דף נוסחאות
נוטציות
אלגברה לינארית
x x x x \boldsymbol{x} x עמודה x ⊤ \boldsymbol{x}^\top x ⊤ שורה x i x_i x i i i i x \boldsymbol{x} x (בכתב יד נשתמש בחץ (במקום באותיות מדגשות) בכדי לסמן וקטורים: x ⃗ \vec{x} x
⟨ x , y ⟩ ( = x ⊤ y = ∑ i x i y i ) \langle\boldsymbol{x},\boldsymbol{y}\rangle(=\boldsymbol{x}^\top\boldsymbol{y}=\sum_i x_iy_i) ⟨ x , y ⟩ ( = x ⊤ y = ∑ i x i y i ) x \boldsymbol{x} x y \boldsymbol{y} y ∥ x ∥ 2 ( = ⟨ x , x ⟩ ) \|\boldsymbol{x}\|_2(=\sqrt{\langle\boldsymbol{x},\boldsymbol{x}\rangle}) ∥ x ∥ 2 ( = ⟨ x , x ⟩ ) l 2 l2 l 2 x \boldsymbol{x} x ∥ x ∥ l ( = ∑ i ∣ x i ∣ l l ) \|\boldsymbol{x}\|_l(=\sqrt[l]{\sum_i {|x_i|}^l}) ∥ x ∥ l ( = l ∑ i ∣ x i ∣ l ) l l l x \boldsymbol{x} x A \boldsymbol{A} A A ⊤ \boldsymbol{A}^\top A ⊤ A \boldsymbol{A} A A i , j A_{i,j} A i , j j j j i i i A \boldsymbol{A} A A i , : A_{i,:} A i , : i i i A \boldsymbol{A} A A : , i A_{:,i} A : , i i i i A \boldsymbol{A} A
משתנים אקראיים
x \text{x} x x \mathbf{x} x
Sets (קבוצות)
נסמן קבוצה של איברים באופן הבא:
{ x ( 1 ) , x ( 2 ) , … , x ( n ) } \{\boldsymbol{x}^{(1)},\boldsymbol{x}^{(2)},\ldots,\boldsymbol{x}^{(n)}\} { x ( 1 ) , x ( 2 ) , … , x ( n ) } n n n
נגזרות
נגזרות וקטוריות שימושיות
∂ ∂ x a ⊤ x = a \frac{\partial}{\partial\boldsymbol{x}} \boldsymbol{a}^{\top}\boldsymbol{x}=\boldsymbol{a} ∂ x ∂ a ⊤ x = a ∂ ∂ x A x = A \frac{\partial}{\partial\boldsymbol{x}} \boldsymbol{A}\boldsymbol{x}=\boldsymbol{A} ∂ x ∂ A x = A ∂ ∂ x x ⊤ A x = ( A + A ⊤ ) x \frac{\partial}{\partial\boldsymbol{x}} \boldsymbol{x}^{\top}\boldsymbol{A}\boldsymbol{x}=(\boldsymbol{A}+\boldsymbol{A}^{\top})\boldsymbol{x} ∂ x ∂ x ⊤ A x = ( A + A ⊤ ) x ∂ ∂ x ∥ A x + b ∥ 2 2 = 2 A ⊤ ( A x + b ) \frac{\partial}{\partial\boldsymbol{x}} \lVert\boldsymbol{A}\boldsymbol{x}+b\rVert_2^2=2\boldsymbol{A}^{\top}(\boldsymbol{A}\boldsymbol{x}+b) ∂ x ∂ ∥ A x + b ∥ 2 2 = 2 A ⊤ ( A x + b )
נגזרת מטריצית שימושית
∂ ∂ A x ⊤ A x = x x ⊤ \frac{\partial}{\partial\boldsymbol{A}} \boldsymbol{x}^{\top}\boldsymbol{A}\boldsymbol{x}=\boldsymbol{x}\boldsymbol{x}^{\top} ∂ A ∂ x ⊤ A x = x x ⊤
בעיית אופטימיזציה
בעיות מהצורה:
θ ∗ = arg min θ f ( θ ) subject to g i ( θ ) ≤ 0 , i = 1 , … , m h j ( θ ) = 0 , j = 1 , … , p \begin{aligned}
\boldsymbol{\theta}^*=&\underset{\boldsymbol{\theta}}{\arg\min}\quad f(\boldsymbol{\theta}) \\
&\begin{aligned}
\text{subject to}\quad
& g_i(\boldsymbol{\theta})\leq 0,\qquad i=1,\ldots,m \\
& h_j(\boldsymbol{\theta})=0,\qquad j=1,\ldots,p
\end{aligned}
\end{aligned} θ ∗ = θ arg min f ( θ ) subject to g i ( θ ) ≤ 0 , i = 1 , … , m h j ( θ ) = 0 , j = 1 , … , p כאשר g i ( θ ) ≥ 0 g_i(\boldsymbol{\theta})\geq0 g i ( θ ) ≥ 0
ו h i ( θ ) = 0 h_i(\boldsymbol{\theta})=0 h i ( θ ) = 0
הפונקציה f ( θ ) f(\boldsymbol{\theta}) f ( θ ) objective .
כמות האילוצים יכולה להשתנות ובמקרים רבים לא יופיעו אילוצים כלל.
בעיות חיזוי
בבעיות חיזוי ננסה למצוא חזאי לערכו של משתנה/וקטור אקראי y \text{y} y x \mathbf{x} x
y ^ = h ( x ) \hat{y}=h(\boldsymbol{x}) y ^ = h ( x ) הערכת ביצועים
אנו נרצה לבחור את החזאי אשר ימעזר את פונקציית המחיר (cost) C ( h ) C(h) C ( h )
h ∗ = arg min h C ( h ) h^* = \underset{h}{\arg\min} C(h) h ∗ = h arg min C ( h ) מקרה פרטי של פונקציית מחיר הינה המקרה של פונקציית סיכון (risk) . פונקציית סיכון היא פונקציה מהצורה של:
R ( h ) = E [ l ( h ( x ) , y ) ] R(h)=\mathbb{E}\left[l(h(\mathbf{x}),\text{y})\right] R ( h ) = E [ l ( h ( x ) , y ) ] הפונקציה l l l פונקציית ההפסד (loss) .
פונקציות הפסד (פונקציות סיכון) נפוצות
Common For
Loss Name
Risk Name
Loss Function
Optimal Predictor
Classification
Zero-One Loss
Misclassification Rate
l ( y 1 , y 2 ) = I { y 1 ≠ y 2 } l\left(y_1,y_2\right)=I\left\lbrace y_1\neq y_2\right\rbrace l ( y 1 , y 2 ) = I { y 1 = y 2 } h ∗ ( x ) = arg max y p y ∣ x ( y ∣ x ) h^*\left(x\right)=\underset{y}{\arg\max}\ p_{\text{y}\mid\mathbf{x}}\left(y\mid x\right) h ∗ ( x ) = y arg max p y ∣ x ( y ∣ x )
Regression
L 1 L_1 L 1 Mean Absolute Error
l ( y 1 , y 2 ) = ∣ y 1 − y 2 ∣ l\left(y_1,y_2\right)=\left\vert y_1-y_2\right\vert l ( y 1 , y 2 ) = ∣ y 1 − y 2 ∣ Median: h ∗ ( x ) = y ^ h^*\left(x\right)=\hat{y} h ∗ ( x ) = y ^ s . t . F y ∣ x ( y ^ ∣ x ) = 0.5 s.t.\ F_{\text{y}\mid\mathbf{x}}\left(\hat{y}\mid x\right)=0.5 s . t . F y ∣ x ( y ^ ∣ x ) = 0 . 5
Regression
L 2 L_2 L 2 Mean Squared Error (MSE)
l ( y 1 , y 2 ) = ( y 1 − y 2 ) 2 l\left(y_1,y_2\right)=\left(y_1-y_2\right)^2 l ( y 1 , y 2 ) = ( y 1 − y 2 ) 2 h ∗ ( x ) = E [ y ∣ x ] h^*\left(x\right)=\mathbf{E}\left[\text{y}\mid\mathbf{x}\right] h ∗ ( x ) = E [ y ∣ x ]
Supervised learning
בעיות חיזוי בהם הפילוג של המשתנים לא ידוע אך יש בידינו מדגם: D = { x ( i ) , y ( i ) } i = 1 N \mathcal{D}=\{x^{(i)}, y^{(i)}\}_{i=1}^N D = { x ( i ) , y ( i ) } i = 1 N
סוגי supervised learning
בעיות סיווג (classification) : y \text{y} y בעיות רגרסיה (regression) : y \text{y} y
גישות לפתרון בעיות supervised learning
ניתן להבחין בין 3 גישות לפתרון בעיות supervised learning:
גישה דיסקרימינטיבית : D \mathcal{D} D h ( x ) h(\boldsymbol{x}) h ( x ) גישה גנרטיבית : D \mathcal{D} D p x , y ( x , y ) p_{\mathbf{x},\text{y}}(\boldsymbol{x},y) p x , y ( x , y ) p y ∣ x ( y ∣ x ) p_{\text{y}|\mathbf{x}}(y|\boldsymbol{x}) p y ∣ x ( y ∣ x ) h ( x ) h(\boldsymbol{x}) h ( x ) גישה דיסקרימינטיבית הסתברותית : D \mathcal{D} D p y ∣ x ( y ∣ x ) p_{\text{y}|\mathbf{x}}(y|\boldsymbol{x}) p y ∣ x ( y ∣ x ) h ( x ) h(\boldsymbol{x}) h ( x )
גישה דיסקרימינטיביות
Empirical Risk Minimization
שיטה אשר משתמשת במודל פרמטרי לפונקציית החיזוי, בה נחפש את הפרמטרים של המודל אשר ממזערים את הסיכון האמפירי (הסיכון שמשוערך על המדגם):
h ∗ = arg min h 1 N ∑ i = 0 N l ( h ( x ( i ) ; θ ) , y ( i ) ) h^* = \underset{h}{\arg\min} \frac{1}{N}\sum_{i=0}^Nl(h(\boldsymbol{x}^{(i)};\boldsymbol{\theta}),y^{(i)}) h ∗ = h arg min N 1 i = 0 ∑ N l ( h ( x ( i ) ; θ ) , y ( i ) ) כאשר המודל הפרמטרי יכול להיות כל מודל, לדוגמא, מודל לינארי או רשת נוירונים.
