינים נוכל לקבל חזאים מהצורה:
נחזור כעת לדוגמא של שיערוך זמן הנסיעה. נראה כעת כיצד ניתן להוסיף את איבר ההיסט על ידי שימוש במאפיינים. העבור הבחירה של במאפיינים הבאים:
כל דגימה תהפוך לוקטור ומודל החיזוי שלנו יהיה:
המטריצת המדידיות תהיה כעת:
הצבה של מטריצה זו בנוחסא ל נותנת את המודל הלינארי הבא:
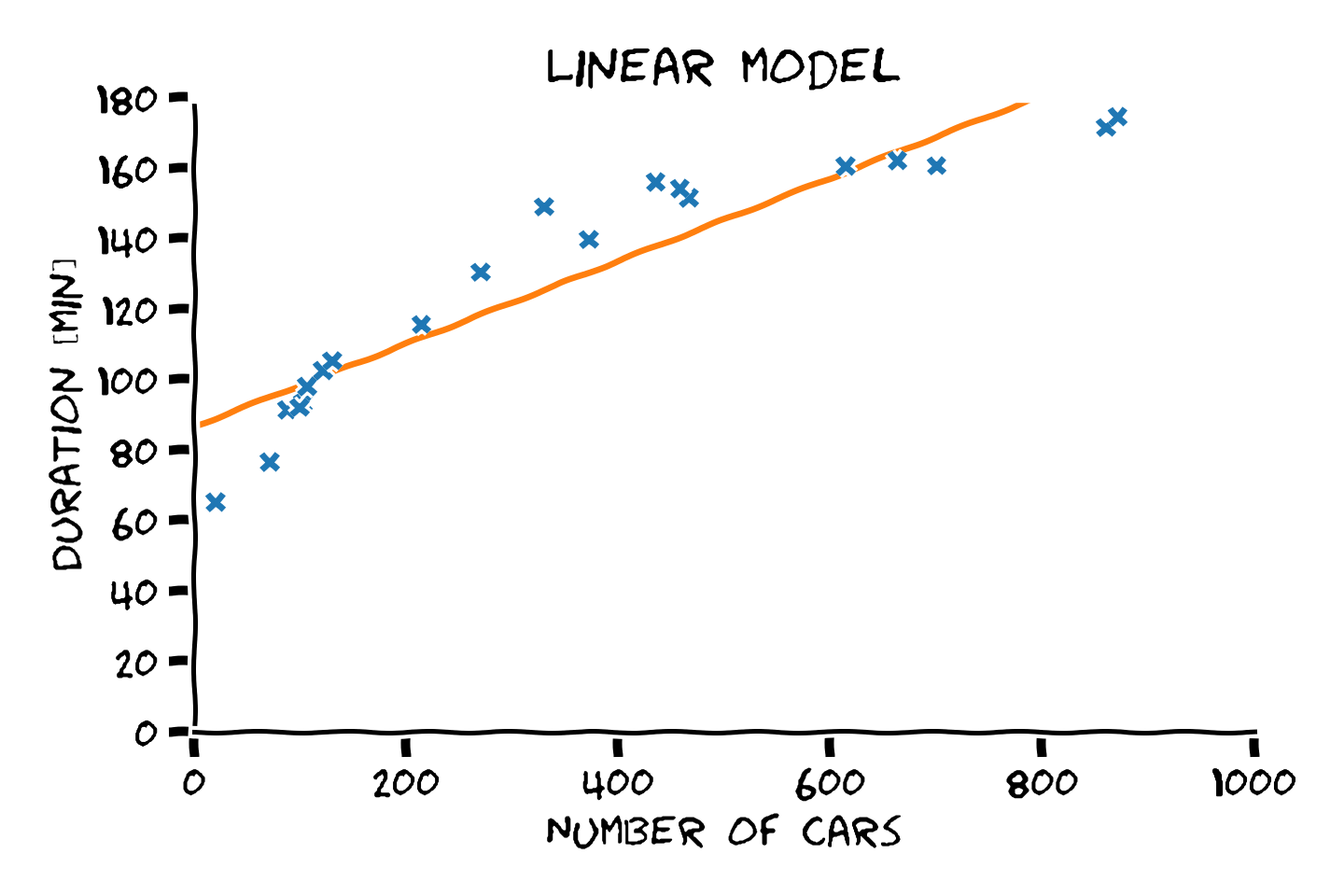
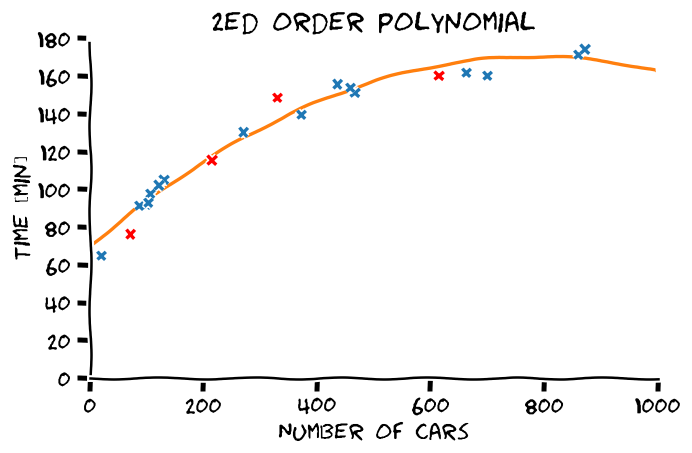
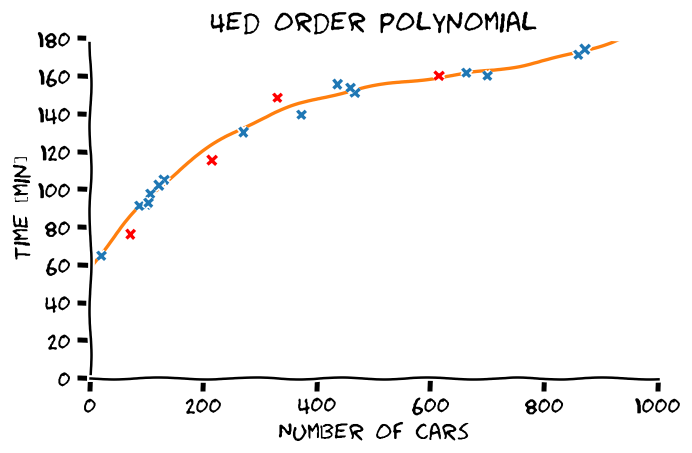
באותו אופן ניתן כמובן להשתמש במודל הלינארי בכדי לייצג מגוון רחב של פונקציות כגון פולינומים או קומבינציה של גאוסיאנים, כפי שיודגם בתרגול 3.