Linear Least Squares (LLS)
LLS הוא מקרה פרטי של ERM שבו המודל הפרמטרי הוא לינארי ופונקציית הסיכון היא MSE:
h ( x ; θ ) = x ⊤ θ h(\boldsymbol{x};\boldsymbol{\theta})=\boldsymbol{x}^{\top}\boldsymbol{\theta} h ( x ; θ ) = x ⊤ θ θ ∗ = arg min θ 1 N ∑ i ( θ ⊤ x ( i ) − y ( i ) ) 2 \boldsymbol{\theta}^*=\underset{\boldsymbol{\theta}}{\arg\min}\ \frac{1}{N}\sum_i (\boldsymbol{\theta}^{\top}\boldsymbol{x}^{(i)}-y^{(i)})^2 θ ∗ = θ arg min N 1 i ∑ ( θ ⊤ x ( i ) − y ( i ) ) 2 במקרה זה ישנו פתרון סגור אשר נתון על ידי:
θ = ( X ⊤ X ) − 1 X ⊤ y \boldsymbol{\theta}=(\boldsymbol{X}^{\top}\boldsymbol{X})^{-1}\boldsymbol{X}^{\top}\boldsymbol{y} θ = ( X ⊤ X ) − 1 X ⊤ y כאשר X \boldsymbol{X} X
X = ( x ( 1 ) , x ( 2 ) , … , x ( N ) ) ⊤ \boldsymbol{X}=(\boldsymbol{x}^{(1)},\boldsymbol{x}^{(2)},\dots,\boldsymbol{x}^{(N)})^{\top} X = ( x ( 1 ) , x ( 2 ) , … , x ( N ) ) ⊤ ו y \boldsymbol{y} y
y = ( y ( 1 ) , y ( 2 ) , … , y ( N ) ) ⊤ \boldsymbol{y}=(y^{(1)},y^{(2)},\dots,y^{(N)})^{\top} y = ( y ( 1 ) , y ( 2 ) , … , y ( N ) ) ⊤
Ridge Regression
בעיית LLS אשר מוסיפים לה איבר רגולריזציית L 2 L_2 L 2
θ ∗ = arg min θ 1 N ∑ i ( θ ⊤ x ( i ) − y ( i ) ) 2 + λ ∥ θ ∥ 2 2 \boldsymbol{\theta}^*=\underset{\boldsymbol{\theta}}{\arg\min}\ \frac{1}{N}\sum_i (\boldsymbol{\theta}^{\top}\boldsymbol{x}^{(i)}-y^{(i)})^2+\lambda\lVert\boldsymbol{\theta}\rVert_2^2 θ ∗ = θ arg min N 1 i ∑ ( θ ⊤ x ( i ) − y ( i ) ) 2 + λ ∥ θ ∥ 2 2 גם כאן יש פתרון סגור:
θ = ( X ⊤ X + N λ I ) − 1 X ⊤ y \boldsymbol{\theta}=(\boldsymbol{X}^{\top}\boldsymbol{X}+N\lambda \boldsymbol{I})^{-1}\boldsymbol{X}^{\top}\boldsymbol{y} θ = ( X ⊤ X + N λ I ) − 1 X ⊤ y Least Absolute Shrinkage and Selection Operator (LASSO)
בעיית LLS אשר מוסיפים לה איבר רגולריזציית L 1 L_1 L 1
θ ∗ = arg min θ 1 N ∑ i ( θ ⊤ x ( i ) − y ( i ) ) 2 + λ ∑ j ∣ θ j ∣ \boldsymbol{\theta}^*=\underset{\boldsymbol{\theta}}{\arg\min}\ \frac{1}{N}\sum_i (\boldsymbol{\theta}^{\top}\boldsymbol{x}^{(i)}-y^{(i)})^2+\lambda\sum_j\lvert\theta_j\rvert θ ∗ = θ arg min N 1 i ∑ ( θ ⊤ x ( i ) − y ( i ) ) 2 + λ j ∑ ∣ θ j ∣ אין פתרון סגור אך ניתן לפתרון באופן יעיל על ידי שיטות איטרטיביות כגון gradient descent.
K-NN (K-Nearest Neighbours)
K-NN הינו אלגוריתם דיסקרימינטיבי לפתרון בעיות סיווג. באלגוריתם זה החיזויים נעשים ישירות על פי המדגם באופן הבא:
בהינתן x \boldsymbol{x} x
נבחר את K K K x ( i ) \boldsymbol{x}^{(i)} x ( i ) x \boldsymbol{x} x
תוצאת החיזוי תהיה התווית השכיחה ביותר (majorety vote) מבין K K K
במקרה של שיוון:
במקרה של שיוויון בשלב 2, נשווה גם את המרחק הממוצע בין ה x \boldsymbol{x} x
במקרה של שיווון גם בין המרחקים הממוצעים, נבחר אקראית.
K-NN לבעיות רגרסיה
ניתן להשתמש באלגוריתם זה גם לפתרון בעיות רגרסיה אם כי פתרון זה יהיה לרוב פחות יעיל. בבעיות רגרסיה ניתן למצע על התוויות במקום לבחור את תווית השכיחה.
Decision Trees
עץ החלטה אשר ממפה כל x \boldsymbol{x} x
שיטה לבניית העץ הינה באופן חמדני אשר בכל שלב מוסיף את הפיצול הטוב ביותר תחת קריטריון מסויים.
נמספר את העלים של עץ נתון על ידי j = 1 , 2 , … j=1,2,\dots j = 1 , 2 , … j j j
שני קריטריונים נפוצים הינם:
אינדקס Gini:
Q j = ∑ y ∈ { 1 , … , C } p ^ j , y ( 1 − p ^ j , y ) Q_j=\sum_{y\in\{1,\dots,C\}}\hat{p}_{j,y}(1-\hat{p}_{j,y}) Q j = y ∈ { 1 , … , C } ∑ p ^ j , y ( 1 − p ^ j , y )
אנטרופיה:
Q j ( = H j ) = ∑ y ∈ { 1 , … , C } − p ^ j , y log 2 p ^ j , y Q_j(=H_j)=\sum_{y\in\{1,\dots,C\}}-\hat{p}_{j,y}\log_2 \hat{p}_{j,y} Q j ( = H j ) = y ∈ { 1 , … , C } ∑ − p ^ j , y log 2 p ^ j , y
בכל צעד נרצה לבחור את הפיצול אשר ממזער את הגודל:
Q total = ∑ j N j N Q j Q_{\text{total}}=\sum_j \frac{N_j}{N}Q_j Q total = j ∑ N N j Q j
SVM
Hard-SVM
בעיה פרימאלית
w ∗ , b ∗ = arg min w , b 1 2 ∥ w ∥ 2 s.t. y ( i ) ( w ⊤ x ( i ) + b ) ≥ 1 ∀ i \begin{aligned}
\boldsymbol{w}^*,b^*=
\underset{\boldsymbol{w},b}{\arg\min}\quad&\frac{1}{2}\left\lVert\boldsymbol{w}\right\rVert^2 \\
\text{s.t.}\quad&y^{(i)}\left(\boldsymbol{w}^{\top}\boldsymbol{x}^{(i)}+b\right)\geq1\quad\forall i
\end{aligned} w ∗ , b ∗ = w , b arg min s.t. 2 1 ∥ w ∥ 2 y ( i ) ( w ⊤ x ( i ) + b ) ≥ 1 ∀ i בעיה דואלית
{ α i } ∗ = arg max { α i } ∑ i α i − 1 2 ∑ i , j y ( i ) y ( j ) α i α j x ( i ) ⊤ x ( j ) s.t. α i ≥ 0 ∀ i ∑ i α i y ( i ) = 0 \begin{aligned}
\left\lbrace\alpha_i\right\rbrace^*=\\
\underset{\left\lbrace\alpha_i\right\rbrace}{\arg\max}\quad&\sum_i\alpha_i-\frac{1}{2}\sum_{i,j}y^{(i)}y^{(j)}\alpha_i\alpha_j\boldsymbol{x}^{(i)\top}\boldsymbol{x}^{(j)} \\
\text{s.t.}\quad
&\alpha_i\geq0\quad\forall i\\
&\sum_i\alpha_iy^{(i)}=0
\end{aligned} { α i } ∗ = { α i } arg max s.t. i ∑ α i − 2 1 i , j ∑ y ( i ) y ( j ) α i α j x ( i ) ⊤ x ( j ) α i ≥ 0 ∀ i i ∑ α i y ( i ) = 0 מתוך הפרמטרים α i \alpha_i α i w \boldsymbol{w} w
w = ∑ i α i y ( i ) x ( i ) \boldsymbol{w}=\sum_i\alpha_iy^{(i)}\boldsymbol{x}^{(i)} w = i ∑ α i y ( i ) x ( i ) את b b b
תכונות
.
.
.
נקודות רחוקותמה margin
y ( i ) ( w ⊤ x ( i ) + b ) > 1 y^{(i)}\left(\boldsymbol{w}^{\top}x^{(i)}+b\right)>1 y ( i ) ( w ⊤ x ( i ) + b ) > 1 α i = 0 \alpha_i=0 α i = 0
נקודות על ה margin(support vectors)
y ( i ) ( w ⊤ x ( i ) + b ) = 1 y^{(i)}\left(\boldsymbol{w}^{\top}x^{(i)}+b\right)=1 y ( i ) ( w ⊤ x ( i ) + b ) = 1 α i ≥ 0 \alpha_i\geq0 α i ≥ 0
Soft SVM
בעיה פרימאלית
w ∗ , b ∗ , { ξ i } ∗ = arg min w , b , { ξ i } 1 2 ∥ w ∥ 2 + C ∑ i = 1 N ξ i s.t. y ( i ) ( w ⊤ x ( i ) + b ) ≥ 1 − ξ i ∀ i ξ i ≥ 0 ∀ i \begin{aligned}
\boldsymbol{w}^*,b^*,\{\xi_i\}^*=\\
\underset{\boldsymbol{w},b,\{\xi_i\}}{\arg\min}\quad&\frac{1}{2}\left\lVert\boldsymbol{w}\right\rVert^2+C\sum_{i=1}^N\xi_i \\
\text{s.t.}\quad
&y^{(i)}\left(\boldsymbol{w}^{\top}\boldsymbol{x}^{(i)}+b\right)\geq1-\xi_i\quad\forall i\\
&\xi_i\geq0\quad\forall i
\end{aligned} w ∗ , b ∗ , { ξ i } ∗ = w , b , { ξ i } arg min s.t. 2 1 ∥ w ∥ 2 + C i = 1 ∑ N ξ i y ( i ) ( w ⊤ x ( i ) + b ) ≥ 1 − ξ i ∀ i ξ i ≥ 0 ∀ i בעיה דואלית
{ α i } ∗ = arg max { α i } ∑ i α i − 1 2 ∑ i , j y ( i ) y ( j ) α i α j x ( i ) ⊤ x ( j ) s.t. 0 ≤ α i ≤ C ∀ i ∑ i α i y ( i ) = 0 \begin{aligned}
\left\lbrace\alpha_i\right\rbrace^*=\\
\underset{\left\lbrace\alpha_i\right\rbrace}{\arg\max}\quad&\sum_i\alpha_i-\frac{1}{2}\sum_{i,j}y^{(i)}y^{(j)}\alpha_i\alpha_j\boldsymbol{x}^{(i)\top}\boldsymbol{x}^{(j)} \\
\text{s.t.}\quad
&0\leq\alpha_i\leq C\quad\forall i\\
&\sum_i\alpha_iy^{(i)}=0
\end{aligned} { α i } ∗ = { α i } arg max s.t. i ∑ α i − 2 1 i , j ∑ y ( i ) y ( j ) α i α j x ( i ) ⊤ x ( j ) 0 ≤ α i ≤ C ∀ i i ∑ α i y ( i ) = 0 תכונות
.
.
.
נקודות שמסווגות נכוןורחוקות מה margin
y ( i ) ( w ⊤ x ( i ) + b ) > 1 y^{(i)}\left(\boldsymbol{w}^{\top}x^{(i)}+b\right)>1 y ( i ) ( w ⊤ x ( i ) + b ) > 1 α i = 0 \alpha_i=0 α i = 0
נקודות על ה margin(support vectors)
y ( i ) ( w ⊤ x ( i ) + b ) = 1 y^{(i)}\left(\boldsymbol{w}^{\top}x^{(i)}+b\right)=1 y ( i ) ( w ⊤ x ( i ) + b ) = 1 0 ≤ α i ≤ C 0\leq\alpha_i\leq C 0 ≤ α i ≤ C
נקודות שחורגותמה margin(גם support vectors)
y ( i ) ( w ⊤ x ( i ) + b ) = 1 − ξ i y^{(i)}\left(\boldsymbol{w}^{\top}x^{(i)}+b\right)=1-\xi_i y ( i ) ( w ⊤ x ( i ) + b ) = 1 − ξ i α i = C \alpha_i=C α i = C
גישה גנרטיבית
שיטות לא פרמטריות
היסטוגרמה
מחלקים את תחום הערכים ש x \mathbf{x} x
לכל תא משערכים את ההסתברות של המאורע ש x \mathbf{x} x
הערך של פונקציית הצפיפות בכל תא תהיה ההסתברות המשוערכת להיות בתא חלקי גודל התא.
נרשום זאת בעבור המקרה של משתנה אקראי סקלרי. נסמן ב B B B l b l_b l b r b r_b r b b b b
p ^ x , D ( x ) = { 1 size of bin 1 p ^ { x in bin 1 } , D x in bin 1 ⋮ 1 size of bin B p ^ { x in bin B } , D x in bin B = { 1 N ( r 1 − l 1 ) ∑ i = 1 N I { l 1 ≤ x ( i ) < r 1 } l 1 ≤ x < r 1 ⋮ 1 N ( r B − l B ) ∑ i = 1 N I { l B ≤ x ( i ) < r B } l B ≤ x < r B \begin{aligned}
\hat{p}_{\text{x},\mathcal{D}}(x)
&=\begin{cases}
\frac{1}{\text{size of bin }1}\hat{p}_{\{\text{x in bin }1\},\mathcal{D}}&\text{x in bin }1\\
\vdots\\
\frac{1}{\text{size of bin }B}\hat{p}_{\{\text{x in bin }B\},\mathcal{D}}&\text{x in bin }B
\end{cases}\\
&=\begin{cases}
\frac{1}{N(r_1-l_1)}\sum_{i=1}^N I\{l_1\leq x^{(i)}<r_1\}&l_1\leq x<r_1\\
\vdots\\
\frac{1}{N(r_B-l_B)}\sum_{i=1}^N I\{l_B\leq x^{(i)}<r_B\}&l_B\leq x<r_B\\
\end{cases}
\end{aligned} p ^ x , D ( x ) = ⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ size of bin 1 1 p ^ { x in bin 1 } , D ⋮ size of bin B 1 p ^ { x in bin B } , D x in bin 1 x in bin B = ⎩ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎧ N ( r 1 − l 1 ) 1 ∑ i = 1 N I { l 1 ≤ x ( i ) < r 1 } ⋮ N ( r B − l B ) 1 ∑ i = 1 N I { l B ≤ x ( i ) < r B } l 1 ≤ x < r 1 l B ≤ x < r B הערות:
בחירת התאים משפיעה באופן משמעותי על תוצאת השערוך של ה PDF.
כלל אצבע: לחלק את טווח הערכים ל-N \sqrt{N} N
Kernel Density Estimation (KDE)
p ^ x , ϕ , D ( x ) = 1 N ∑ i = 1 N ϕ ( x − x ( i ) ) \hat{p}_{\mathbf{x},\phi,\mathcal{D}}(\boldsymbol{x})=\frac{1}{N}\sum_{i=1}^N \phi(\boldsymbol{x}-\boldsymbol{x}^{(i)}) p ^ x , ϕ , D ( x ) = N 1 i = 1 ∑ N ϕ ( x − x ( i ) ) כאשר ϕ ( x ) \phi(\boldsymbol{x}) ϕ ( x ) פונקציית גרעין (kernel ) או Parzan window . פונקציות גרעין נפוצות הינן:
חלון מרובע:
ϕ h ( x ) = 1 h D I { ∣ x j ∣ ≤ h 2 ∀ j } \phi_h(\boldsymbol{x})=\frac{1}{h^D}I\{|x_j|\leq \tfrac{h}{2}\quad\forall j\} ϕ h ( x ) = h D 1 I { ∣ x j ∣ ≤ 2 h ∀ j }
גאוסיאן:
ϕ σ ( x ) = 1 2 π σ D exp ( − ∥ x ∥ 2 2 2 σ 2 ) \phi_{\sigma}\left(x\right)=\frac{1}{\sqrt{2\pi}\sigma^D}\exp\left(-\frac{\lVert x\rVert_2^2}{2\sigma^2}\right) ϕ σ ( x ) = 2 π σ D 1 exp ( − 2 σ 2 ∥ x ∥ 2 2 )
כאשר h h h σ \sigma σ
כלל אצבע לבחירת רוחב הגרעין במקרה הגאוסי הסקלרי הינו σ = ( 4 ⋅ std ( x ) 5 3 N ) 1 5 ≈ 1.06 std ( x ) N − 1 5 \sigma=\left(\frac{4\cdot\text{std}(\text{x})^5}{3N}\right)^\frac{1}{5}\approx1.06\ \text{std}(\text{x})N^{-\tfrac{1}{5}} σ = ( 3 N 4 ⋅ std ( x ) 5 ) 5 1 ≈ 1 . 0 6 std ( x ) N − 5 1 std ( x ) \text{std}(\text{x}) std ( x ) x \text{x} x
שיטות פרמטריות
בשיטה הפרמטרית נציע מודל פרמטרי לפילוג המושתף של x \mathbf{x} x y \text{y} y
MLE
θ ^ MLE = arg max θ L ( θ ; D ) = arg min θ − ∑ i log ( p x , y ( x ( i ) , y ( i ) ; θ ) ) \hat{\boldsymbol{\theta}}_{\text{MLE}}
=\underset{\boldsymbol{\theta}}{\arg\max}\ \mathcal{L}(\boldsymbol{\theta};\mathcal{D})
=\underset{\boldsymbol{\theta}}{\arg\min}\ -\sum_i \log\left(p_{\mathbf{x},\text{y}}(\boldsymbol{x}^{(i)},y^{(i)};\boldsymbol{\theta})\right) θ ^ MLE = θ arg max L ( θ ; D ) = θ arg min − i ∑ log ( p x , y ( x ( i ) , y ( i ) ; θ ) ) לרוב נוח לנסות לבנו את המודל כמכפלה של שני פונקציות.
p x , y ( x , y ) = p x ∣ y ( x ∣ y ) p y ( y ) p_{\mathbf{x},\text{y}}(\boldsymbol{x},y)
=p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|y)p_{\text{y}}(y) p x , y ( x , y ) = p x ∣ y ( x ∣ y ) p y ( y ) MAP
θ ^ MAP = arg max θ p θ ∣ D ( θ ∣ D ) = arg min θ − log ( p θ ( θ ) ) − ∑ i log ( p x , y ∣ θ ( x ( i ) , y ( i ) ∣ θ ) ) \hat{\boldsymbol{\theta}}_{\text{MAP}}
=\underset{\boldsymbol{\theta}}{\arg\max}\ p_{\boldsymbol{\theta}|\mathcal{D}}(\boldsymbol{\theta}|\mathcal{D})
=\underset{\boldsymbol{\theta}}{\arg\min}\ -\log\left(p_{\boldsymbol{\theta}}(\boldsymbol{\theta})\right)-\sum_i \log\left(p_{\mathbf{x},\text{y}|\boldsymbol{\theta}}(\boldsymbol{x}^{(i)},y^{(i)}|\boldsymbol{\theta})\right) θ ^ MAP = θ arg max p θ ∣ D ( θ ∣ D ) = θ arg min − log ( p θ ( θ ) ) − i ∑ log ( p x , y ∣ θ ( x ( i ) , y ( i ) ∣ θ ) )
Linear Discriminant Analysis (LDA)
LDA משתמש במודל הבא + MLE:
p x ∣ y ( x ∣ y ) = 1 ( 2 π ) d ∣ Σ ∣ e − 1 2 ( x − μ y ) T Σ − 1 ( x − μ y ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|y)=\frac{1}{\sqrt{(2\pi)^d|\Sigma|}}e^{-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}_y\right)^T\Sigma^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}_y\right)} p x ∣ y ( x ∣ y ) = ( 2 π ) d ∣ Σ ∣ 1 e − 2 1 ( x − μ y ) T Σ − 1 ( x − μ y ) לפרמטרים של המודל יש פתרון סגור. נשתמש בסימונים:
I c = { i : y ( i ) = c } \mathcal{I}_c=\{i:\ y^{(i)}=c\} I c = { i : y ( i ) = c } y ( i ) = c y^{(i)}=c y ( i ) = c ∣ I c ∣ |\mathcal{I}_c| ∣ I c ∣ I c \mathcal{I}_c I c μ c \mu_c μ c p x ∣ y ( x ∣ c ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|c) p x ∣ y ( x ∣ c )
μ c = 1 ∣ I c ∣ ∑ i ∈ I c x ( i ) \boldsymbol{\mu}_c = \frac{1}{|\mathcal{I}_c|}\sum_{i\in \mathcal{I}_c}\boldsymbol{x}^{(i)} μ c = ∣ I c ∣ 1 i ∈ I c ∑ x ( i ) Σ = 1 N ∑ i ( x ( i ) − μ y ( i ) ) ( x ( i ) − μ y ( i ) ) T \Sigma = \frac{1}{N}\sum_{i}\left(\boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{y^{(i)}}\right)\left(\boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{y^{(i)}}\right)^T Σ = N 1 i ∑ ( x ( i ) − μ y ( i ) ) ( x ( i ) − μ y ( i ) ) T את הפילוג של p y p_{\text{y}} p y y \text{y} y
במקרה של misclassification rate בינארי, המשערך נתון על ידי:
h ( x ) = { 1 a T x + b > 0 0 otherwise h\left(x\right)=
\begin{cases}
1\qquad \boldsymbol{a}^T \boldsymbol{x} + b > 0 \\
0\qquad \text{otherwise}\\
\end{cases} h ( x ) = { 1 a T x + b > 0 0 otherwise כאשר:
a = Σ − 1 ( μ 1 − μ 0 ) \boldsymbol{a}=\Sigma^{-1}\left(\boldsymbol{\mu}_1-\boldsymbol{\mu}_0\right) a = Σ − 1 ( μ 1 − μ 0 ) b = 1 2 ( μ 0 T Σ − 1 μ 0 − μ 1 T Σ − 1 μ 1 ) + log ( p y ( 1 ) p y ( 0 ) ) b=\tfrac{1}{2}\left(\boldsymbol{\mu}_0^T\Sigma^{-1}\boldsymbol{\mu}_0 - \boldsymbol{\mu}_1^T\Sigma^{-1}\boldsymbol{\mu}_1\right) + \log\left(\frac{p_\text{y}\left(1\right)}{p_\text{y}\left(0\right)}\right) b = 2 1 ( μ 0 T Σ − 1 μ 0 − μ 1 T Σ − 1 μ 1 ) + log ( p y ( 0 ) p y ( 1 ) )
Quadric Discriminant Analysis (QDA)
QDA דומה ל LDA רק שכאן ישנה מטריצה Σ c \Sigma_c Σ c
p x ∣ y ( x ∣ y ) = 1 ( 2 π ) d ∣ Σ y ∣ e − 1 2 ( x − μ y ) T Σ y − 1 ( x − μ y ) p_{\mathbf{x}|\text{y}}(\boldsymbol{x}|y)=\frac{1}{\sqrt{(2\pi)^d|\Sigma_y|}}e^{-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}_y\right)^T\Sigma_y^{-1}\left(\boldsymbol{x}-\boldsymbol{\mu}_y\right)} p x ∣ y ( x ∣ y ) = ( 2 π ) d ∣ Σ y ∣ 1 e − 2 1 ( x − μ y ) T Σ y − 1 ( x − μ y ) הפרמטר Σ c \Sigma_c Σ c
Σ c = 1 ∣ I c ∣ ∑ i ∈ I c ( x ( i ) − μ y ( i ) ) ( x ( i ) − μ y ( i ) ) T \Sigma_c = \frac{1}{|\mathcal{I}_c|}\sum_{i\in \mathcal{I}_c}\left(\boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{y^{(i)}}\right)\left(\boldsymbol{x}^{(i)}-\boldsymbol{\mu}_{y^{(i)}}\right)^T Σ c = ∣ I c ∣ 1 i ∈ I c ∑ ( x ( i ) − μ y ( i ) ) ( x ( i ) − μ y ( i ) ) T במקרה של misclassification rate בינארי, המשערך נתון על ידי:
h ( x ) = { 1 x T C x + a T x + b > 0 0 otherwise h\left(x\right)
=\begin{cases}
1\qquad \boldsymbol{x}^T C \boldsymbol{x} + \boldsymbol{a}^T \boldsymbol{x} + b > 0 \\
0\qquad \text{otherwise}\\
\end{cases} h ( x ) = { 1 x T C x + a T x + b > 0 0 otherwise כאשר:
C = 1 2 ( Σ 0 − 1 − Σ 1 − 1 ) C=\frac{1}{2}(\Sigma^{-1}_0-\Sigma^{-1}_1) C = 2 1 ( Σ 0 − 1 − Σ 1 − 1 ) a = Σ 1 − 1 μ 1 − Σ 0 − 1 μ 0 \boldsymbol{a}=\Sigma^{-1}_1\boldsymbol{\mu}_1-\Sigma^{-1}_0\boldsymbol{\mu}_0 a = Σ 1 − 1 μ 1 − Σ 0 − 1 μ 0 b = 1 2 ( μ 0 T Σ 0 − 1 μ 0 − μ 1 T Σ 1 − 1 μ 1 ) + log ( ∣ Σ 0 ∣ p y ( 1 ) ∣ Σ 1 ∣ p y ( 0 ) ) b=\tfrac{1}{2}\left(\boldsymbol{\mu}_0^T\Sigma_0^{-1}\boldsymbol{\mu}_0 - \boldsymbol{\mu}_1^T\Sigma_1^{-1}\boldsymbol{\mu}_1\right) + \log\left(\frac{\sqrt{|\Sigma_0|}p_\text{y}(1)}{\sqrt{|\Sigma_1|}p_\text{y}(0)}\right) b = 2 1 ( μ 0 T Σ 0 − 1 μ 0 − μ 1 T Σ 1 − 1 μ 1 ) + log ( ∣ Σ 1 ∣ p y ( 0 ) ∣ Σ 0 ∣ p y ( 1 ) )
גישה דיסקרימינטיבית הסתברותית
Logistic Regression
p y ∣ x ( y ∣ x ) = softmax ( F ( x ; θ ) ) y = e f y ( x ; θ y ) ∑ c e f c ( x ; θ c ) p_{\text{y}|\mathbf{x}}(y|\boldsymbol{x})=\text{softmax}(F(\boldsymbol{x};\boldsymbol{\theta}))_y=\frac{e^{f_y(\boldsymbol{x};\boldsymbol{\theta}_y)}}{\sum_c e^{f_c(\boldsymbol{x};\boldsymbol{\theta}_c)}} p y ∣ x ( y ∣ x ) = softmax ( F ( x ; θ ) ) y = ∑ c e f c ( x ; θ c ) e f y ( x ; θ y ) כאשר F F F C C C F ( x ; θ ) = ( f 1 ( x ; θ 1 ) , f 2 ( x ; θ 2 ) , … , f C ( x ; θ C ) ) ⊤ F(\boldsymbol{x};\boldsymbol{\theta})=(f_1(\boldsymbol{x};\boldsymbol{\theta}_1),f_2(\boldsymbol{x};\boldsymbol{\theta}_2),\dots,f_C(\boldsymbol{x};\boldsymbol{\theta}_C))^{\top} F ( x ; θ ) = ( f 1 ( x ; θ 1 ) , f 2 ( x ; θ 2 ) , … , f C ( x ; θ C ) ) ⊤
את הפרמטרים מוצאים בעזרת MLE ו gradient descent.
המקרה הבינארי
במקרה הבנארי ניתן להשתמש במודל:
p y ∣ x ( 1 ∣ x ) = σ ( f ( x ; θ ) ) p y ∣ x ( 0 ∣ x ) = 1 − σ ( f ( x ; θ ) ) \begin{aligned}
p_{\text{y}|\mathbf{x}}(1|\boldsymbol{x})&=\sigma(f(\boldsymbol{x};\boldsymbol{\theta}))\\
p_{\text{y}|\mathbf{x}}(0|\boldsymbol{x})&=1-\sigma(f(\boldsymbol{x};\boldsymbol{\theta}))
\end{aligned} p y ∣ x ( 1 ∣ x ) p y ∣ x ( 0 ∣ x ) = σ ( f ( x ; θ ) ) = 1 − σ ( f ( x ; θ ) ) כאשר σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ ( x ) = 1 + e − x 1
תכונת של סיגמואיד ו softmax
σ ( − z ) = 1 − σ ( z ) \sigma(-z)=1-\sigma(z) σ ( − z ) = 1 − σ ( z ) ∂ ∂ z log ( σ ( z ) ) = 1 − σ ( z ) \frac{\partial}{\partial z}\log(\sigma(z))=1-\sigma(z) ∂ z ∂ log ( σ ( z ) ) = 1 − σ ( z ) ∂ ∂ z j log ( softmax ( z ) ) i = δ i , j ⏟ = I { i = j } − softmax ( z ) j \frac{\partial}{\partial z_j} \log(\text{softmax}(\boldsymbol{z}))_i=\underbrace{\delta_{i,j}}_{=I\{i=j\}}-\text{softmax}(\boldsymbol{z})_j ∂ z j ∂ log ( softmax ( z ) ) i = = I { i = j } δ i , j − softmax ( z ) j
Gradient Descent
בעבור בעיית המינמיזציה:
arg min θ g ( θ ) \underset{\boldsymbol{\theta}}{\arg\min}\quad g(\boldsymbol{\theta}) θ arg min g ( θ )
Bagging
מקטין את ה variance לרוב בלי לפגוע הרבה ב bias.
נייצר p p p
בעבור כל מדגם חדש נבנה חזאי.
החזאי הכולל יהיה קומבינציה/בחירת הרוב של כל החזאים שבנינו:
בעבור רגרסיה : : h ( x ) = 1 p ∑ i = 1 p h ~ i ( x ) h(\boldsymbol{x})=\frac{1}{p}\sum_{i=1}^p \tilde{h}_i(\boldsymbol{x}) h ( x ) = p 1 ∑ i = 1 p h ~ i ( x ) בעבור סיווג : : h ( x ) = majority ( { h ~ 1 ( x ) , h ~ 2 ( x ) , … , h ~ p ( x ) } ) h(\boldsymbol{x})=\text{majority}(\{\tilde{h}_1(\boldsymbol{x}),\tilde{h}_2(\boldsymbol{x}),\dots,\tilde{h}_p(\boldsymbol{x})\}) h ( x ) = majority ( { h ~ 1 ( x ) , h ~ 2 ( x ) , … , h ~ p ( x ) } )
AdaBoost
בעבור סיווג בינארי מקטין את ה bias, לרוב ללא פגיעה גדולה ב variance.
אלגוריתם
ב t = 0 t=0 t = 0 w i ( t ) = 1 N w_i^{(t)}=\frac{1}{N} w i ( t ) = N 1 t t t
נבחר את המסווג אשר ממזער את ה misclassification rate הממושקל:
h ~ t = arg min h ~ ∑ i = 1 N w i ( t − 1 ) I { y ( i ) ≠ h ~ ( x ( i ) ) } \tilde{h}_t=\underset{\tilde{h}}{\arg\min}\ \sum_{i=1}^N w_i^{(t-1)}I\{y^{(i)}\neq \tilde{h}(\boldsymbol{x}^{(i)})\} h ~ t = h ~ arg min i = 1 ∑ N w i ( t − 1 ) I { y ( i ) = h ~ ( x ( i ) ) }
נחשב את המקדם α t + 1 \alpha_{t+1} α t + 1
ε t = ∑ i = 1 N w i ( t − 1 ) I { y ( i ) ≠ h ~ t ( x ( i ) ) } α t = 1 2 ln ( 1 − ε t ε t ) \begin{aligned}
\varepsilon_t&=\sum_{i=1}^N w_i^{(t-1)}I\{y^{(i)}\neq \tilde{h}_t(\boldsymbol{x}^{(i)})\}\\
\alpha_t&=\frac{1}{2}\ln\left(\frac{1-\varepsilon_t}{\varepsilon_t}\right)
\end{aligned} ε t α t = i = 1 ∑ N w i ( t − 1 ) I { y ( i ) = h ~ t ( x ( i ) ) } = 2 1 ln ( ε t 1 − ε t )
נעדכן את וקטור המשקלים:
w ~ i ( t ) = w i ( t − 1 ) exp ( − α t y ( i ) h ~ t ( x ( i ) ) ) w i ( t ) = w ~ i ( t ) ∑ j = 1 N w ~ j ( t ) \begin{aligned}
\tilde{w}_i^{(t)}&=w_i^{(t-1)}\exp\left(-\alpha_t y^{(i)}\tilde{h}_t(\boldsymbol{x}^{(i)})\right)\\
w_i^{(t)}&=\frac{\tilde{w}_i^{(t)}}{\sum_{j=1}^N \tilde{w}_j^{(t)}}
\end{aligned} w ~ i ( t ) w i ( t ) = w i ( t − 1 ) exp ( − α t y ( i ) h ~ t ( x ( i ) ) ) = ∑ j = 1 N w ~ j ( t ) w ~ i ( t )
המסווג הסופי
הסיווג הסופי נעשה על ידי קומבינציה לינארית של כל מסווגים והמשקל שלהם.
h ( x ) = sign ( ∑ t = 1 T α t h ~ t ( x ) ) h(\boldsymbol{x})=\text{sign}\left(\sum_{t=1}^T\alpha_t \tilde{h}_t(\boldsymbol{x})\right) h ( x ) = sign ( t = 1 ∑ T α t h ~ t ( x ) ) חסם
ניתן להראות שאם מתקיים שבכל צעד שגיאת ה misclassification error הממושקלת קטנה מ 1 2 − γ t \tfrac{1}{2}-\gamma_t 2 1 − γ t
1 N ∑ i I { h ( x ( i ) ) ≠ y ( i ) } ≤ 1 N ∑ i = 1 N exp ( − ∑ t = 1 T α t y ( i ) h ~ t ( x ( i ) ) ) ≤ exp ( − 2 ∑ t = 1 T γ t 2 ) \frac{1}{N}\sum_i I\{h(\boldsymbol{x}^{(i)})\neq y^{(i)}\}
\leq
\frac{1}{N}\sum_{i=1}^N\exp\left(-\sum_{t=1}^T\alpha_t y^{(i)}\tilde{h}_t(\boldsymbol{x}^{(i)})\right)
\leq
\exp\left(-2\sum_{t=1}^T\gamma_t^2\right) N 1 i ∑ I { h ( x ( i ) ) = y ( i ) } ≤ N 1 i = 1 ∑ N exp ( − t = 1 ∑ T α t y ( i ) h ~ t ( x ( i ) ) ) ≤ exp ( − 2 t = 1 ∑ T γ t 2 )
רשתות נוירונים
שיטה לבניית מודלים פרמטריים בעלי יכולת ייצוג גבוה בהשראת רשתות נוירונים ביוליגיות. רשתות נוירונים מתקבלות על ידי שירשור של מספר נוירונים כאשר כל נוירון מבצע פעולה מטמתית פשוטה.
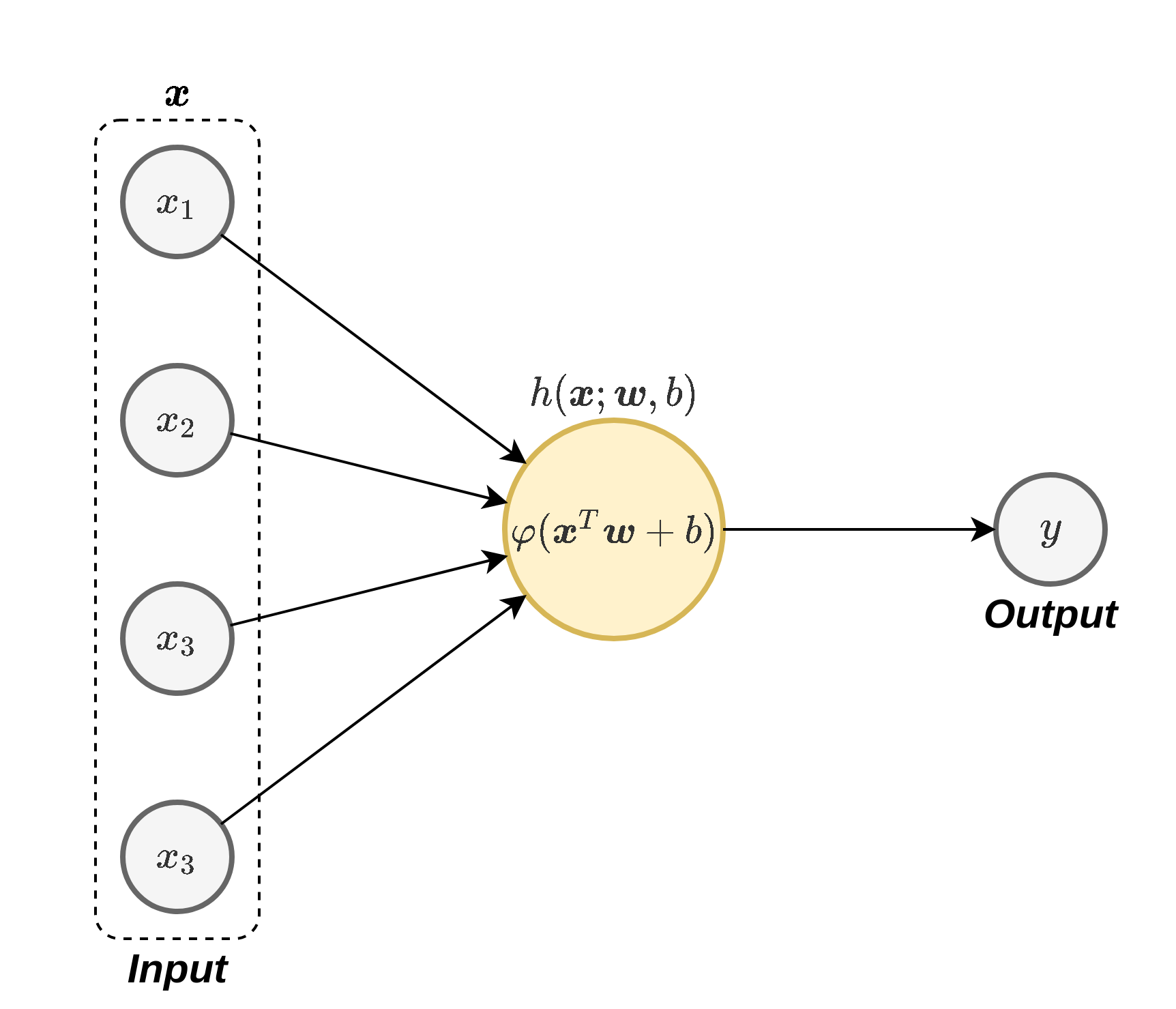
נוריון בודד
:כל נוירון ברשת מבצע את הפעולה הבאה
כאשר w \boldsymbol{w} w b b b φ ( ⋅ ) \varphi(\cdot) φ ( ⋅ ) פונקציית ההפעלה (activation function) . בחירות נפוצות של פונקציית ההפעלה כוללות את
הפונקציה הלוגיסטית (סיגמואיד): φ ( x ) = σ ( x ) = 1 1 + e − x \varphi(x)=\sigma(x)=\frac{1}{1+e^{-x}} φ ( x ) = σ ( x ) = 1 + e − x 1
טנגנס היפרבולי: φ ( x ) = tanh ( x / 2 ) \varphi(x)=\tanh\left(x/2\right) φ ( x ) = tanh ( x / 2 )
פונקציית ה ReLU (Rectified Linear Unit): אשר מוגדרת φ ( x ) = max ( x , 0 ) \varphi(x)=\max(x,0) φ ( x ) = max ( x , 0 )
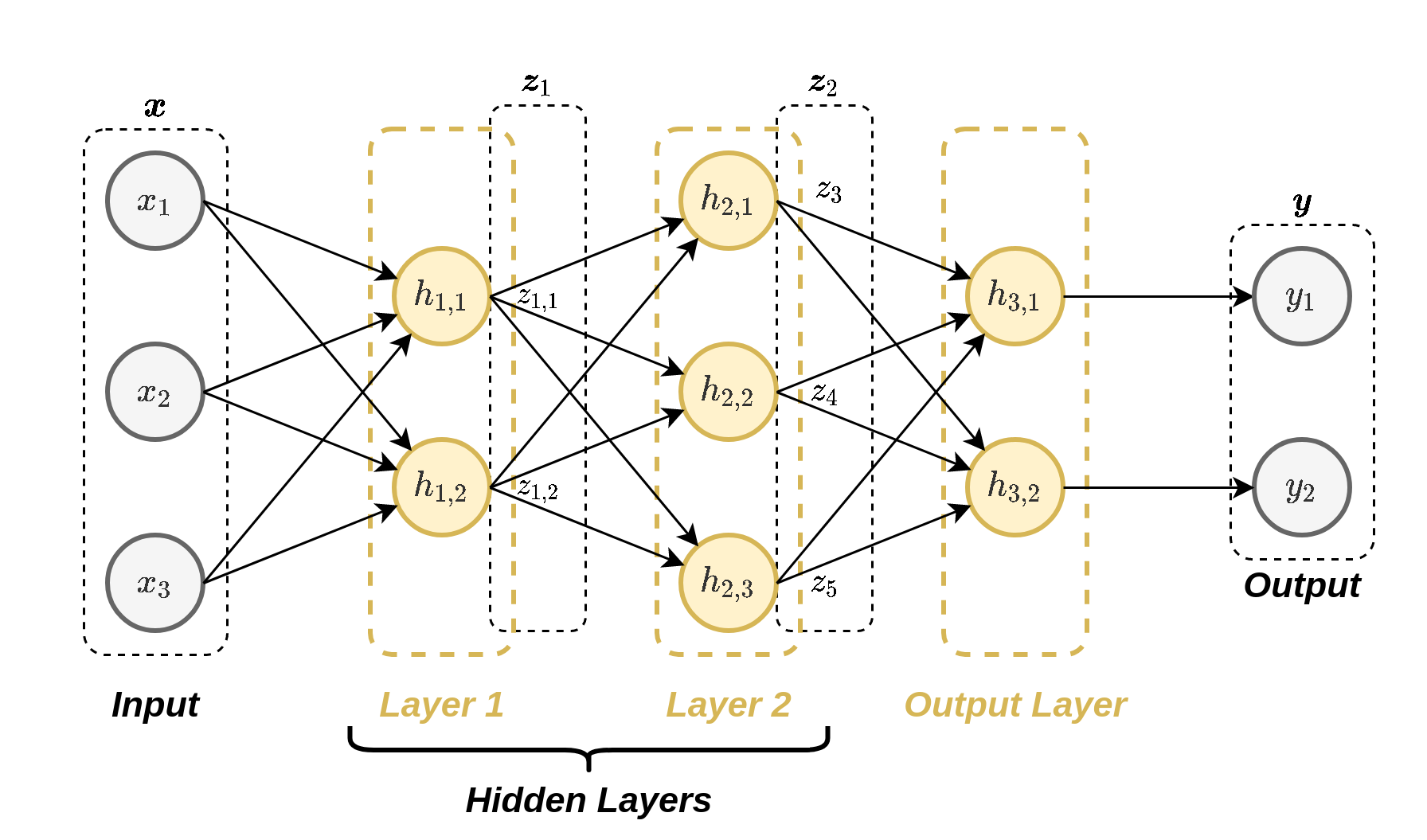
רשתות נוירונים
מושגים:
ארכיטקטורה : המבנה של הרשת (האופן בו הנוירונים מחוברים)יחידות נסתרות (hidden units ): הנוירונים אשר אינם מחוברים למוצא הרשת (אינם נמצאים בסוף הרשת).רשת עמוקה (deep network ): רשת אשר מכילה מסלולים מהכניסה למוצא אשר עוברים דרך יותר מיחידה נסתרת אחת.
Multi-Layer Perceptron (MLP)
רשת שבה:
הנוירונים מסודרים בשתייים או יותר שכבות (layers).
השכבות הם Fully Connected (FC) layers (כל נוירון מוזן מכל הנוריונים שבשכבה שלפניו).
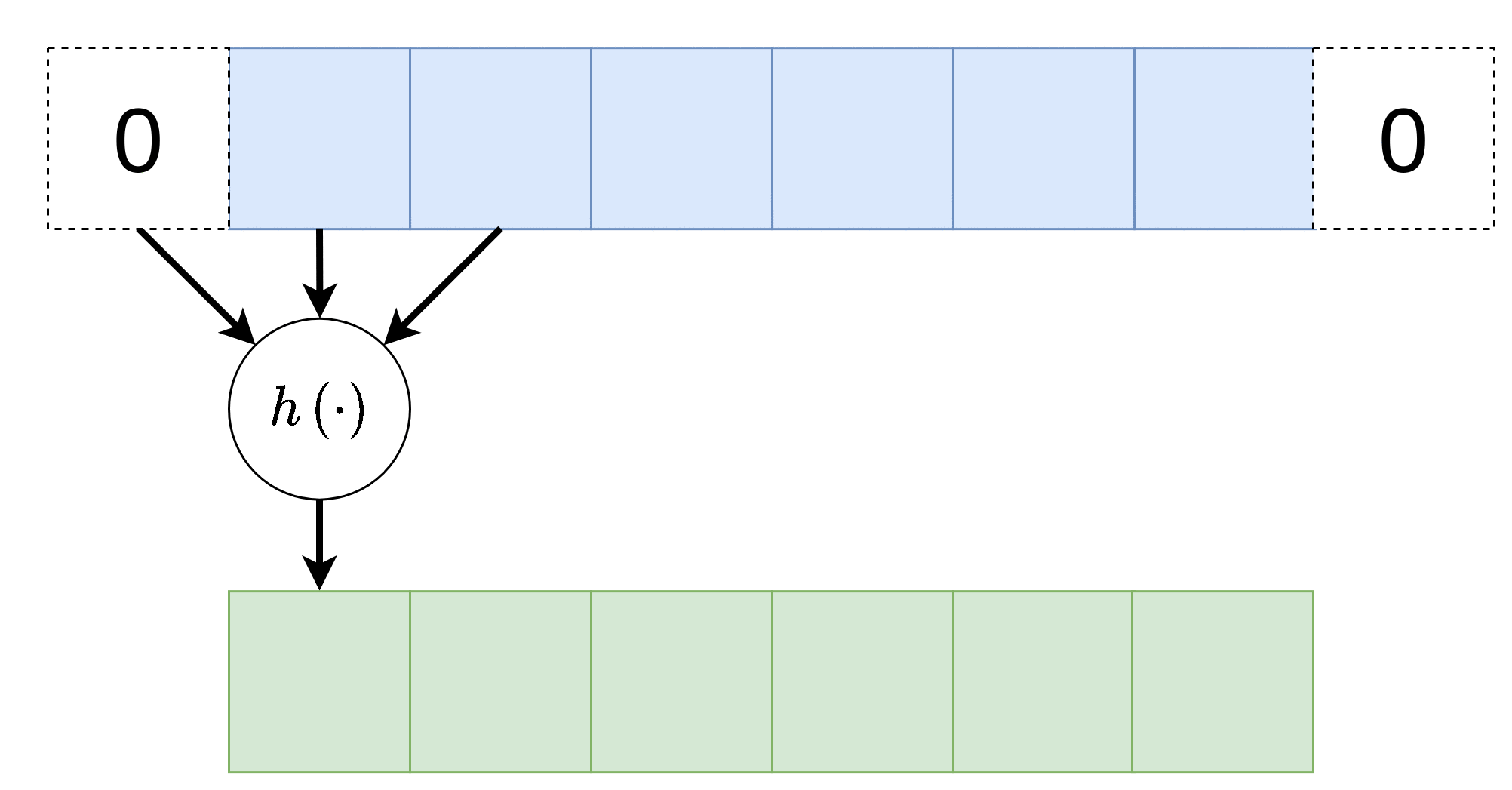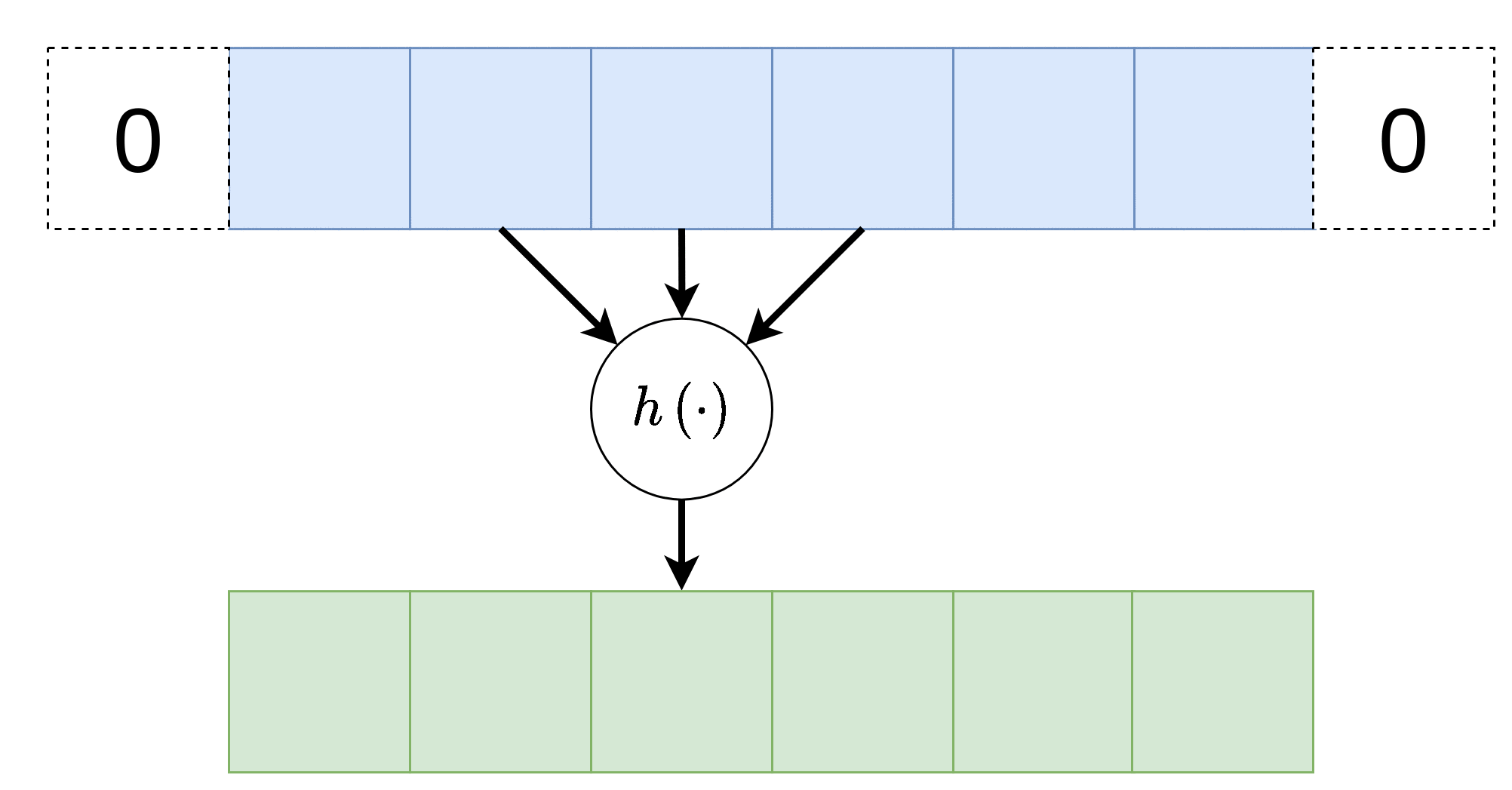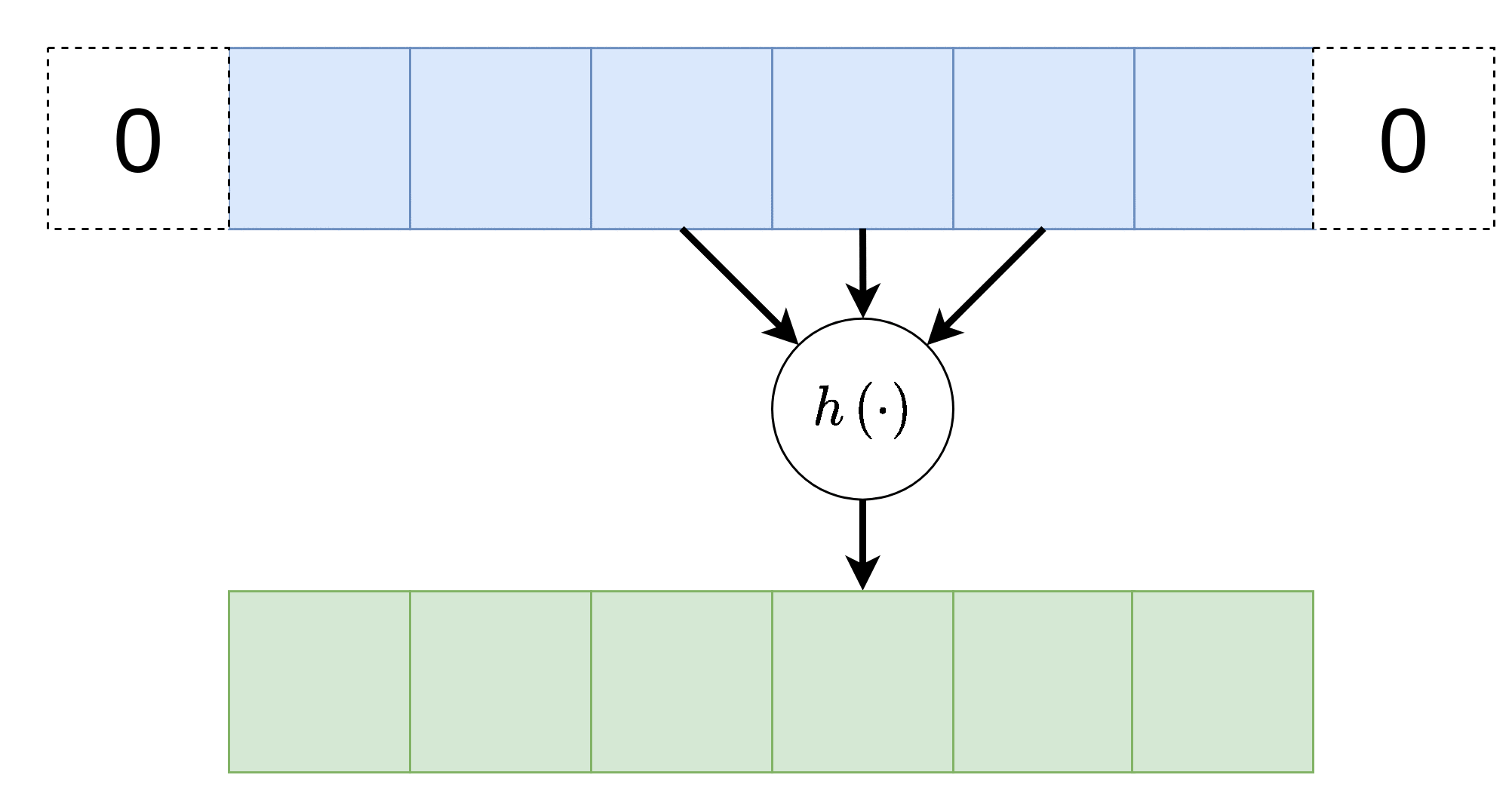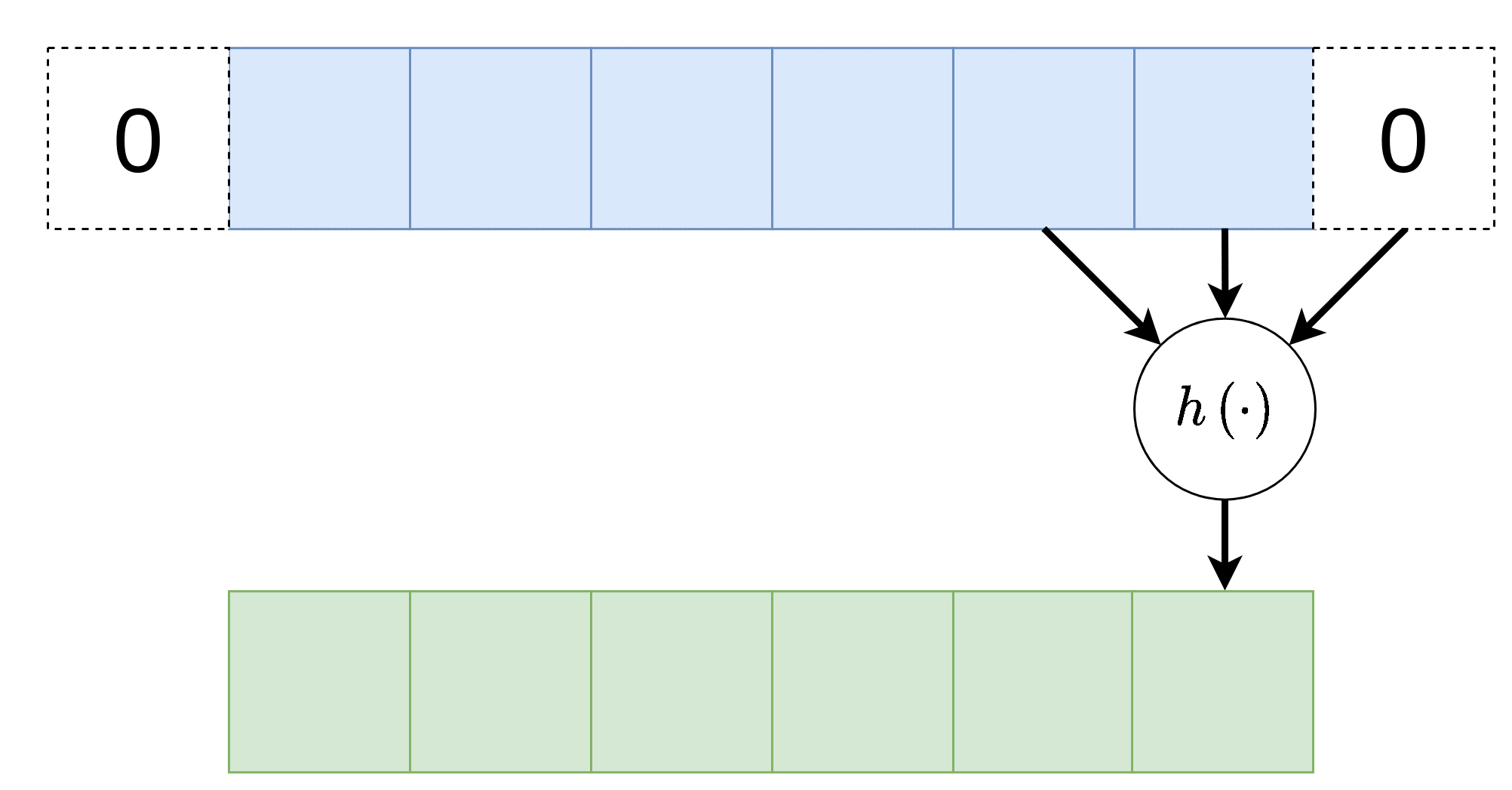
Convolutional Neural Network (CNN)
רשתות אשר מכילות שכבות קונבולוציה. שכבת קונבולוציה נבדלת משכבת FC בשני מובנים:
כל נוירון בשכבה זו מוזן רק מכמות מוגבלת של ערכים הנמצאים בסביבתו הקרובה.
כל הנוירונים בשכבה מסויימת זהים, זאת אומרת שהם משתמשים באותם הפרמטרים (תכונה המכונה weight sharing ).
וקטור המשקלים אשר מכפיל את הערכים בכניסה לנוירונים בשכבת הקונבולוציה נראה גרעין הקונבולוציה.
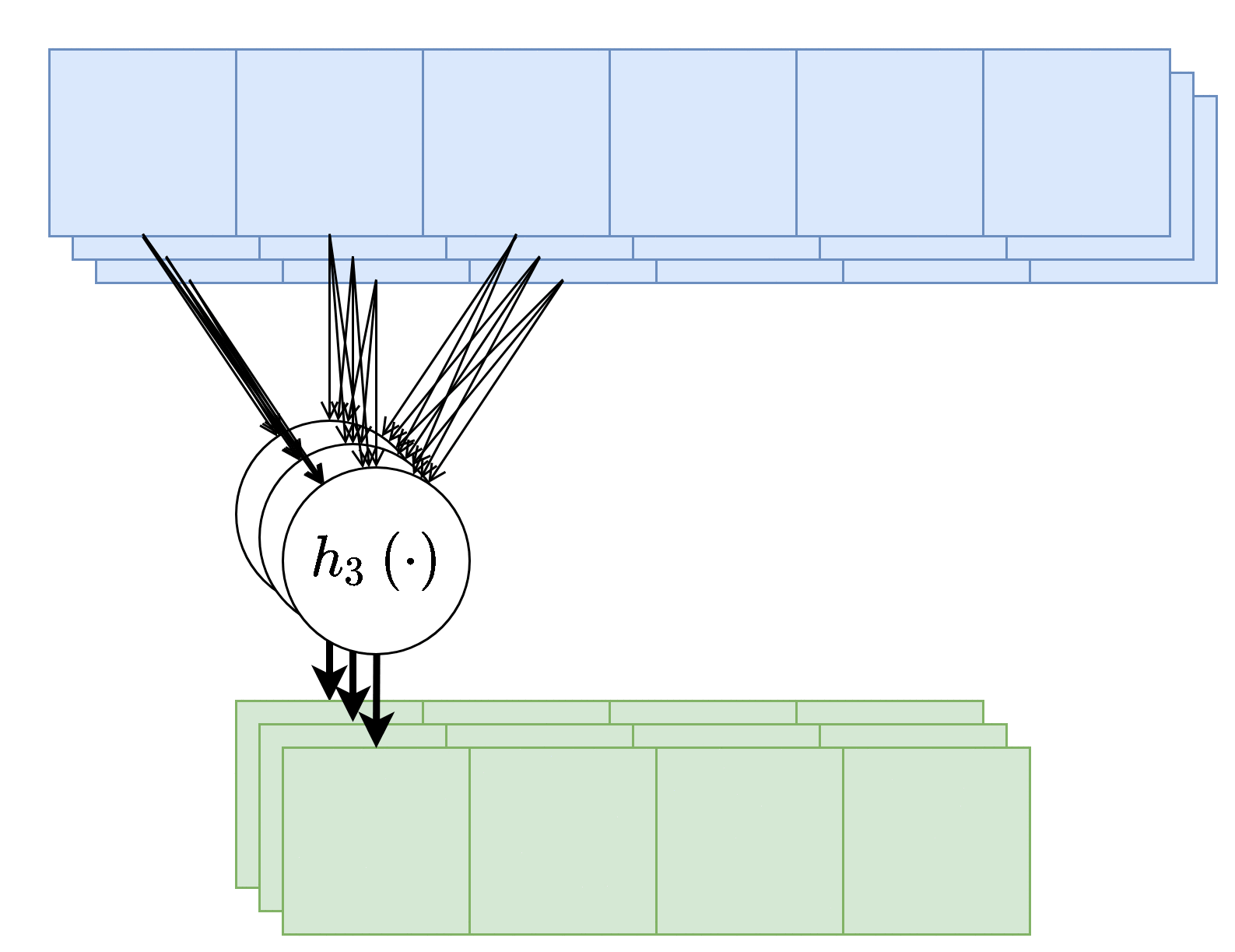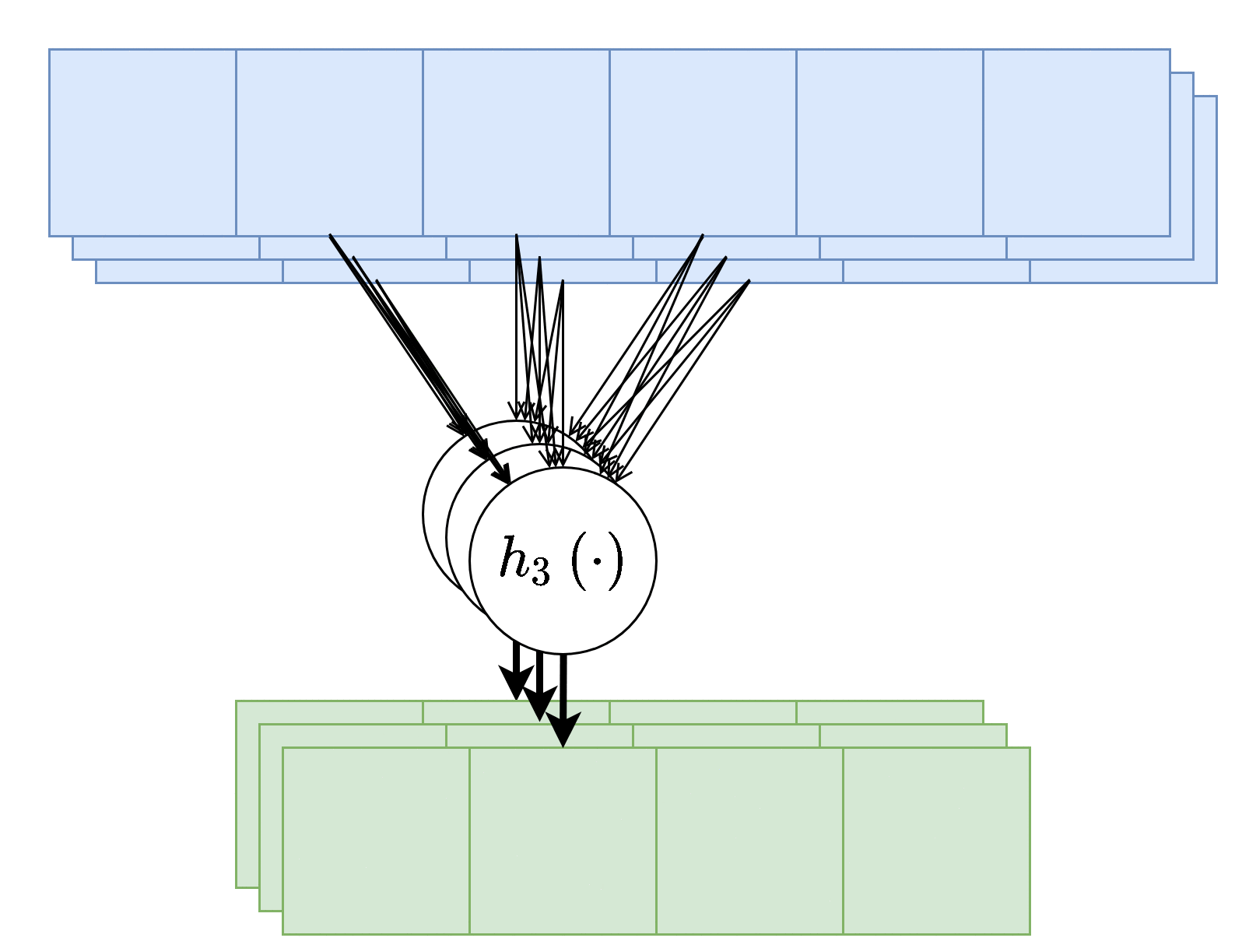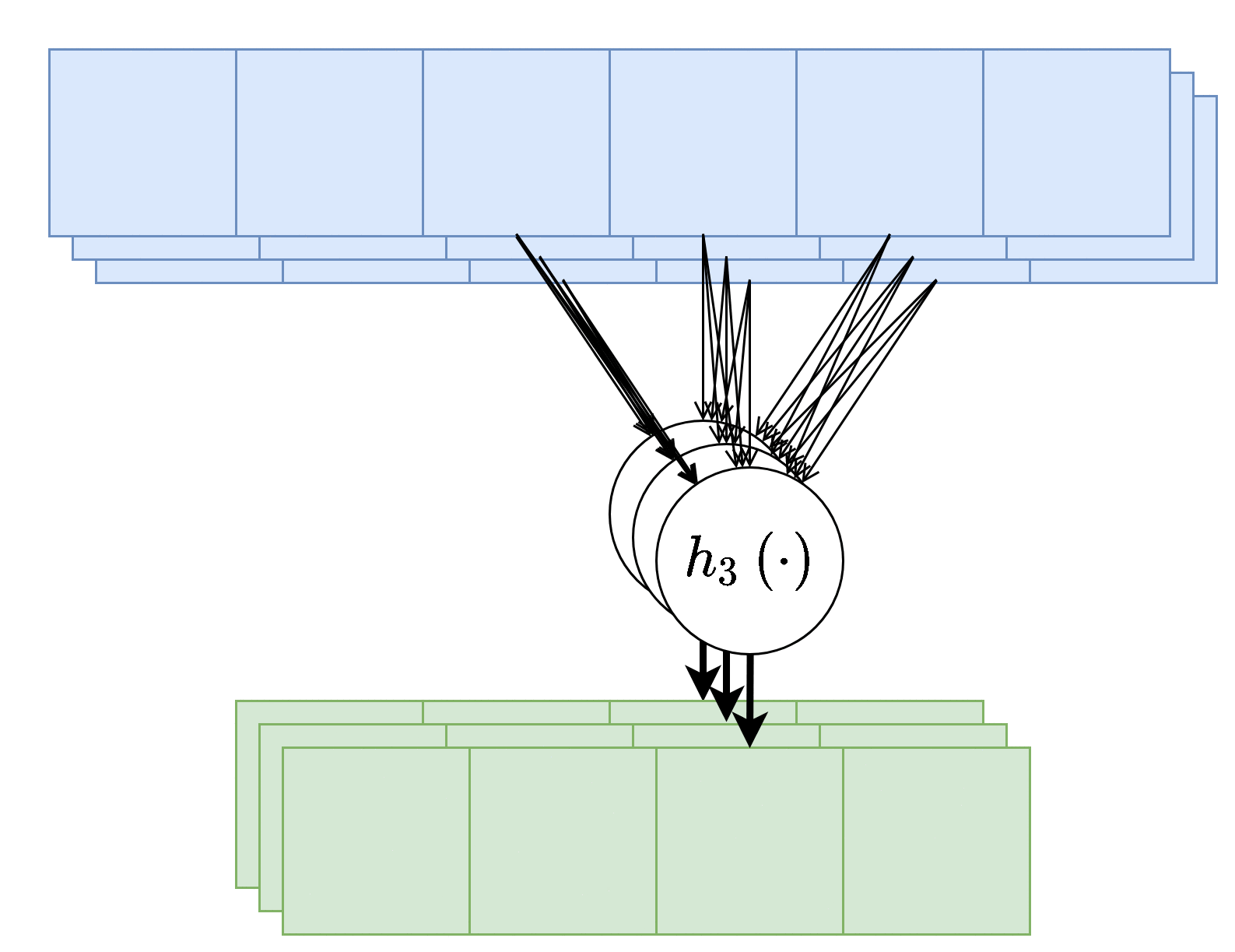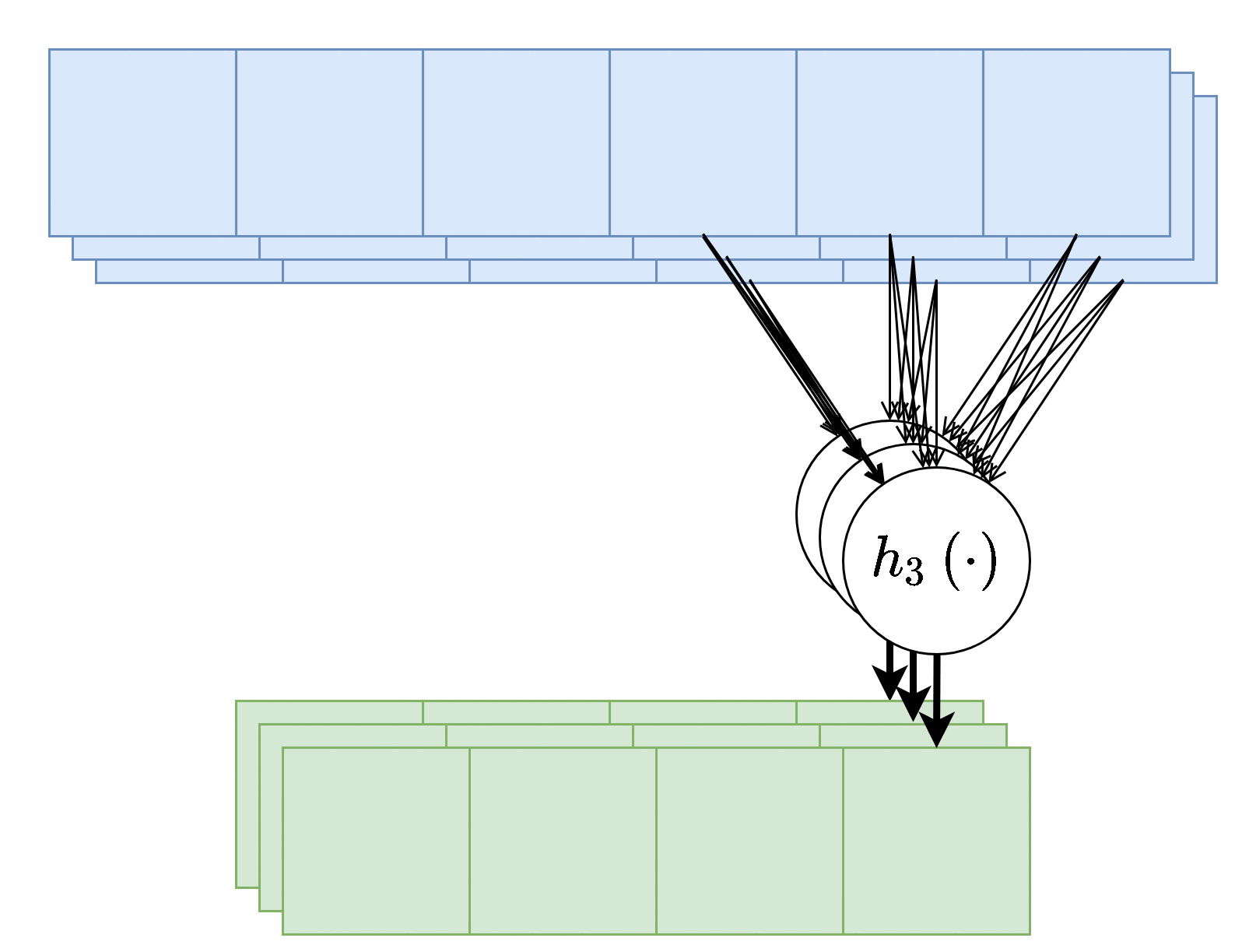
שכבות קונבולוציה עם מספר ערצים
שכבת קונבולוציה תכיל לרוב מספר ערוצים בכניסה ומספר ערוצים ביציאה. במקרה זה יהיה נוירון שונה (עם גרעין קונבולוציה שונה) בעבור כל ערוץ ביציאה וכל אחד מהנוירונים יפעל על כל ערוצי הכניסה
מספר הפרמטרים בשכבת כזאת היינו: C in × C out × K ⏟ the weights + C out ⏟ the bias \underbrace{C_\text{in}\times C_\text{out}\times K}_\text{the weights}+\underbrace{C_\text{out}}_\text{the bias} the weights C in × C out × K + the bias C out
כאשר:
C in C_\text{in} C in C out C_\text{out} C out K K K
תכונות נוספות
שכבות Pooling
שכבות אשר משמשות להקטנת המספר האיברים שעליהם הרשת עובדת. שתי שכבות pooling נפוצות הינן:
Average pooling : אשר פועל כל פעם על חלון מסויים ומחזיר את הממוצע שלו.Max pooling : אשר פועל כל פעם על חלון מסויים ומחזיר את הערך המקסימאלי בחלון הנתון.
שכבות pooling מוגדרות על ידי שני פרמטרים, גודל החלון וה stride (גודל הצעד שבו הם זזות). (לרוב ה-stride יהיה זהה לגודל החלון).
בשכבה זאת אין פרמטרים נלמדים.
Usupervised Learning
PCA
PCA הוא אלגוריתם לינארי להורדת המימד של הוקטור x \boldsymbol{x} x K K K
Encoding (קידוד): z = T ⊤ ( x − x ˉ ) \boldsymbol{z}=\boldsymbol{T}^{\top}(\boldsymbol{x}-\bar{\boldsymbol{x}}) z = T ⊤ ( x − x ˉ )
Decoding (שיחזור): x ~ = T z + x ˉ \tilde{\boldsymbol{x}}=\boldsymbol{T}\boldsymbol{z}+\bar{\boldsymbol{x}} x ~ = T z + x ˉ
כאשר:
x ˉ = 1 N ∑ i = 1 N x ( i ) \bar{\boldsymbol{x}}=\frac{1}{N}\sum_{i=1}^N \boldsymbol{x}^{(i)} x ˉ = N 1 ∑ i = 1 N x ( i ) X \boldsymbol{X} X X = ( x ( 1 ) − x ˉ , x ( 2 ) − x ˉ , … , x ( N ) − x ˉ ) ⊤ \boldsymbol{X}=(\boldsymbol{x}^{(1)}-\bar{\boldsymbol{x}},\boldsymbol{x}^{(2)}-\bar{\boldsymbol{x}},\dots,\boldsymbol{x}^{(N)}-\bar{\boldsymbol{x}})^{\top} X = ( x ( 1 ) − x ˉ , x ( 2 ) − x ˉ , … , x ( N ) − x ˉ ) ⊤ T \boldsymbol{T} T K K K X ⊤ X \boldsymbol{X}^{\top}\boldsymbol{X} X ⊤ X
K-Means
אלגוריתם אשכול אשר מבצע אישכול ל K K K
K K K I k \mathcal{I}_k I k k k k I 5 = { 3 , 6 , 9 , 13 } \mathcal{I}_5=\left\lbrace3, 6, 9, 13\right\rbrace I 5 = { 3 , 6 , 9 , 1 3 } ∣ I k ∣ |\mathcal{I}_k| ∣ I k ∣ k k k { I k } k = 1 K \{\mathcal{I}_k\}_{k=1}^K { I k } k = 1 K
K-means מנסה לפתור את בעיית האופטימיזציה הבאה:
arg min { I j } k = 1 K 1 N ∑ k = 1 K 1 2 ∣ I k ∣ ∑ i , j ∈ I k ∥ x ( j ) − x ( i ) ∥ 2 2 = arg min { I j } k = 1 K 1 N ∑ k = 1 K ∑ i ∈ I k ∥ x ( i ) − μ k ∥ 2 2 \underset{\{\mathcal{I}_j\}_{k=1}^K}{\arg\min}\frac{1}{N}\sum_{k=1}^K\frac{1}{2|\mathcal{I}_k|}\sum_{i,j\in\mathcal{I}_k}\lVert\boldsymbol{x}^{(j)}-\boldsymbol{x}^{(i)}\rVert_2^2
=\underset{\{\mathcal{I}_j\}_{k=1}^K}{\arg\min}\frac{1}{N}\sum_{k=1}^K\sum_{i\in\mathcal{I}_k}\lVert\boldsymbol{x}^{(i)}-\boldsymbol{\mu}_k\rVert_2^2 { I j } k = 1 K arg min N 1 k = 1 ∑ K 2 ∣ I k ∣ 1 i , j ∈ I k ∑ ∥ x ( j ) − x ( i ) ∥ 2 2 = { I j } k = 1 K arg min N 1 k = 1 ∑ K i ∈ I k ∑ ∥ x ( i ) − μ k ∥ 2 2 כאשר:
μ k = 1 ∣ I k ∣ ∑ i ∈ I k x ( i ) \boldsymbol{\mu}_k=\frac{1}{|\mathcal{I}_k|}\sum_{i\in\mathcal{I}_k}\boldsymbol{x}^{(i)} μ k = ∣ I k ∣ 1 i ∈ I k ∑ x ( i ) האלגוריתם
האלגוריתם מאותחל בצעד t = 0 t=0 t = 0 K K K { μ k } k = 1 K \{\mu_k\}_{k=1}^K { μ k } k = 1 K
בכל צעד t t t
עדכון מחדש את החלוקה לאשכולות { I k } k = 1 K \{\mathcal{I}_k\}_{k=1}^K { I k } k = 1 K x \boldsymbol{x} x
k = arg min k ∈ [ 1 , K ] ∥ x − μ k ∥ 2 2 k=\underset{k\in[1,K]}{\arg\min} \lVert\boldsymbol{x}-\boldsymbol{\mu}_k\rVert_2^2 k = k ∈ [ 1 , K ] arg min ∥ x − μ k ∥ 2 2 (במקרה של שני מרכזים במרחק זהה נבחר בזה בעל האינדקס הנמוך יותר).
עדכון של מרכזי המסה המסה על פי:
μ k = 1 ∣ I k ∣ ∑ i ∈ I k x ( i ) \boldsymbol{\mu}_k=\frac{1}{|\mathcal{I}_k|}\sum_{i\in\mathcal{I}_k}\boldsymbol{x}^{(i)} μ k = ∣ I k ∣ 1 i ∈ I k ∑ x ( i ) (אם ∣ I k ∣ = 0 |\mathcal{I}_k|=0 ∣ I k ∣ = 0
תנאי העצירה של האלגוריתם הינו כשהאשכולות מפסיקים להשתנות.
אחת הדרכים הנפוצות לאיתחול של { μ k } k = 1 K \{\mu_k\}_{k=1}^K { μ k } k = 1 K k k k